Reactor Proactor模型 epoll模型
内容整理from:
http://www.cnblogs.com/pigerhan/p/3532695.html
http://blog.csdn.net/linxcool/article/details/7771952
http://www.blogjava.net/DLevin/archive/2015/09/02/427045.html
http://www.lai18.com/content/538888.html
Reactor模型与epoll模型的区别s
2.轮询式检查文件描述符集合中的每个fd可读可写状态,IO效率会随着描述符集合增大而降低;
3.可以采用一个父进程专门accept,父进程均衡的分配多个子进程分别处理一部分的链接,子进程采用select模型监测自己负责的fd的可读可写。
epoll模式的特点:
1.支持进程打开的最大文件描述符,很好的解决了C10K问题;
2.IO效率不随FD数目增加而线性下降,epoll不是通过轮询,而是通过在等待的描述符上注册回调函数,当事件发生时,回调函数负责把发生的事件存储在就绪事件链表中,最后写到用户空间;
3.使用mmap加速内核与用户空间的消息传递
在连接少而且都活跃的情况下,使用select模型效果很好;而epoll在高并发量的处理上表现更优秀。
JDK 6.0 以及JDK 5.0 update 9 的 nio支持epoll ( 仅限 Linux 系统 ),对并发idle connection会有大幅度的性能提升,这就是很多网络服务器应用程序需要的。
启用的方法如下:
-Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider
例如在 Linux 下运行的 Tomcat 使用 NIO Connector ,那么启用 epoll 对性能的提升会有帮助。
而 Tomcat 要启用这个选项的做法是在 catalina.sh 的开头加入下面这一行
CATALINA_OPTS='-Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider'
Epoll是Linux内核为处理大批量句柄而作了改进的poll。要使用epoll只需要这三个系统调用:epoll_create(2), epoll_ctl(2), epoll_wait(2)。它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux
kernel 2.5.44),在2.6内核中得到广泛应用,例如LightHttpd。
epoll的优点
支持一个进程打开大数目的socket描述符(FD)
select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是2048。对于那些需要支持的上万连接数目的IM服务器来说显然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。不过
epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
IO效率不随FD数目增加而线性下降
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是"活跃"的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个"伪"AIO,因为这时候推动力在os内核。在一些
benchmark中,如果所有的socket基本上都是活跃的---比如一个高速LAN环境,epoll并不比select/poll有什么效率,相反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
使用mmap加速内核与用户空间的消息传递。
这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。而如果你想我一样从2.5内核就关注epoll的话,一定不会忘记手工 mmap这一步的。
内核微调
这一点其实不算epoll的优点了,而是整个linux平台的优点。也许你可以怀疑linux平台,但是你无法回避linux平台赋予你微调内核的能力。比如,内核TCP/IP协议栈使用内存池管理sk_buff结构,那么可以在运行时期动态调整这个内存pool(skb_head_pool)的大小--- 通过echo XXXX>/proc/sys/net/core/hot_list_length完成。再比如listen函数的第2个参数(TCP完成3次握手的数据包队列长度),也可以根据你平台内存大小动态调整。更甚至在一个数据包面数目巨大但同时每个数据包本身大小却很小的特殊系统上尝试最新的NAPI网卡驱动架构。
epoll的使用
令人高兴的是,2.6内核的epoll比其2.5开发版本的/dev/epoll简洁了许多,所以,大部分情况下,强大的东西往往是简单的。唯一有点麻烦是epoll有2种工作方式:LT和ET。
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表.
ET (edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only
once),不过在TCP协议中,ET模式的加速效用仍需要更多的benchmark确认。
[转]两种高性能I/O设计模式(Reactor/Proactor)的比较
【原文地址:http://www.cppblog.com/pansunyou/archive/2011/01/26/io_design_patterns.html】
综述
这篇文章探讨并比较两种用于TCP服务器的高性能设计模式. 除了介绍现有的解决方案, 还提出了一种更具伸缩性,只需要维护一份代码并且跨平台的解决方案(含代码示例), 以及其在不同平台上的微调. 此文还比较了java,c#,c++对各自现有以及提到的解决方案的实现性能.
系统I/O 可分为阻塞型, 非阻塞同步型以及非阻塞异步型[1, 2]. 阻塞型I/O意味着控制权只到调用操作结束了才会回到调用者手里. 结果调用者被阻塞了, 这段时间了做不了任何其它事情. 更郁闷的是,在等待IO结果的时间里,调用者所在线程此时无法腾出手来去响应其它的请求,这真是太浪费资源了。拿read()操作来说吧, 调用此函数的代码会一直僵在此处直至它所读的socket缓存中有数据到来.
