强化学习——多臂老虎机
2.1 简介
我们在第 1 章中了解到,强化学习关注智能体和环境交互过程中的学习,这是一种试错型学习(trial-and-error learning)范式。在正式学习强化学习之前,我们需要先了解多臂老虎机问题,它可以被看作简化版的强化学习问题。与强化学习不同,多臂老虎机不存在状态信息,只有动作和奖励,算是最简单的“和环境交互中的学习”的一种形式。多臂老虎机中的探索与利用(exploration vs. exploitation)问题一直以来都是一个特别经典的问题,理解它能够帮助我们学习强化学习。
2.2 问题介绍
2.2.1 问题定义
在多臂老虎机(multi-armed bandit,MAB)问题中,有一个拥有K根拉杆的老虎机,拉动每一根拉杆都对应一个关于奖励的概率分布R 。我们每次拉动其中一根拉杆,就可以从该拉杆对应的奖励概率分布中获得一个奖励 。我们在各根拉杆的奖励概率分布未知的情况下,从头开始尝试,目标是在操作T次拉杆后获得尽可能高的累积奖励。由于奖励的概率分布是未知的,因此我们需要在“探索拉杆的获奖概率”和“根据经验选择获奖最多的拉杆”中进行权衡。“采用怎样的操作策略才能使获得的累积奖励最高”便是多臂老虎机问题。如果是你,会怎么做呢?

2.2.2 形式化描述

2.2.3 累积懊悔

2.2.4 估计期望奖励
为了知道拉动哪一根拉杆能获得更高的奖励,我们需要估计拉动这根拉杆的期望奖励。由于只拉动一次拉杆获得的奖励存在随机性,所以需要多次拉动一根拉杆,然后计算得到的多次奖励的期望,其算法流程如下所示。

以上 for 循环中的第四步如此更新估值,是因为这样可以进行增量式的期望更新,公式如下。
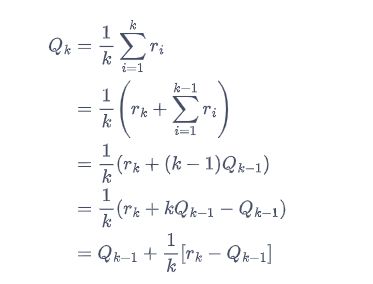
如果将所有数求和再除以次数,其缺点是每次更新的时间复杂度和空间复杂度均为O(n) 。而采用增量式更新,时间复杂度和空间复杂度均为O(1) 。
下面我们编写代码来实现一个拉杆数为 10 的多臂老虎机。其中拉动每根拉杆的奖励服从伯努利分布(Bernoulli distribution),即每次拉下拉杆有P的概率获得的奖励为 1,有1-P的概率获得的奖励为 0。奖励为 1 代表获奖,奖励为 0 代表没有获奖。
# 导入需要使用的库,其中numpy是支持数组和矩阵运算的科学计算库,而matplotlib是绘图库
import numpy as np
import matplotlib.pyplot as plt
class BernoulliBandit:
""" 伯努利多臂老虎机,输入K表示拉杆个数 """
def __init__(self, K):
self.probs = np.random.uniform(size=K) # 随机生成K个0~1的数,作为拉动每根拉杆的获奖
# 概率
self.best_idx = np.argmax(self.probs) # 获奖概率最大的拉杆
self.best_prob = self.probs[self.best_idx] # 最大的获奖概率
self.K = K
def step(self, k):
# 当玩家选择了k号拉杆后,根据拉动该老虎机的k号拉杆获得奖励的概率返回1(获奖)或0(未
# 获奖)
if np.random.rand() < self.probs[k]:
return 1
else:
return 0
np.random.seed(1) # 设定随机种子,使实验具有可重复性
K = 10
bandit_10_arm = BernoulliBandit(K)
print("随机生成了一个%d臂伯努利老虎机" % K)
print("获奖概率最大的拉杆为%d号,其获奖概率为%.4f" %
(bandit_10_arm.best_idx, bandit_10_arm.best_prob))随机生成了一个10臂伯努利老虎机
获奖概率最大的拉杆为1号,其获奖概率为0.7203
接下来我们用一个 Solver 基础类来实现上述的多臂老虎机的求解方案。根据前文的算法流程,我们需要实现下列函数功能:根据策略选择动作、根据动作获取奖励、更新期望奖励估值、更新累积懊悔和计数。在下面的 MAB 算法基本框架中,我们将根据策略选择动作、根据动作获取奖励和更新期望奖励估值放在 run_one_step() 函数中,由每个继承 Solver 类的策略具体实现。而更新累积懊悔和计数则直接放在主循环 run() 中。
class Solver:
""" 多臂老虎机算法基本框架 """
def __init__(self, bandit):
self.bandit = bandit
self.counts = np.zeros(self.bandit.K) # 每根拉杆的尝试次数
self.regret = 0. # 当前步的累积懊悔
self.actions = [] # 维护一个列表,记录每一步的动作
self.regrets = [] # 维护一个列表,记录每一步的累积懊悔
def update_regret(self, k):
# 计算累积懊悔并保存,k为本次动作选择的拉杆的编号
self.regret += self.bandit.best_prob - self.bandit.probs[k]
self.regrets.append(self.regret)
def run_one_step(self):
# 返回当前动作选择哪一根拉杆,由每个具体的策略实现
raise NotImplementedError
def run(self, num_steps):
# 运行一定次数,num_steps为总运行次数
for _ in range(num_steps):
k = self.run_one_step()
self.counts[k] += 1
self.actions.append(k)
self.update_regret(k)2.3 探索与利用的平衡
在 2.2 节的算法框架中,还没有一个策略告诉我们应该采取哪个动作,即拉动哪根拉杆,所以接下来我们将学习如何设计一个策略。例如,一个最简单的策略就是一直采取第一个动作,但这就非常依赖运气的好坏。如果运气绝佳,可能拉动的刚好是能获得最大期望奖励的拉杆,即最优拉杆;但如果运气很糟糕,获得的就有可能是最小的期望奖励。在多臂老虎机问题中,一个经典的问题就是探索与利用的平衡问题。探索(exploration)是指尝试拉动更多可能的拉杆,这根拉杆不一定会获得最大的奖励,但这种方案能够摸清楚所有拉杆的获奖情况。例如,对于一个 10 臂老虎机,我们要把所有的拉杆都拉动一下才知道哪根拉杆可能获得最大的奖励。利用(exploitation)是指拉动已知期望奖励最大的那根拉杆,由于已知的信息仅仅来自有限次的交互观测,所以当前的最优拉杆不一定是全局最优的。例如,对于一个 10 臂老虎机,我们只拉动过其中 3 根拉杆,接下来就一直拉动这 3 根拉杆中期望奖励最大的那根拉杆,但很有可能期望奖励最大的拉杆在剩下的 7 根当中,即使我们对 10 根拉杆各自都尝试了 20 次,发现 5 号拉杆的经验期望奖励是最高的,但仍然存在着微小的概率—另一根 6 号拉杆的真实期望奖励是比 5 号拉杆更高的。
于是在多臂老虎机问题中,设计策略时就需要平衡探索和利用的次数,使得累积奖励最大化。一个比较常用的思路是在开始时做比较多的探索,在对每根拉杆都有比较准确的估计后,再进行利用。目前已有一些比较经典的算法来解决这个问题,例如-贪婪算法、上置信界算法和汤普森采样算法等,我们接下来将分别介绍这几种算法。
2.4 ϵ-贪心算法

