深度学习基础篇之深度神经网络(DNN)
神经网络不应该看做是一个算法,应该看做是一个特征挖掘方法。在实际的业界发展过程中,数据的作用往往大于模型,当我们把数据的隐藏特征提取出来之后,用很简单的模型也能预测的很好。
神经网络模型由生物神经中得到启发。在生物神经元细胞中,神经突触接收到信号,经过接收并处理信号后判断信号的信息强弱,来做出不同神经电位变化反应。受此启发,科研人员设计出基础的神经网络模型结构,神经元模型(Neuron Model)。
一、从感知机到神经网络
1.1 感知机
下图为一个最简单的“M-P神经元结构”,该模型1943年提出,并一直沿用至今:

从模型示意图看,对于一个单一的神经元模型,其中 { x 1 , x 2 , . . . . . . , x n } \{x_1, x_2, ......,x_n\} {x1,x2,......,xn}为该模型的输入数据; { ω 1 , ω 2 , . . . . . . , ω n } \{\omega_1, \omega_2, ......,\omega_n\} {ω1,ω2,......,ωn}为神经元模型计算参数,与输入数据维度一一对应,用于反映输入数据各维度的权重; θ \theta θ表示神经元输出阈值,通常用于控制神经元是否输出结果或修正输出结果;为神经元模型的输出结果,计算方式如下公式:
y = f ( ∑ i = 1 n ω i x i − θ ) y=f(\sum_{i=1}^n\omega_ix_i-\theta) y=f(i=1∑nωixi−θ)
其中,函数 f f f用于将函数值映射至区间[0, 1](主要)或[-1, 1](部分),函数 f f f通常称为激活函数(activation function)。常用的激活函数包括Sigmoid、Tanh函数等。
单层感知机可以实现线性可分的数据学习(存在一个超平面使得数据分开),但是当数据线性不可分时,单层感知机便无法处理。
为了能够使得感知机的适应范围更广,可以将多个感知机进行连接,构成多层感知机模型来适应更复杂的任务。多层感知机模型也被称作人工神经网络(Artificial Neuron Network,ANN),或者叫多层感知机(Multiple-Layer Perceptron,MLP)。
1.2 神经网络
1)为了增强模型的表达能力,在神经网络中加入隐藏层,隐藏层可以有多层,下图实例是一个有2个隐藏层的网络,增加隐藏层会导致模型的复杂度增加。

2)输出层的神经元也可以不止一个输出,可以有多个输出,这样模型可以灵活的应用于分类回归,以及其他的机器学习领域比如降维和聚类等。多个神经元输出的输出层对应的一个实例如下图,输出层现在有4个神经元了。

3)神经网络的激活函数也可以有很多种,感知机的激活函数是 sign(z),虽然简单但是处理能力有限,因此神经网络中一般使用的其他的激活函数,比如我们在逻辑回归里面使用过的Sigmoid函数,即: f ( z ) = 1 1 + e − z f(z)=\frac{1}{1+e^{-z}} f(z)=1+e−z1
还有后来出现的tanx, softmax,和ReLU等。通过使用不同的激活函数,神经网络的表达能力进一步增强。
二、DNN的基本结构
DNN可以理解为有多个隐藏层的神经网络,叫做深度神经网络(Deep Neural Network),DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP),其实是一个东西。
DNN按不同层的位置划分,内部的神经网络层可以分为三类,输入层、隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。

层与层之间是全连接的,也就是说,第 i i i层的任意一个神经元一定与第 i + 1 i+1 i+1层的任意一个神经元相连。虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系 z = ∑ w i x i + b z=\sum w_ix_i+b z=∑wixi+b 加上一个激活函数 s i g m o i d ( z ) sigmoid(z) sigmoid(z)。
由于DNN层数多,则我们的线性关系系数 w w w和偏置 b b b的数量也就是很多了。具体的参数在DNN是如何定义的呢?
首先我们来看线性关系系数 w w w的定义。以下图一个三层的DNN为例,第二层的第4个神经元到第三层的第2个神经元的线性系数定义为 w 24 3 w_{24}^3 w243。上标3代表线性系数 w w w所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。

再来看看偏置 b b b的定义。还是以这个三层的DNN为例,第二层的第三个神经元对应的偏置定义为 b 3 2 b^2_3 b32。其中,上标2代表所在的层数,下标3代表偏倚所在的神经元的索引。同样的道理,第三个的第一个神经元的偏置应该表示为 b 1 3 b^3_1 b13,输入层是没有偏置参数 b b b的。

