Pascal VOC数据集详细介绍
Pascal VOC数据集详细介绍
前言
因为最近打算尝试一下Faster-RCNN的复现,不要多想,我还没有厉害到可以一个人复现所有代码。所以,是参考别人的代码,进行自己的解读。
代码来自于B站的UP主(大佬666),其把代码都放到了GitHub上了,我把链接都放到下面了(应该不算侵权吧,毕竟代码都开源了_):
b站链接:https://www.bilibili.com/video/BV1of4y1m7nj/?vd_source=afeab8b555e5eb1bfa1e7f267262cbf2
GitHub链接:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
目的
其实UP主已经做了很好的视频讲解了他的代码,只是有时候我还是喜欢阅读博客来学习,视频不能享受随心所欲的感觉(另外视频很长,6个小时),所以才打算写博客。
目前完成的内容
第一篇:VOC数据集详细介绍(本文)
目录结构
文章目录
-
- Pascal VOC数据集详细介绍
-
- 1. 数据集下载:
- 2. Annotations文件夹:
- 3. ImageSets文件夹:
- 4. JPEGImage文件夹:
- 5. SegmentationClass文件夹:
- 6. SegmentationObject文件夹:
- 7. 总结:
1. 数据集下载:
Pascal VOC2012 训练集和验证集下载地址:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
下载后,可以把它解压缩,得到下面的目录结构:

2. Annotations文件夹:
Annotation,翻译过来为注释,里面为xml文件,一种类似于html的格式,一个xml文件对应一张图片,里面通过标签包围数据,随意打开一个xml文件,部分内容如下:
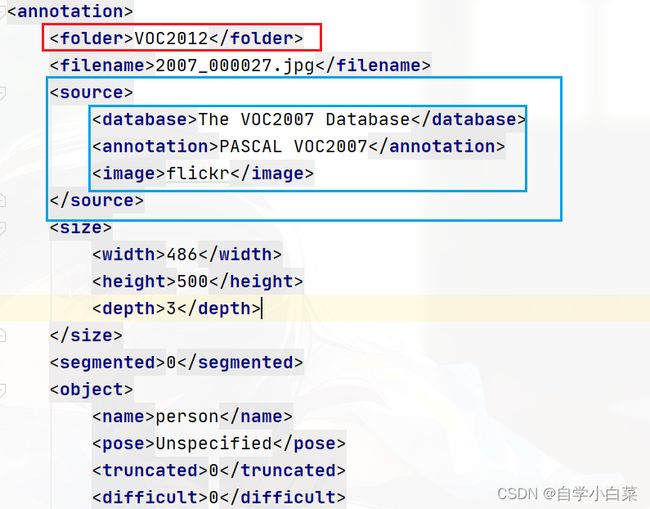
你可以把xml文件当作txt文件,两者的区别在于存储数据的格式不同。在xml文件中,主要的结构就是节点/标签,比如上图中红色的内容:
<folder>VOC2012folder>
尖括号包围的内容(folder),就是我们之后获取数据的定位信息,而两者之间的VOC2012就是这个标签包围的数据信息。而,看蓝色框起来的部分,可以知道,xml里的标签可以是嵌套的。
知道了这些信息,我们就可以对里面的内容进行解读了:(看下面代码的注释即可)
<annotation>
<folder>VOC2012folder>
<filename>2007_000027.jpgfilename>
<source>
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
source>
<size>
<width>486width>
<height>500height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>personname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>174xmin>
<ymin>101ymin>
<xmax>349xmax>
<ymax>351ymax>
bndbox>
<part>
<name>headname>
<bndbox>
<xmin>169xmin>
<ymin>104ymin>
<xmax>209xmax>
<ymax>146ymax>
bndbox>
part>
<part>
<name>handname>
<bndbox>
<xmin>278xmin>
<ymin>210ymin>
<xmax>297xmax>
<ymax>233ymax>
bndbox>
part>
<part>
<name>footname>
<bndbox>
<xmin>273xmin>
<ymin>333ymin>
<xmax>297xmax>
<ymax>354ymax>
bndbox>
part>
<part>
<name>footname>
<bndbox>
<xmin>319xmin>
<ymin>307ymin>
<xmax>340xmax>
<ymax>326ymax>
bndbox>
part>
object>
annotation>
在后面的代码中,获取的信息都是通过这些节点来获取的,比如xxx['object']之类的。
3. ImageSets文件夹:
其下有四个文件夹,其中:
Action
指的是人的动作,比如:

一般是三个三个一起出现的,分别为训练集、训练的验证集和测试集。文件的名字前面表示的是动作,比如上图中第一个jumping,表示人的跳跃。我们打开这个文件夹,发现共有三列构成,第一行内容为:
2011_003279 1 -1
为了体现后面数字的差别,我们再找两行:
2011_003285 3 -1
2011_003298 1 1
然后,分别找到它们的图片:



不难猜测,第三列应该是这个动作是否出现在图片中的意思。
而这个第二列,我是猜测的,因为我发现一个东西:
2011_003285 1 -1
2011_003285 2 -1
2011_003285 3 -1
2011_003285 4 -1
2011_003285 5 -1
一张图片居然出现了几次,而且第二列数字不同,所以我猜测第二列可能是**系统觉得处于跳跃中人的个数(猜测)。**具体第二列是什么,我没有找到具体的说明,如果有朋友知道可以告知一声。
Layout
人的具体部位的信息文件夹。它不像Action一样,还分为很多的动作,而是就只有三个文件,即训练集、训练的验证集和测试集三个。
打开任意一个文件,里面的内容格式都为:
2007_000027 1
其中第一列肯定是图片的名字,第二列具体是什么也不太清楚,猜测和Action的第三列一样,是部分出现的可能数目。
Main
**最重要的文件夹,**里面是图像检测的数据,共20个类别,比如:

每个类别由三个文件构成,分别为训练集、训练的验证集和测试集。其中,打开任意一个文件,一行的内容为(我这里打开的bicycle文件):
2008_003075 1
第一列是对应的图片名字,第二列表示这个对象是否出现在该图像中,1表示出现,-1表示没有出现。
我们找到上面对应的图片为(红色的框是我画的):

注意,在Main文件夹下,有两个最重要的txt文件,分别为train.txt和val.txt。这两个文件夹是总的划分,即相当于机器学习中的训练集和测试集的划分一样,需要保证两者数据不交叉。而这个文件也是我们后面训练需要用到的文件。
Segmentation
里面包含是三个文件,分别为图像分割用到的训练、训练的验证集和测试集三个。任意打开一个文件,里面的内容为:
2007_000032
这里对应的不仅仅是图片名字,还对应了分割文件夹下的分割图片。
4. JPEGImage文件夹:
这个文件夹里面就是所有的图片文件,这倒没啥好说的。
5. SegmentationClass文件夹:
这个是**语义分割(即同一类别不区分颜色)**后的图像,比如:

6. SegmentationObject文件夹:
这个是**图像分割(即同一类别也要区分颜色)**后的图像,如:

7. 总结:
熟悉数据文件,才可以在后面读代码的时候,搞清楚很多东西,比如真实边界框如何获取,边界框变量的值什么等等。