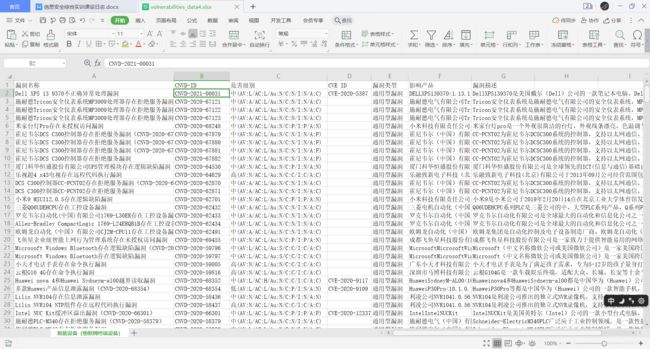
爬虫CNVD构建漏洞库
爬虫CNVD构建漏洞库
1.CNVD设置了加速乐cookie反爬虫
直接爬虫只会爬取一些JavaScript,下面是解决方案!我写代码参考第二个,第二个是纯python代码。
https://blog.csdn.net/YungGuo/article/details/109818327
https://blog.csdn.net/YungGuo/article/details/112181113
2.安装python模块
可能需要下载一些模块,可以参考我的链接,这个链接的方法对于我来说屡试不爽!
https://blog.csdn.net/weixin_40502018/article/details/112547333
3.算法主要思想
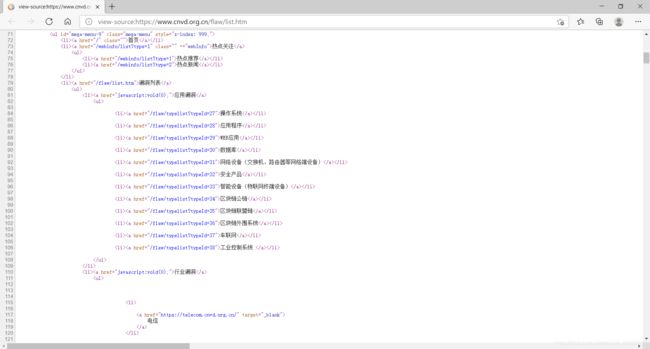
3.1 我的代码的特点是按照漏洞类型爬取的,有如图的类型,根据自己情况选择,Ctrl+U查看typeId!

漏洞类型及type ID如下所示!
3.2 以Web为例,通过https://www.cnvd.org.cn/flaw/typeResult?typeId=31,从页面下方获取最大页数,如下是399页,每页20个详情页链接,根据自己需要改变爬取的最大页数,不要超过网站的最大页数即可!

3.3 对于每一页,获取对应的详情页链接!

