【论文翻译】Class-Incremental Few-Shot Object Detection
Class-Incremental Few-Shot Object Detection
论文地址:https://arxiv.org/pdf/2105.07637.pdf
摘要
Conventional detection networks usually need abundant labeled training samples, while humans can learn new concepts incrementally with just a few examples. This paper focuses on a more challenging but realistic class-incremental few-shot object detection problem (iFSD). It aims to incrementally transfer the model for novel objects from only a few annotated samples without catastrophically forgetting the previously learned ones. To tackle this problem, we propose a novel method LEAST, which can transfer with Less forgetting, fEwer training resources, And Stronger Transfer capability. Specifically, we first present the transfer strategy to reduce unnecessary weight adaptation and improve the transfer capability for iFSD. On this basis, we then integrate the knowledge distillation technique using a less resource-consuming approach to alleviate forgetting and propose a novel clustering-based exemplar selection process to preserve more discriminative features previously learned. Being a generic and effective method, LEAST can largely improve the iFSD performance on various benchmarks.
传统的检测网络通常需要大量的标记训练样本,而人类只需几个例子就可以逐步学习新概念。本文主要研究一个更具挑战性但更现实的类增量小样本目标检测问题(iFSD)。它的目标是在忘记先前学习的模型的情况下,从仅有的几个标注样本增量地传递新目标的模型。为了解决这一问题,我们提出了一种新的最小迁移方法,该方法能够以较少的遗忘、较少的训练资源和更强的迁移能力进行迁移。具体来说,我们首先提出了迁移策略,以减少不必要的重量适应,并提高iFSD的转移能力。在此基础上,我们结合知识提取技术,使用一种资源消耗较少的方法来缓解遗忘,并提出了一种新的基于聚类的样本选择过程,以保留先前学习到的更多鉴别特征。作为一种通用且有效的方法,最小二乘法可以大大提高iFSD在各种基准上的性能。
介绍
Object detection has achieved significant improvements in both speed and accuracy based on the deep Convolutional Neural Network (CNN) [Ren et al., 2015; Lin et al., 2017a; Lin et al., 2017b; Liu et al., 2018], but they are facing new practical challenges. A notable bottleneck is their heavy dependency on the large training set that contains carefully annotated images. However, on the one hand, it is hard to collect a large and sufficiently annotated dataset that covers all the required categories for most real-world problems. On the other hand, novel classes may be continually encountered after the learning stage, e.g. detecting new living species. Training a particular model whenever these novel classes emerge is infeasible.
基于深度卷积神经网络(CNN)的目标检测在速度和准确性方面都取得了显著的提高[Ren等人,2015年;Lin等人,2017a;Lin等人,2017b;Liu等人,2018年],但他们面临着新的实际挑战。一个显著的瓶颈是它们对包含仔细标注的图像的大型训练集的严重依赖性。然而,一方面,很难收集一个包含大多数实际问题所需的所有类别的大型且有足够注释的数据集。另一方面,在学习阶段之后,可能会不断遇到新的类别,例如发现新的活物种。每当这些新课程出现时,训练一个特定的模型是不可行的。
Inspired by the human’s remarkable ability to incrementally learn novel concepts with just a few samples, classincremental few-shot object detection (iFSD) is beginning to raise research attention. Assuming there is a detector that is well pre-trained on base classes, iFSD aims to transfer it for novel classes that are sequentially observed with very few training examples while not forgetting the old ones.
受人类通过小样本逐步学习新概念的非凡能力的启发,经典增量小样本目标检测(iFSD)开始引起研究关注。假设有一个检测器对基类进行了良好的预训练,iFSD的目标是将其转移到新类,这些新类在不忘记旧类的情况下,通过很少的训练示例连续观察到。
The majority of existing works that transfer a detection model to novel classes focus on non-incremental few-shot object detection (FSD) [Karlinsky et al., 2019; Kang et al., 2019; Wang et al., 2020; Xiao and Marlet, 2020] and classincremental object detection (iOD) [Shmelkov et al., 2017; Hao et al., 2019]. Fig.1 illustrates similarity and difference among FSD, iOD and iFSD. Compared with FSD that mainly cares for detecting novel classes while ignoring base ones, iFSD needs to attack the catastrophic forgetting phenomenon [McCloskey and Cohen, 1989]. It refers to that a neural network forgets previous knowledge when learning a new task and often happens when we simply apply FSD solutions to iFSD. In contrast with iOD that transfers the detector utilizing abundant labeled samples of novel classes, iFSD is more realistic and challenging since people are only willing to annotate very few samples. Even if we have abundant novel samples, large-scale training usually needs intensive computing resources to support, such as GPU servers or clusters. How to incrementally learn novel detectors under limited training resources poses another challenge in iFSD.
将检测模型转换为新类的大多数现有工作侧重于非增量小样本物体检测(FSD)[Karlinsky等人,2019;Kang等人,2019;Wang等人,2020;Xiao和Marlet,2020]和经典增量物体检测(iOD)[Shmelkov等人,2017;Hao等人,2019]。图1说明了FSD、iOD和iFSD之间的相似性和差异。与主要关注检测新类而忽略基本类的FSD相比,iFSD需要攻击灾难性遗忘现象[McCloskey和Cohen,1989]。它指的是神经网络在学习新任务时会忘记以前的知识,并且经常发生在我们简单地将FSD解决方案应用于iFSD时。与利用新类的大量标记样本传输检测器的iOD相比,iFSD更具现实性和挑战性,因为人们只愿意注释很少的样本。即使我们有丰富的新样本,大规模训练通常也需要密集的计算资源来支持,例如GPU服务器或集群。如何在有限的训练资源下逐步学习新型探测器是iFSD面临的另一个挑战。
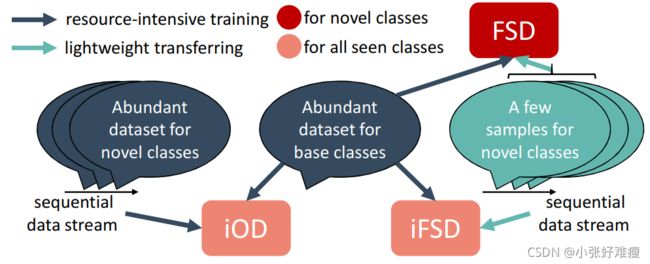
Figure 1: Illustration of similarity and difference among fewshot detection (FSD), class-incremental object detection (iOD), and class-incremental few-shot detection (iFSD). iFSD uses lightweight transferring to incrementally detect novel objects from a sequential data stream, in which novel classes are offered a few samples. 小样本检测(FSD)、类增量检测(iOD)和小样本类增量检测(iFSD)之间的相似性和差异说明。iFSD使用轻量级传输从序列数据流中增量检测新目标,在序列数据流中,新类提供了一些样本。
A straightforward idea to iFSD is integrating standard detection frameworks with class -incremental few-shot classifiers [Ren et al., 2019; Tao et al., 2020; Liu et al., 2020] who use new techniques to avoid forgetting based on the insight from distillation [Hinton et al., 2015], i.e. previous knowledge can be retained by not perturbing the pre-trained discriminative distribution. However, due to the complicated nature of detection tasks, we need to identify multiple objects from millions of candidate regions in one single image. The above classifiers and detection networks cannot be simply merged. The very recent work [Perez-Rua et al., 2020] proposes a class-specific weight generator to register novel classes incrementally. In each incremental novel task, it requires only a single forward pass of novel samples and does not access base classes. Although it can reduce the consumption of training resources for each novel task, it struggles to remember the knowledge learned in previous tasks and has low transfer capability to detect novel objects.
