【原创】工作流引擎运转模型之--终极利器退回时回收分支算法
得到终极回收算法之前过程,分享一下所经历的过程
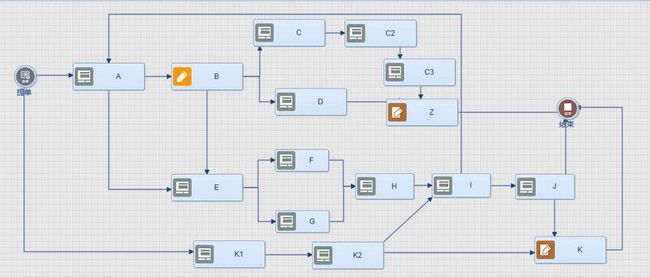
图中B是多步发散并行活动,Z和K是并行聚合活动
经缜密思考总结如下规则:
我们先从最简模型的单步退回着手分析:
单步退回:
规则1:B退回A
A的发散类型是:异或SplitXOR,执行:完成B,创建A活动实例。(这种情况占多数)
A的发散类型是SplitOR或SplitAnd,执行完成B,以A是基准寻找所有由A活动实例所产生的后继路径产生的正在进行中的活动实例。进行回收,创建A活动实例。
规则2:C3退回C2(并行区内向退回),执行:同理规则1。
规则3:C退回B(并行区内向区边退回,执行:同理规则1。
规则4:Z退回C3(并行结束边向并行区域内退回),我认为这是不合理的,因为Z退回了C3后Z需要等候D的到达才能聚合完成,而Z退回C3只产生C3的活动实例,所以这时候Z就永远不会聚合了,导致流程死掉。所以聚合活动不可单步退回上一步。
跨步或任意退回:
规则5:C退回A,回收总规则:退回到哪一活动,就以那一活动为基准向后寻找所有由这一活动定义产生出去的活动实例为超点的所有后继活动实例,取消正在进行中的活动实例。注意:防止死循环
引发命案:
假如是I退回A,根据回收总规则而会进行A活动后的所有活动实例进行回收,I在K0与K的并行区域内,此时K3路径来向的活动实例并没有被回收,这情况发生在I活动实例是由K2产生的。如果I实例是由H产生的而不存在命案。但如果是则K2产生的,命案就发生了。由此我们思考到总规则2:
总规则2:退回时只能退回到曾经走过的历史轨迹。那么I退回A一定是曾经从A发出来的路径,则从A开始向后面的所有活动实例回收不会有错。
好像有了总规则2问题就解决了,看似解决了,还依然存在命案问题,原因是如果A走到I,然后I退回提单,提单向K1路径下发直到I,那此时A来向路径和K1来向路径都是曾经走过的路径,此时退回A命案问题还是和原来一样。
由此又想到了总规则3.
总规则3:再加上以以I活动实例为基准点向所有前继活动描述回收。但这样只有K2前面的会被回收,K2后面的不会被回收。好像问题总是存在,不过能应用到这种情况的需求已经是相当少的了,没有完美的解决方法,只有更好的解决方法,不妨就先到此为止。不考虑K2后面不会被回收的情况了。视为到此是边界了。多数情况下即使有这样的需求也可以通过流程的设计和需求协商解决。其实上图中存在很多不合理的流程路径设计。比如从A出发走到J,J向K聚合时就是一个不合理情况,因为K要等K3和J,而K3压根没有产生过实例,所以流程会死掉。
退回的定义
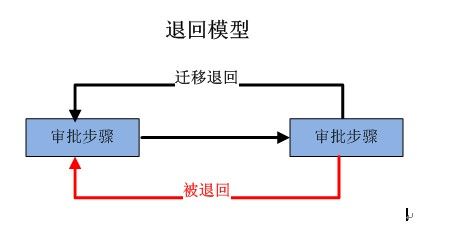
退回,在有的应用中叫“回退”。退回是中国特色的一种方式,经常也是隐性的,比如申请经费可能由于资料不足被退回来补充资料,像这样的例子有非常多,也很常见。
退回是工作流参与者对自己“待办任务”(实际是对工作项)的一种操作,即参与者主动回退待办任务列表中的任务到已经执行过的人工节点。
