校园商城项目自制面经
ware-仓库
目录
ES
为什么redis快
为什么ES搜索快?
怎么理解es的倒排索引
简单看SpringCache的api
Feign怎么用的
gateWay实现前端和后端的跨域请求:
三级分类:
网站的数据上传:
JSR303校验
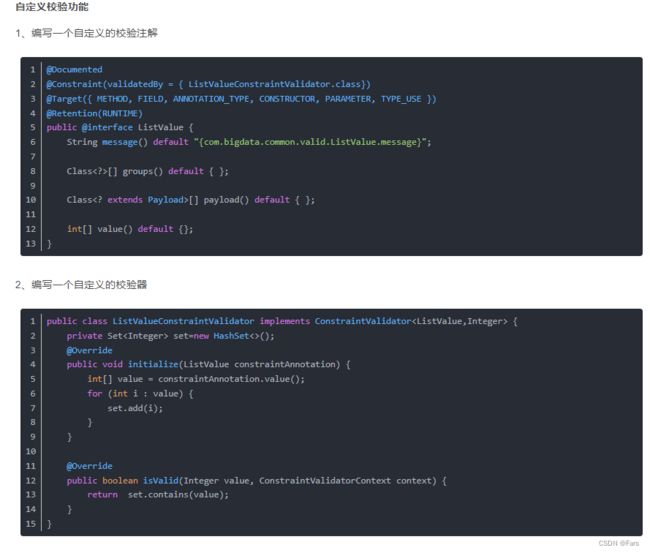
自定义校验功能
ES(参考黑马程序员的springcloud教程md文档)
es里面就是,一个索引库对应多个doc
1.es是倒排索引


2.
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性

精确查询常见的有哪些?
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索 


为什么redis快
Redis 将数据储存在内存里面,读写数据的时候都不会受到硬盘I/O 速度的限制,所以速度极快
为什么ES搜索快?
因为ES使用了倒排索引
怎么理解es的倒排索引
倒排索引是一种数据结构,用于快速定位包含特定单词的文档。它是搜索引擎中最常用的技术之一。在倒排索引中,对于每个单词,存储一张包含该单词的文档列表,每个文档列表包含包含该单词的文档ID。这个列表被称为倒排列表。
例如,假设我们有以下文档:
- 文档1: "The quick brown fox jumps over the lazy dog"
- 文档2: "A quick brown dog outpaces a quick fox"
对于每个单词,我们可以创建一个包含该单词的文档列表,如下所示:
- quick: [文档1, 文档2]
- brown: [文档1, 文档2]
- fox: [文档1, 文档2]
- jumps: [文档1]
- over: [文档1]
- the: [文档1]
- lazy: [文档1]
- dog: [文档1, 文档2]
- outpaces: [文档2]
- a: [文档2]
当我们需要搜索包含特定单词的文档时,只需查找包含该单词的文档列表即可。此外,倒排索引还可以用于计算文档之间的相似度,以及用于自动完成功能。
简单看SpringCache的api瑞吉外卖项目学习笔记-P24-项目优化-Spring Cache缓存套餐数据_探索者7号的博客-CSDN博客
package com.itheima.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.itheima.entity.User;
import com.itheima.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private CacheManager cacheManager;
@Autowired
private UserService userService;
/**
* CachePut:将方法返回值放入缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@CachePut(value = "userCache",key = "#user.id")
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
/**
* CacheEvict:清理指定缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@CacheEvict(value = "userCache",key = "#p0")
//@CacheEvict(value = "userCache",key = "#root.args[0]")
//@CacheEvict(value = "userCache",key = "#id")
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}
//@CacheEvict(value = "userCache",key = "#p0.id")
//@CacheEvict(value = "userCache",key = "#user.id")
//@CacheEvict(value = "userCache",key = "#root.args[0].id")
@CacheEvict(value = "userCache",key = "#result.id")
@PutMapping
public User update(User user){
userService.updateById(user);
return user;
}
/**
* Cacheable:在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
* condition:条件,满足条件时才缓存数据
* unless:满足条件则不缓存
*/
@Cacheable(value = "userCache",key = "#id",unless = "#result == null")
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
@Cacheable(value = "userCache",key = "#user.id + '_' + #user.name")
@GetMapping("/list")
public List list(User user){
LambdaQueryWrapper queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(user.getId() != null,User::getId,user.getId());
queryWrapper.eq(user.getName() != null,User::getName,user.getName());
List list = userService.list(queryWrapper);
return list;
}
}
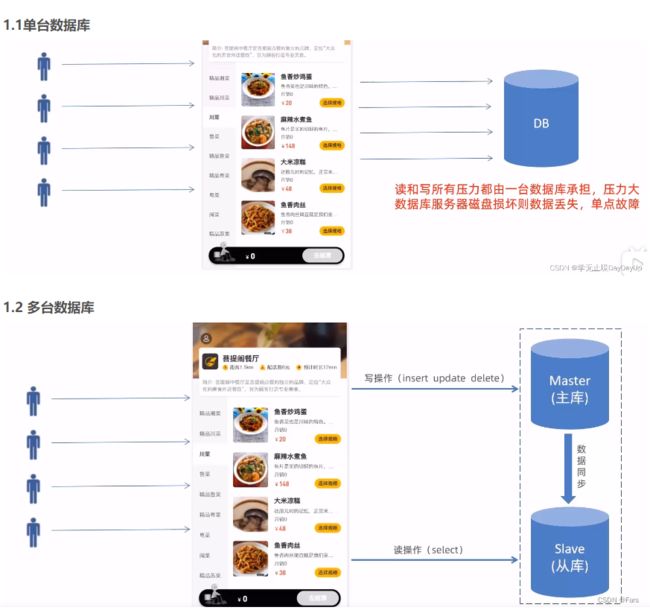
MYSQL的主从复制瑞吉外卖项目学习笔记-P25-项目优化-读写分离_探索者7号的博客-CSDN博客
MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的二进制日志功能。
就是一台或多台MysQL数据库(slave,即从库)从另一台NySQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL主从复制是NySQL数据库自带功能,无需借助第三方工具。
Feign怎么用的
employee给brand发请求
则在employee中单独在client代理商文件夹写接口BrandClient
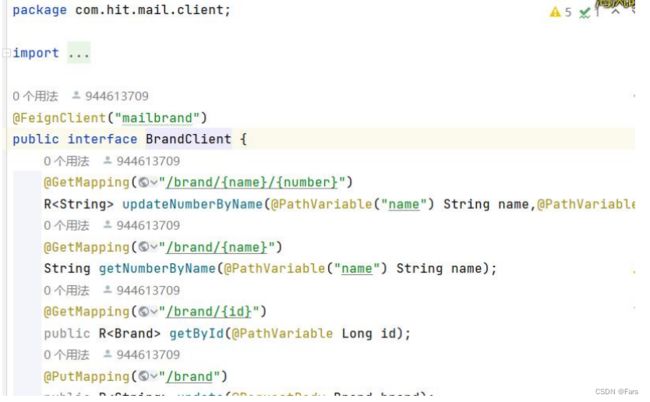
在BrandClient写抽象方法,方法要和想要调用的brandController中的方法一模一样