iFSD的一个直截了当的想法是将标准检测框架与类增量小样本分类器集成[Ren等人,2019年;Tao等人,2020年;Liu等人,2020年],这些分类器使用新技术避免基于蒸馏而遗忘[Hinton等人,2015年],即,通过不干扰预先训练的判别分布,可以保留先前的知识。然而,由于检测任务的复杂性,我们需要在一幅图像中从数百万个候选区域中识别多个目标。上述分类器和检测网络不能简单地合并。最近的工作[Perez Rua et al.,2020]提出了一种特定于类的权重生成器,以增量方式注册新类。在每个增量新任务中,它只需要一次新样本的前向传递,并且不访问基类。虽然它可以减少每个新任务的训练资源消耗,但它难以记住以前任务中学习到的知识,并且检测新对象的传输能力较低。
To attack aforementioned problems, we propose a novel iFSD method that incrementally detects novel objects with Less forgetting, fEwer training resources, And Stronger Transfer capability (LEAST). It is generic and straightforward while effectively alleviating the catastrophic forgetting and economizing the consumption of training resources. The contributions of this paper are summarized as follows:
为了解决上述问题,我们提出了一种新的iFSD方法,该方法能够以较少的遗忘、较少的训练资源和较强的传输能力(最少)增量检测新目标。它具有通用性和直观性,同时有效地缓解了灾难性遗忘,节约了训练资源的消耗。本文的贡献总结如下:
• We first give a careful analysis of current methods that can solve the iFSD problem, and then propose a new transfer strategy that decouples class-sensitive object feature extractor from the whole detector in order to obtain stronger transfer capability with less unnecessary weight adaptation.
• We integrate the knowledge distillation technique using a less resource-consuming approach in order to alleviate forgetting the previously learned knowledge.
• We propose a clustering-based exemplar selection algorithm, expected to representatively capture the distribution and intra-class variance of base classes leveraging a few exemplars.
• We conduct extensive experiments to demonstrate that our proposed LEAST can significantly outperform the state-of-the-arts in different settings.
•我们首先仔细分析了当前可以解决iFSD问题的方法,然后提出了一种新的传输策略,该策略将类敏感目标特征提取器与整个检测器解耦,以获得更强的传输能力,同时减少不必要的权重适配。
•我们采用资源消耗较少的方法集成知识蒸馏技术,以减轻对先前学习知识的遗忘。
•我们提出了一种基于聚类的示例选择算法,期望能够代表性地利用一些示例捕获基类的分布和类内差异。
•我们进行了广泛的实验,以证明我们提出的最小二乘法可以在不同环境下显著优于最新水平。
相关工作
Few-shot object detection. Modern machine learning models mainly focus on learning from abundant labeled instances. In contrast, humans can learn new concepts quickly with just a few samples, which gives rise to the recent research of few-shot learning. Most of the existing works are developed in the context of classification, which cannot be directly applied to object detection. Some previous works [Karlinsky et al., 2019; Wang et al., 2019; Kang et al., 2019; Fan et al., 2020] have made useful attempts in integrating few-shot classifiers with detection frameworks in order to improve the performance of novel classes. However, due to the unconstrained nature, a single test image may contain both novel and base classes. Model’s knowledge retention on base classes should also be evaluated at the same time. To meet this requirement, [Yan et al., 2019; Xiao and Marlet, 2020; Wang et al., 2020] randomly select a few base samples and then construct a balanced training set of both base and novel classes for the transfer learning stage. Thus, overfitting on novel classes and forgetting on base ones can be simultaneously alleviated to some extent. [Perez-Rua et al., 2020] further extends this problem to the incremental learning setting, where novel tasks containing several novel classes come sequentially, and performance on all classes observed so far needs to be evaluated.
小样本目标检测。现代机器学习模型主要关注从大量标记实例中学习。相比之下,人类只需几个样本就可以快速学习新概念,这引发了最近的少镜头学习研究。现有的大多数工作都是在分类的背景下进行的,不能直接应用于目标检测。之前的一些工作【Karlinsky等人,2019年;Wang等人,2019年;Kang等人,2019年;Fan等人,2020年】在将小样本分类器与检测框架集成以提高新类的性能方面进行了有益的尝试。然而,由于不受约束的性质,单个测试图像可能同时包含新类和基类。同时还应评估模型在基类上的知识保留。为了满足这一要求,[Yan等人,2019年;Xiao和Marlet,2020年;Wang等人,2020年]随机选择一些基础样本,然后为迁移学习阶段构建一个平衡的基础类和新类训练集。因此,在一定程度上可以同时缓解对新类的过度拟合和对基础类的遗忘。[Perez Rua et al.,2020]进一步将这一问题扩展到增量学习环境,在增量学习环境中,包含多个新类的新任务依次出现,需要评估迄今为止观察到的所有类的性能。
Rehearsal, i.e. incremental learning not only with the novel data but also with earlier data, is actually a feasible strategy to overcome catastrophic forgetting. Under the limitation of memory usage and computational requirement, we cannot use all data in previous tasks but some exemplars instead [Rebuffi et al., 2017]. The methods [Yan et al., 2019; Xiao and Marlet, 2020; Wang et al., 2020] using randomly selected exemplars can naturally be regarded as exemplarbased solutions for iFSD. In contrast with random selection, we propose to select a few representative exemplars with a clustering-based approach, with the hope of capturing the distribution and intra-class variance of base classes.