相比之下,非阻塞同步是会立即返回控制权给调用者的。调用者不需要等等,它从调用的函数获取两种结果:要么此次调用成功进行了;要么系统返回错误标识告诉调用者当前资源不可用,你再等等或者再试度看吧。比如read()操作, 如果当前socket无数据可读,则立即返回EWOULBLOCK/EAGAIN,告诉调用read()者"数据还没准备好,你稍后再试".
在非阻塞异步调用中,稍有不同。调用函数在立即返回时,还告诉调用者,这次请求已经开始了。系统会使用另外的资源或者线程来完成这次调用操作,并在完成的时候知会调用者(比如通过回调函数)。拿Windows的ReadFile()或者POSIX的aio_read()来说,调用它之后,函数立即返回,操作系统在后台同时开始读操作。
在以上三种IO形式中,非阻塞异步是性能最高、伸缩性最好的。
这篇文章探讨不同的I/O利用机制并提供一种跨平台的设计模式(解决方案). 希望此文可以给于TCP高性能服务器开发者一些帮助,选择最佳的设计方案。下面我们会比较 Java, c#, C++各自对探讨方案的实现以及性能. 我们在文章的后面就不再提及阻塞式的方案了,因为阻塞式I/O实在是缺少可伸缩性,性能也达不到高性能服务器的要求。
两种IO多路复用方案:Reactor and Proactor
一般情况下,I/O 复用机制需要事件分享器(event demultiplexor [1, 3]). 事件分享器的作用,即将那些读写事件源分发给各读写事件的处理者,就像送快递的在楼下喊: 谁的什么东西送了, 快来拿吧。开发人员在开始的时候需要在分享器那里注册感兴趣的事件,并提供相应的处理者(event handlers),或者是回调函数; 事件分享器在适当的时候会将请求的事件分发给这些handler或者回调函数.
涉及到事件分享器的两种模式称为:Reactor and Proactor [1]. Reactor模式是基于同步I/O的,而Proactor模式是和异步I/O相关的. 在Reactor模式中,事件分离者等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分离者就把这个 事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。
而在Proactor模式中,事件处理者(或者代由事件分离者发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起 时,需要提供的参数包括用于存放读到数据的缓存区,读的数据大小,或者用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分离者得知了这 个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。举例来说,在Windows上事件处理者投递了一个异步IO操作(称有 overlapped的技术),事件分离者等IOCompletion事件完成[1]. 这种异步模式的典型实现是基于操作系统底层异步API的,所以我们可称之为“系统级别”的或者“真正意义上”的异步,因为具体的读写是由操作系统代劳的。
举另外个例子来更好地理解Reactor与Proactor两种模式的区别。这里我们只关注read操作,因为write操作也是差不多的。下面是Reactor的做法:
- 某个事件处理者宣称它对某个socket上的读事件很感兴趣;
- 事件分离者等着这个事件的发生;
- 当事件发生了,事件分离器被唤醒,这负责通知先前那个事件处理者;
- 事件处理者收到消息,于是去那个socket上读数据了. 如果需要,它再次宣称对这个socket上的读事件感兴趣,一直重复上面的步骤;
下面再来看看真正意义的异步模式Proactor是如何做的:
- 事件处理者直接投递发一个写操作(当然,操作系统必须支持这个异步操作). 这个时候,事件处理者根本不关心读事件,它只管发这么个请求,它魂牵梦萦的是这个写操作的完成事件。这个处理者很拽,发个命令就不管具体的事情了,只等着别人(系统)帮他搞定的时候给他回个话。
- 事件分离者等着这个读事件的完成(比较下与Reactor的不同);
- 当事件分离者默默等待完成事情到来的同时,操作系统已经在一边开始干活了,它从目标读取数据,放入用户提供的缓存区中,最后通知事件分离者,这个事情我搞完了;
- 事件分享者通知之前的事件处理者: 你吩咐的事情搞定了;
- 事件处理者这时会发现想要读的数据已经乖乖地放在他提供的缓存区中,想怎么处理都行了。如果有需要,事件处理者还像之前一样发起另外一个写操作,和上面的几个步骤一样。
现行做法
开源C++开发框架 ACE[1, 3](Douglas Schmidt, et al.开发) 提供了大量平台独立的底层并发支持类(线程、互斥量等). 同时在更高一层它也提供了独立的几组C++类,用于实现Reactor及Proactor模式。 尽管它们都是平台独立的单元,但他们都提供了不同的接口.
