Redis主从复制和哨兵模式介绍
目录
前言
一、redis群集
1、模式
2、作用
2.1 主从复制
2.2 哨兵
2.3 集群
二、redis主从复制
1、概述
2、redis结构分类
3、主从复制原理
4、redis全量同步
5、redis增量复制
6、redis主从同步策略
三、搭建Redis主从复制
1、项目环境
2、关闭防火墙,安装环境
3、解压并安装
4、创建链接文件,并启动服务
5、修改配置文件
5.1 主服务器上
5.2 备选服务器上,先开启和主服务器一样的功能,再进行以下配置
6、master主服务器上验证从节点
7、验证结果
四、哨兵模式
1、为什么要用到哨兵
1.1 从redis宕机
1.2 主redis宕机
2、主要功能
3、作用
4、 原理
5、哨兵模式下的故障迁移
5.1 哨兵的三个定时任务
5.2 主观下线(SDOWN)和客观下线(ODOWN)
5.3 master选举
5.4 故障转移
6、哨兵模式优缺点
五、哨兵的配置
1、编辑配置文件
2、拷贝配置文件到slave服务器
3、启动哨兵模式
4、查看哨兵信息
5、模拟故障
6、验证结果
总结
前言
由于redis的高性能,在应用中对其依赖很高,有时候一台redis服务器性能不够,需要配置redis集群。最简单的就是一台用来读,一台用来写。一般对读的需求比较大,所以可以配置一主(读)多从(写)。
一、redis群集
1、模式
分别是主从同步/复制、哨兵模式
2、作用
2.1 主从复制
是高可用Redis的基础,主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
2.2 哨兵
在主从复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡:存储能力受到单机的限制。
2.3 集群
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
二、redis主从复制
1、概述
- Redis,虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,保证主数据库的数据内容和从数据库的内容完全一致。
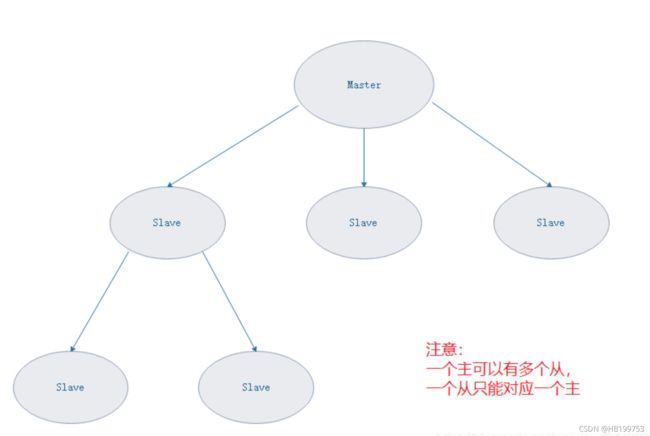
2、redis结构分类
- Redis 的主从结构可以采用一主多从或者级联结构,
- Redis 主从复制可以根据是否是全量分为全量同步和增量同步。
3、主从复制原理
当从节点启动后,会向主数据库发送SYNC命令。同时主数据库收到SYNC命令后会开始在后台保存快照(即RDB持久化,在主从复制时,会无条件触发RDB),并将保存快照期间接收到的命令缓存起来,当快照完成后,redis会将快照文件和所有缓存命令发送给数据库。从数据库接收到快照文件和缓存命令后,会载入快照文件和执行命令,也就是说redis是通过RDB持久化文件和redis缓存命令来时间主从复制。一般在建立主从关系时,一次同步会进行复制初始化。
以上过程为复制初始化,复制初始化结束后,主数据库每当受到写命令时,就会将命令同步给从数据库,保证主从数据一致性。
这里需要提一句,在Redis2.6之前,每次主从数据库断开连接后,Redis需要重新执行复制初始化,在数据量大的情况下,非常低效。而在Redis2.8之后,在断线重连后,主数据库只需要将断线期间执行的命令传送给从数据库。
4、redis全量同步
- Redis 全量复制一般发生在Slave初始化阶段,这时 Slave 需要将 Master 上的所有数据都复制一份。
- 具体步骤如下:
从服务器连接主服务器,发送SYNC命令;
主服务器接收到sYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令。

5、redis增量复制
-
Redis 增量复制是指 Slave 初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。·
-
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
6、redis主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
三、搭建Redis主从复制
1、项目环境
一台mater主服务器
IP:192.168.140.20
两台slave备选服务器
IP:192.168.140.21
IP:192.168.140.22
2、关闭防火墙,安装环境
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
yum -y install gcc gcc-c++ make
