ClickHouse分布式IN & JOIN 查询的避坑指南
当数据表包含多个分片的时候,我们需要将普通的本地查询转换为分布式查询。当然,这个转换动作是不需要用户自己进行的,在ClickHouse里面会由Distributed表引擎代劳。
Distributed表引擎的定位就好比是一个分表的中间件,它本身并不存储数据,而是分片的代理,能自动的将SQL查询路由到每个分片。
对于分片概念、定义方式以及相关表引擎作用等内容,这里就不再赘述了,我在ClickHouse这本书中对它们都有过详细的论述。
总而言之,分布式查询是面向Distributed表引擎的,而Distributed与分片表的关系如下图所示:
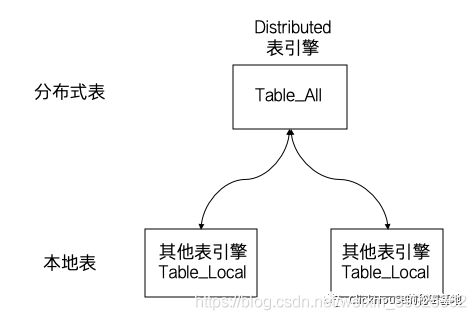
一种约定俗成的命名方式,是将Distributed表附带_all后缀;本地分片附带_local后缀,以示区分。
当我们面对Distributed表引擎查询的时候,它主要为我们做了3件事情:
- 发起远程调用,根据集群的配置信息,从当前节点向远端分片发起Remote远程查询调用
- 分布式表转本地表,在发送远程查询时,将SQL内的 _all表 转成 _local表
- 合并结果集,合并由多个分片返回的数据
假设Distributed表test_all映射了两个分片,它们分布在CH5和CH6两个节点,那么在CH5节点执查询SELECT * FROM test_all 的执行计划会是下面的这个样子:
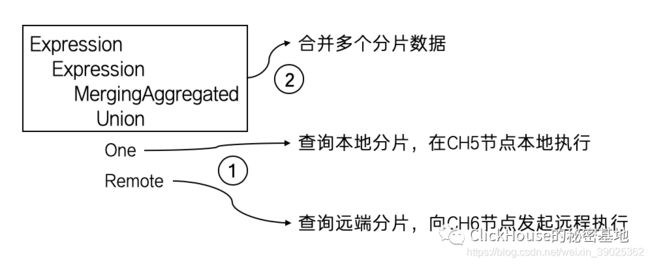
其中,Remote远程查询 和 One本地查询是并行的,所以图中归为了一个步骤。可以看到,面向Distributed表引擎查询,就自动的完成了整个分布式查询的过程。
是不是这样就高枕无忧了呢?
显然不是,铺垫了1000字,现在终于要进入正文了,哦也。
在大多数时候,面向Distributed表的SQL写法与本地查询没有多大区别。但当我们执行 IN 或者 JOIN 查询的时候,一不小心就容易掉到坑里,因为这些查询子句会面对多张数据表。
为了便于演示,我们简化一下场景,用一个自查询的IN子句来解释说明,假设一张表的数据如下:
SELECT * FROM test_query_local
┌─id─┬─repo─┐
│ 1 │ 100 │
│ 2 │ 100 │
│ 3 │ 100 │
│ 3 │ 200 │
│ 4 │ 200 │
└────┴──────┘
现在有一个统计的需求,找到同时拥有repo = 100 和 repo = 200的个数,那么它的查询SQL可能是下面这个样子
SELECT uniq(id) FROM test_query_local WHERE repo = 100
AND id IN (SELECT id FROM test_query_local WHERE repo = 200)
这条语句目前在单机执行是没有问题的,id为3的数据同时拥有2个repo:
┌─uniq(id)─┐
│ 1 │
└──────────┘
现在模拟分布式的场景,把这张表进行分片操作,将它们分布到CH5和CH6两个节点,且每个节点的数据数据如下:
CH5节点 test_query_local
┌─id─┬─repo─┐
│ 1 │ 100 │
│ 2 │ 100 │
│ 3 │ 100 │
└────┴──────┘
CH6节点 test_query_local
┌─id─┬─repo─┐
│ 3 │ 200 │
│ 4 │ 200 │
└────┴──────┘
接着使用 分布式表 test_query_all 映射这2个分片。
那么,刚才的那条SQL应该怎么改?