class EpsilonGreedy(Solver):
""" epsilon贪婪算法,继承Solver类 """
def __init__(self, bandit, epsilon=0.01, init_prob=1.0):
super(EpsilonGreedy, self).__init__(bandit)
self.epsilon = epsilon
#初始化拉动所有拉杆的期望奖励估值
self.estimates = np.array([init_prob] * self.bandit.K)
def run_one_step(self):
if np.random.random() < self.epsilon:
k = np.random.randint(0, self.bandit.K) # 随机选择一根拉杆
else:
k = np.argmax(self.estimates) # 选择期望奖励估值最大的拉杆
r = self.bandit.step(k) # 得到本次动作的奖励
self.estimates[k] += 1. / (self.counts[k] + 1) * (r - self.estimates[k])
return k为了更加直观地展示,可以把每一时间步的累积函数绘制出来。于是我们定义了以下绘图函数,方便之后调用。
def plot_results(solvers, solver_names):
"""生成累积懊悔随时间变化的图像。输入solvers是一个列表,列表中的每个元素是一种特定的策略。
而solver_names也是一个列表,存储每个策略的名称"""
for idx, solver in enumerate(solvers):
time_list = range(len(solver.regrets))
plt.plot(time_list, solver.regrets, label=solver_names[idx])
plt.xlabel('Time steps')
plt.ylabel('Cumulative regrets')
plt.title('%d-armed bandit' % solvers[0].bandit.K)
plt.legend()
plt.show()
np.random.seed(1)
epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
epsilon_greedy_solver.run(5000)
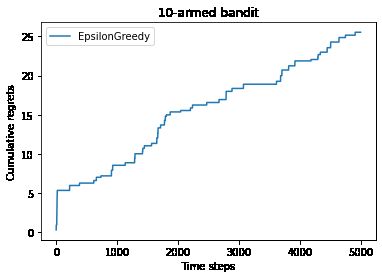
print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
plot_results([epsilon_greedy_solver], ["EpsilonGreedy"])psilon-贪婪算法的累积懊悔为:25.526630933945313

