用Python做随机数据研究的大概率预测

1.随机组合效益分析
3D随机数据有单选单复式的组合选择方法,可以从0~9这十个数字中选择3个以上不重复的数作为一个组,例如:358就是组三、15789就是组五、013679就是组六,当然也可以是组十,即0123456789全选作为一组,这是单选单复式的最大的组合,但是这个组十其实是没有实际意义的,因为如果单倍下注组十的价格金额是10*9*8*2元/注=1440元,然而中奖金额是1040元,亏了400元。
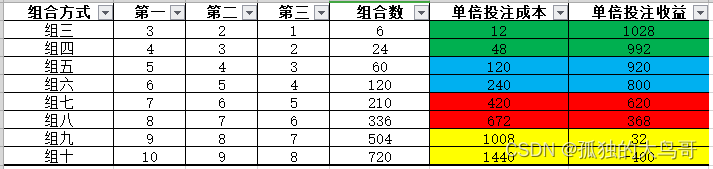
从上表组合效益分析可以看出:组十的收益是负数,是没有实际意义的。组九以下至组三都是有收益的,组九的风险最低但收益最小,组三的风险最高但收益最大。
组九只需要排除重复数和杀掉一个数字,风险相对最小但同时投入很大且收益也最低,如果按100倍投注计算,如果不中将会损失10.08万元,中奖收益是3200元,损失是收益的31.5倍,这很不划算!因此,组九即使有收益也不适合投资。组八则比组九多杀掉一个数字即可,仍以100倍投注计算,如果不中将会损失6.72万元,中奖收益是3.68万元,损失是收益的1.826倍,这就比组九要靠谱很多,这个组合不适合小本操作票友,适合规模效益的集团作战的票友。
2.组五函数模型建立
组三和组四的风险较大,大鸟哥认为组五是最适合以小博大的。那么我们就要研究两个问题:1)组五有多少种组合?2)那几种组五是概率最大的?
大鸟哥用Python爬虫获取了3D的历史数据,并用Python制作并建立了组五函数分析模型。从0~9这十个数字里选出五个不重复的数字组成一组,可以算出总共有252种组五,利用组五函数分析模型可以找出最佳的组五。代码如下:
from itertools import combinations,permutations
import csv #引入csv模块
import openpyxl
# 组合输出
a=[0,1,2,3,4,5,6,7,8,9]
c=list(combinations(a,5)) # 不放回抽样组合,五个数一组合输出
f_0=open('D_0.csv','w',encoding='utf-8',newline="")
csv_writer=csv.writer(f_0)
csv_writer.writerow(['a','b','c','d','e'])
for i in range(len(c)):
csv_writer.writerow(c[i])
# 须将D_0.csv数据粘贴到cdata.xlsx表格在,转换为xlsx格式再进行数据分析处理
workbook = openpyxl.load_workbook('C:\\Users\\Administrator\\Desktop\\cdata.xlsx')
s_1 = workbook['Sheet1'] # 存放理论组合数据
s_2 = workbook['Sheet2'] # 存放历史组合数据
# 将每组6个数字分别判断奇数偶数并计数统计
x_list = []
f_1 = open('D_1.csv', 'w', encoding='utf-8', newline="")
csv_writer = csv.writer(f_1)
csv_writer.writerow(['a', 'b'])
print('正在统计...')
for i in range(len(s_1['A'])): # len(s_1['A'])=252即C(10,5)
llnum_1 = s_1['A'][i].value
llnum_2 = s_1['B'][i].value
llnum_3 = s_1['C'][i].value
llnum_4 = s_1['D'][i].value
llnum_5 = s_1['E'][i].value
x_list = [llnum_1,llnum_2,llnum_3,llnum_4,llnum_5]
p = list(permutations(x_list, 3)) # 五个数中任选三个排成一列
n = 0
for j in range(len(p)): # len(p)=60即A(5,3)
for k in range(len(s_2['A'])): # len(s_2['A'])=7198个历史组合数据
lsnum_0 = s_2['A'][k].value
lsnum_1 = s_2['B'][k].value
lsnum_2 = s_2['C'][k].value
print('核对中...')
print('第:' + str(i * 60 * 7198 + j * 7198 + k + 1)) # 统计循环次数
print('///')
if p[j][0] == lsnum_0 and p[j][1] == lsnum_1 and p[j][2] == lsnum_2 :
n += 1
print('------------------')
print(str(x_list) + '组中出现历史数据组合的频次数:' + str(n))
print('倒查次数:' + str(7198 - n) + '次')
print('------------------')
csv_writer.writerow([str(x_list), str(n)]) # 将210个组五数据及出现频次数写入A_1表格
print('完成统计!')
小伙伴如果想知道运行结果可以到大鸟哥的CSDN论坛主页资源去自行下载(3D随机数据-组五最优组合)。
3.频次预测和测距函数模型
知道了哪些组五是出现频次较高的,我们就可以根据这些高频组五去预测大概率随机数字。这需要统计和分析每一个高频组五的出现频数以及间距的分布。大鸟哥用Python又制作并建立了测距函数模型。代码如下:
import openpyxl
import csv #引入csv模块
workbook = openpyxl.load_workbook('C:\\Users\\Administrator\\Desktop\\3D组五.xlsx')
s_1 = workbook['效益测算'] # 存放历史数据
n = 0
m = 0
p = 0
x_list = []
f_1 = open('L_02459.csv', 'w', encoding='utf-8', newline="")
csv_writer = csv.writer(f_1)
csv_writer.writerow(['distance'])
for i in range(len(s_1['X'])-1):#len(s_1['I'])-1
if s_1['X'][i+1].value == '#N/A' :
n += 1
p += 1
else :
print('出现数字:'+str(s_1['X'][i + 1].value))
print('与上一个数字的实际距离:'+str(n))
print('\\\\\\\\')
x_list.append(n)
m += 1
n = 0
continue
for j in range(len(x_list)):
csv_writer.writerow([int(x_list[j])]) # 将与上个数字的距离写入L_0表格
print('++++++++++++++')
print(x_list)
print('最大距离为:'+str(max(x_list)))
l = p / m
print('平均距离为:'+str(l))
print('完成统计!')
我们用02459这个组五为例,运行一下上述代码,结果如下:
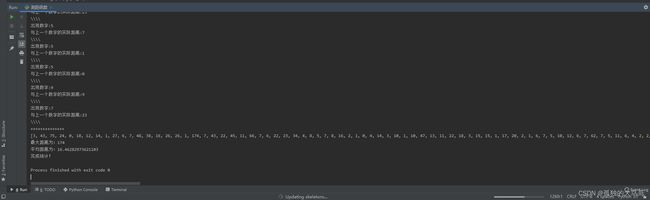
上面这段代码可以用来分析3D随机数据的出现频次和周期间距,这个功能很有参考意义。
结合组五函数模型和测距函数模型,预测3D随机数据就具有了相当的精准能力。