三、前向传播
在上一节,我们已经介绍了DNN各层权重系数 w w w,偏置 b b b的定义。假设我们选择的激活函数是 s i g m o i d ( z ) sigmoid(z) sigmoid(z),隐藏层和输出层的输出值为 a a a,则对于下图的三层DNN,利用和感知机一样的思路,我们可以利用上一层的输出计算下一层的输出,也就是所谓的DNN前向传播算法。
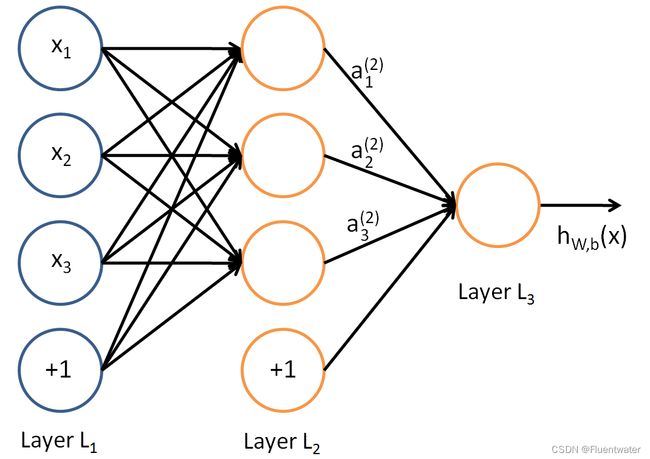
对于第二层的输出 a 1 2 , a 2 2 , a 3 2 a_1^2,a_2^2,a_3^2 a12,a22,a32,我们有:
a 1 2 = σ ( z 1 2 ) = σ ( ω 11 2 x 1 + ω 12 2 x 2 + ω 13 2 x 3 + b 1 2 ) a 2 2 = σ ( z 2 2 ) = σ ( ω 21 2 x 1 + ω 22 2 x 2 + ω 23 2 x 3 + b 2 2 ) a 3 2 = σ ( z 3 2 ) = σ ( ω 31 2 x 1 + ω 32 2 x 2 + ω 33 2 x 3 + b 3 2 ) a_1^2=\sigma(z_1^2)=\sigma(\omega_{11}^2x_1+\omega_{12}^2x_2+\omega_{13}^2x_3+b_1^2) \\ a_2^2=\sigma(z_2^2)=\sigma(\omega_{21}^2x_1+\omega_{22}^2x_2+\omega_{23}^2x_3+b_2^2) \\ a_3^2=\sigma(z_3^2)=\sigma(\omega_{31}^2x_1+\omega_{32}^2x_2+\omega_{33}^2x_3+b_3^2) a12=σ(z12)=σ(ω112x1+ω122x2+ω132x3+b12)a22=σ(z22)=σ(ω212x1+ω222x2+ω232x3+b22)a32=σ(z32)=σ(ω312x1+ω322x2+ω332x3+b32)
对于第三层的输出 a 1 3 a_1^3 a13,我们有:
a 1 3 = σ ( z 1 3 ) = σ ( ω 11 3 a 1 2 + ω 12 3 a 2 2 + ω 13 3 a 3 2 + b 1 3 ) a_1^3=\sigma(z_1^3)=\sigma(\omega_{11}^3a_1^2+\omega_{12}^3a_2^2+\omega_{13}^3a_3^2+b_1^3) a13=σ(z13)=σ(ω113a12+ω123a22+ω133a32+b13)
将上面的例子一般化,假设 l − 1 l-1 l−1层共有 m m m个神经元,则对于第 l l l层的第 j j j个神经元的输出 a j l a_j^l ajl,可以计算出:
a j l = σ ( z j l ) = σ ( ∑ k = 1 m w j k l a k l − 1 + b j l ) a_j^l = \sigma(z_j^l) = \sigma(\sum_{k=1}^m w_{jk}^la_k^{l-1}+b_j^l) ajl=σ(zjl)=σ(k=1∑mwjklakl−1+bjl)
用向量形式表示每一层的输出为:
a l = σ ( z l ) = σ ( W l a l − 1 + b l ) a^l = \sigma(z^l) = \sigma(W^la^{l-1}+b^l) al=σ(zl)=σ(Wlal−1+bl)
从输入层开始,依次计算下一层的输出,直到最后一层即可得到模型的输出结果。单独看前向传播似乎只是简单的矩阵相乘,没有太大用处,但神经网络的奥秘在于下一节的反向传播,反向传播会不断的更新模型参数,继而优化预测准确性。
四、反向传播
在了解DNN的反向传播算法前,我们先要知道DNN反向传播算法要解决的问题,也就是说,什么时候我们需要这个反向传播算法?