Linux 操作系统原理 — PCIe 总线标准
目录
文章目录
- 目录
- 总线系统
- PCIe 总线
-
- PCIe 总线的传输速率
- PCIe 总线的架构
- PCIe 外设
-
- PCIe 设备的枚举过程
- PCIe 设备的编址方式
-
- BDF(Bus-Device-Function)编号
- BAR(Base Address Register)地址
- Linux 上的 PCIe 设备
-
- 查看 PCIe 设备的 BDF
- 查看 PCIe 设备的 Vendor ID 和 Device ID
- 查看 PCIe 设备的详细信息
总线系统
总线系统(Bus System),用于完成主机(CPU + Main Memory)和 I/O 外设(网卡、磁盘)等内部组件之间的通信。
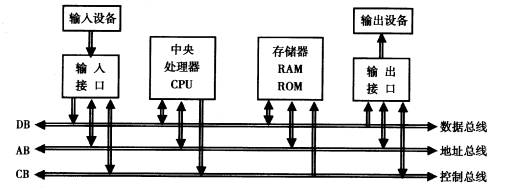
从功能实现上,可以分为 3 种总线类型:
- 数据总线:用于在 CPU 与 Main Memory 或 I/O 设备之间传输数据。
- 地址总线:用于在 CPU 与 Main Memory 或 I/O 设备之间传输地址信息。
- 控制总线:用于在 CPU 与 Main Memory 或 I/O 设备之间传输控制信号。
从系统模块的角度,总线系统主要由 2 大部分组成:
- CPU 总线,又称为 FSB(Front Side Bus,前端总线)。
- PCI/PCIe 总线。
PCIe 总线
PCIe(Peripheral Component Interconnect Express,快速外设组件互连标准)是一种高速总线技术,用于统一连接 NIC、Disk、GPU 等多种类型的 I/O 外设。
PCIe 总线的传输速率
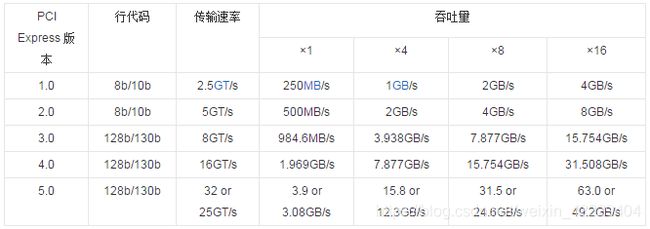
PCIe 使用 GT/s(Giga transmission per Second)作为传输速率的计量单位,区别于网络带宽的计量单位 Gbps(Giga bits per second)。因为 PCIe 协议具有 “行代码比“ 开销,根据不同的编码方案,会占用一定量的原始信道带宽。
所以,PCIe 带宽吞吐量的计算公式为:带宽 = 传输速率 x 行代码比。例如:PCIe 2.0 采用的编码方案是 8b/10b,含义是 10bits 数据里面,有 2bits 是额外的开销,实际上只传递了 8bits 的实际数据。所以,PCIe 2.0 每一条 Lane 的带宽为 5GT/s x 8b / 10b = 500MB/s,那么 PCIe 2.8 x 8 Lane 设备的总带宽就是 500MB/s x 8 = 4GB/s。
通常我们只需要关注实际的吞吐量数据,只是需要区分两者的差别。另外,PCIe 协议支持向前兼容的特性,如果设备支持 PCIe 4.0,但计算机主板支持只支持 PCIe 3.0,那么系统就只能以 3.0 的传输速率运行。
此外,与 PCIe 总线传输速率相关的参数还有以下几个:
