运维面试精选:3、Docker面试题
文章目录
- 1、Docker 中cmd add copy区别?
- 2、请说一说Docker中Cgroups,namespace,unionFS?
- 3、容器的rootfs层?
- 4、Docker的网络模式有哪些?
- 5、Docker 存储引擎
- 6、docker和kvm区别
1、Docker 中cmd add copy区别?
COPY 指令将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 <目标路径> 位置。
COPY abcdocker.json /usr/src/app/
ADD指令不仅能够将构建命令所在的主机本地的文件或目录,而且能够将远程URL所对应的文件或目录,作为资源复制到镜像文件系统。
所以,可以认为ADD是增强版的COPY,支持将远程URL的资源加入到镜像的文件系统。
2、请说一说Docker中Cgroups,namespace,unionFS?
1、Linux Cgroups全称[Linux Control Group]。它最主要的作用就是限制一个进程组能够使用的资源上限,包括CPU、内存、硬盘、网络带宽等
此外,Cgroup还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
Cgroups的每一项子系统都有其独有的资源限制能力
blkio,为块设备设置I/O限制,一般用于磁盘等设备
cpuset,为进程分配单独的CPU核和对应的内存节点
memory,为进程设定内存的使用限制
Linux Cgroups 就是一个子系统目录加上一组资源限制文件的组合。而对于Docker等Linux容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个子进程的PID填写到对应控制组的tasks文件中即可
而至于这些控制组下面的资源文件填什么,就靠用户执行docker run时的参数指定
#例如
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在启动这个容器之后,我们可以通过Cgroups文件系统下,CPU子系统中,docker这个控制组里的资源限制文件的内容来确认;
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
#这就意味着这个Docker容器,只能使用到20%的CPU带宽。
2、Linux Namespace
如果CGroup设计出来的目的是为了隔离物力资源,那么namespace则用来隔离PID,IPC,network等系统不同资源。不同的container内的进程属于不同的namespace,彼此透明,互不干扰。
| namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTC | CLONE_NEWUTS | 主机名和域名 |
| IPS | CLONE_NEWIPS | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS | 文件系统 |
| User | CLONE_NEWUSER | 用户、用户组 |
容器本质就是一个进程,用户的应用进程实际上就是容器PID=1的进程,也是其他后续创建的所有进程的父进程。这意味着,在一个容器中,无法同时运行两个不同的应用,除非可以事先找到一个公共的PID=1的程序来充当两个不同的父进程。
在Linux下的/proc目录存储是记录当前内核运行的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程信息,比如CPU使用资源、内存占用率等,这些文件也是top查看系统信息的主要数据来源。
但是,如果我们在容器执行top指令就会发现,它显示的信息是宿主机的CPU和内存数据,而不是当前容器的数据。造成这个问题的原因就是,/proc文件系统并不知道用户通过Cgroups给这个容器做了什么限制;针对这个问题可以通过以下方式解决
top是从/prof/stats目录下获取数据,做法是将宿主机的/var/lib/lxcfs/proc/memoinfo文件挂载到Docker容器的/proc/meminfo位置。
3、针对CGroup和namespace总结
Namespace的作用是隔离,它让应用进程只能看到该namespace内的世界;而Cgroup的作用是限制,它给这个世界围上了一圈看不到的墙。
4、Docker UnionFS
联合文件系统 (Union File System) 2004年由纽约州里大学石溪分校开发,它可以把多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的。UnionFS允许只读和可读写目录并存,就是说可以同时删除和增加内容。UnionFS的应用地方很多,比如在多个磁盘分区上合并不同文件系统的主目录,或把几张CD光盘合并成一个统一的光盘目录。另外,局域写时复制功能UnionFS可以把只读和可读写文件系统合并在一起。
3、容器的rootfs层?
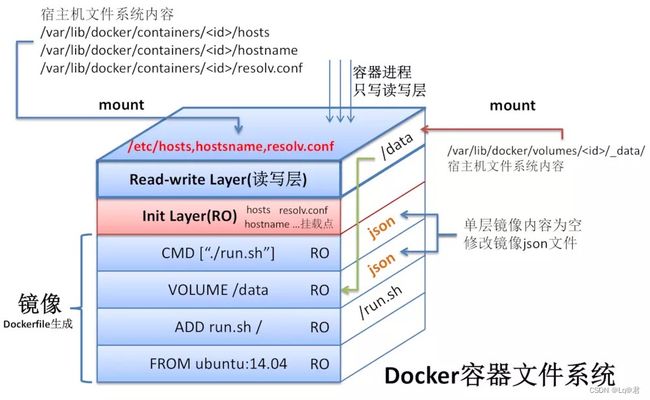
容器的rootfs(即layer)一共有8层
第一部分 只读层
它是容器rootfs最下面的6层,它们的挂载方式都是只读的。一般来说只读目录都会有whiteout属性
第二部分 init层
它是一个以-init结尾的层,夹在只读层和读写层之间。init层是Docker项目单独生成的一个内部层,专门用来存放/etc/hosts、/etc/resolv.conf等信息。需要这一层的原因是,这些文件本来属于只读的系统镜像层的一部分,但是用户往往需要在启动容器时写入一些特定的值,比如hostname,所以就需要在可读写层对它们进行修改。可是,这些修改往往只对当前的容器有效,我们并不希望之星docker commit时,把这些信息联通可读层一起提交。所以,docker做法是在修改了这些文件之后,以一个单独吃层挂载了出来。而用户执行docker commit只会提交可读层,所以不包含这些内容
第三部分 可读写层
它是这个容器的rootfs最上面一层,它的挂载方式为rw,即read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。删除ro-wh层等时,也会在rw层创建对应的whiteout文件,把只读层的文件遮挡起来。而当我们使用完这个被修改的容器之后,还可以使用docker commit和push指令,保存这个被修改过的可读层,并上传到hub,供其他人使用,而与此同时,原先的只读层的内容则不会有任何变化
- 最终,这8个层的都被联合挂载到/var/lib/docker/aufs/mnt目录下,表现为一个完整的操作系统和golang环境供容器使用
4、Docker的网络模式有哪些?