回退的情况实际上是非常复杂的,有串行上的退回,也有并行内的退回,并行区内退回到并行区外,从分支退回到主干等,从主干退回到分支内,多重聚合的退回等。退回过程中会发生很多事情,也会可能导致重走路径时产生重复路径。
隐匿退回方式的支持力度也往往成为评价一个工作流引擎是否具有中国特色和引擎强弱的能重要批价指标。
下面我们依次来看看种情况的退回模型以及F2在这方面强大的支持力度的算法实现。
如下图所示,有任务A到任务B 属于正常发送,但从任务B到任务A,则出现两种情况:
(1)迁移退回:正常发送,如图中B—A黑色线;(迁移的退回严格上没有退回的意义存在,只是一种表象,与正常向后续节点迁移没有区别,所以迁移式的退回不是本节讨论的重点)
(2)被退回:(也称隐匿退回,流程图中不存在线)可能因为某些特殊原因,被任务B退回,要求任务A重新办理,如图中B—A红色线。虽然都是从B到A,代表的意义却完全不同。(本章所讨论的退回模型都是讨论这种情况)
隐式退回类型有以下四种类型
1 仅可退回到提单
2 仅可退回到上一步
3 仅可退回到上一步或提单
4 退回任意历史步骤
串型退回模型分析
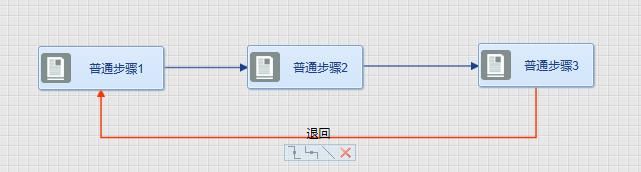
这种情况最为简单,后续节点可以回退到前续任意人工步骤节点。回退后,节点重走。
(实际中没有退回线,这里是为了使用图表述说明清晰特意标上了线,本文中后面也是如此)
异或分支退回模型分析
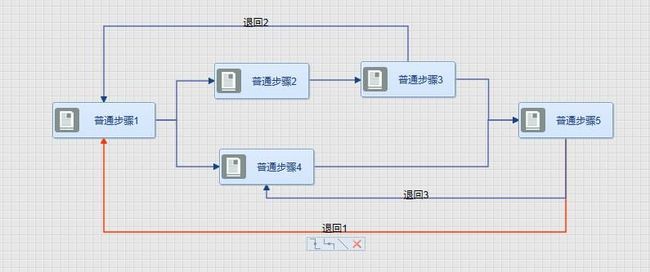
这种情况也相对简单,实际执行的分支上的节点可以回退到前续任意人工节点(不区分主支和分支)。同样,主支上的节点也可以回退到任意实际执行的分支上的节点。
可能的问题:多次回退后的回退节点选择。例如:第一次流程经过节点2、节点3到达节点5,节点5可以回退到节点1、节点2和节点3的任意一个,此时节点5回退到节点1,节点1重走,这一次流程改为经过节点4到达节点5,节点5回退时如何选择回退节点?F2有退回回收器,当节点5退回到节点1时,会回收至节点1曾经走过的路径,这样此时节点5只允许回退到节点4和节点1,不允许回退到节点2和节点3。(因为节点2节点3的历史路径已被回收)
并发(或多重发散)退回模型分析
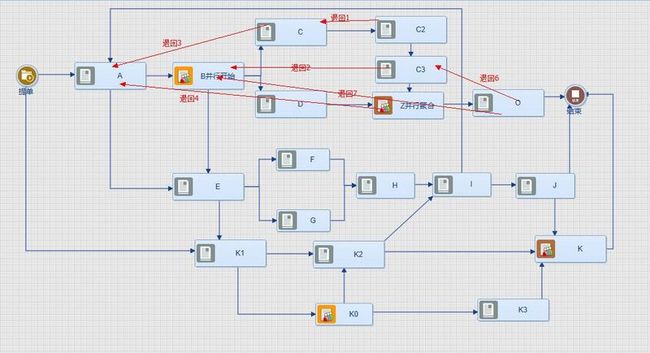
图示使用F2纯Web\JS流程设计器拖拉拽设计而成。
这个流程图相对有点复杂,我们看来来F2所支持的回退情况:
1、 退回1
C2退回C,显然这是并行分支间的退回,相对简单。也没有什么好说的。
2、 退回2
C3退回B,这是并行分支间退回到并行发散开始节点,此时需要回收D路径上的分支,并取消这分支上所有产生的任务,对于C路径上已走过的任务需要进行实例迁移的回收。
这种模式很多工作流引擎都不支持,多数引擎只能支持分支内部的退回即“退回1”所讲的情况,至于分支内退回到并发开始或者并发节点之前的节点多数不支持,原因实际上的实现比较复杂远远比上面的图示例子要复杂多了。
对于F2来说,只要调用回收器就能智能回收其因退回需要回收的路径及任务,F2有站良好的轨迹跟踪。当C3退回B时不单单要回收B=》C=》C2,还要回收B=》 D,还有B=》E=》F, F后面还有很多等等。