- 第一种改法
将本地表 test_query_local 改成 分布式表 test_query_all
ch5.nauu.com :) SELECT uniq(id) FROM test_query_all WHERE repo = 100 AND id IN (SELECT id FROM test_query_local WHERE repo = 200)
SELECT uniq(id)
FROM test_query_all
WHERE (repo = 100)
AND (
id IN
(
SELECT id
FROM test_query_local
WHERE repo = 200
)
)
┌─uniq(id)─┐
│ 0 │
└──────────┘
1 rows in set. Elapsed: 0.009 sec.
你会发现返回的数据不对,进一步检查,原因是由 IN 子句引起的,因为它还在使用本地表 test_query_local。
这是什么原理呢?我们看下面这张图就明白了
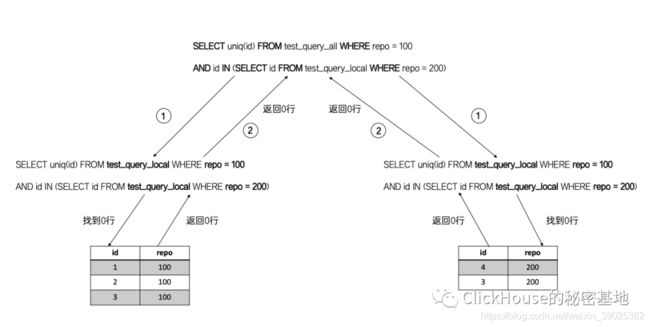
分布式查询将 _all 表转 _local之后,在两个分片最终执行的语句是这样的:
SELECT uniq(id) FROM test_query_local WHERE repo = 100
AND id IN (SELECT id FROM test_query_local WHERE repo = 200)
由于分片的数据分布是不同的,所以数据没有查全。
- 第二种改法
在有了刚才的经验之后,现在把 IN 子句也替换成 _all 分布式表:
ch5.nauu.com :) SELECT uniq(id) FROM test_query_all WHERE repo = 100 AND id IN (SELECT id FROM test_query_all WHERE repo = 200)
SELECT uniq(id)
FROM test_query_all
WHERE (repo = 100)
AND (
id IN (
SELECT id
FROM test_query_all
WHERE repo = 200
)
)
┌─uniq(id)─┐
│ 1 │
└──────────┘
从返回结果来看,这次好像没问题了。
为什么这样能返回正确的结果呢? 如下图所示:

站在CH5节点的视角,在SQL语句 _all 转 _local后,在CH5本地会执行下面的语句:
SELECT uniq(id) FROM test_query_local WHERE repo = 100
AND id IN (SELECT id FROM test_query_all WHERE repo = 200)
注意,IN 子句此时是分布式表 test_query_all,所以它又转成了下面的形式,分别在CH5本地和CH6远端执行:
SELECT id FROM test_query_local WHERE repo = 200
讲到这里就应该很清楚了,因为 IN子句 单独发起了一次分布式查询,所以数据查不全的问题被解决了。
还有什么"坑" 吗? 当然有啦 !!