host模式,使用–net=host指定。
container模式,使用–net=container:NAME_or_ID指定。
none模式,使用–net=none指定。
bridge模式,使用–net=bridge指定,默认设置。
1、host模式
Docker使用的网络实际上和宿主机一样,在容器内看到的网卡ip是宿主机上的ip。
众所周知,Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等。一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable规则等都与其他的Network Namespace隔离。一个Docker容器一般会分配一个独立的Network Namespace。但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
2、container模式
多个容器使用共同的网络看到的ip是一样的。
在理解了host模式后,这个模式也就好理解了。这个模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。
3、none模式
这种模式下不会配置任何网络
这个模式和前两个不同。在这种模式下,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
4、bridge模式
bridge模式是Docker默认的网络设置,此模式会为每一个容器分配Network Namespace、设置IP等,并将一个主机上的Docker容器连接到一个虚拟网桥上。
类似于Vmware的nat网络模式。同一个宿主机上的所有容器会在同一个网段下,相互之间是可以通信的。
5、Docker 存储引擎
Docker最开始采用AUFS作为文件系统,也得益于AUFS分层的概念,实现了多个Container可以共享一个image。但是由于AUFS未并入Linux内核,且只支持Ubuntu,考虑到兼容性问题,在Docker 0.7 版本中引入了存储驱动,目前,Docker支持AUFS、Btrfs、Devicemapper、OverlayFS、ZFS五种存储驱动。
写时复制 (CoW)
所有驱动都用到的技术————写时复制,Cow全称copy-on-write,表示只是在需要写时才去复制,这个是针对已有文件的修改场景。比如基于一个image启动多个Container,如果每个Container都去分配一个image一样的文件系统,那么将会占用大量的磁盘空间。而CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。所以无论有多少个容器共享一个image,所做的写操作都是对从image中复制到自己的文件系统的副本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个副本,每个容器修改的都是自己的副本,互相隔离,互不影响。使用CoW可以有效的提高磁盘的利用率。
用时分配 (allocate-on-demand)
写是分配是用在原本没有这个文件的场景,只有在要新写入一个文件时才分配空间,这样可以提高存储资源的利用率。比如启动一个容器,并不会因为这个容器分配一些磁盘空间,而是当有新文件写入时,才按需分配新空间。
存储引擎介绍
1、AUFS
AUFS (AnotherUnionFS)是一种UnionFS,是文件级的存储驱动。AUFS能透明覆盖一或多个现有文件系统的层状文件系统,把多层合并成文件系统的单层表示。简单来说就是支持将不同目录挂载到同一个虚拟文件下的文件系统。这种文件系统可以一层一层地叠加修改文件。无论底下有多少层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS创建该文件的一个副本,使用CoW将文件从只读层复制到可写层进行修改,结果也保存在科协层。在Docker中,只读层就是image,可写层就是Container
2、OverlayFS
OverlayFS是一种和AUFS很类似的文件系统,与AUFS相比,OverlayFS有以下特性;
- 更简单地设计;
- 从Linux 3.18开始,就加入了Linux内核主线;
- 速度更快
因此,OverlayFS在Docker社区关注提高很快,被很多人认为是AUFS的继承者。Docker的overlay存储驱动利用了很多OverlayFS特性来构建和管理镜像与容器的磁盘结构
从Docker1.12起,Docker也支持overlay2存储驱动,相比于overlay来说,overlay2在inode优化上更加高效,但overlay2驱动只兼容Linux kernel4.0以上的版本
注意: 自从OverlayFS加入kernel主线后,它的kernel模块中的名称就从overlayfs改为overlay了
OverlayFS (overlay2)镜像分层与共享
overlay驱动只工作在一个lower OverlayFS层之上,因此需要硬链接来实现多层镜像,但overlay2驱动原生地支持多层lower OverlayFS镜像(最多128层)。因此overlay2驱动在合层相关的命令(如build何commit)中提供了更好的性能,与overlay驱动对比,减少了inode消耗
6、docker和kvm区别
Docker与虚拟机的本质区别:多个docker时,共享一个内核,这样访问底层硬件时,必然会互相影响,在一定时间内会有限制。