Segment Anything Model代码讲解(一)之SAM
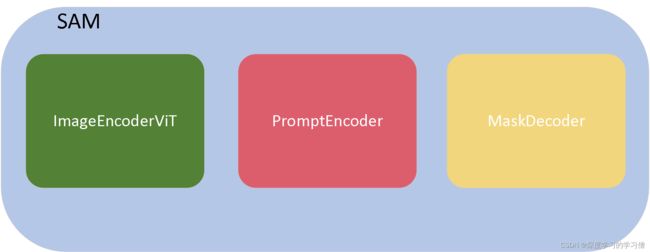
SAM代码内容解析
导入依赖包
import torch
from torch import nn
from torch.nn import functional as F
from typing import Any, Dict, List, Tuple
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
def postprocess_masks(
self,
masks: torch.Tensor, #掩码
input_size: Tuple[int, ...], #输入
original_size: Tuple[int, ...],
) -> torch.Tensor:
"""
Remove padding and upscale masks to the original image size.
将填充和高清掩膜解码的过程去除,使掩膜恢复到原始图像的大小。
Arguments:
masks (torch.Tensor): 从掩码解码器得到的批处理掩码,格式为BxCxHxW
input_size (tuple(int, int)): 输入到模型的图像大小,格式为(H,W),用于去除填充
original_size (tuple(int, int)): 输入模型之前的原始图像大小,格式为(H,W)
Returns:
(torch.Tensor):BxCxHxW格式的批量掩码,其中(H,W)由original_size给出.
"""
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
) #线性插值算法进行掩码
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
#定义预处理方法
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
"""Normalize pixel values and pad to a square input."""
# Normalize colors 归一化
x = (x - self.pixel_mean) / self.pixel_std
# Pad 填充到self.image_encoder.img_size的正方形
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT, #传入一个ImageEncoderViT类型的参数
prompt_encoder: PromptEncoder, #传入一个PromptEncoder类型的参数
mask_decoder: MaskDecoder, #传入一个MaskDecoder类型的参数
pixel_mean: List[float] = [123.675, 116.28, 103.53], #对输入图像中的像素进行归一化的平均值。
pixel_std: List[float] = [58.395, 57.12, 57.375], #用于对输入图像中的像素进行标准化的标准值。
) -> None:
"""
SAM predicts object masks from an image and input prompts.
"""
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
#self.register_buffer用于存储像素值的平均值,它被转换为torch.Tensor并传递给这个方法,以供模型在处理图像时使用。
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
#@property装饰器让使用方法访问属性值的代码看起来像访问实例属性一样,同时为属性访问提供更多的控制和保护。
@property
def device(self) -> Any:
return self.pixel_mean.device
#torch.no_grad()装饰器主要用来禁用PyTorch中的梯度计算,以降低内存消耗和提高代码效率
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
"""
Predicts masks end-to-end from provided images and prompts.
If prompts are not known in advance, using SamPredictor is
recommended over calling the model directly.
Arguments:
batched_input (list(dict)): 一个输入图像的列表,每个图像为一个字典,具有以下键。 如果不存在,可以省略提示键。.
'image': 3xHxW格式的torch张量形式的图像,已经转换为输入到模型中。
'original_size': (tuple(int,int))转换前图像的原始大小,格式为(H,W)
'point_coords':(torch.Tensor)此图像的批处理点提示,形状为BxNx2。已转换为模型的输入帧
'point_labels': (torch.Tensor)点提示的标签,形状为BxN的批量标签
'boxes': torch.Tensor)批量框输入,形状为Bx4。已转换到模型的输入box
'mask_inputs': 模型输入的批量掩码输入,形式为Bx1xHxW
'multimask_output (bool)': 模型是否应预测多个消除歧义的掩码,还是返回单个掩码
Returns:
'(list(dict))': 包含每个图像的字典列表,其中每个元素具有以下键
'masks': (torch.Tensor) 批量二进制掩码预测,形状为BxCxHxW,其中B是输入提示的数量,C由multimask_output确定,(H,W)是原始图像的大小
'iou_predictions': torch.Tensor)掩码质量的模型预测,形状为BxC.
'low_res_logits': (torch.Tensor) 低分辨率的logits,形状为BxCxHxW,其中H=W=256。可以将其作为掩码输入传递给后续的预测迭代
"""
#将图片进行批处理后放入对象input_images的栈中(torch.stack)
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
#怼图片进行image_encode形式的编码嵌入
image_embeddings = self.image_encoder(input_images)
#定义局部变量outputs作为输出
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
#解码的结果
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
#对mask进行处理得到原始图像大小尺度
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
#将预测出的mask、iou_predictions、low_res_logits的结果放入output中
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs