利用Radix tree基树进行IP地址的匹配
一 基树概念
Radix tree(也称为基树trie或紧凑trie)是一种空间优化的trie数据结构,用于存储关联数组,其中键是字符序列(例如,字符串或字节数组)。在基数树中,树中的每个节点表示一个或多个键的公共前缀,节点之间的边缘表示该前缀的扩展。由于它们的前缀共享,基数树可能比常规尝试更节省空间,特别是对于具有许多键共享公共前缀的数据集。注意:有的地方区分了Radix tree和Trie Tree,但是我觉得两者差不多,只是Radix Tree可以将多个字符分支叠加到一起,从而节省空间,如下图,不过我觉得这不影响问题的本质,只能算是一种压缩方式吧
 基树的例子
基树的例子
Radix tree的工作原理是在树上建立一个前缀树,并在每个节点上存储一个字符串前缀。当查询字符串时,它可以从根节点开始遍历,并与每个节点的前缀进行比较,直到找到符合的节点为止。
Radix tree的优势在于支持高效的存储和查询,并且比其他树形数据结构更加紧凑,因此它是内存敏感型应用的理想选择。
Radix tree在很多领域都有广泛应用,如网络安全,路由,网络管理,字典管理等。在这些领域中,Radix tree可以用于存储并查询IP地址,规则集等信息。 总的来说,Radix tree是一种高效的、紧凑的树形数据结构,在很多领域都有广泛的应用。它可以用于存储和查询各种信息,从而提高应用的性能和效率。
二 CIDR的基树实现
2.1 初始简单版本
我们在进行IDS或路由的时候,经常会进行IP的匹配,利用基树实现是一种比较好的方式,利用java代码实现如下:
import java.util.*;
class RadixNode {
int value;
Map children;
public RadixNode() {
children = new HashMap<>();
}
}
class RadixTree {
private RadixNode root;
public RadixTree() {
root = new RadixNode();
}
public void insert(String cidr) {
// 将CIDR格式切分成ip部分和网络地址的位数
String[] parts = cidr.split("/");
String[] ipParts = parts[0].split("\\.");
// 网络地址的位数
int prefixLength = Integer.parseInt(parts[1]);
// 获取mask
int mask = 0xffffffff << (32 - prefixLength);
RadixNode node = root;
for (int i = 0; i < ipParts.length; i++) {
// 对IP进行切分,每个元素都表示ip的一部分值
int b = Integer.parseInt(ipParts[i]);
int shift = 24 - 8 * i;
// 将每一部分进行移位 b & 0xff 更好的办法是和mask进行对应匹配
int key = (b & 0xff) << shift;
RadixNode child = node.children.get(key);
if (child == null) {
child = new RadixNode();
node.children.put(key, child);
}
node = child;
}
node.value = mask;
}
public int match(String ip) {
String[] ipParts = ip.split("\\.");
RadixNode node = root;
for (int i = 0; i < ipParts.length; i++) {
int b = Integer.parseInt(ipParts[i]);
int shift = 24 - 8 * i;
int key = (b & 0xff) << shift;
RadixNode child = node.children.get(key);
if (child == null) {
return 0;
}
node = child;
}
return node.value;
}
} 这个是对cidr进行简单的处理,将ipv4的代码按照点号切分后,每个部分,当作key存入到树中,叶子节点的值为mask的值。 代码还存在一些问题:
比如cidr必须严格按照子网掩码对ip取余后的再进行匹配。
上面直接定义HashMap来存储节点比较浪费内存。
测试代码:
RadixTree tree = new RadixTree();
tree.insert("192.168.2.0/24");
tree.insert("192.168.0.0/16");
int mask = tree.match("192.168.2.3");
System.out.println(Integer.toBinaryString(mask));大概形成的树是: 黄色部分为叶子节点,括号里面是存的值。
黄色部分为叶子节点,括号里面是存的值。
2.2 优化内存占用版本
上面版本利用hashmap来存储子节点,如果ip很多的话,会占用大量内存,我们可以改成简单点利用数组来存放,从而减少内存的占用
import java.util.*;
class RadixNode {
int value;
RadixNode[] children;
public RadixNode() {
// 每段IP的最大值
children = new RadixNode[256];
}
}
class RadixTree {
private RadixNode root;