Rehearsal等认为增量学习不仅使用新数据而且使用早期数据,实际上是克服灾难性遗忘的可行策略。在内存使用和计算需求的限制下,我们不能使用以前任务中的所有数据,而是使用一些示例[Rebuffi et al.,2017]。使用随机选择的样本的方法[Yan等人,2019;Xiao和Marlet,2020;Wang等人,2020]自然可以被视为iFSD的样本解决方案。与随机选择相比,我们建议使用基于聚类的方法选择一些具有代表性的样本,希望能够捕获基类的分布和类内方差。
Class-incremental object detection. Humans can continuously learn new knowledge as their experience goes, without catastrophically forgetting previously learned knowledge. However, deep neural networks will forget what has been learned when they are trained on a new task, which is a key challenge in incremental learning. [Li and Hoiem, 2016; Rebuffi et al., 2017] try to attack this challenge in the context of visual classification. While [Shmelkov et al., 2017; Hao et al., 2019] focus their attention on the object detection scenario, where a detector is learned from sequentially arrived data that contain disjoint objects. In the incremental learning stage, the knowledge distillation [Hinton et al., 2015] technique is adopted, where extra memory for storing the frozen copy of the pre-trained model is needed. Different from using abundant data in each novel task above, [PerezRua et al., 2020] incrementally detects novel objects with just a few samples, which is more challenging and realistic.
类增量目标检测。随着经验的发展,人类可以不断地学习新知识,而不会灾难性地忘记以前学到的知识。然而,深度神经网络在接受新任务训练时会忘记所学内容,这是增量学习的一个关键挑战。[Li和Hoiem,2016;Rebuffi等人,2017]试图在视觉分类的背景下应对这一挑战。而[Shmelkov等人,2017年;Hao等人,2019年]则将注意力集中在目标检测场景上,即从包含不相交目标的顺序到达的数据中学习检测器。在增量学习阶段,采用了知识提取[Hinton et al.,2015]技术,其中需要额外的内存来存储预训练模型的冻结副本。与在上述每项新任务中使用大量数据不同,[PerezRua et al.,2020]只需少量样本即可增量检测新目标,这更具挑战性和现实性。
Comparing with the above works, we attempt to integrate the knowledge distillation technique with iFSD in a generic and effective framework. It does not need a large amount of extra memory for the frozen copy during training, but only a little for the pre-computed logits of a few instances instead. Besides, LEAST can be established with either one-stage or two-stage detection frameworks. For a fair comparison with previous models [Yan et al., 2019; Wang et al., 2020; Fan et al., 2020; Xiao and Marlet, 2020], we adopt Faster-RCNN [Ren et al., 2015] as the basic architecture in this paper.
与上述工作相比,我们尝试将知识提取技术与iFSD集成在一个通用而有效的框架中。在训练过程中,冻结的副本不需要大量额外内存,而对几个实例的预先计算的logit只需要少量内存。此外,可以使用单阶段或两阶段检测框架来建立最小检测。为了与之前的模型进行公平比较[Yan等人,2019;Wang等人,2020;Fan等人,2020;Xiao和Marlet,2020],我们采用Faster RCNN[Ren等人,2015]作为本文的基本架构。
方法
3.1 Problem Definition
Let C = Cb ∪ Cn denotes the whole set of object categories. Cb is the set of base classes that have a large number of training instances, annotated with object categories and bounding boxes. Cn is the disjoint set of novel classes that have only K (usually less than 10) instances per class (i.e. K-shot detection). iFSD aims to learn a detector that can incrementally detect novel objects using K-shot per class. It may encounter a different number of novel classes in practice. Here we consider two different settings as in [Perez-Rua et al., 2020]. The typical setting for iFSD is that the novel classes are added at once with a single model transfer. In the more challenging continual iFSD setting, the novel classes are added one by one with |Cn| times model transfer.
设C=Cb∪Cn表示目标类别的整个集合。Cb是具有大量训练实例的基类集,用目标类别和边界框进行注释。Cn是一组不相交的新类,每个类只有K个(通常少于10个)实例(即K-shot检测)。iFSD的目标是学习一种检测器,该检测器可以使用每类K-shot增量检测新目标。在实践中,它可能会遇到不同数量的新类别。在这里,我们考虑两个不同的设置,如[ Perez Rua等人,2020 ]。iFSD的典型设置是通过单个模型传输立即添加新类。在更具挑战性的连续iFSD设置中,使用|Cn| 次模型传输逐个添加新类。
A general iFSD solution consists of two stages: (1) Pretrain stage: pre-train a standard detector on base classes; (2) Incremental transfer stage: transfer the pre-trained detector to novel classes without forgetting the old ones. Considering the computational requirement and the memory limit, it should be computationally-efficient without revisiting the whole base class data. Our main focus in this paper is the essential incremental transfer stage.
