Easter2.0:tensorflow源码转pytorch
论文题目:Easter2.0: IMPROVING CONVOLUTIONAL MODELS FORHANDWRITTEN TEXT RECOGNITION
论文地址:https://arxiv.org/pdf/2205.14879.pdf
论文源码:GitHub - kartikgill/Easter2: Easter2.0: IMPROVING CONVOLUTIONAL MODELS FOR HANDWRITTEN TEXT RECOGNITION
一、为啥转?!
因为我看了论文之后,有点想法,想做做实验,改一改,弄一弄创新点,但是我转成pytorch的格式之后(可以进行训练了),我师兄过来看了这篇论文说:“阿三的论文别看,速跑!”,我之前都没看作者,直接看的论文,真的是印度阿三的,可恶啊!然后我就跑了,弄其他论文的了,这个很粗糙的pytorch版本(测试的代码没写,只有训练和验证的阶段),我就放出来了,你们有需要自取吧,请不要嫌弃,自己拿去改一改吧!!
二、代码架构
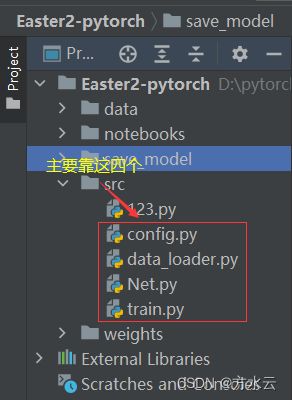
1.文件放置

这是我的文件目录,可进行参照,以保证能正确运行!!!以下进行详细讲解!!!



2. 具体代码
①config.py
我照搬源码的文件,里面我有些用到,有些没用到,赶时间跑训练,懒的改。
"""
Before training and evaluation - make sure to select desired/correct settings
我看了看都是相对路径,啥也不用改
"""
# Input dataset related settings
DATA_PATH = "../data/"
INPUT_HEIGHT = 80
INPUT_WIDTH = 2000
INPUT_SHAPE = (INPUT_HEIGHT, INPUT_WIDTH)
TACO_AUGMENTAION_FRACTION = 0.9
# If Long lines augmentation is needed (see paper)
LONG_LINES = True #把两行做行拼接之后再做数据增强
LONG_LINES_FRACTION = 0.3 #30%的可能性干这个事
# Model training parameters
BATCH_SIZE = 32
EPOCHS = 1000
VOCAB_SIZE = 80
DROPOUT = True
OUTPUT_SHAPE = 500
# Initializing weights from pre-trained
LOAD = True
LOAD_CHECKPOINT_PATH = "../weights/saved_checkpoint.hdf5"
# Other learning parametes
LEARNING_RATE = 0.01
BATCH_NORM_EPSILON = 1e-5
BATCH_NORM_DECAY = 0.997
# Checkpoints parametes
CHECKPOINT_PATH = '../weights/EASTER2--{epoch:02d}--{loss:.02f}.hdf5'
LOGS_DIR = '../logs'
BEST_MODEL_PATH = "../weights/saved_checkpoint.hdf5"②data_loader.py
"""数据加载部分,主要是改维度,我就奇怪了tensorflow和pytorch一维卷积的通道索引竟然不同"""
"""存心要改死我是吧"""
import pandas as pd
import numpy as np
import cv2
import random
import itertools, os, time
import config
import matplotlib.pyplot as plt
from tacobox import Taco
class Sample:
"sample from the dataset"
def __init__(self, gtText, filePath):
self.gtText = gtText
self.filePath = filePath
class data_loader:
def __init__(self, path, batch_size):
self.batchSize = batch_size
self.samples = []
self.currIdx = 0
self.charList = []
# creating taco object for augmentation (checkout Easter2.0 paper)
self.mytaco = Taco(
cp_vertical=0.2,
cp_horizontal=0.25,
max_tw_vertical=100,
min_tw_vertical=10,
max_tw_horizontal=50,
min_tw_horizontal=10
)
f = open(path + 'lines.txt')
chars = set()
for line in f:
if not line or line[0] == '#':
continue
lineSplit = line.strip().split(' ')
assert len(lineSplit) >= 9
fileNameSplit = lineSplit[0].split('-')
fileName = path + 'lines/' + fileNameSplit[0] + '/' + \
fileNameSplit[0] + '-' + fileNameSplit[1] + '/' + lineSplit[0] + '.png'
gtText = lineSplit[8].strip(" ").replace("|", " ")
chars = chars.union(set(list(gtText)))
self.samples.append(Sample(gtText, fileName))
train_folders = [x.strip("\n") for x in open(path + "LWRT/train.uttlist").readlines()]