cd /opt3、解压并安装
[root@master opt]# tar zxvf redis-5.0.7.tar.gz
[root@master opt]# cd redis-5.0.7/
[root@master redis-5.0.4]# make
[root@master redis-5.0.4]# make PREFIX=/usr/local/redis install
[root@master redis-5.0.4]# cd
4、创建链接文件,并启动服务
[root@master ~]# ln -s /usr/local/redis/bin/* /usr/local/bin/
[root@master ~]# cd redis-5.0.7/utils/
[root@master utils]# ./ //按table 查看相关命令
create-cluster/ graphs/ hyperloglog/ lru/ redis_init_script.tpl speed-regression.tcl
generate-command-help.rb hashtable/ install_server.sh redis_init_script releasetools/ whatisdoing.sh
[root@master utils]# ./install_server.sh
...//弹出的信息,按回车即可
[root@master utils]# netstat -anpt | grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 60219/redis-server
5、修改配置文件
5.1 主服务器上
[root@master ~]# vi /etc/redis/6379.conf
...
69 bind 0.0.0.0 //修改监听地址为 0.0.0.0 (在实验环境使用),现网环境建议绑定从服务器IP地址
136 daemonize yes //开启守护进程
171 logfile /var/log/redis_6379.log //修改日志文件目录
263 dir /var/lib/redis/6379 //修改工作目录
699 appendonly yes //开启AOF持久化功能
5.2 备选服务器上,先开启和主服务器一样的功能,再进行以下配置
[root@slave1 ~]# vi /etc/redis/6379.conf
...
replicaof 192.168.140.20 6379 //开启复制功能
[root@slave1 ~]# /etc/init.d/redis_6379 restart
Stopping ...
Waiting for Redis to shutdown ...
Redis stopped
Starting Redis server...
在主服务器上查看日志
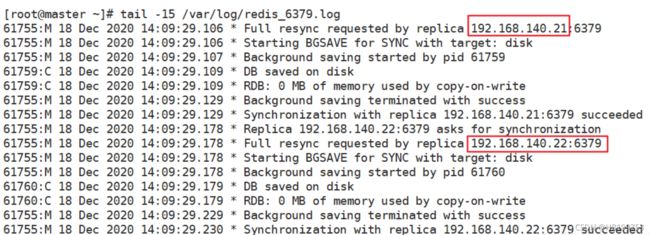
6、master主服务器上验证从节点
- 主服务器上连接数据库并编辑内容
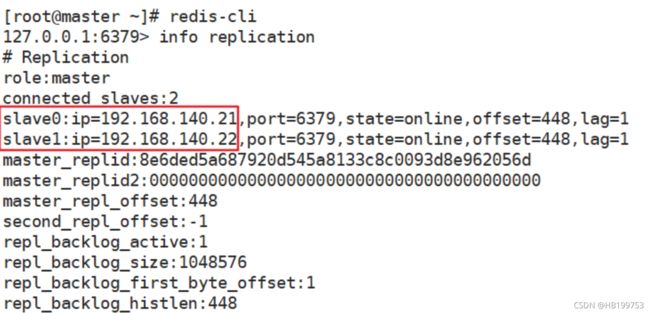
[root@master ~]# redis-cli //连接数据库
127.0.0.1:6379> info replication //查看节点信息
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.140.21,port=6379,state=online,offset=448,lag=1
slave1:ip=192.168.140.22,port=6379,state=online,offset=448,lag=1
master_replid:8e6ded5a687920d545a8133c8c0093d8e962056d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:448
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:448
127.0.0.1:6379> set cp 9 //写入内容,并验证
OK
127.0.0.1:6379> get cp
"9"
- 从服务器上验证主服务器上编辑的内容
[root@slave1 ~]# redis-cli
127.0.0.1:6379> get cp
"9"
127.0.0.1:6379>
7、验证结果
- 当主节点宕机以后
[root@master ~]# /etc/init.d/redis_6379 stop
Stopping ...