一般的iFSD解决方案包括两个阶段:(1)预训练阶段:在基类上预训练标准检测器;(2) 增量转移阶段:在不忘记旧类的情况下,将预先训练好的检测器转移到新类。考虑到计算需求和内存限制,它应该在不重新访问整个基类数据的情况下具有计算效率。我们在本文中的主要关注点是基本增量迁移阶段。
3.2 Reducing Unnecessary Weight Adaptation
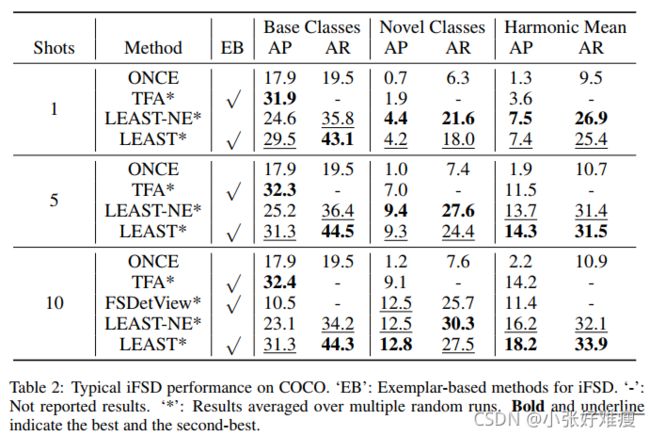
We start with a detailed analysis of current methods that can solve the iFSD problem (including exemplar-based methods mentioned in Section 2) and then propose our transfer strategy. Previous approaches can be divided into two subgroups, according to their transfer strategy in the incremental transfer stage: (1) Fix the pre-trained detector and only adapt the last layer to novel classes (denoted as FIX ALL) [Wang et al., 2020; Perez-Rua et al., 2020]. (2) Adapt the whole detector to novel classes (denoted by FIT ALL) [Yan et al., 2019; Xiao and Marlet, 2020]. The former consumes minimal resources in transferring for novel classes while has limited generalization ability since the feature extractor is fixed. The latter usually has good performance on novel classes but forgets old ones since the whole network is biased towards novel objects. It also needs more training resources than the former methods. The difference in resource consumption between these two types of approaches is straightforward, and the performance difference can be found in Tab.2, where TFA is the state-of-the-art method of FIX ALL and FSDetView is the state-of-the-art method of FIT ALL.
我们首先详细分析了当前解决iFSD问题的方法(包括第2节提到的基于示例的方法),然后提出了我们的迁移策略。根据增量迁移阶段的迁移策略,先前的方法可分为两个子组:(1)固定预先训练的检测器,并仅使最后一层适应新类(用FIX ALL表示)【Wang等人,2020年;Perez Rua等人,2020年】。(2) 使整个检测器适应新的类别(用FIT ALL表示)[Yan等人,2019;Xiao和Marlet,2020]。前者对新类的传输消耗最少的资源,但由于特征提取器是固定的,因此泛化能力有限。后者通常在新类上具有良好的性能,但由于整个网络偏向于新目标,因此会忘记旧类。与以前的方法相比,它还需要更多的训练资源。这两种方法之间的资源消耗差异是显而易见的,性能差异可以在表2中找到,其中TFA是最先进的FIX ALL方法,而FSDetView是最先进的FIT ALL方法。
The low performance of FIT ALL on base classes make sense due to unnecessary weight adaptation. From the architecture’s perspective, we know that even if a neuron of the front layers changes a little, the final output may vary a lot after the feed-forward pass of a neural network. If we transfer the whole detector using limited supervision (i.e. K-shot), the discriminative distribution learned from previous classes will be further influenced as the updated layers get deeper. Besides, the front layers in a deep learning model usually learn generic features for an image and are well trained in the abundant training examples. Adaptation on them is unnecessary and may cause overfitting on the few samples.
由于不必要的权重调整,FIT ALL在基类的低性能是有意义的。从体系结构的角度来看,我们知道,即使前几层的神经元发生了一些变化,在神经网络的前馈传递之后,最终的输出可能会有很大的变化。如果我们使用有限监督(即K-shot)转移整个检测器,则随着更新层的加深,从以前的类中学习到的区分性分布将进一步受到影响。此外,深度学习模型中的前端层通常学习图像的一般特征,并在丰富的训练示例中得到良好的训练。对其进行调整是不必要的,可能会导致少数样本的过度拟合。
Based on the above consideration, we propose to separate the whole detector into class-agnostic image feature extractor (unchanged during the incremental learning stage) and classs ensitive object feature extractor (CSE) (optimized during the incremental learning stage), as is shown in Fig.2. Usually, a deep backbone in the detection network, e.g. ResNet [He et al., 2016], extracts generic features for an input image and can be regarded as a class-agnostic image feature extractor. If we update the backbone with a few novel samples, its feature extraction capability will be damaged instead, possibly resulting in the forgetting. While the object feature extractor (e.g. RPN and ROI head for a two-stage detector like FasterRCNN [Ren et al., 2015], or FPN and extra subnets for a one-stage detector like RetinaNet [Lin et al., 2017b]) is more sensitive to object categories and often extract object-specific features. It expects to be updated to learn more discriminative information of novel classes; otherwise, the detector will be hard to generalize to novel classes. Thus, we propose only to optimize CSE while keep others fixed in the incremental transfer stage (denoted as FIT CSE).
基于上述考虑,我们将整个检测器分为类无关图像特征提取器(增量学习阶段不变)和类敏感目标特征提取器(CSE)(增量学习阶段优化),如图2所示。通常,检测网络中的深层骨干网络(例如ResNet[He et al.,2016])会提取输入图像的一般特征,可以视为类无关图像特征提取器。如果我们用一些新的样本更新骨干网络,它的特征提取能力反而会被破坏,可能导致遗忘。而目标特征提取器(例如,两级检测器(如Faster RCNN[Ren等人,2015])的RPN和ROI头部,或一级检测器(如RetinaNet[Lin等人,2017b])的FPN和额外子网)对目标类别更为敏感,通常提取目标特定的特征。它预计将被更新,以了解更多的新类歧视性信息;否则,检测器将很难推广到新类。因此,我们建议只优化CSE,而在增量转移阶段(表示为FIT_CSE)保持其他固定的CSE。
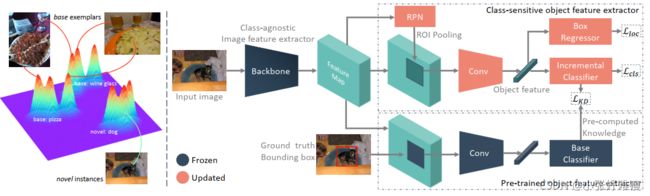
Figure 2: Illustration of our proposed method based on Faster R-CNN framework. Left: our clustering-based exemplar selection that is expected to have the potential to capture modes of each base class. These exemplars and few novel instances form a balanced set for the incremental transfer stage. Right: the overall architecture. The decoupled detector and distilled knowledge are used to enhance the model’s transfer capability to novel classes, without forgetting the base ones at the same time. Faster R-CNN框架提出的方法的说明。左图:我们基于集群的示例选择,有望捕获每个基类的模式。这些示例和少数新实例构成了增量转移阶段的平衡集。右图:总体架构。在不忘记基本类的情况下,使用解耦检测器和提取知识来增强模型向新类的传输能力。
The proposed transfer strategy combines the advantages of both FIX ALL and FIT ALL. Without the unnecessary weight adaptation on class-agnostic image feature extractor, it consumes fewer training resources and is more generalized to novel objects utilizing the well learned image features.