ACE Proactor在MS-Windows上无论是性能还在健壮性都更胜一筹,这主要是由于Windows提供了一系列高效的底层异步API. [4, 5].
(这段可能过时了点吧) 不幸的是,并不是所有操作系统都为底层异步提供健壮的支持。举例来说, 许多Unix系统就有麻烦.因此, ACE Reactor可能是Unix系统上更合适的解决方案. 正因为系统底层的支持力度不一,为了在各系统上有更好的性能,开发者不得不维护独立的好几份代码: 为Windows准备的ACE Proactor以及为Unix系列提供的ACE Reactor.
就像我们提到过的,真正的异步模式需要操作系统级别的支持。由于事件处理者及操作系统交互的差异,为Reactor和Proactor设计一种通用统一的外部接口是非常困难的。这也是设计通行开发框架的难点所在。
更好的解决方案
在文章这一段时,我们将尝试提供一种融合了Proactor和Reactor两种模式的解决方案. 为了演示这个方案,我们将Reactor稍做调整,模拟成异步的Proactor模型(主要是在事件分离器里完成本该事件处理者做的实际读写工作,我们称这种方法为"模拟异步")。 下面的示例可以看看read操作是如何完成的:
- 事件处理者宣称对读事件感兴趣,并提供了用于存储结果的缓存区、读数据长度等参数;
- 调试者等待(比如通过select());
- 当有事件到来(即可读),调试者被唤醒, 调试者去执行非阻塞的读操作(前面事件处理者已经给了足够的信息了)。读完后,它去通知事件处理者。
- 事件处理者这时被知会读操作已完成,它拥有完整的原先想要获取的数据了.
我们看到,通过为分离者(也就上面的调试者)添加一些功能,可以让Reactor模式转换为Proactor模式。所有这些被执行的操作,其实是和 Reactor模型应用时完全一致的。我们只是把工作打散分配给不同的角色去完成而已。这样并不会有额外的开销,也不会有性能上的的损失,我们可以再仔细 看看下面的两个过程,他们实际上完成了一样的事情:
标准的经典的 Reactor模式:
- 步骤 1) 等待事件 (Reactor 的工作)
- 步骤 2) 发"已经可读"事件发给事先注册的事件处理者或者回调 ( Reactor 要做的)
- 步骤 3) 读数据 (用户代码要做的)
- 步骤 4) 处理数据 (用户代码要做的)
模拟的Proactor模式:
- 步骤 1) 等待事件 (Proactor 的工作)
- 步骤 2) 读数据(看,这里变成成了让 Proactor 做这个事情)
- 步骤 3) 把数据已经准备好的消息给用户处理函数,即事件处理者(Proactor 要做的)
- 步骤 4) 处理数据 (用户代码要做的)
在没有底层异步I/O API支持的操作系统,这种方法可以帮我们隐藏掉socket接口的差异(无论是性能还是其它), 提供一个完全可用的统一"异步接口"。这样我们就可以开发真正平台独立的通用接口了。
TProactor
我们提出的TProactor方案已经由TerabitP/L [6]公司实现了. 它有两种实现: C++的和Java的.C++版本使用了ACE平台独立的底层元件,最终在所有操作系统上提供了统一的异步接口。
TProactor中最重要的组件要数Engine和WaitStrategy了. Engine用于维护异步操作的生命周期;而WaitStrategy用于管理并发策略. WaitStrategy和Engine一般是成对出现的, 两者间提供了良好的匹配接口.
Engines和等待策略被设计成高度可组合的(完整的实现列表请参照附录1)。TProactor是高度可配置的方案,通过使用异步内核API和同步Unix API(select(), poll(), /dev/poll (Solaris 5.8+), port_get (Solaris 5.10),RealTime (RT) signals (Linux 2.4+), epoll (Linux 2.6), k-queue (FreeBSD) ),它内部实现了三种引擎(POSIX AIO, SUN AIO and Emulated AIO)并隐藏了六类等待策略。TProactor实现了和标准的 ACE Proactor一样的接口。这样一来,为不同平台提供通用统一的只有一份代码的跨平台解决方案成为可能。
Engines和WaitStrategies可以像乐高积木一样自由地组合,开发者可以在运行时通过配置参数来选择合适的内部机制(引擎和等待策略)。 可以根据需求设定配置,比如连接数,系统伸缩性,以及运行的操作系统等。如果系统支持相应的异步底层API,开发人员可以选择真正的异步策略,否则用户也 可以选择使用模拟出来的异步模式。所有这一切策略上的实现细节都不太需要关注,我们看到的是一个可用的异步模型。
举例来说,对于运行在Sun Solaris上的HTTP服务器,如果需要支持大量的连接数,/dev/poll或者port_get()之类的引擎是比较合适的选择;如果需要高吞吐 量,那使用基本select()的引擎会更好。由于不同选择策略内在算法的问题,像这样的弹性选择是标准ACE Reactor/Proactor模式所无法提供的(见附录2)。
在性能方面,我们的测试显示,模拟异步模式并未造成任何开销,没有变慢,反倒是性能有所提升。根据我们的测试结果,TProactor相较标签的ACE Reactor在Unix/Linux系统上有大约10-35%性能提升,而在Windows上差不多(测试了吞吐量及响应时间)。
性能比较 (JAVA / C++ / C#).
