java.io.BufferedInputStream 源码分析
BufferedInputStream是一个带缓冲区的输入流,在读取字节数据时可以从底层流中一次性读取多个字节到缓冲区,而不必每次读取操作都调用底层流,从而提高系统性能。
先介绍几个关键属性
//默认缓冲区的小大
private static int defaultBufferSize = 8192; //内部缓冲区
protected volatile byte buf[]; //缓冲区中可用的字节数量
protected int count; //缓冲区中当前读取位置
protected int pos; //重复读取时标记的位置
protected int markpos = -1; //这个值是设置当用户调用了mark(int readlimit)以后,后续可以读取readlimit这个多个字节reset方法有效。
protected int marklimit;
pos指向缓冲区中下一个可以read的位置,count是记录缓冲区中可用的字节总数,当pos >= count就需要重新读取底层流来填充缓冲区了。

当你调用mark方法时,内部会保存一个markPos标志,它的值为目前读取字节流的pos位置,倘若你调用reset方法,这时候会把pos重置为markPos的值,这样你就可以重读已经读过的字节。
举个例子来说,比如有个字节流为【ABCDEFG】 那么pos指向B的位置,当比调用mark方法时markPos也指向B的位置,然后你接着调用read方法读取 B,C,D,现在pos指向E 当你调用reset方法后
会将pos设置为markPos的位置,这样你在读的时候又从B开始读了,这样就实现了重复读的效果。
mark方法中还有个参数markLimit,它是设置当你调用mark方法后 接着可以读取多少个字节 reset方法仍然保持有效。
举个例子来说,比如你传入的markLimit的值为20, 那么当你调用mark后,后面我读取了22个字节(超过了20),那么这时在调用reset方法就失效了,缓冲区不会再为我保存之前mark标记的那段数据了。
核心方法:当我们调用read()方法时,它在内部做了一些事情。
public synchronized int read() throws IOException { if (pos >= count) { // 检查是否有可读缓冲数据
fill(); // 没有缓冲数据可读,则从物理数据源读取数据并填充缓冲区
if (pos >= count) // 若物理数据源也没有多于可读数据,则返回-1,标示EOF
return -1; } // 从缓冲区读取buffer[pos]并返回(由于这里读取的是一个字节,而返回的是整型,所以需要把高位置0)
return getBufIfOpen()[pos++] & 0xff; } private byte[] getBufIfOpen() throws IOException { byte[] buffer = buf; // buf为内部缓冲区
if (buffer == null) throw new IOException("Stream closed"); return buffer; }
其中pos为缓冲区buffer下一个可读的数组下标,count是比缓冲区中最后一个有效字节的索引大 1 的索引。
我们可以一直从缓冲区里读取数据,直到pos变为count(此时只能从物理数据源读取数据),下面我们就分析下,当缓冲区里没有数据可读时,BufferedInputStream是如何处理的:
private void fill() throws IOException { byte[] buffer = getBufIfOpen(); if (markpos < 0) //对应情况1 这也是最简单的一种情况
pos = 0; //pos < buffer.length 对应情况2当中的A
else if (pos >= buffer.length) //如果进入条件 那么对应情况2当中到B
if (markpos > 0) { //对应情况B1
int sz = pos - markpos; System.arraycopy(buffer, markpos, buffer, 0, sz); pos = sz; markpos = 0; } else if (buffer.length >= marklimit) { //对应情况B3