public RadixTree() {
root = new RadixNode();
}
public void insert(String cidr) {
String[] parts = cidr.split("/");
String[] ipParts = parts[0].split("\\.");
int prefixLength = Integer.parseInt(parts[1]);
int mask = 0xffffffff << (32 - prefixLength);
RadixNode node = root;
for (int i = 0; i < ipParts.length; i++) {
int b = Integer.parseInt(ipParts[i]);
int shift = 24 - 8 * i;
int key = (b & 0xff) << shift;
RadixNode child = node.children[key];
if (child == null) {
child = new RadixNode();
node.children[key] = child;
}
node = child;
}
node.value = mask;
}
public int match(String ip) {
String[] ipParts = ip.split("\\.");
RadixNode node = root;
for (int i = 0; i < ipParts.length; i++) {
int b = Integer.parseInt(ipParts[i]);
int shift = 24 - 8 * i;
int key = (b & 0xff) << shift;
RadixNode child = node.children[key];
if (child == null) {
return 0;
}
node = child;
}
return node.value;
}
}这个版本只是将hashmap改成了数组形式,但是每个数组申请256个大小,在cidr比较少的时候,仍然占用比较多的内存,不一定会比hashmap少。
2.3 进一步优化内存占用版本
我们可以将ip转成字节数组,然后对每个bit值做判断,存放到左右子树中,从而进一步减少内存占用,代码如下:
class RadixNode {
int value;
RadixNode[] children;
public RadixNode() {
children = new RadixNode[2];
}
}
class RadixTree {
private RadixNode root;
public RadixTree() {
root = new RadixNode();
}
public void insert(String cidr) {
String[] parts = cidr.split("/");
String[] ipParts = parts[0].split("\\.");
int prefixLength = Integer.parseInt(parts[1]);
int mask = 0xffffffff << (32 - prefixLength);
RadixNode node = root;
for (int i = 0; i < 32; i++) {
int b = Integer.parseInt(ipParts[i / 8]);
int key = (b >> (7 - i % 8) & 1);
RadixNode child = node.children[key];
if (child == null) {
child = new RadixNode();
node.children[key] = child;
}
node = child;
}
node.value = mask;
}
public int match(String ip) {
String[] ipParts = ip.split("\\.");
RadixNode node = root;
for (int i = 0; i < 32; i++) {
int b = Integer.parseInt(ipParts[i / 8]);
int key = (b >> (7 - i % 8) & 1);
RadixNode child = node.children[key];
if (child == null) {
return 0;
}
node = child;
}
return node.value;
}
}其中核心代码在于:
for (int i = 0; i < 32; i++) {
int b = Integer.parseInt(ipParts[i / 8]);
int key = (b >> (7 - i % 8) & 1);
RadixNode child = node.children[key];
if (child == null) {
return 0;
}
node = child;
}对于ipv4来说,我们可以看成四个字节的整数,所以一共占用4*8=32个bit,对于每一位获取的办法是: int b = Integer.parseInt(ipParts[i / 8]); 先通过这个i/8的办法得到具体的字节、然后进入关键代码: key的计算, int key = (b >> (7 - i % 8) & 1); 将获得到具体的字节值,右移动(7 - i % 8) 位再和1求与,得到的值要么为0要么为1,根据这个再决定在哪个子树上。
三 基树应用
3.1 suricata中基树应用