Redis stopped
在从节点上查看日志可得
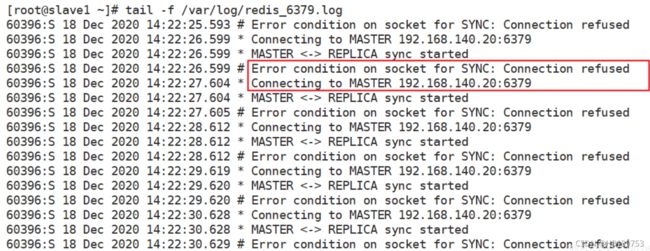
从服务器上查看主服务器上编辑的内容是否存在
[root@slave1 ~]# redis-cli
127.0.0.1:6379> get cp
"9"
127.0.0.1:6379>
-
此时表示redis主从搭建成功
-
结论:redis主从复制,当主服务器故障后,不会自动切换备服务器。虽然读取数据正常,但写入数据会出现问题。
四、哨兵模式
1、为什么要用到哨兵
哨兵(Sentinel)主要是为了解决在主从复制架构中出现宕机的情况,主要分为两种情况:
1.1 从redis宕机
这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据。在Redis2.8版本后,主从断线后恢复的情况下实现增量复制。
1.2 主redis宕机
这个相对而言就会复杂一些,需要以下2步才能完成
第一步,在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务
第二步,将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来
由于这个手动完成恢复的过程其实是比较麻烦的并且容易出错,所以Redis提供的哨兵(sentinel)的功能来解决.
2、主要功能
集群监控:负责监控Redismaster和slave进程是否正常工作
消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报敬通知给管理员
故障转移:如果masternode挂掉了,会自动转移到slave node上
配置中心:如果故障转移发生了,通知client客户端新的master地址
3、作用
哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题
4、 原理
三个哨兵之间建立命令连接,周期检测“队友"状态;
哨兵会向master节点(已在配置文件中指定)发送两条连接,分别是命令连接和订阅连接(为了周期性获取master节点的数据);
哨兵向master周期性发送info命令, master(活着的情况下)会返回redis-cli info replication master节点的信息+从节点位置;
哨兵通过master返回的信息,再会向slaves节点发送info命令,slaves返回数据,从而哨兵集群就可以获取到redis所有集群信息;
哨兵会向服务器发送命令连接,建立自己的hello频道,哨兵会向这个hello频道建立订阅,用于哨兵之间的消息共享;
5、哨兵模式下的故障迁移
5.1 哨兵的三个定时任务
-
1、每个哨兵每10秒会向主节点和从节点发送info命令获取最新的拓扑结构图,哨兵配置时只需要配置对主节点的监控即可,通过向主节点发送info,获取从节点的信息,并当有新的从节点加入时可以马上感知。
-
2、每个哨兵节点每隔2秒会向redis数据节点的指定频道上(sentinel:hello)发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个哨兵节点也会订阅该频道,来了解其他哨兵节点的信息以及对主节点的判断。
- 3、每隔1秒每个哨兵会向主节点、从节点、其他哨兵发送ping命令,做心跳检测。
5.2 主观下线(SDOWN)和客观下线(ODOWN)
主观下线:根据定时任务3对没有有效回复的节点做主观下线处理。
客观下线:若主观下线的是主节点,会联系其他哨兵对此主节点进行判断,一定数量(一半以上吧)的哨兵达成一致意见才认为一个master客观上已经宕机掉,各个哨兵之间通过命令SENTINELis_master_down_by_addr来获得其它哨兵对master的检测结果。
5.3 master选举
在认为主节点客观下线的情况下,哨兵节点节点间会发起一次选举,命令为:SENTINEL is-master-down-by-addr
只是runid这次会将自己的runid带进去,希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为leacer的情况下,会有该leader对故障进行迁移
5.4 故障转移
- sentinel的领导者从从机中选举出合适的丛机进行故障转移
- 对选取的从节点进行slave of no one命令,(这个命令用来让从机关闭复制功能,并从从机变为主机)
- 更新应用程序段的链接到新的主节点
- 对其他从节点变更master为新的节点
- 修复原来的master并将其设置为新的master的从机
6、哨兵模式优缺点
优点:
哨兵集群,基于主从复制模式,所有的主从配置优点,它都有;
主从可以切换,故障可以转移,高可用性的系统;
哨兵模式就是主从模式的升级,手动到自动,更加健壮;
缺点:
Redis不好在线扩容的,集群容量一旦到达上限,在线扩容就十分麻烦;
哨兵模式的配置繁琐;
五、哨兵的配置
1、编辑配置文件
[root@master ~]# vi redis-5.0.4/sentinel.conf
17 protected-mode no //关闭保护模式
26 daemonize yes //指定sentinel为后台启动(开启守护进程)