所提出的转移策略结合了FIX-ALL和FIT-ALL的优点。该算法不需要对类无关图像特征提取器进行不必要的权值调整,只需消耗较少的训练资源,并且可以更广泛地应用于利用已学习图像特征的新目标。
3.3 Less Forgetting with Knowledge Distillation
In the incremental transfer stage, a naive method is to finetune the network with standard classification loss:
在增量传输阶段,一种简单的方法是使用标准分类损耗对网络进行微调:![]()
where X denotes all candidate regions in the few available images. y∗ is the ground-truth label for x. p(y | x,Φ) is the classification probability for observed classes including incrementally added ones, with parameters Φ. However, since base classes are not available in the incremental transfer stage, the model tends to forget the previous knowledge catastrophically. Even if we use the exemplar set to store a few old samples, the model will also forget some discriminative information for previous classes due to the limited supervision.
其中X表示少数可用图像中的所有候选区域。Y∗ 是x的ground-truth 标签。p(y | x,Φ)是观察到的类别的分类概率,包括递增增加的类别,参数为Φ。然而,由于基类在增量迁移阶段不可用,模型往往会灾难性地忘记以前的知识。即使我们使用样本集来存储一些旧样本,由于监督有限,模型也会忘记以前类的一些鉴别信息。
To attack this problem, we propose to use knowledge distillation [Hinton et al., 2015] in iFSD, inspired by its success in incremental classification [Li and Hoiem, 2016]. Although previous works [Shmelkov et al., 2017; Hao et al.,2019] have tried integrating distillation in object detection, they still need an exact copy of the pre-trained detector to compute the learned knowledge in the discriminative distribution 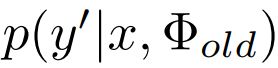 . Here y0 belongs to the previous classes Cold. Φold denotes the parameters learned in previous tasks. In this way, much more computing resources are used than directly training the detector. In contrast, we apply knowledge distillation on positive candidate regions with pre-computed knowledge, shown in Fig.2. To be specific, the previous knowledge for positive candidate regions x ∼ Xp will be pre-computed through ground-truth bounding-boxes bgt and ROI pooling [Ren et al., 2015]. Here Xp denote the set of positive candidate regions, whose Intersection over Union (IoU) with ground truth is above α, i.e. IoU(x, bgt) > α. Similarly, it can also be pre-computed in the one-stage detector according to the anchor owning the maximum IOU with bgt. Then, it is straightforward to avoid forgetting the pre-trained knowledge:
. Here y0 belongs to the previous classes Cold. Φold denotes the parameters learned in previous tasks. In this way, much more computing resources are used than directly training the detector. In contrast, we apply knowledge distillation on positive candidate regions with pre-computed knowledge, shown in Fig.2. To be specific, the previous knowledge for positive candidate regions x ∼ Xp will be pre-computed through ground-truth bounding-boxes bgt and ROI pooling [Ren et al., 2015]. Here Xp denote the set of positive candidate regions, whose Intersection over Union (IoU) with ground truth is above α, i.e. IoU(x, bgt) > α. Similarly, it can also be pre-computed in the one-stage detector according to the anchor owning the maximum IOU with bgt. Then, it is straightforward to avoid forgetting the pre-trained knowledge:
为了解决这个问题,我们建议在iFSD中使用知识蒸馏[Hinton et al.,2015],其灵感来自于增量分类的成功[Li和Hoiem,2016]。尽管之前的工作【Shmelkov等人,2017年;Hao等人,2019年】已经尝试将蒸馏集成到目标检测中,但他们仍然需要一个经过预训练的检测器的精确副本来计算判别分布中的学习知识。这里y0属于前面的类Cold。Φold表示在以前的任务中学习到的参数。这样,使用的计算资源比直接训练检测器要多得多。相比之下,我们使用预先计算的知识对正候选区域进行知识提取,如图2所示。具体地说,正候选区域的先前知识)x∼ Xp将通过ground-truth边界框bgt和ROI池化预先计算[Ren等人,2015]。这里Xp表示正候选区域集,其与ground-truth的联合(IoU)的交集高于α,即IoU(x,bgt)>α。类似地,它也可以在一级检测器中根据具有bgt的最大IOU的锚预先计算。然后,可以直接避免忘记预先训练的知识:
![]()
where Kullback-Leibler (KL) divergence measures the forgotten information of the new discriminative distribution for Cold with respect to the pre-trained one. Considering KL(Pold || P) = H(Pold,P) - H(Pold) and the Cross Entropy H(Pold) is irrelevant to Φ, Eq.2 is equivalent to:
其中,KL散度测量了新的 Cold判别分布相对于预训练分布的遗忘信息。考虑到KL(Pold | | P)=H(Pold,P)-H(Pold),且交叉熵H(Pold)与Φ无关,等式2等价于:
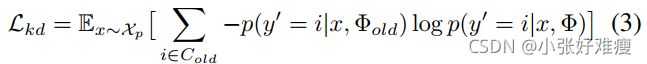
where the classification probability for distillation is produced by scaled softmax:  and zi is the output logit of class i. T is the temperature, which is suggested T > 1 to encourage the network to better encode previously learned class similarities [Hinton et al., 2015]. The final loss used in iFSD becomes:
and zi is the output logit of class i. T is the temperature, which is suggested T > 1 to encourage the network to better encode previously learned class similarities [Hinton et al., 2015]. The final loss used in iFSD becomes:
其中,蒸馏的分类概率由缩放的softmax生成:和zi是i类的输出逻辑。T是温度,建议T>1,以鼓励网络更好地编码之前学习到的类相似性[Hinton等人,2015]。iFSD中使用的最终损失为:
![]()
where Lrpn and Lloc are the same loss as in Faster R-CNN. ![]() is to balance the relative contribution of Lkd.
is to balance the relative contribution of Lkd.