3.4 对于获取到的详情页链接,使用session.get()获取页面HTML!
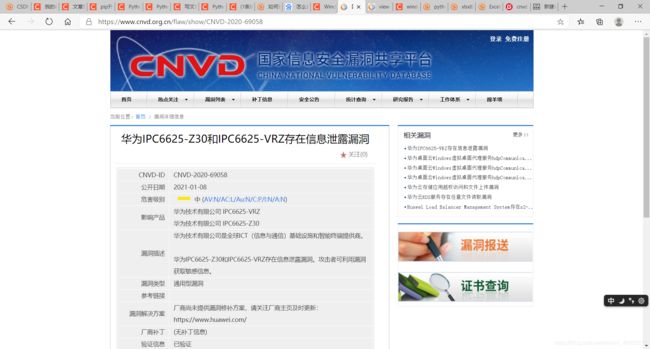
参考以下链接学习XPath,如何从HTML提取相应的内容:
https://zhuanlan.zhihu.com/p/35050247
4.python代码
代码参考链接:
https://gitee.com/moqsien/cnvd
https://blog.csdn.net/weixin_30553065/article/details/99510580
我不想做过多解释,好好看看上面两个链接,我的代码也有一些改进!有什么问题评论就好,我每天都在CSDN看别人文章学习!需要注意的是:根据自己的情况修改函数get_max_page(self)的return min(max_page, 500),将500改小。若觉得运行太慢,可以改改sleep()的参数,可是太小,就可能爬取失败!
查看HTML报错error_403: ‘您访问频率太高,请稍候再试。’ || ‘当前访问疑似黑客攻击,已被网站管理员设置为拦截’,
import requests
from lxml import etree
import xlsxwriter
from requests.utils import add_dict_to_cookiejar
import execjs
import hashlib
import json
import re
import time
import datetime
def get__jsl_clearance_s(data):
"""
通过加密对比得到正确cookie参数
:param data: 参数
:return: 返回正确cookie参数
"""
chars = len(data['chars'])
for i in range(chars):
for j in range(chars):
__jsl_clearance_s = data['bts'][0] + data['chars'][i] + data['chars'][j] + data['bts'][1]
encrypt = None
if data['ha'] == 'md5':
encrypt = hashlib.md5()
elif data['ha'] == 'sha1':
encrypt = hashlib.sha1()
elif data['ha'] == 'sha256':
encrypt = hashlib.sha256()
encrypt.update(__jsl_clearance_s.encode())
result = encrypt.hexdigest()
if result == data['ct']:
return __jsl_clearance_s
def setCookie(url):
global session
session = requests.session()
response1 = session.get(url)
jsl_clearance_s = re.findall(r'cookie=(.*?);location', response1.text)[0]
jsl_clearance_s = str(execjs.eval(jsl_clearance_s)).split('=')[1].split(';')[0]
add_dict_to_cookiejar(session.cookies, {'__jsl_clearance_s': jsl_clearance_s})
response2 = session.get(url)
data = json.loads(re.findall(r';go\((.*?)\)', response2.text)[0])
jsl_clearance_s = get__jsl_clearance_s(data)
add_dict_to_cookiejar(session.cookies, {'__jsl_clearance_s': jsl_clearance_s})
class CNVD(object):
def __init__(self, type_id):
self.type_id = str(type_id)
self.host_url = "https://www.cnvd.org.cn"
self.start_url = "https://www.cnvd.org.cn/flaw/typeResult?typeId=" + self.type_id
self.base_url = "https://www.cnvd.org.cn/flaw/typeResult?typeId={}&max={}&offset={}"
def get_max_page(self):
"""
通过列表页第一页获取最大分页页码, 最多选取10000条记录
Returns: [type] -- [min(最大分页页码, 500),整数]
"""
response = session.get(url=self.start_url)
content = response.text
html = etree.HTML(content)
max_page = html.xpath("//div[@class='pages clearfix']//a[last()-1]/text()")[0]
if max_page:
max_page = int(max_page)
return min(max_page, 5)
def get_list_page(self, max_page):
"""
获取列表页html内容
Arguments: max_page {[int]} -- [最大分页页码]
"""
max = 20
for page in range(max_page):
print("正在爬取列表页第<%s>页" % str(page))
offset = page * max
url = self.base_url.format(self.type_id, max,
offset) # base_url = "https://www.cnvd.org.cn/flaw/typeResult?typeId={}&max={}&offset={}"
response = session.get(url=url)
time.sleep(10)
content = response.text
yield content
def parse_list_page(self, content):
"""
获取列表页中的详情页href,返回href列表
Arguments:
content {[str]} -- [列表页html内容]
Returns:
[list] -- [详情页href列表]
"""
html = etree.HTML(content)
href_list = html.xpath("//tbody/tr/td//a/@href")
return href_list
def handle_str(self, td_list):
"""
字符串去除空格\r\n\t等字符
Arguments:
td_list {[list]} -- [获取文本的列表]
Returns:
[type] -- [返回处理后的合并文本]
"""
result = ''
for td_str in td_list[1:]:
result += td_str.strip()
result = "".join(result.split())
# 去除"危害级别"中的括号
if result.endswith("()"):
result = result[:-2]
return result
def parse_detail_page(self, content):
"""
从详情页中提取信息
Arguments:
content {[str]} -- [详情页html内容]
Returns:
[dict] -- [提取信息字典]
"""
html = etree.HTML(content)
item = {}
item['漏洞名称'] = '' if len(html.xpath("//div[@class='blkContainer']//div[@class='blkContainerSblk']/h1/text()")) == 0 else html.xpath("//div[@class='blkContainer']//div[@class='blkContainerSblk']/h1/text()")[0]
tr_list = html.xpath("//div[@class='blkContainer']//div[@class='blkContainerSblk']//tbody/tr")
for tr in tr_list:
td_list = tr.xpath("./td/text()|./td/a/text()")
if len(td_list) >= 2:
item[td_list[0]] = self.handle_str(td_list)
return item
def get_detail_info(self, href):
"""
通过详情页href,获取详情页html内容
Arguments:
href {[str]} -- [详情页href]
Returns:
[调用详情页解析函数] -- [提取信息]
"""
# host_url = "https://www.cnvd.org.cn"
url = self.host_url + href
print("正在爬取详情页<%s>" % url)
respons = session.get(url=url)
time.sleep(5)
return self.parse_detail_page(respons.content.decode())
def vulnerability_xlsx(vlist, type):
worksheet = workbook.add_worksheet(type)
column_names = ['漏洞名称', 'CNVD-ID', '危害级别', 'CVE ID', '漏洞类型', '影响产品', '漏洞描述']
for i in range(len(column_names)):
worksheet.write(0, i, column_names[i])
for i in range(len(vlist)):
for j in range(len(column_names)):
worksheet.write(i + 1, j, vlist[i][column_names[j]] if column_names[j] in vlist[i].keys() else '')
def spider(type_id):
vlist = []
cnvd = CNVD(type_id)
max_page = cnvd.get_max_page()
content_generator = cnvd.get_list_page(max_page)
for content in content_generator:
href_list = cnvd.parse_list_page(content)
for href in href_list:
item = cnvd.get_detail_info(href)
vlist.append(item)
vulnerability_xlsx(vlist, vtype[type_id])
if __name__ == "__main__":
setCookie('https://www.cnvd.org.cn/')
vtype = {27: 'OS', 29: 'WEB应用', 31: '网络设备(交换机、路由器等网络端设备)', 33: '智能设备(物联网终端设备)'}
workbook = xlsxwriter.Workbook('vulnerabilities_data.xlsx')
for type_id in vtype.keys():
print('正在爬取<%s>漏洞类型' % vtype[type_id])
begin = datetime.datetime.now()
spider(type_id)
time.sleep(20)
end = datetime.datetime.now()
total_time = end - begin
print('爬取', vtype[type_id], '漏洞的时间: ', total_time, sep='')
workbook.close()
- 部分结果如下