- MPS(Maximum Payload Size,最大有效载荷大小):决定了 PCIe 设备可以处理的最大的数据包大小。MPS 由 PCIe 设备的最大 TLP(Transaction Layer Packet,PCIe 事务层数据包)大小和主机的 MPS 参数中较小的一个确定。当数据包大小超过 MPS 时,需要进行 TLP 分片。
- MRRS(Maximum Read Request Size,最大读请求大小):决定了 PCIe 设备可以发送的最大的读请求数据量。MRRS 由主机的 MRRS 参数和 PCIe 设备的 MRRS Capability 中较小的一个确定。
- RCB(Read Completion Boundary,读完成边界):是 PCIe 设备接收的 TLP 的大小限制,即 TLP 读取操作必须是 RCB 的倍数。RCB 由 PCIe 设备的 RCBCR 寄存器设置。
上面 3 个参数的设置都可以影响到 PCIe 的性能。一般来说,提高 MPS、MRRS 可以增加 PCIe 性能,但也会增加延迟和 CPU 占用率。而调整 RCB 可以在一定程度上减小 DMA 操作带来的内存碎片化。
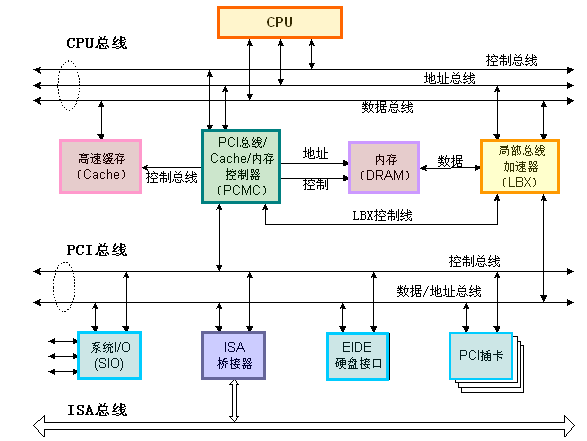
PCIe 总线的架构
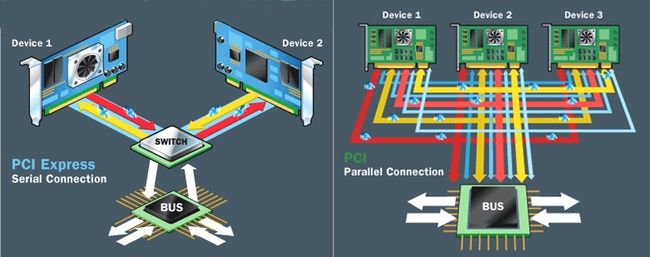
相较于更早前的 PCI Bus 采用的共享并行互联架构,所有 I/O 设备共用一个总线带宽,导致整体性能不高。PCIe Bus 则采用了串行互联架构,以点对点的形式进行数据传输,也就是说每个 PCIe Devices 都有自己的专用连接,可以独享带宽,而不必向共享总线竞争带宽。
具体而言,PCIe 总线架构由以下几个部分组成:
-
PCIe Root Complex(RC,根聚合体):位于主板之上,通过 CPU Bus 与 CPU 和 Main Memory 互联,充当 CPU、Main Memory、PCIe Bus 之间通信的枢纽,并实现各类外设总线的聚合。
-
PCIe Switch:作为 PCle Hub and Switch,连接 PCIe RC 和多个 PCIe Devices,使得 PCIe Bus 具有良好的扩展性。
-
PCIe Endpoint:接入到 PCIe Bus 上的 PCIe Device,可以分为 2 种类型:
- Lagacy PCl-E Endpoint:指兼容 PCIe 标准的 PCI / PCI-X Device。
- Native PCl-E Endpoint:指标准的 PCle Device。
-
PCI/PCI-X Bridge:作为 PCI/PCI-X Bus 和 PCIe Bus 之间的桥接,以此支持标准的 PCI/PCI-X Devices。
PCIe 总线的工作原理如下:
- PCIe Root Complex 发送一个 TLP 到 PCIe Bus。
- PCIe Switch 接收 TLP 并进行路由,将 TLP 转发到 Target PCIe Device。