36 logfile "/var/log/sentinel.log" //指定日志存放路径
65 dir /var/lib/redis/6379 //指定数据库存放路径
84 sentinel monitor mymaster 192.168.140.20 6379 2
//至少几个哨兵检测到主服务器故障了,才会进行故障迁移(当主服务器故障,切换到slave为主服务器时,会将地址改为一个ID号)
113 sentinel down-after-milliseconds mymaster 3000 //判定服务器down掉的时间周期,默认30000毫秒(30S)
146 sentinel failover-timeout mymaster 180000 //故障节点的最大超时时间为180000(180秒)
2、拷贝配置文件到slave服务器
[root@master ~]# scp redis-5.0.4/sentinel.conf [email protected]:/root/redis-5.0.4
3、启动哨兵模式
先启动master,再启slave
[root@master ~]# redis-sentinel redis-5.0.4/sentinel.conf & //&表示在后台启动
[1] 63649
[root@slave1 ~]# redis-sentinel redis-5.0.4/sentinel.conf &
[1] 62327
[root@slave2 ~]# redis-sentinel redis-5.0.4/sentinel.conf &
[1] 60481
4、查看哨兵信息
查看日志
[root@master ~]# tail -f /var/log/sentinel.log

查看进程
[root@master ~]# ps aux | grep sentinel
root 63650 0.2 0.1 153836 2668 ? Ssl 17:23 0:01 redis-sentinel *:26379 [sentinel]
root 63739 0.0 0.0 112676 980 pts/1 S+ 17:31 0:00 grep --color=auto sentinel
[root@master ~]# ps aux | grep redis
root 62860 0.1 0.1 156396 2800 ? Ssl 16:03 0:06 /usr/local/bin/redis-server 0.0.0.0:6379
root 63650 0.2 0.1 153836 2668 ? Ssl 17:23 0:01 redis-sentinel *:26379 [sentinel]
root 63742 0.0 0.0 112676 984 pts/1 S+ 17:31 0:00 grep --color=auto redis

查看哨兵状态
[root@master ~]# redis-cli -h 192.168.140.20 -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.140.20:6379,slaves=2,sentinels=3
[root@master ~]# redis-cli -h 192.168.140.20 -p 6379 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.140.21,port=6379,state=online,offset=174385,lag=0
slave1:ip=192.168.140.22,port=6379,state=online,offset=174385,lag=0
master_replid:75cd6e32461f20e72b1ae7a09bffff02803fb9f9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:174385
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:174385
5、模拟故障
在主服务器上停掉 redis 服务
[root@master ~]# /etc/init.d/redis_6379 stop //停止redis服务
也可以用 kill 命令
kill -9 进程号
6、验证结果
在slave服务器上查看日志得
[root@slavel ~]# tail -f /var/log/sentinel.log
62328:X20 Dec 2020 18:31:59.919 #+failover-state-reconf-slaves master mymaster 192.168.140.20 6379
62328:X20 Dec 2020 18:31:59.975 *+sawe-reconf-sent slave 192.168.140.21:6379 192.168.140.216379@mymaster 192.168.140.20 6379
62328:x20 Dec2020 18:32:00.935 * +slave-reconf-inprog slave 192.168.140.21:6379192.168.140.216379@mymaster 192.168.140.206379