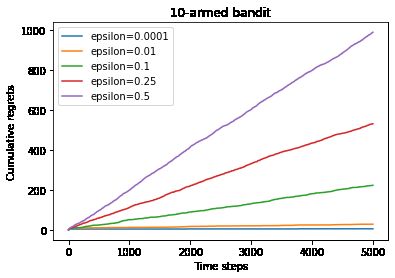
np.random.seed(0)
epsilons = [1e-4, 0.01, 0.1, 0.25, 0.5]
epsilon_greedy_solver_list = [
EpsilonGreedy(bandit_10_arm, epsilon=e) for e in epsilons
]
epsilon_greedy_solver_names = ["epsilon={}".format(e) for e in epsilons]
for solver in epsilon_greedy_solver_list:
solver.run(5000)
plot_results(epsilon_greedy_solver_list, epsilon_greedy_solver_names)
![]()
class DecayingEpsilonGreedy(Solver):
""" epsilon值随时间衰减的epsilon-贪婪算法,继承Solver类 """
def __init__(self, bandit, init_prob=1.0):
super(DecayingEpsilonGreedy, self).__init__(bandit)
self.estimates = np.array([init_prob] * self.bandit.K)
self.total_count = 0
def run_one_step(self):
self.total_count += 1
if np.random.random() < 1 / self.total_count: # epsilon值随时间衰减
k = np.random.randint(0, self.bandit.K)
else:
k = np.argmax(self.estimates)
r = self.bandit.step(k)
self.estimates[k] += 1. / (self.counts[k] + 1) * (r - self.estimates[k])
return k
np.random.seed(1)
decaying_epsilon_greedy_solver = DecayingEpsilonGreedy(bandit_10_arm)
decaying_epsilon_greedy_solver.run(5000)
print('epsilon值衰减的贪婪算法的累积懊悔为:', decaying_epsilon_greedy_solver.regret)
plot_results([decaying_epsilon_greedy_solver], ["DecayingEpsilonGreedy"])epsilon值衰减的贪婪算法的累积懊悔为:10.114334931260183

![]()

class UCB(Solver):
""" UCB算法,继承Solver类 """
def __init__(self, bandit, coef, init_prob=1.0):
super(UCB, self).__init__(bandit)
self.total_count = 0
self.estimates = np.array([init_prob] * self.bandit.K)
self.coef = coef
def run_one_step(self):
self.total_count += 1
ucb = self.estimates + self.coef * np.sqrt(
np.log(self.total_count) / (2 * (self.counts + 1))) # 计算上置信界
k = np.argmax(ucb) # 选出上置信界最大的拉杆
r = self.bandit.step(k)
self.estimates[k] += 1. / (self.counts[k] + 1) * (r - self.estimates[k])
return k
np.random.seed(1)
coef = 1 # 控制不确定性比重的系数
UCB_solver = UCB(bandit_10_arm, coef)
UCB_solver.run(5000)
print('上置信界算法的累积懊悔为:', UCB_solver.regret)
plot_results([UCB_solver], ["UCB"])上置信界算法的累积懊悔为: 70.45281214197854



我们编写代码来实现汤普森采样算法,并且仍然使用 2.2.4 节定义的 10 臂老虎机来观察实验结果。
class ThompsonSampling(Solver):
""" 汤普森采样算法,继承Solver类 """
def __init__(self, bandit):
super(ThompsonSampling, self).__init__(bandit)
self._a = np.ones(self.bandit.K) # 列表,表示每根拉杆奖励为1的次数
self._b = np.ones(self.bandit.K) # 列表,表示每根拉杆奖励为0的次数
def run_one_step(self):
samples = np.random.beta(self._a, self._b) # 按照Beta分布采样一组奖励样本
k = np.argmax(samples) # 选出采样奖励最大的拉杆
r = self.bandit.step(k)
self._a[k] += r # 更新Beta分布的第一个参数
self._b[k] += (1 - r) # 更新Beta分布的第二个参数
return k
np.random.seed(1)
thompson_sampling_solver = ThompsonSampling(bandit_10_arm)
thompson_sampling_solver.run(5000)
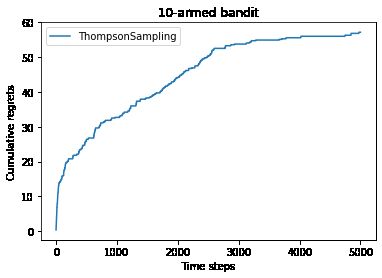
print('汤普森采样算法的累积懊悔为:', thompson_sampling_solver.regret)
plot_results([thompson_sampling_solver], ["ThompsonSampling"])汤普森采样算法的累积懊悔为:57.19161964443925

2.7 总结
探索与利用是与环境做交互学习的重要问题,是强化学习试错法中的必备技术,而多臂老虎机问题是研究探索与利用技术理论的最佳环境。了解多臂老虎机的探索与利用问题,对接下来我们学习强化学习环境探索有很重要的帮助。对于多臂老虎机各种算法的累积懊悔理论分析,有兴趣的同学可以自行查阅相关资料。 -贪婪算法、上置信界算法和汤普森采样算法在多臂老虎机问题中十分常用,其中上置信界算法和汤普森采样方法均能保证对数的渐进最优累积懊悔。
多臂老虎机问题与强化学习的一大区别在于其与环境的交互并不会改变环境,即多臂老虎机的每次交互的结果和以往的动作无关,所以可看作无状态的强化学习(stateless reinforcement learning)。第 3 章将开始在有状态的环境下讨论强化学习,即马尔可夫决策过程。