现在站在CH6节点的视角,SQL在CH5被 _all 转 _local后,会向CH6节点发起远程查询调用。在CH6本地将同样会执行下面的语句:
SELECT uniq(id) FROM test_query_local WHERE repo = 100
AND id IN (SELECT id FROM test_query_all WHERE repo = 200)
注意 IN 子查询,由于它是 分布式表 test_query_all,所以它又会向集群内其他分片发起分布式查询,如下图所示:
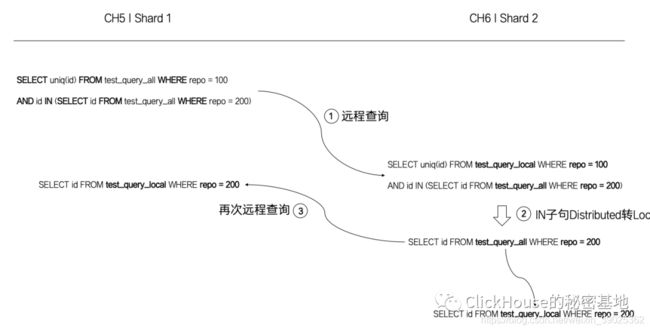
这就是分布式查询的放大问题,放大次数是 N的平方(N = 分片数量)。所以说,如果一张表有10个分片,那么一次分布式 IN 查询的背后会涉及100次查询,这显然是不可接受的。
- 第三种改法
查询放大怎么解决呢? ClickHouse为我们提供了解决方案,继续改造刚才的语句,增加 GLOBAL修饰符:
SELECT uniq(id) FROM test_query_all WHERE repo = 100
AND id GLOBAL IN (SELECT id FROM test_query_all WHERE repo = 200)
增加了 GLOBAL 之后查询会有什么变化呢?
在使用了 GLOBAL 之后,整个分布式查询的流程又发生了变化,我们看下面这张图:
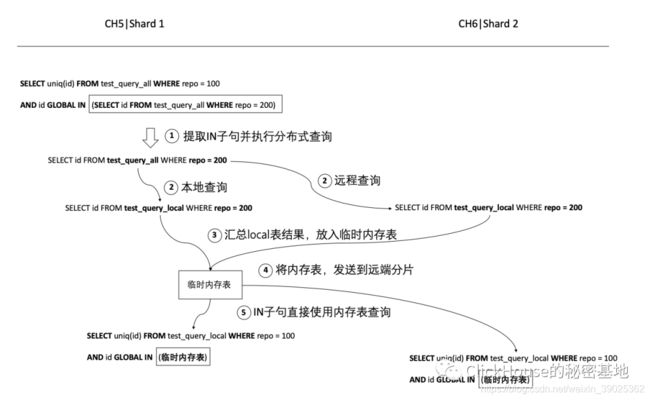
首先,将 GLOBAL 修饰的子句,单独进行了一次分布式查询;
接着,将子句的结果汇总后,用内存临时表保存;
最后,直接将临时表分发至每个分片节点,从而避免了查询放大的问题。
- 关于JOIN查询
对于分布式JOIN查询而言,其执行逻辑和 IN查询是一样的,它们唯一的区别是分发的语句不同,例如:
当执行 IN子句的时候,是将IN子句提取,发起分布式查询:
GLOBAL IN (SELECT id FROM test_query_all WHERE repo = 200)
IN子句 _all 转 _local,分发到每个分片执行,再汇总:
#分布式执行
SELECT id FROM test_query_local WHERE repo = 200
当执行JOIN子句的时候,是将右表提取,发起分布式查询:
SELECT * FROM test_query_all AS t1 GLOBAL JOIN test_query_all AS t2 ON t1.id = t2.id
右表 _all 转 _local,分发到每个分片执行,再汇总:
#分布式执行
SELECT id, repo FROM default.test_query_local
所以分布式JOIN查询我就不再演示图例了,参照IN子句的即可。
好了,现在总结一下,当执行分布式JOIN 或者IN 查询的时候,会碰到几种问题:
查询不全,由于分片的数据不均,会出现查询数据不全的问题,所以JOIN表 和 IN子句 也要使用 _all 分布式表;
查询放大,由于JOIN表 和 IN子句 也是 _all 分布式表,所以每个分片又会向其他远端的分片发起分布式查询,最终的查询次数是 N 的平方(N=分片数量);
解决思路,使用 GLOBAL IN 和 GLOBAL JOIN 可以避免查询放大的问题。
文章来源:ClickHouse分布式IN & JOIN 查询的避坑指南