除了C++,我们也在Java中实现了TProactor. JDK1.4中, Java仅提供了同步方法, 像C中的select() [7, 8]. Java TProactor基于Java的非阻塞功能(java.nio包),类似于C++的TProactor使用了select()引擎.
图1、2显示了以 bits/sec为单位的传输速度以及相应的连接数。这些图比较了以下三种方式实现的echo服务器:标准ACE Reactor实现(基于RedHat Linux9.0)、TProactor C++/Java实现(Microsoft Windows平台及RedHat v9.0), 以及C#实现。测试的时候,三种服务器使用相同的客户端疯狂地连接,不间断地发送固定大小的数据包。
这几组测试是在相同的硬件上做的,在不同硬件上做的相对结果对比也是类似。
用户代码示例
下面是TProactor Java实现的echo服务器代码框架。总的来说,开发者只需要实现两个接口:一是OpRead,提供存放读结果的缓存;二是OpWrite,提供存储待 写数据的缓存区。同时,开发者需要通过回调onReadComplated()和onWriteCompleted()实现协议相关的业务代码。这些回调 会在合适的时候被调用.
class EchoServerProtocol implements AsynchHandler
{
AsynchChannel achannel = null;
EchoServerProtocol( Demultiplexor m, SelectableChannel channel )
throws Exception
{
this.achannel = new AsynchChannel( m, this, channel );
}
public void start() throws Exception
{
// called after construction
System.out.println( Thread.currentThread().getName() +
": EchoServer protocol started" );
achannel.read( buffer);
}
public void onReadCompleted( OpRead opRead ) throws Exception
{
if ( opRead.getError() != null )
{
// handle error, do clean-up if needed
System.out.println( "EchoServer::readCompleted: " +
opRead.getError().toString());
achannel.close();
return;
}
if ( opRead.getBytesCompleted () <= 0)
{
System.out.println("EchoServer::readCompleted: Peer closed "
+ opRead.getBytesCompleted();
achannel.close();
return;
}
ByteBuffer buffer = opRead.getBuffer();
achannel.write(buffer);
}
public void onWriteCompleted(OpWrite opWrite)
throws Exception
{
// logically similar to onReadCompleted
...
}
}
结束语
TProactor为多个平台提供了一个通用、弹性、可配置的高性能通讯组件,所有那些在附录2中提到的问题都被很好地隐藏在内部实现中了。
从上面的图中我们可以看出C++仍旧是编写高性能服务器最佳选择,虽然Java已紧随其后。然而因为Java本身实现上的问题,其在Windows上表现不佳(这已经应该成为历史了吧)。
需要注意的是,以上针对Java的测试,都是以裸数据的形式测试的,未涉及到数据的处理(影响性能)。
纵观AIO在Linux上的快速发展[9], 我们可以预计Linux内核API将会提供大量更加强健的异步API, 如此一来以后基于此而实现的新的Engine/等待策略将能轻松地解决能用性方面的问题,并且这也能让标准ACE Proactor接口受益。
附录 I
TProactor中实现的Engines 和 等待策略
| 引擎类型 | 等待策略 | 操作系统 |
|---|---|---|
POSIX_AIO (true async)aio_read()/aio_write() |
aio_suspend() |
POSIX complained UNIX (not robust) POSIX (not robust) SGI IRIX, LINUX (not robust) |
SUN_AIO (true async)aio_read()/aio_write() |
aio_wait() |
SUN (not robust) |
| Emulated Async Non-blocking read()/write() |
select()poll()/dev/poll Linux RT signals Kqueue |
generic POSIX Mostly all POSIX implementations SUN Linux FreeBSD |
附录 II
所有同步等待策略可划分为两组:
- edge-triggered (e.g. Linux实时信号) - signal readiness only when socket became ready (changes state);
- level-triggered (e.g.
select(),poll(), /dev/poll) - readiness at any time.