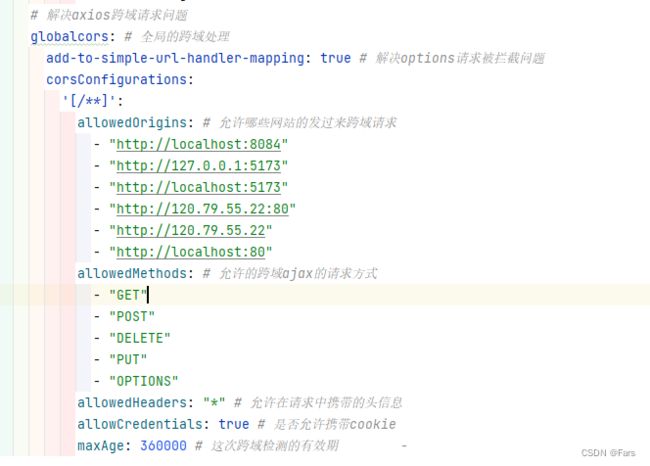
gateWay实现前端和后端的跨域请求:
gateway/application.yaml
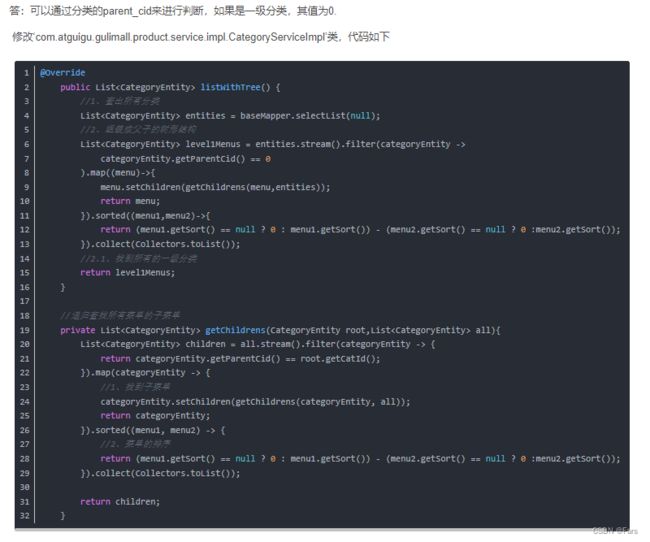
三级分类:
核心思想:类似于并查集的findRoot()经过路径压缩的函数,需要找到最顶层的Root()

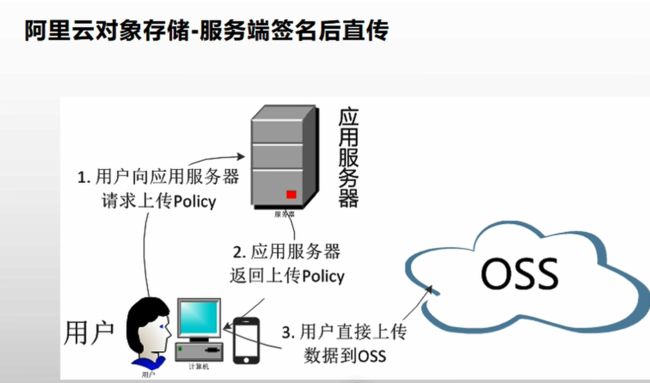
网站的数据上传:
引入gulimall-third-party
直接利用aliyun OSS提供的API
采用的是阿里云的OSS对象存储

且使用的是服务器签名后直传,允许用户在校园商城网站上用校园商城服务器的签名,上传文件到OSS
服务端签名后直传的原理如下:
- 用户发送上传Policy请求到应用服务器。
- 应用服务器返回上传Policy和签名给用户。
- 用户直接上传数据到OSS。
JSR303校验
这是一种java提供的校验方式
在Java中提供了一系列的校验方式,它这些校验方式在“javax.validation.constraints”包中,提供了如@Email,@NotNull等注解。
在非空处理方式上提供了@NotNull,@Blank
自定义校验功能