- PCIe Device 接收到 TLP 后返回 TLP Response。
- PCIe Switch 接收 TLP Response 后返回给 PCIe Root Complex。
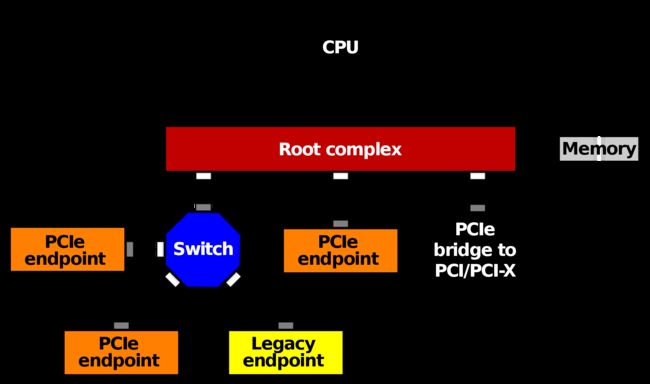
PCIe 外设
-
PCIe 设备的接口类型:

-
PCIe 设备的体积类型:
- LP(半高)
- FH(全高)
- HL(半长)
- FL(全长)
- SW(单宽)
- DW(双宽)
-
PCIe 设备的插槽:PCIe Bus 支持对 PCI/PCI-X Bus 的软件兼容,但主板上的接口插槽却不兼容,因为 PCIe 是串行接口,针数会更少,插槽会更短。

PCIe 设备的枚举过程
PCIe Bus 是一个树状结构,所以 PCIe Devices 的枚举算法采用了深度优先遍历算法,即:对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
-
主机起电后,操作系统首先扫描 Bus0(Root Complex 与 Host Bridge 相连的 PCIe Bus 定为 Bus0)。随后发现 Bridge1,将 Bridge1 下游的 PCIe Bus 定为 Bus1。初始化 Bridge 1 的配置空间,并 Bridge1 的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 0 和 1,表明 Bridge1 的上游总线是 Bus0,下游总线是 Bus1。由于还无法确定 Bridge1 下挂载设备的具体情况,系统先暂时将 Subordinate Bus Number 设为 0xFF。
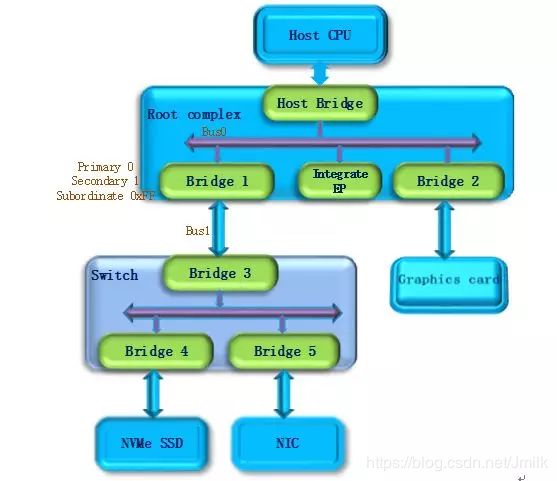
-
操作系统开始扫描 Bus1。随后发现 Bridge3,并识别为一个 PCIe Switch 类型。系统将 Bridge3 下游的 PCIe Bus 定为 Bus 2,并将 Bridge3 的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 1 和 2。一样暂时把 Bridge3 的 Subordinate Bus Number 设为 0xFF。
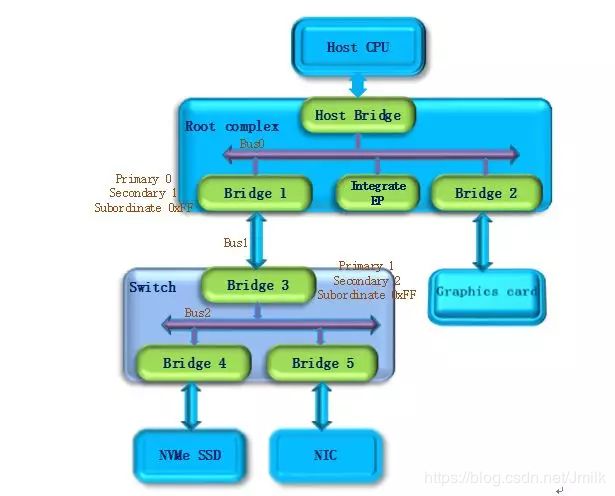
-
操作系统继续扫描 Bus2。随后发现 Bridge4。继续扫描,随后发现 Bridge4 下面挂载了 NVMe SSD 设备。将 Bridge4 下游的 PCIe Bus 定为 Bus3,并将 Bridge4 的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 2 和 3。另外,因为 Bus3 下游是 PCIe Endpoint,不会再有下游总线了,因此 Bridge4 的 Subordinate Bus Number 的值可以确定为 3。