Suricata 是一个开源入侵检测系统 (IDS),它在规则处理中使用基数树进行 IP 地址匹配。在 Suricata 中,基数树用于存储 IP 地址和 CIDR 范围,以便在规则匹配过程中进行高效查找。这使 Suricata 能够快速确定给定的 IP 地址或网络流量是否与特定规则匹配,从而减少规则匹配所需的时间。
在 Suricata 中,基数树与其他技术(如模式匹配和规则分组)结合使用,以提供全面高效的规则匹配过程。基数树的使用使 Suricata 能够实时处理大量规则,使其成为需要快速可靠的 IDS 系统的网络安全管理员的热门选择。
Suricata 在规则中处理 IPv6 的方式与处理 IPv4 的方式类似,通过使用基数树进行高效查找。Suricata 中的基数树能够存储 IPv4 和 IPv6 地址,并且对于这两种类型的地址,树的构造方式相同。
简单仿照suricata的基树实现:
public class RadixTree2 {
private RadixTreeNode root;
public RadixTree2() {
root = new RadixTreeNode();
}
public void insert(String cidr) {
String[] parts = cidr.split("/");
String ipAddress = parts[0];
int prefixLength = Integer.parseInt(parts[1]);
byte[] address = null;
if (!ipAddress.contains(":")) {
address = ip4AddressToBytes(ipAddress);
}else {
address = ip6AddressToBytes(ipAddress);
}
RadixTreeNode node = root;
for (int i = 0; i < prefixLength; i++) {
int index = (address[i / 8] >> (7 - (i % 8))) & 1;
if (!node.children.containsKey(index)) {
node.children.put(index, new RadixTreeNode());
}
node = node.children.get(index);
}
node.cidrs.add(cidr);
}
public List match(String ipAddress) {
byte[] address = null;
if (!ipAddress.contains(":")) {
address = ip4AddressToBytes(ipAddress);
}else {
address = ip6AddressToBytes(ipAddress);
}
RadixTreeNode node = root;
for (int i = 0; i < address.length * 8; i++) {
int index = (address[i / 8] >> (7 - (i % 8))) & 1;
if (!node.children.containsKey(index)) {
break;
}
node = node.children.get(index);
}
return node.cidrs;
}
private byte[] ip4AddressToBytes(String ipAddress) {
String[] parts = ipAddress.split("\\.");
if (parts.length == 4) {
byte[] address = new byte[4];
for (int i = 0; i < 4; i++) {
address[i] = (byte) Integer.parseInt(parts[i]);
}
return address;
} else {
// TODO: Add support for IPv6
return new byte[0];
}
}
private byte[] ip6AddressToBytes(String ipAddress) {
String[] parts = ipAddress.split(":");
if (parts.length == 8) {
byte[] address = new byte[16];
for (int i = 0; i < 8; i++) {
int x = Integer.parseInt(parts[i], 16);
address[i * 2] = (byte) (x >> 8);
address[i * 2 + 1] = (byte) x;
}
return address;
} else if (parts.length == 4) {
byte[] address = new byte[4];
for (int i = 0; i < 4; i++) {
address[i] = (byte) Integer.parseInt(parts[i]);
}
return address;
} else {
throw new IllegalArgumentException("Invalid IP address format");
}
}
private class RadixTreeNode {
Map children;
List cidrs;
public RadixTreeNode() {
children = new HashMap<>();
cidrs = new ArrayList<>();
}
}
public static void main(String[] args) {