validation_folders = [x.strip("\n") for x in open(path + "LWRT/validation.uttlist").readlines()]
test_folders = [x.strip("\n") for x in open(path + "LWRT/test.uttlist").readlines()]
self.trainSamples = []
self.validationSamples = []
self.testSamples = []
for i in range(0, len(self.samples)):
file = self.samples[i].filePath.split("/")[-1][:-4].strip(" ")
folder = "-".join(file.split("-")[:-1])
if (folder in train_folders):
self.trainSamples.append(self.samples[i])
elif folder in validation_folders:
self.validationSamples.append(self.samples[i])
elif folder in test_folders:
self.testSamples.append(self.samples[i])
self.trainSet()
self.charList = sorted(list(chars))
def trainSet(self):
self.currIdx = 0
random.shuffle(self.trainSamples)
self.samples = self.trainSamples
def validationSet(self):
self.currIdx = 0
self.samples = self.validationSamples
def testSet(self):
self.currIdx = 0
self.samples = self.testSamples
def getIteratorInfo(self):
return (self.currIdx // self.batchSize + 1, len(self.samples) // self.batchSize)
def hasNext(self):
return self.currIdx + self.batchSize <= len(self.samples)
def preprocess(self, img, augment=True):
if augment:
img = self.apply_taco_augmentations(img)
# scaling image [0, 1]
img = img / 255
# img = img.swapaxes(-2, -1)[..., ::-1]
target = np.ones((config.INPUT_HEIGHT, config.INPUT_WIDTH))
new_x = config.INPUT_HEIGHT / img.shape[0]
new_y = config.INPUT_WIDTH / img.shape[1]
min_xy = min(new_x, new_y)
new_x = int(img.shape[0] * min_xy)
new_y = int(img.shape[1] * min_xy)
img2 = cv2.resize(img, (new_y, new_x))
target[:new_x, :new_y] = img2
return 1 - (target)
def apply_taco_augmentations(self, input_img):
random_value = random.random()
if random_value <= config.TACO_AUGMENTAION_FRACTION:
augmented_img = self.mytaco.apply_vertical_taco(
input_img,
corruption_type='random'
)
else:
augmented_img = input_img
return augmented_img
def GetNext(self):
while True:
if ((self.currIdx + self.batchSize) <= len(self.samples)):
itr = self.getIteratorInfo()
batchRange = range(self.currIdx, self.currIdx + self.batchSize)
if config.LONG_LINES:
random_batch_range = random.choices(range(0, len(self.samples)), k=self.batchSize)
gtTexts = np.ones([self.batchSize, config.OUTPUT_SHAPE])
input_length = np.ones((self.batchSize, 1)) * config.OUTPUT_SHAPE
label_length = np.zeros((self.batchSize, 1))
imgs = np.ones([self.batchSize, config.INPUT_HEIGHT, config.INPUT_WIDTH])
j = 0
for ix, i in enumerate(batchRange):
img = cv2.imread(self.samples[i].filePath, cv2.IMREAD_GRAYSCALE)
if img is None:
img = np.zeros([config.INPUT_HEIGHT, config.INPUT_WIDTH])
text = self.samples[i].gtText
if config.LONG_LINES:
if random.random() <= config.LONG_LINES_FRACTION:#把两个行级文本变成更长的文本,阈值好像是0.3吧,记错了别骂我!