-
完成 Bus3 的扫描后,操作系统返回到 Bus2 继续扫描,随后发现 Bridge5。继续扫描,随后发现 Bridge5 下面挂载的 NIC 设备。将 Bridge5 下游的 PCIe Bus 设置为 Bus4,并将 Bridge5 的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 2 和 4。另外,同样因为 Bus4 上挂在的是 PCIe Endpoint,所以 Bridge5 的 Subordinate Bus Number 的值可以确定为 4。
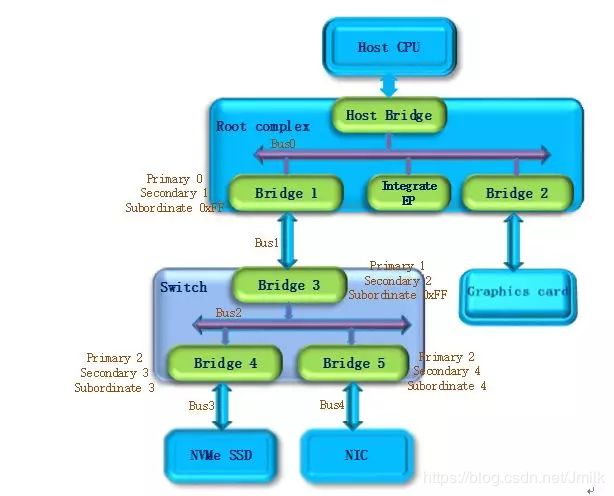
-
除了 Bridge4 和 Bridge5 以外,Bus2 下面已经遍历完毕,因此返回到 Bridge3。因为 Bus4 是挂载在 Bridge3 下游的最后一个 Bus Number,所以将 Bridge3 的 Subordinate Bus Number 设置为 4。Bridge3 的下游设备都已经扫描完毕,继续返回到 Bridge1,同样将 Bridge1 的 Subordinate Bus Number 设置为 4。

-
系统返回到 Bus0 继续扫描,会发现 Bridge2,将 Bridge2 下游的 PCIe Bus 定为 Bus5。并将 Bridge2 的 Primary Bus Number 和 Secondary Bus Number 寄存器分别设置成 0 和 5。由于 Graphics Card 也是 PCIe Endpoint,因此 Bridge2 的 Subordinate Bus Number 的值可以确定为 5。
至此,系统完成了对 PCIe Bus 的扫描,将 PCIe Devices 都枚举了出来,操作系统通过这一过程获得了一个完整的 PCIe 设备拓扑结构。

PCIe 设备的编址方式
BDF(Bus-Device-Function)编号
CPU 要访问一个 PCIe Device 就必须要知道它的总线编号。
PCIe 标准支持在一台 Host 上创建最多 256 个 PCIe Bus,每条 Bus 最多可以支持 32 个 PCIe Device,每个 Device 最多可以支持 8 个 Functions。所以 PCIe 设备的总线编号由 Bus Number(范围是 0~255)、Device Number(范围是 0~31)、Function Number(范围是 0~7)这 3 个部分组成,简称 BDF。
例如:BDF 0000:01:00.0 表示位于 Bus0、Device1、Func0 的 PCIe 设备。

BAR(Base Address Register)地址
CPU 除了需要支持 PCIe Device 得 BDF 之外,还需要从 PCIe Device 的 BAR(Base Address Register,基地址寄存器)知道它所拥有的内存空间的地址范围。Device 的 Driver 需要通过 “基地址+寄存器偏移量“ 的方式来访问 Device 的内存空间并完成相应的配置操作。