RadixTree2 tree = new RadixTree2();
// IPv4 CIDRs
tree.insert("192.168.0.0/24");
tree.insert("192.168.2.0/24");
// IPv6 CIDRs
tree.insert("2001:0db8:85a3:0000:0000:8a2e:0370:7334/64");
tree.insert("2001:0db8:85a3:0000:0000:8a2e:0370:7336/64");
// IPv4 match
List result = tree.match("192.168.2.3");
System.out.println("IPv4 match: " + result);
// IPv6 match
result = tree.match("2001:0db8:85a3:0000:0000:8a2e:0370:7336");
System.out.println("IPv6 match: " + result);
}
} 里面用手写的方式实现了ipv4和ipv6的地址转换,不支持缩写形式,节点的数据保存采用list保存数据、 子节点采用hashmap。
3.2 代码改进版本
将ipv4和ipv6的转成字节数组采用库函数方式,将hashmap改成数组,就有了一下代码:
import java.net.InetAddress;
import java.util.HashMap;
import java.util.Map;
public class RadixTree3 {
private Node root;
public RadixTree3() {
root = new Node();
}
public void insert(String cidr) throws Exception {
String[] parts = cidr.split("/");
String ipAddress = parts[0];
int prefixLength = Integer.parseInt(parts[1]);
byte[] ipBytes = InetAddress.getByName(ipAddress).getAddress();
Node node = root;
for (int i = 0; i < prefixLength; i++) {
int bit = (ipBytes[i / 8] >> (7 - i % 8)) & 1;
if (node.children[bit] == null) {
node.children[bit] = new Node();
}
node = node.children[bit];
}
node.isLeaf = true;
node.prefixLength = prefixLength;
}
public boolean search(String ipAddress) throws Exception {
byte[] ipBytes = InetAddress.getByName(ipAddress).getAddress();
Node node = root;
for (int i = 0; i < (ipBytes.length * 8); i++) {
int bit = (ipBytes[i / 8] >> (7 - i % 8)) & 1;
if (node.children[bit] == null) {
break;
}
node = node.children[bit];
}
if (!node.isLeaf) {
return false;
}
return true;
}
private static class Node {
private Node[] children;
private boolean isLeaf;
private int prefixLength;
public Node() {
children = new Node[2];
isLeaf = false;
}
}
public static void main(String[] args) throws Exception {
RadixTree3 tree = new RadixTree3();
tree.insert("192.168.0.0/16");
tree.insert("192.168.2.0/24");
System.out.println(tree.search("192.168.2.3")); // true
System.out.println(tree.search("192.168.3.3")); // false
tree.insert("2001:0db8:85a3:0000:0000:8a2e:0370:7334/64");
System.out.println(tree.search("2001:0db8:85a3:0000:0000:8a2e:0370:7334")); // true
}
}代码并不复杂,采用左右分支两个元素的数组来存储bit的分支,代码里面没有存数据,只是对是否满足匹配做了个判断,如果查询到叶子节点则匹配,否则不匹配,在我们的生产应用中,很容易改造成带数据的基树,这样存储起来、查询性能还是挺好的。
整体的原理就是将ip转成字节数组,然后对每个bit做判断,如果是0则存在数组为0的位置,可以认为为左子树,如果为1则存数组为1的位置,可以认为为右子树,如下图: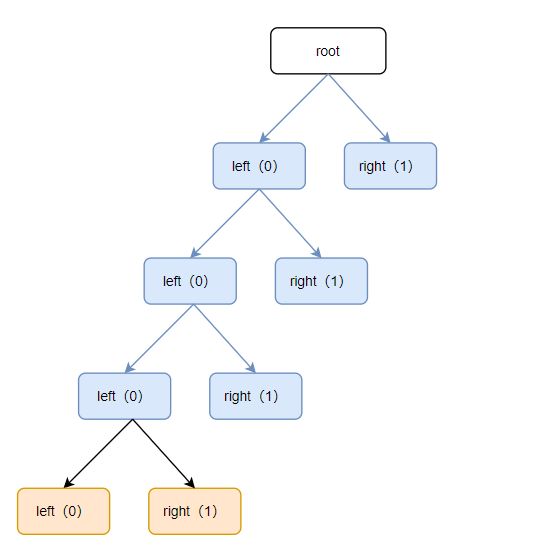
三 总结
对于字符串的一般查找来说,红黑树、哈希表等数据结构都可以很好的满足一般需求,Radix tree可以节省内存,另外对于前缀搜索性能比较好,因为搜索不中的话,可以回溯到父节点继续查找。