index = random_batch_range[ix]
img2 = cv2.imread(self.samples[index].filePath, cv2.IMREAD_GRAYSCALE)
if img2 is None:
img2 = np.zeros([config.INPUT_HEIGHT, config.INPUT_WIDTH])
text2 = self.samples[index].gtText
avg_w = (img.shape[1] + img2.shape[1]) // 2
avg_h = (img.shape[0] + img2.shape[0]) // 2
resized1 = cv2.resize(img, (avg_w, avg_h))
resized2 = cv2.resize(img2, (avg_w, avg_h))
space_width = random.randint(config.INPUT_HEIGHT // 4, 2 * config.INPUT_HEIGHT)
space = np.ones((avg_h, space_width)) * 255
img = np.hstack([resized1, space, resized2])
text = text + " " + text2
if len(self.samples) < 3000: # FOR VALIDATION AND TEST SETS
eraser = -1
img = self.preprocess(img)
imgs[j] = img
val = list(map(lambda x: self.charList.index(x), text))
while len(val) < config.OUTPUT_SHAPE:
val.append(len(self.charList))
gtTexts[j] = (val)
label_length[j] = len(text)
input_length[j] = config.OUTPUT_SHAPE
j = j + 1
# if False:
# plt.figure(figsize=(20, 20))
# plt.imshow(img)
# plt.show()
self.currIdx += self.batchSize
inputs = {
'the_input': imgs,
'the_labels': gtTexts,
'input_length': input_length,
'label_length': label_length,
}
# outputs = {'ctc': np.zeros([self.batchSize])}
return inputs #(inputs, outputs)
else:
self.currIdx = 0
def getValidationImage(self):
batchRange = range(0, len(self.samples))
imgs = []
texts = []
reals = []
for i in batchRange:
img1 = cv2.imread(self.samples[i].filePath, cv2.IMREAD_GRAYSCALE)
real = cv2.imread(self.samples[i].filePath)
if img1 is None:
img1 = np.zeros([config.INPUT_HEIGHT, config.INPUT_WIDTH])
img = self.preprocess(img1, augment=False)
img = np.expand_dims(img, 0)
text = self.samples[i].gtText
imgs.append(img)
texts.append(text)
reals.append(real)
self.currIdx += self.batchSize
return imgs, texts, reals
def getTestImage(self):
batchRange = range(0, len(self.samples))
imgs = []
texts = []
reals = []
for i in batchRange:
img1 = cv2.imread(self.samples[i].filePath, cv2.IMREAD_GRAYSCALE)
real = cv2.imread(self.samples[i].filePath)
if img1 is None:
img1 = np.zeros([config.INPUT_HEIGHT, config.INPUT_WIDTH])
img = self.preprocess(img1, augment=False)
img = np.expand_dims(img, 0)
text = self.samples[i].gtText
imgs.append(img)
texts.append(text)
reals.append(real)
self.currIdx += self.batchSize
return imgs, texts, reals③Net.py
"""就是网络的构架呗,可以去看论文"""
import torch
import config
from torch import nn
from torchvision import models
from torchsummary import summary
class GlobalContext(nn.Module):
def __init__(self, filters):
super(GlobalContext, self).__init__()
self.pool = nn.AdaptiveAvgPool1d(1)
self.fc1 = nn.Linear(filters, filters // 8)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(filters // 8, filters)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
batch_size, channels, timesteps = x.size()
# Average pooling over time dimension
y = self.pool(x).view(batch_size, channels)
# Two fully connected layers with ReLU activation and sigmoid activation
y = self.fc1(y)
y = self.relu(y)
y = self.fc2(y)
y = self.sigmoid(y)