其中,Lrpn和Lloc的损耗与FasterR-CNN相同。是平衡Lkd的相对贡献。
3.4 More Preserving with A Few Exemplars
In order to not forget the old learned knowledge, another feasible method in the incremental transfer stage is to store a few exemplars drawn from the old training set. As discussed in Section 2, several current methods can be regarded as exemplar-based solutions for iFSD, where exemplars are selected randomly. However, the randomly selected exemplar set is unstable and can not guarantee to well represent the non-uniform data distributions of different classes. Another class-average based exemplar selection [Rebuffi et al., 2017] that aims to approximate the class mean vector is also not suitable for iFSD because of the complex scenarios and intraclass variance in the detection task [Karlinsky et al., 2019].
为了不忘记旧的学习知识,增量迁移阶段的另一个可行方法是存储从旧训练集中提取的一些样本。如第2节所述,当前的几种方法可以被视为iFSD的基于示例的解决方案,其中示例是随机选择的。然而,随机选择的样本集是不稳定的,不能保证很好地表示不同类别的非均匀数据分布。另一种基于类平均值的样本选择[Rebuffi等人,2017年]旨在近似类平均向量,但由于检测任务中的复杂场景和类内方差,也不适用于iFSD[Karlinsky等人,2019年]。
As is shown in the left of Fig.2, the data distribution of each class may have multiple modes. To better preserve the discriminative features learned on base classes, we expect the selected exemplars could have the potential to represent these modes as many as possible. Randomly selected exemplars may not be representative, and class-average based exemplars can only capture one mode. To this problem, we propose a novel clustering-based examplar selection algorithm as follows. Details can be found in Algorithm 1
如图2左侧所示,每个类别的数据分布可能有多种模式。为了更好地保留在基类上学习到的区别性特征,我们希望所选的示例能够尽可能多地表示这些模式。随机选择的示例可能不具有代表性,基于类平均的示例只能捕获一种模式。针对这个问题,我们提出了一种新的基于聚类的样本选择算法。详细信息可在算法1中找到

Each image may contain multiple instances from different classes. Thus, we need to calculate multiple features for an image. Firstly, for simplicity, each distinct category contained in an image is represented by the averaged features of instances with the same category, since the same category’s instances in a single image are probably similar. Secondly, for each c ∈ Cb, we use the k-means algorithm to cluster the features from images containing c into K clusters. K is assumed as the number of shots in order to construct a balanced fewshot dataset between base and novel classes. We will then obtain K centroids for each category. Finally, we progressively select the images that best approximates these learned centroids. Since a single image may cover clusters of different classes, we hope that using at most |Cb|∗ K images to representatively capture the discriminative features of base classes. Moreover, although we use the simple but effective clustering method (k-means) in this paper, other exemplar learning methods are worth trying in the future [Bautista et al., 2016; Mairal et al., 2008]
每个映像可能包含来自不同类的多个实例。因此,我们需要计算图像的多个特征。首先,为简单起见,图像中包含的每个不同类别由具有相同类别的实例的平均特征表示,因为单个图像中相同类别的实例可能相似。其次,对于每个c∈cb,我们使用k-means算法将包含c的图像中的特征聚类为k个聚类。为了在基类和新类之间构建一个平衡的小样本数据集,假设K为新类别数。然后,我们将获得每个类别的K个质心。最后,我们逐步选择最接近这些学习到的质心的图像。由于单个映像可能覆盖不同类的集群,因此我们希望最多使用|Cb|∗ K图像代表性地捕获基类的区别特征。此外,尽管我们在本文中使用了简单但有效的聚类方法(k-means),但其他样本学习方法在未来值得尝试【Bautista等人,2016;Mairal等人,2008】
4 实验
4.1 Experimental Setup
Dataset. We use two popular and challenging datasets for non-incremental FSD and incremental FSD (iFSD) in this paper to evaluate the detection performance, i.e. Pascal VOC [Everingham et al., 2015], and MS-COCO [Lin et al., 2014]. We use the same data splits as in the previous work [Kang et al., 2019; Wang et al., 2019; Yan et al., 2019; Wang et al., 2020] for FSD and the work [Perez-Rua et al., 2020] for iFSD, respectively. In MS-COCO, there are 80 classes in total, which include the whole 20 classes in Pascal VOC. The 60 categories disjoint with Pascal VOC are used as base classes, while the remaining 20 categories are used as novel ones. Each novel class has K 2 f1; 5; 10g samples, and 10 random sample groups are considered in this paper, following [Wang et al., 2020]. For the MS-COCO dataset, we use 5000 images as in [Kang et al., 2019] from the validation set for evaluation, and the rest images containing at least one base instance in train/val sets for pre-training. For the Pascal VOC dataset, we use the 2007 test set for testing.
数据集。在本文中,我们使用了两个流行且具有挑战性的非增量FSD和增量FSD(iFSD)数据集来评估检测性能,即Pascal VOC【Everingham等人,2015年】和MS-COCO【Lin等人,2014年】。我们分别对FSD和iFSD使用与先前工作[Kang等人,2019;Wang等人,2019;Yan等人,2019;Wang等人,2020]相同的数据分割。在MS-COCO中,总共有80个类,其中包括Pascal VOC中的全部20个类。与Pascal VOC不相交的60个类别用作基类,其余20个类别用作新类别。每个新类都有k2f1;5.本文考虑了10g样本和10个随机样本组,如下[Wang等人,2020]。对于MS-COCO数据集,我们使用验证集[Kang等人,2019]中的5000张图像进行评估,其余图像至少包含训练集/val集中的一个基本实例进行预训练。对于Pascal VOC数据集,我们使用2007测试集进行测试。
Evaluation metric. To evaluate the detection performance, we use the average precision (AP) with IOU threshold from 0.5 to 0.95 of the top 100 detections and the corresponding average recall (AR) as the evaluation metrics. For nonincremental FSD, only the performance on novel classes is tested. While for iFSD, the performance on both base and novel classes needs to be tested. To evaluate the model’s comprehensive performance between base and novel domains in a balanced way, we also report their harmonic mean value, i.e. HM(x,y) = 2xy/(x+y), same as another incremental fewshot scenario [Cermelli et al., 2020]. Some works only report the mean score of all classes, which ignores the significance of novel classes. Since the number of novel classes is usually much smaller than base classes, the simple mean score will bias a lot to base classes and then can not well evaluate the comprehensive performance.