让我们看看这两组的一些普遍的逻辑问题:
- edge-triggered group: after executing I/O operation, the demultiplexing loop can lose the state of socket readiness. Example: the "read" handler did not read whole chunk of data, so the socket remains still ready for read. But the demultiplexor loop will not receive next notification.
- level-triggered group: when demultiplexor loop detects readiness, it starts the write/read user defined handler. But before the start, it should remove socket descriptior from theset of monitored descriptors. Otherwise, the same event can be dispatched twice.
- Obviously, solving these problems adds extra complexities to development. All these problems were resolved internally within TProactor and the developer should not worry about those details, while in the synch approach one needs to apply extra effort to resolve them.
Java NIO非堵塞技术实际是采取反应器模式,或者说是观察者(observer)模式为我们监察I/O端口,如果有内容进来,会自动通知我们,这样,我们就不必开启多个线程死等,从外界看,实现了流畅的I/O读写,不堵塞了。
同步和异步区别:有无通知(是否轮询)
堵塞和非堵塞区别:操作结果是否等待(是否马上有返回值),只是设计方式的不同
NIO 有一个主要的类Selector,这个类似一个观察者,只要我们把需要探知的socketchannel告诉Selector,我们接着做别的事情,当有事件发生时,他会通知我们,传回一组SelectionKey,我们读取这些Key,就会获得我们刚刚注册过的socketchannel,然后,我们从这个Channel中读取数据,接着我们可以处理这些数据。
反应器模式与观察者模式在某些方面极为相似:当一个主体发生改变时,所有依属体都得到通知。不过,观察者模式与单个事件源关联,而反应器模式则与多个事件源关联 。
一般模型
我们想象以下情形:长途客车在路途上,有人上车有人下车,但是乘客总是希望能够在客车上得到休息。
传统的做法是:每隔一段时间(或每一个站),司机或售票员对每一个乘客询问是否下车。
反应器模式做法是:汽车是乘客访问的主体(Reactor),乘客上车后,到售票员(acceptor)处登记,之后乘客便可以休息睡觉去了,当到达乘客所要到达的目的地后,售票员将其唤醒即可。
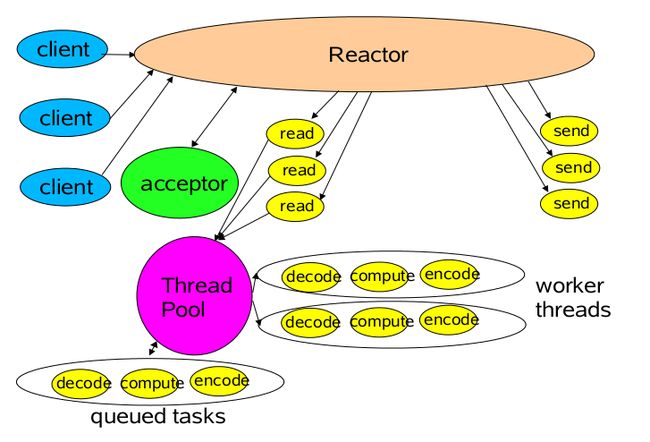
代码实现
前记
第一次听到Reactor模式是三年前的某个晚上,一个室友突然跑过来问我什么是Reactor模式?我上网查了一下,很多人都是给出NIO中的 Selector的例子,而且就是NIO里Selector多路复用模型,只是给它起了一个比较fancy的名字而已,虽然它引入了EventLoop概 念,这对我来说是新的概念,但是代码实现却是一样的,因而我并没有很在意这个模式。然而最近开始读Netty源码,而Reactor模式是很多介绍Netty的文章中被大肆宣传的模式,因而我再次问自己,什么是Reactor模式?本文就是对这个问题关于我的一些理解和尝试着来解答。什么是Reactor模式
要回答这个问题,首先当然是求助Google或Wikipedia,其中Wikipedia上说:“The reactor design pattern is an event handling pattern for handling service requests delivered concurrently by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to associated request handlers.”。从这个描述中,我们知道Reactor模式首先是 事件驱动的,有一个或多个并发输入源,有一个Service Handler,有多个Request Handlers ;这个Service Handler会同步的将输入的请求(Event)多路复用的分发给相应的Request Handler。如果用图来表达: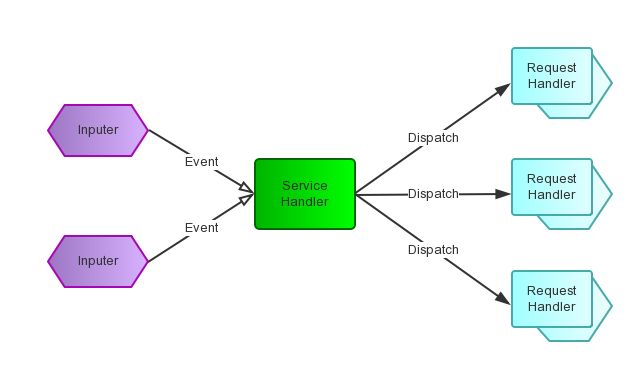
从结构上,这有点类似生产者消费者模式,即有一个或多个生产者将事件放入一个Queue中,而一个或多个消费者主动的从这个Queue中Poll事件来处理;而Reactor模式则并没有Queue来做缓冲,每当一个Event输入到Service Handler之后,该Service Handler会主动的根据不同的Event类型将其分发给对应的Request Handler来处理。