# Reshape to make it broadcastable element-wise with input tensor x
y = y.view(batch_size, channels, 1)
# Scale input tensor x with output of SE block
z = torch.mul(x, y)
return z
class easter_unit(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, dropout):
super(easter_unit, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm1d(out_channels),
)
self.layer2 = nn.Sequential(
nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=(kernel_size - 1) // 2),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.Dropout(dropout),
)
self.layer3 = nn.Sequential(
nn.Conv1d(in_channels=out_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=(kernel_size - 1) // 2),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.Dropout(dropout),
)
self.layer4 = nn.Sequential(
nn.Conv1d(in_channels=out_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=(kernel_size - 1) // 2),
nn.BatchNorm1d(out_channels),
)
self.global_context = GlobalContext(out_channels)
self.layer5 = nn.Sequential(
nn.ReLU(),
nn.Dropout(dropout),
)
def forward(self, old, data):
old = self.layer1(old)
this = self.layer1(data)
old = old + this
data = self.layer2(data)
data = self.layer3(data)
data = self.layer4(data)
data = self.global_context(data)
final = old + data
data = self.layer5(final)
return data, old
class Visual_Model(nn.Module):
def __init__(self):
super(Visual_Model, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv1d(in_channels=config.INPUT_SHAPE[0], out_channels=128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.2),
)
self.layer2 = nn.Sequential(
nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.2),
)
self.easter_unit1 = easter_unit(128, 256, 5, 1, 0.2)
self.easter_unit2 = easter_unit(256, 256, 7, 1, 0.2)
self.easter_unit3 = easter_unit(256, 256, 9, 1, 0.3)
self.layer3 = nn.Sequential(
nn.Conv1d(in_channels=256, out_channels=512, kernel_size=11, stride=1, padding=10, dilation=2),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.4),
)
self.layer4 = nn.Sequential(
nn.Conv1d(in_channels=512, out_channels=512, kernel_size=1, stride=1, padding=0),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.4),
)
self.layer5 = nn.Sequential(
nn.Conv1d(in_channels=512, out_channels=config.VOCAB_SIZE, kernel_size=1, stride=1, padding=0),
nn.Softmax(dim=1),
)
def forward(self, data):
data = self.layer1(data)
data = self.layer2(data)
old = data
data, old = self.easter_unit1(old, data)
data, old = self.easter_unit2(old, data)
data, old = self.easter_unit3(old, data)
data = self.layer3(data)
data = self.layer4(data)
y_pred = self.layer5(data)
return y_pred④train.py
"""训练+验证:训练一轮,验证一轮,验证指标是CER,可看论文"""
import torch
from torch import nn
from tqdm import tqdm
from Net import Visual_Model
import config
from data_loader import data_loader
from torchvision import datasets, transforms
from torch.optim import lr_scheduler
import os
import itertools
import numpy
from editdistance import eval as edit_distance
def ctc_custom(args): #这个pytorch版本的ctc_loss跟源码tensorflow版本的ctc_loss不太一样,输入张量的维度不一样先不说,感觉两个版本在相同输入下的输出也不太一样,我测试了好久好久,最后放弃了,直觉告诉我这里有问题,信我!!!!