评价指标。为了评估检测性能,我们使用前100个检测中IOU阈值为0.5到0.95的平均精度(AP)和相应的平均召回率(AR)作为评估指标。对于非增量FSD,仅测试新类的性能。而对于iFSD,基本类和新类的性能都需要测试。为了以平衡的方式评估模型在基本域和新域之间的综合性能,我们还报告了它们的调和平均值,即HM(x,y)=2xy/(x+y),与另一个增量小样本情景相同[Cermelli等人,2020]。有些论文只报告所有类别的平均分数,而忽略了新类别的重要性。由于新类的数量通常比基类小得多,简单的平均分数会对基类产生很大的偏差,从而无法很好地评估综合性能。
Implementation details. We use Faster-RCNN as our basic detection architecture and ResNet 101 as the backbone following [Wang et al., 2020]. We train the model using the SGD optimizer with a momentum of 0.9 and a weight decay of 0.0001. The parameters α and T are set to 0:7 and 20 respectively. During the pre-training stage, we train the standard Faster-RCNN on base classes for 6 epochs with a learning rate of 0.01, which is decreased by 10 after 4 epochs. We freeze the class-agnostic image feature extractor during the incremental transfer stage and then train our proposed method for 10 epochs with a learning rate of 0.001. Our code is uploaded as an attachment.
实施细节。我们使用Faster-RCNN作为我们的基本检测架构,并使用ResNet 101作为主干网[Wang等人,2020]。我们使用SGD优化器训练模型,动量为0.9,权重衰减为0.0001。参数α和T分别设置为0.7和20。在预训练阶段,我们在基类上训练了6个阶段的标准快速RCNN,学习率为0.01,4个阶段后下降了10。我们在增量传输阶段冻结类无关图像特征提取器,然后以0.001的学习率对我们提出的方法进行10个阶段的训练。我们的代码作为附件上传。
4.2 Non-Incremental Few-Shot Detection
When all novel classes are added at once in one incremental learning stage, and only novel classes are focused, the iFSD problem naturally degenerates into the vanilla FSD problem. In this case, our method (LEAST) can be regarded as an effective solution to the non-incremental FSD, along with the specific advantage of not forgetting base classes at the same time. We compare LEAST with several state-of-thearts on MS-COCO in Tab.1, which are MetaDet [Wang et al., 2019], Meta-RCNN [Yan et al., 2019], TFA [Wang et al., 2020], Attn-RPN [Fan et al., 2020], and FSDetView [Xiao and Marlet, 2020]. From Tab.1, we can observe that LEAST can achieve comparable results on novel classes with nonincremental FSD approaches. AP and AR are even a little higher than the state-of-the-art FSDetView. Since unknown objects in a test image may cover all possible categories, the class similarities and discriminative information previously learned will also benefit novel classes’ performance. It validates the effectiveness of LEAST. Furthermore, comparing with all these competitors that generally improve the detection performance of novel classes while sacrificing the performance on base ones, LEAST has a significant advantage of not forgetting previous knowledge.
当在一个增量学习阶段同时添加所有新类,并且只关注新类时,iFSD问题自然退化为普通FSD问题。在这种情况下,我们的方法(最少)可以被视为非增量FSD的有效解决方案,同时具有不忘记基类的特殊优势。我们至少将表1中MS-COCO的几种状态进行了比较,它们是MetaDet[Wang等人,2019]、Meta-RCNN[Yan等人,2019]、TFA[Wang等人,2020]、Attn RPN[Fan等人,2020]和FSDetView[Xiao和Marlet,2020]。从表1中,我们可以观察到,在使用非增量FSD方法的新类上,最小类可以获得可比的结果。AP和AR甚至比最先进的FSDetView略高。由于测试图像中的未知对象可能涵盖所有可能的类别,因此先前学习到的类相似性和鉴别信息也将有助于新类的性能。验证了最小二乘法的有效性。此外,与所有这些竞争对手相比,LEAST在提高新类的检测性能的同时牺牲了基本类的性能,它在不忘记以前的知识方面具有显著的优势。

4.3 Class-Incremental Few-Shot Detection
Typical iFSD results. We first evaluate the iFSD performance under the typical setting on MS-COCO, where all the novel classes are added at once with one incremental transfer session. In this case, as mentioned in Section 2, some methods for FSD can be naturally regarded as exemplar-based solutions for iFSD. We compare LEAST with several stateof-the-arts in Tab.2: ONCE [Perez-Rua et al., 2020], TFA [Wang et al., 2020] and FSDetView [Xiao and Marlet, 2020]. We also report our proposed method’s performance using no exemplars for a fair comparison with methods without exemplars, denoted as ‘LEAST-NE’.
典型的iFSD结果。我们首先评估了MS-COCO上典型设置下的iFSD性能,其中所有新类都是通过一个增量传输会话一次添加的。在这种情况下,如第2节所述,FSD的一些方法自然可以被视为iFSD的基于示例的解决方案。我们在表2中至少与几种最新技术进行了比较:ONCE【Perez Rua等人,2020年】、TFA【Wang等人,2020年】和FSDetView【肖和Marlet,2020年】。我们还报告了我们提出的方法在使用无示例的情况下的性能,以便与没有示例的方法(表示为“最少-NE”)进行公平比较。

From Tab.2, we have the following observations: (1) LEAST performs better on novel classes than all competitors, with a second highest performance on base ones. TFA freezes the whole feature extractor so that it obtains the best base AP that is a little higher than ours, but its performance on novel classes is explicitly limited. Compared with these methods that have a large performance gap between base and novel classes, LEAST can better balance these two domains and thus have a much higher HM value. Even without exemplars, ours can still achieve promising results on avoiding forgetting and adapting to novel classes. This can validate the effectiveness of using knowledge distillation and transferring with less unnecessary weight adaptation. (2) Using a few exemplars selected by our proposed approach is generally beneficial to iFSD. It can largely improve the performance on previous tasks, and then the HM value, which indicates that previous discriminative features are better preserved.