更学术的,这篇文章( Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events )上说:“The Reactor design pattern handles service requests that are delivered concurrently to an application by one or more clients. Each service in an application may consistent of several methods and is represented by a separate event handler that is responsible for dispatching service-specific requests. Dispatching of event handlers is performed by an initiation dispatcher, which manages the registered event handlers. Demultiplexing of service requests is performed by a synchronous event demultiplexer. Also known as Dispatcher, Notifier ”。这段描述和Wikipedia上的描述类似,有多个输入源,有多个不同的EventHandler(RequestHandler)来处理不同的请求,Initiation Dispatcher用于管理EventHander,EventHandler首先要注册到Initiation Dispatcher中,然后Initiation Dispatcher根据输入的Event分发给注册的EventHandler;然而Initiation Dispatcher并不监听Event的到来,这个工作交给Synchronous Event Demultiplexer来处理。
Reactor模式结构
在解决了什么是Reactor模式后,我们来看看Reactor模式是由什么模块构成。图是一种比较简洁形象的表现方式,因而先上一张图来表达各个模块的名称和他们之间的关系:
Handle: 即操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个连接(Socket)、Timer等。由于Reactor模式一般使用在网络编程中,因而这里一般指Socket Handle,即一个网络连接(Connection,在Java NIO中的Channel)。这个Channel注册到Synchronous Event Demultiplexer中,以监听Handle中发生的事件,对ServerSocketChannnel可以是CONNECT事件,对SocketChannel可以是READ、WRITE、CLOSE事件等。
Synchronous Event Demultiplexer: 阻塞等待一系列的Handle中的事件到来,如果阻塞等待返回,即表示在返回的Handle中可以不阻塞的执行返回的事件类型。这个模块一般使用操作系统的select来实现。在Java NIO中用Selector来封装,当Selector.select()返回时,可以调用Selector的selectedKeys()方法获取Set
Initiation Dispatcher: 用于管理Event Handler,即EventHandler的容器,用以注册、移除EventHandler等;另外,它还作为Reactor模式的入口调用Synchronous Event Demultiplexer的select方法以阻塞等待事件返回,当阻塞等待返回时,根据事件发生的Handle将其分发给对应的Event Handler处理,即回调EventHandler中的handle_event()方法。
Event Handler: 定义事件处理方法:handle_event(),以供InitiationDispatcher回调使用。
Concrete Event Handler: 事件EventHandler接口,实现特定事件处理逻辑。
Reactor模式模块之间的交互
简单描述一下Reactor各个模块之间的交互流程,先从序列图开始:
1. 初始化InitiationDispatcher,并初始化一个Handle到EventHandler的Map。
2. 注册EventHandler到InitiationDispatcher中,每个EventHandler包含对相应Handle的引用,从而建立Handle到EventHandler的映射(Map)。
3. 调用InitiationDispatcher的handle_events()方法以启动Event Loop。在Event Loop中,调用select()方法(Synchronous Event Demultiplexer)阻塞等待Event发生。
4. 当某个或某些Handle的Event发生后,select()方法返回,InitiationDispatcher根据返回的Handle找到注册的EventHandler,并回调该EventHandler的handle_events()方法。
5. 在EventHandler的handle_events()方法中还可以向InitiationDispatcher中注册新的Eventhandler,比如对AcceptorEventHandler来,当有新的client连接时,它会产生新的EventHandler以处理新的连接,并注册到InitiationDispatcher中。
Reactor模式实现
在 Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events 中,一直以Logging Server来分析Reactor模式,这个Logging Server的实现完全遵循这里对Reactor描述,因而放在这里以做参考。Logging Server中的Reactor模式实现分两个部分:Client连接到Logging Server和Client向Logging Server写Log。因而对它的描述分成这两个步骤。Client连接到Logging Server

1. Logging Server注册LoggingAcceptor到InitiationDispatcher。