markpos = -1; pos = 0; } else { //对应情况B4
int nsz = pos * 2; if (nsz > marklimit) nsz = marklimit; byte nbuf[] = new byte[nsz]; System.arraycopy(buffer, 0, nbuf, 0, pos); buffer = nbuf; } count = pos; int n = getInIfOpen().read(buffer, pos, buffer.length - pos); if (n > 0) count = n + pos; }
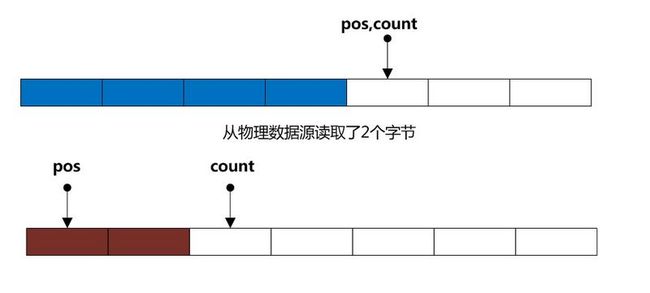
情况1、若用户没有开启re-read功能(即未调用mark方法) 当pos==count时, 我们只需要将pos重新置为0,然后从物理源读取数据(假设读到了n个字节),最后把count设置成 n + pos 即可 (其实就是n,因为pos之前被设置成了0), 当下次你在调用read方法时,就直接从缓冲读取,非常快速(如下图)
情况2、若用户开启了re-read功能,(即调用mark方法),那么情况就变得复杂了,这意味着我们需要保存从markPos到pos这段数据,以供用户调用reset时重复读取该段数据,现在我们分情况讨论。
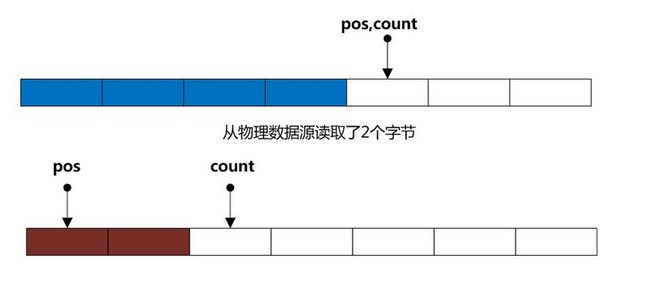
A:pos < buffer.length 这意味着缓冲区还有多余空间,所以我们可以继续从物理数据源读取数据放入到缓冲区中(如下图)
B: pos >= buffer.length 这意味着缓冲区已经没有更多空间,所以需要清空缓冲区,同时还必须保留原来 markPos到pos那段数据,以供用户调用reset时重复读取该段数据,
到这一步又分为几种情况
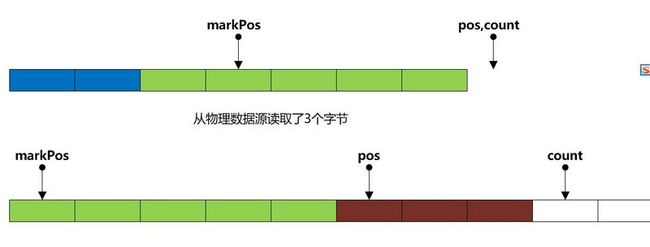
B1:markpos > 0 那么 (pos - makrPos)一定小于缓冲区大小,这样意味着我们保留原来markPos到pos那段数据的同时 缓冲区还有空余空间
所以需要这样做
// 计算需要保留多少字节的数据
int sz = pos - markPos; // 然后拷贝到缓冲头部
System.arraycopy(buffer, markpos, buffer, 0, sz); // 重置pos以及markPos
pos=sz; markPos=0;

B2: markpos == 0 那么 (pos - makrPos)已经等于缓冲区大小,这样意味着我们保留原来markPos到pos那段数据的同时 缓冲区已经没有空余空间,所以这时候我们是无法通过挪动位置来使缓冲区有多余空间的,所以我们只可以清空或扩展缓冲区 那么又分为俩种情况(B3:B4)。
B3: buffer.length >= marklimit时 ,此时意味着markPos已经失效,用户不可以在进行re-read,所以此时我们就可以简单释放整个缓冲区了:pos=0, markPos=-1;
B4: 意味着markPos还有效,所以我们只能通过扩展缓冲区的方式来使缓冲区有多余空间。
再解释一下mark(int readlimit)这个方法的用法,这个readlimit的意思是在调用mark方法以后,缓冲区最对还可以读取多少个字节标记才失效。
是取readlimit和BufferedInputStream类的缓冲区大小两者中的最大值,而并非完全由readlimit确定,这个在JAVA文档中是没有提到的。
JAVA中mark()和reset()用法的通俗理解mark就像书签一样,在这个BufferedInputStream对应的buffer里作个标记,以后再调用reset时就可以再回到这个mark过的地方。mark方法有个参数,通过这个整型参数,你告诉系统,希望在读出这么多个字符之前,这个mark保持有效。读过这么多字符之后,系统可以使mark不再有效,而你不能觉得奇怪或怪罪它。这跟buffer有关,如果你需要很长的距离,那么系统就必须分配很大的buffer来保持你的mark。