62328:X20 Dec2020 18:32:01.006 #-odown master mymaster 192.168.140.20 6379
62328:X20 Dec2020 18:32:02.004 * +slave- reconf-done slave 192.168.140.21:6379 192.168.140.21 6379 @ mymaster 192.168.140.20 6379
62328:X20 Dec2020 18:32:02.079 #+failover-end master mymaster 192.168.140.206379
62328:X20 Dec2020 18:32:02.079 #+switch-master mymaster 192.168.140.20 6379 192.168.140.22 6379
62328:X20 Dec 2020 18:32:02.080 *+slave slave 192.168.140.21:6379 192.168.140.216379 @ mymaster192.168.140.226379
62328:X20 Dec 2020 18:32:02.080 *+s1ave slave 192.168.140.20:6379192.168.140.206379@mymaster 192.168.140.226379
62328:X20 Dec 2020 18:32:05.092 #+sdown slave 192.168.140.20:6379192.168.140.206379 mymaster 192.168.140.226379 csdn.net/weixin_42449832[root@slave2 ~]# tail -f/var/log/sentinel.log
60482:X14 Dec 2020 09:01:57.686 #+sdown mastermymaster 192.168.140.20 6379
60482:X14 Dec 2020 09:01:57.770 #+new-epoch1
60482:X14 Dec 2020 09:01:57.771 #+vote-for-leader 59fee431b06aaf5789d561df1e56be6b48c56cec12020
60482:X14 Dec 2020 09:01:58.780 #+odown master mymaster 192.168.140.20 6379 #quorum 3/2
60482:X14 Dec 2020 09:01:58.780 # Next failover delay: I will not start a failover before Mon Dec 14 09:07:582020
60482:X14 Dec 2020 09:01:58.886 # +config-update-from sentinel 59fee431b06aaf5789d561dfle56be6b48c56cec 192.168.140.21
60482:X14 Dec 2020 09:01:58.886 # +Switch-master mymaster I92.168.140.20 6379 192.168.140.22 6379
60482:X14 Dec 2020 09:01:58.886 * +s1ave slave 192.168.140.21:6379 192.168.140.21 6379 @ mymaster 192.168.140.22 6379
60482:X14 Dec 2020 09:01:58.886 * +slave slave 192.168.140.20:6379 192.168.140.20 6379 @mymaster 192.168.140.22 6379
60482:X14 Dec 2020 09:02:01.968 # +sdown slave 192.168.140.20:6379 192.168 .140.20 6379 @ mymaster192.168.140.226379
[root@slave2 ~]# redis-cli -h 192.168.140.22 -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.140.22:6379,slaves=2,sentinels=3
- 当主服务器master重新启动后
查看日志及哨兵状态发现,master并没有抢占slave服务器
[root@master ~]# /etc/init.d/redis_6379 start


总结
主从模式:
- 主机宕机,从机作为 主节点 的 备份进行人工切换。
- 扩展 主机 的 读能力,分担主机的压力。
- 主机的写能力和存储能力仍然受到单机的限制
哨兵模式:
- 哨兵只是一个进程,不存储数据,只是监控redis服务。
- 主机宕机,哨兵组会通过投票机制,将其中一台从机切换为主机,而原有的主机变成了从机。
- 通过哨兵机制原主从复制模式下人工切换的方式,变成了自动切换,保证了redis服务的高可用。