2. Logging Server调用InitiationDispatcher的handle_events()方法启动。
3. InitiationDispatcher内部调用select()方法(Synchronous Event Demultiplexer),阻塞等待Client连接。
4. Client连接到Logging Server。
5. InitiationDisptcher中的select()方法返回,并通知LoggingAcceptor有新的连接到来。
6. LoggingAcceptor调用accept方法accept这个新连接。
7. LoggingAcceptor创建新的LoggingHandler。
8. 新的LoggingHandler注册到InitiationDispatcher中(同时也注册到Synchonous Event Demultiplexer中),等待Client发起写log请求。
Client向Logging Server写Log
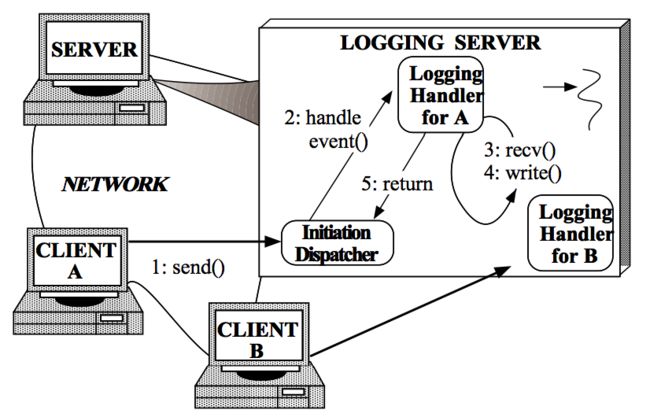
1. Client发送log到Logging server。
2. InitiationDispatcher监测到相应的Handle中有事件发生,返回阻塞等待,根据返回的Handle找到LoggingHandler,并回调LoggingHandler中的handle_event()方法。
3. LoggingHandler中的handle_event()方法中读取Handle中的log信息。
4. 将接收到的log写入到日志文件、数据库等设备中。
3.4步骤循环直到当前日志处理完成。
5. 返回到InitiationDispatcher等待下一次日志写请求。
在 Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events 有对Reactor模式的C++的实现版本,多年不用C++,因而略过。
Java NIO对Reactor的实现
在Java的NIO中,对Reactor模式有无缝的支持,即使用Selector类封装了操作系统提供的Synchronous Event Demultiplexer功能。这个Doug Lea已经在 Scalable IO In Java 中有非常深入的解释了,因而不再赘述,另外 这篇文章 对Doug Lea的 Scalable IO In Java 有一些简单解释,至少它的代码格式比Doug Lea的PPT要整洁一些。需要指出的是,不同这里使用InitiationDispatcher来管理EventHandler,在Doug Lea的版本中使用SelectionKey中的Attachment来存储对应的EventHandler,因而不需要注册EventHandler这个步骤,或者设置Attachment就是这里的注册。而且在这篇文章中,Doug Lea从单线程的Reactor、Acceptor、Handler实现这个模式出发;演化为将Handler中的处理逻辑多线程化,实现类似Proactor模式,此时所有的IO操作还是单线程的,因而再演化出一个Main Reactor来处理CONNECT事件(Acceptor),而多个Sub Reactor来处理READ、WRITE等事件(Handler),这些Sub Reactor可以分别再自己的线程中执行,从而IO操作也多线程化。这个最后一个模型正是Netty中使用的模型。并且在 Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events 的9.5 Determine the Number of Initiation Dispatchers in an Application中也有相应的描述。
EventHandler接口定义
对EventHandler的定义有两种设计思路:single-method设计和multi-method设计:A single-method interface: 它将Event封装成一个Event Object,EventHandler只定义一个handle_event(Event event)方法。这种设计的好处是有利于扩展,可以后来方便的添加新的Event类型,然而在子类的实现中,需要判断不同的Event类型而再次扩展成 不同的处理方法,从这个角度上来说,它又不利于扩展。另外在Netty3的使用过程中,由于它不停的创建ChannelEvent类,因而会引起GC的不稳定。
A multi-method interface: 这种设计是将不同的Event类型在 EventHandler中定义相应的方法。这种设计就是Netty4中使用的策略,其中一个目的是避免ChannelEvent创建引起的GC不稳定, 另外一个好处是它可以避免在EventHandler实现时判断不同的Event类型而有不同的实现,然而这种设计会给扩展新的Event类型时带来非常 大的麻烦,因为它需要该接口。
关于Netty4对Netty3的改进可以参考 这里 :
ChannelHandler with no event objectIn 3.x, every I/O operation created a
ChannelEvent object. For each read / write, it additionally created a new ChannelBuffer. It simplified the internals of Netty quite a lot because it delegates resource management and buffer pooling to the JVM. However, it often was the root cause of GC pressure and uncertainty which are sometimes observed in a Netty-based application under high load.