下图是一个 PCIe Device 的 Configuration Space(配置空间),具有 6 个 BARs,分布在 0x0010 ~ 0x0028 这 24Bytes 中。在操作系统启动时,就会将这些 BARs 完成解析,并以文件系统的方式供用户态 Application 读取。

更进一步的,PCIe Device 会根据不同的目录将这 6 个 BARs 划分为不同的 Region,以 Intel 82599 网卡为例子。其拥有的 6 个 BAR 被分成了 3 块 Regions,各占 64bits:
-
Memory BAR:指向 Main Memory 的一个地址,表示数据存储空间,对应 Device Memory(数据缓冲寄存器、状态寄存器)。支持进行 mmap() 映射,如果 Application 希望操作 PCIe 设备,就必须 mmap() 这个地址空间。
-
I/O BAR:指向 Main Memory 的一个地址,表示 I/O 空间,对应 Device Register。CPU 可以通过专门的 CPU 指令来操作网卡设备。
-
MSI-X BAR:指向 Main Memory 的一个地址,表示 MSI-X 空间。用来配置 MSI-X 中断向量。

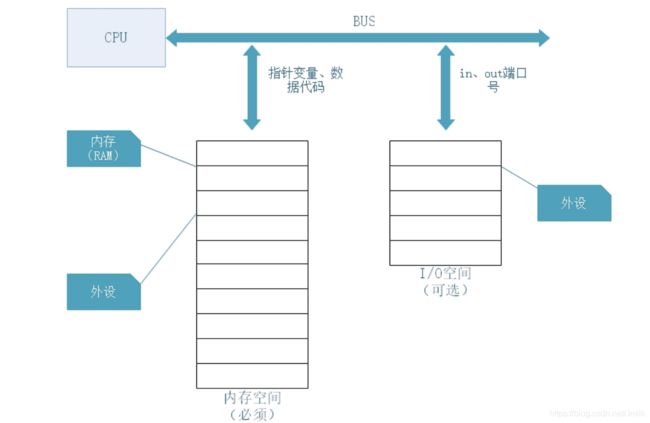
在有了 Memory BAR 和 I/O BAR 之后,CPU 就可以通过 2 种不同的方式来访问 Device 了。其中 Memory BAR 是必须的,而 IO BAR 是可选的。
- 通过 I/O 空间,结合专用的 CPU 指令进行访问。例如:in、out 指令。Intel x86 CPU 的 in、out 的语法如下:
IN 累加器, {端口号 | DX}
OUT {端口号 | DX}, 累加器
- 通过 Memory 空间,进行数据读写,实现上更加容易。
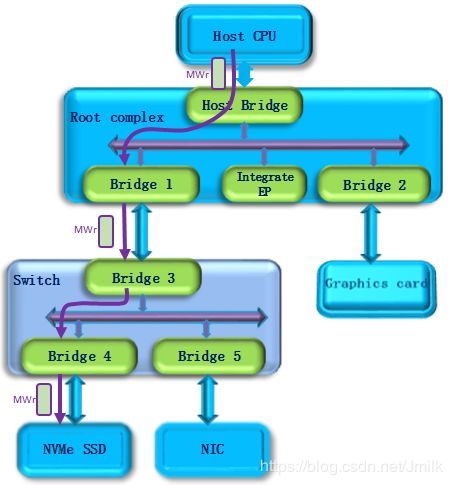
下面以 Memory BAR 为例,介绍 Application 访问 Device 的流程。PCIe Device 的 Memory 空间关联到 PF Memory,存放的是 PF 的控制与状态信息。以 NVMe 为例,对 NVMe 的控制以及获取其工作状态都可以通过访问它的 Memory 空间来实现。
NVMe 命令下发的基本操作是:
- Host 写 doorbell 寄存器,此时使用 PCIe Memory 写请求。如下图所示,Host 发出一个 MWr(Memory Write)请求,该请求经过 PCIe Switch 到达要访问的 NVMe SSD 设备。
- NVMe 读取命令操作,这个请求会被 PCIe Endpoint 接收并执行。如下图所示,此时 NVMe SSD 作为请求者,发出一个 MRd(Memory Read)请求,该请求经过 PCIe Switch 到达 Host CPU。Host CPU 作为完成者会返回一个 CplD(事务完成包),将访问结果返回给 NVMe SSD。