"""
custom CTC loss
"""
y_pred, labels, input_length, label_length = args
ctc_loss = torch.nn.functional.ctc_loss(
y_pred.permute(2,0,1).log_softmax(2),
labels,
input_length,
label_length,
blank=0,
zero_infinity=True
)
p = torch.exp(-ctc_loss)
gamma = 0.5
alpha = 0.25
return alpha * (torch.pow((1-p),gamma)) * ctc_loss
#查看数据集的长度--数量
training_data = data_loader(config.DATA_PATH, config.BATCH_SIZE)
validation_data = data_loader(config.DATA_PATH, config.BATCH_SIZE)
training_data.trainSet()
validation_data.validationSet()
print("Training Samples : ", len(training_data.samples))
print("Validation Samples : ", len(validation_data.samples))
print("CharList Size : ", len(training_data.charList))
STEPS_PER_EPOCH = len(training_data.samples) // config.BATCH_SIZE
# 将网络模型传入到GPU中
model = Visual_Model()
model = model#.cuda() #将模型传入CPU或者GPU自己改,去掉#即可
# 定义一个优化器
optimizer = torch.optim.Adam(model.parameters(), lr=config.LEARNING_RATE) #优化参数
# 每隔100轮学习率变为原来的0.6倍
scheduler = lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.6)
# 定义训练模型
def train(training_data, model, optimizer):
for i in range(STEPS_PER_EPOCH):
inputs = training_data.GetNext()
imgs = inputs['the_input']
gtTexts = inputs['the_labels']
input_length = inputs['input_length']
label_length = inputs['label_length']
imgs = torch.from_numpy(imgs) #tensorflow的numpy 和 pytorch的tensor 改死我了
imgs = torch.as_tensor(imgs, dtype=torch.float32)
gtTexts = torch.from_numpy(gtTexts)
imgs = imgs#.cuda() #传入CPU或者GPU自己改,去掉#即可
y_pred = model(imgs)
input_length = torch.from_numpy(input_length)
input_length = input_length.long()
label_length = torch.from_numpy(label_length)
label_length = label_length.long()
args = y_pred, gtTexts, input_length, label_length
cur_loss = ctc_custom(args)#.cuda() #传入CPU或者GPU自己改,去掉#即可
optimizer.zero_grad() #梯度清零
cur_loss.backward() #损失反向传播
optimizer.step() #梯度更
print(" {}/{}------------------->train_loss: {} ".format(i+1, STEPS_PER_EPOCH, cur_loss.item()))
def decoder(output,letters): #解码
ret = []
for j in range(output.shape[0]):
out_best = list(torch.argmax(output[j,:], 0))
out_best = [k for k, g in itertools.groupby(out_best)]
outstr = ''
for c in out_best:
if c < len(letters):
outstr += letters[c]
ret.append(outstr)
return ret
#验证函数,不需要更新梯度
def val(validation_data, model):
char_error = 0
total_chars = 0
charlist = training_data.charList
model.eval() #验证模式
with torch.no_grad():
imgs, truths, _ = validation_data.getValidationImage()
print ("Number of Samples : ",len(imgs))
for i in tqdm(range(0, len(imgs))):
img = imgs[i]
truth = truths[i].strip(" ").replace(" ", " ")
img = torch.from_numpy(img)
img = torch.as_tensor(img, dtype=torch.float32)
imgs = imgs#.cuda() #传入CPU或者GPU自己改,去掉#即可
output = model(img)
prediction = decoder(output, charlist)
output = (prediction[0].strip(" ").replace(" ", " "))
char_error += edit_distance(output, truth)
total_chars += len(truth)
print("Character error rate is : ", (char_error / total_chars) * 100)
#开始训练
for i in range(config.EPOCHS):
print("epoch->{}".format(i+1)+"\n----------------------------")
train(training_data, model, optimizer)
val(validation_data, model)
scheduler.step()
torch.save(model.state_dict(), "../save_model/best_model.pth")#可以按照最好的CER来保存模型参数,我懒的写了
print("done")三、结语
反正我这次代码写的有点糙,主要是我能看的顺,你们可以参考参考,自己写出自己风格的代码。另外,代码的注释挺少的,主要因为实验不做了,代码白改了,有点心累,不想写注释了,原谅我吧!最后,我跑了几轮,错误率都是100%,可能那些地方需要细细调整,你们可以按照自己的想法来,建议全程debug一遍。最后的最后,我还是觉得ctc_loss有问题,相信我的直觉!!
写完了,可恶,还有一篇更长的MAE失败实验没写多少啊,真滴不想写啊!!救命!!!