从表2,我们有以下观察结果:(1)在新类中,最少的表现优于所有竞争对手,在基本类中表现第二高。TFA冻结了整个特征提取器,以便获得比我们的略高的最佳基AP,但其在新类上的性能明显受限。与这些基类和新类之间存在较大性能差距的方法相比,LEAST可以更好地平衡这两个领域,因此具有更高的HM值。即使没有范例,我们仍然可以在避免遗忘和适应新课程方面取得有希望的结果。这可以验证使用知识提取和转移的有效性,同时减少不必要的权重调整。(2) 使用我们提出的方法选择的一些示例通常对iFSD有益。它可以大大提高以前任务的性能,然后提高HM值,这表明以前的鉴别特征得到了更好的保留。
Continual iFSD results. We then evaluate the iFSD performance under the continual setting, where the novel classes are added one at a time with |Cn| model updates. We report the harmonic mean performance of base classes and all novel classes added so far in the bottom of Fig.3. We can see that as novel classes are processed sequentially, the performance of LEAST first decreases and then levels off. While without exemplars for base classes, LEAST-NE decreases to 0 after 15 incremental transfer stages. This means that the previously learned knowledge is catastrophically forgotten. Comparing with typical iFSD performance (i.e. AP 18.2 and AR 33.9), the final performance (i.e. AP 12.1 and AR 26.5) of continual iFSD after 20 sessions is lower. It is reasonable since fewer model updates naturally forget less previous knowledge. As ONCE does no report the harmonic mean and has no released code, it does not appear in Fig.3. Yet we can find its performance on the typical setting (i.e. AP 2.2 and AR 10.9) is lower than ours on the continual setting. As the continual setting is more challenging, we can legitimately infer that LEAST consistently outperforms it.
持续的iFSD结果。然后,我们在连续设置下评估iFSD性能,在该设置下,通过|Cn|模型更新一次添加一个新类。我们在图3的底部报告了基类和迄今为止添加的所有新类的调和平均性能。我们可以看到,随着新类的顺序处理,LEAST的性能先是下降,然后趋于平稳。在没有基类示例的情况下,经过15个增量传输阶段后,LEAST-NE将降至0。这意味着以前学到的知识被灾难性地遗忘了。与典型的iFSD表现(即AP 18.2和AR 33.9)相比,20个循环后持续iFSD的最终表现(即AP 12.1和AR 26.5)更低。这是合理的,因为较少的模型更新自然会忘记较少的以前的知识。由于ONCE没有报告谐波平均值,也没有发布代码,因此它没有出现在图3中。然而,我们可以发现其在典型设置(即AP 2.2和AR 10.9)上的性能低于我们在连续设置上的性能。由于连续设置更具挑战性,我们可以合理地推断,最不稳定的设置优于连续设置。

Cross-domain iFSD evaluation. We also evaluate the typical iFSD performance in a cross-domain setting from MSCOCO to Pascal VOC. The performance is only evaluated on novel classes since VOC contains no objects of base classes. As shown at the top of Fig.3, our method (either with or without the selected exemplar set) significantly outperforms the previous competitors in terms of both AR and AP, which verifies the efficacy of LEAST in the cross-domain setting. Comparing with the results of MS-COCO in Tab.2, the performance on VOC is higher on both AP and AR. The performance gap is reasonable since MS-COCO images contain more complex scenarios from both base and novel objects.
跨域iFSD评估。我们还评估了从MSCOCO到Pascal VOC的跨域设置中典型的iFSD性能。由于VOC不包含基类的对象,因此性能仅在新类上进行评估。如图3顶部所示,我们的方法(有或没有选择的样本集)在AR和AP两方面都显著优于之前的竞争对手,这验证了LEST在跨域设置中的有效性。与表2中MS-COCO的结果相比,AP和AR的VOC性能都更高。性能差距是合理的,因为MS-COCO图像包含来自基本目标和新目标的更复杂场景。
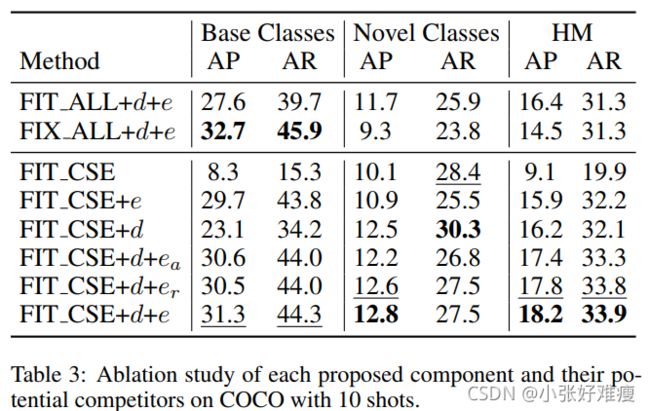
Ablation studies. In the ablation study, we test the influence of the proposed transfer strategy, distillation loss, and the exemplar selection method for iFSD in Tab.3. It is clear that the proposed transfer strategy FIT CSE significantly outperforms FIX ALL and FIT ALL. Meanwhile, the distillation loss (denoted by d) largely improves novel class performance since it can preserve the previously learned discriminative information. Besides capable of remembering base classes, the proposed clustering-based exemplar selection algorithm (e) performs better than random selection (er) and class-average based selection (ea) [Rebuffi et al., 2017], when we use the same number of selected exemplars for a fair comparison. It shows that the proposed selection method preserves more modes for base classes.
消融研究。在消融研究中,我们测试了表3中提出的转移策略、蒸馏损失和iFSD样本选择方法的影响。显然,建议的转移策略FIT CSE明显优于FIX ALL和FIT ALL。同时,蒸馏损失(用d表示)可以保留以前学习到的鉴别信息,因此极大地提高了新类的性能。除了能够记住基类外,当我们使用相同数量的选定样本进行公平比较时,所提出的基于聚类的样本选择算法(e)的性能优于随机选择(er)和基于类平均数的选择(ea)[Rebuffi et al.,2017]。结果表明,所提出的选择方法为基类保留了更多的模式。
5 结论
We delved into the realistic and challenging problem: classincremental few-shot object detection, which aims at incrementally detecting novel objects from just a few labeled samples while without forgetting the previously learned ones. We proposed a generic and effective method that uses relatively fewer training resources and can still have stronger transfer capability with less forgetting. Extensive experimental results under different settings verified its effectiveness.
我们深入研究了一个现实且具有挑战性的问题:经典增小样本目标检测,其目的是在不忘记先前学习的目标的情况下,从少量标记样本中增量检测新目标。我们提出了一种通用而有效的方法,该方法使用相对较少的训练资源,并且在较少遗忘的情况下仍然具有更强的传输能力。在不同环境下的大量实验结果验证了其有效性。