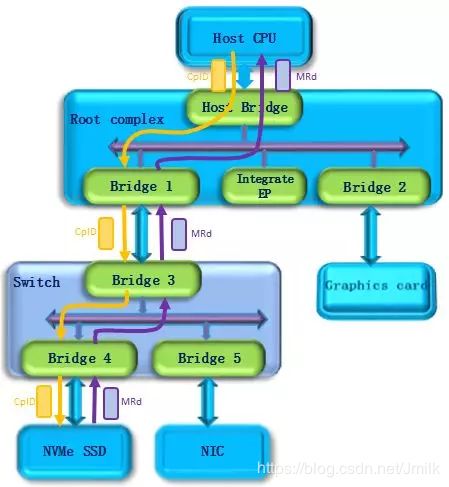
同样,NVMe 的其他操作都是通过 PCIe Memory 访问的方式来进行的。
Linux 上的 PCIe 设备
如下图,查看 Linux 操作系统上的一个 PCIe 设备,具有以下文件:
- config:设备的 Configuration Space,二进制,可读写。
- device:设备的 Device ID,只读。
- vendor:设备的 Vendor ID,只读。
- driver:设备驱动程序的目录。
- enable:设备是否正常使能,可读写;
- irq:设备分到的中断号,只读;
- local_cpulist:和设备处于同一个 NUMA Node 的 CPU 清单,用于实现 NUMA 亲和性。
- local_cpu:和 local_cpulist 的作用一样,以掩码的方式给出。
- numa_node:设备所属的 NUMA node,只读。
- resource:设备的 BARs 记录,只读。
- resource0…N:某个 BAR 空间,二进制,只读。
- sriov_numfs:设备的 VFs 数量。
- sriov_totalvfs:与 sriov_numfs 作用相同。
- subsystem_device:PCIe 子系统设备 ID,只读。
- subsystem_vendor:PCIe 子系统厂商 ID,只读。
查看 PCIe 设备的 BDF
下图黄色方框中的 PCIe 设备是 Bejing Starblaze Technology Co., LTD. 推出的 STAR1000 系列 NVMe SSD 设备,其中 9d32 是 Starblaze 在 PCI-SIG 组织的注册码,1000 是设备系列号。
STAR1000 的 BDF 分别为 0x3C、0x00、0x0,即:3C:00.0,与之对应的上游端口是 00:1d.0。

查看 PCIe 设备的 Vendor ID 和 Device ID
下图可以看到一个 NVMe Controller 的详细信息:
- Vendor ID:供应商识别字段,由 PCI SIG 分配。
- Device ID:设备识别字段,由供应商分配。
- Class Code:表示这是一个 NVMe SSD 设备。
- First Capability Pointer:指向 Device Capability 的入口,从 0x40 地址开始依次是 Power management、MSI 中断、链路控制与状态、MSI-X 中断等特性组。

查看 PCIe 设备的详细信息
下图中展示了指定 PCIe 设备的详细信息。其中可以看见该设备的 Memory BAR 空间,一段的大小是 1MB,另一段的大小是 256KB。系统可以通过 Memory 空间访问设备。