4.0 removes event object creation almost completely by replacing the event objects with strongly typed method invocations. 3.x had catch-all event handler methods such as handleUpstream() andhandleDownstream(), but this is not the case anymore. Every event type has its own handler method now:
为什么使用Reactor模式
归功与Netty和Java NIO对Reactor的宣传,本文慕名而学习的Reactor模式,因而已经默认Reactor具有非常优秀的性能,然而慕名归慕名,到这里,我还是要不得不问自己Reactor模式的好处在哪里?即为什么要使用这个Reactor模式?在 Reactor An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events 中是这么说的:Reactor Pattern优点
Separation of concerns: The Reactor pattern decouples application-independent demultiplexing and dispatching mechanisms from application-specific hook method functionality. The application-independent mechanisms become reusable components that know how to demultiplex events and dispatch the appropriate hook methods defined by Event Handlers. In contrast, the application-specific functionality in a hook method knows how to perform a particular type of service.
Improve modularity, reusability, and configurability of event-driven applications: The pattern decouples application functionality into separate classes. For instance, there are two separate classes in the logging server: one for establishing connections and another for receiving and processing logging records. This decoupling enables the reuse of the connection establishment class for different types of connection-oriented services (such as file transfer, remote login, and video-on-demand). Therefore, modifying or extending the functionality of the logging server only affects the implementation of the logging handler class.
Improves application portability: The Initiation Dispatcher’s interface can be reused independently of the OS system calls that perform event demultiplexing. These system calls detect and report the occurrence of one or more events that may occur simultaneously on multiple sources of events. Common sources of events may in- clude I/O handles, timers, and synchronization objects. On UNIX platforms, the event demultiplexing system calls are called selectand poll [1]. In the Win32 API [16], the WaitForMultipleObjects system call performs event demultiplexing.
Provides coarse-grained concurrency control: The Reactor pattern serializes the invocation of event handlers at the level of event demultiplexing and dispatching within a process or thread. Serialization at the Initiation Dispatcher level often eliminates the need for more complicated synchronization or locking within an application process.
Thread Per Connection缺点
Efficiency: Threading may lead to poor performance due to context switching, synchronization, and data movement [2];
Programming simplicity: Threading may require complex concurrency control schemes;

在这个统计中,每个线程从磁盘中读8KB数据,每个线程读同一个文件,因而数据本身是缓存在操作系统内部的,即减少IO的影响;所有线程是事先分配的,不会有线程启动的影响;所有任务在测试内部产生,因而不会有网络的影响。该统计数据运行环境:Linux 2.2.14,2GB内存,4-way 500MHz Pentium III。从图中可以看出,随着线程的增长,吞吐量在线程数为8个左右的时候开始线性下降,并且到64个以后而迅速下降,其相应事件也在线程达到256个后指数上升。即1+1<2,因为线程切换、同步、数据移动会有性能损失,线程数增加到一定数量时,这种性能影响效果会更加明显。
对于这点,还可以参考 C10K Problem ,用以描述同时有10K个Client发起连接的问题,到2010年的时候已经出现10M Problem了。
当然也有人说: Threads are expensive are no longer valid .在不久的将来可能又会发生不同的变化,或者这个变化正在、已经发生着?没有做过比较仔细的测试,因而不敢随便断言什么,然而本人观点,即使线程变的影响并没有以前那么大,使用Reactor模式,甚至时SEDA模式来减少线程的使用,再加上其他解耦、模块化、提升复用性等优点,还是值得使用的。
Reactor模式的缺点
Reactor模式的缺点貌似也是显而易见的:1. 相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
2. Reactor模式需要底层的Synchronous Event Demultiplexer支持,比如Java中的Selector支持,操作系统的select系统调用支持,如果要自己实现Synchronous Event Demultiplexer可能不会有那么高效。
3. Reactor模式在IO读写数据时还是在同一个线程中实现的,即使使用多个Reactor机制的情况下,那些共享一个Reactor的Channel如果出现一个长时间的数据读写,会影响这个Reactor中其他Channel的相应时间,比如在大文件传输时,IO操作就会影响其他Client的相应时间,因而对这种操作,使用传统的Thread-Per-Connection或许是一个更好的选择,或则此时使用Proactor模式。