从E出来后面可能还更复杂,因为这些我们没有全部能画出来,但实际要支持C3退回B就必须支持因退回而对其它分支产生的影响。所以回收器是必须准确进行回收。
有这退回的支持,也表示后面几种复杂的退回模型也将得到支持。后面会详细说明回收器的回收算法,本人经过N多种情况的精心思考,在此也感谢园子里“路过秋天”的提示,让原来很复杂的算法变得简单很多。才有这这退回回收器的终极利器。
3、 退回3
C退回A,这是从并行聚合环节退回到并行开始节点之前,与退回2的情况类似。
4、 退回4
Z退回A,这是从并行分支退回到并行开始节点之前,与退回2的情况类似,只是要多回收一个路径A到B这节路径也得回收。
5、 退回7
O退回B,这是从并行聚合之后的节点退回到并行开始节点,最终也是要进行历史轨迹路径的回收,交由回收器回收。
6、 退回6
O退回C3,这是从并行聚合之后的节点退回到并行分支间节点,这种退回实际是不合理的,因为这会导致聚合节点Z会永远等不来D,导致流程卡死。所以这种退回不合法,故也不支持。
终极利器-工作流引擎退回回收分支算法
算法内容:从节点9(假设其个节点)退回到节点1(假设其个节点)的退回时,从节点9寻找轨迹前继,如果是异或节点而直接回收,然后继续寻找前续实例,凡遇到并行发散或多重发散而以此并行或多重发散节点向后续活动实例回收轨迹实例,回收完之后继续向前,直到节点1或者提单节点为止。
算法举例说明:
如上图中,退回算法是适合于任何节点退回到另一个节点的,我们找个复杂一些节点退回,比如从O退回A,那么回收器的执行过程是:
首先以O活动实例为开始向前寻找走过的实例轨迹,回收Z=》O迁移实例,判断Z的节点类型,此时Z为异或发散类型,而直接回收Z活动实例,再从Z向前找到
C3=>C2=>C=>B和D=>B那么这些活动都会被直接回收,因为C C2 C3 D都是异或发散类型,所以不会有多个后续实例存在,进行直接回收,这里当来到B时,发现B是并行发散类型,这时回收器会转向从B开始向后搜索,会搜索到B=>E=>F=>H=>I=>A=>B(搜索到自己会结束,避免死循环),这里搜索器会智能发现B=>C2=>C3=>Z和B=>D=>Z已经被回收过了所以不处理。此时回收掉了B=>E=>F=>H=>I=>A=>B,最后回收B活动实例,然后继续找B的前继找到了A,此时回收A=》B的迁移实例,最后判断已经是A目标要退回的环节了,回收结束退出。
应用上面的算法依此类推,无论多复杂的情况这算法都能解决因退回而引起需要撤消取消的其它路径的问题。还可以解决更多的问题,如下面的引申应用。
另外因聚合完毕的回收:
此算法做一些终止开关判断就可应用到多重聚合时的回收,比如Z是多重聚合,条件是只要有一条分支到达就聚合完成,那么举例B同时发给了C和 D那当D先到这Z时,C路径上的还停留在C2,那么这时会因D的到达需要回收C=》=》C2。假设C2又是一个发散节点也不成问题,回收器会自动回收因C2产生出去的实例活动节点。直到寻找到一个并行或多重发散节点为止。
另外因结束完毕的回收:
假设有路径从A=>B=>E=>F=>H=>I=>J=>结束由J走向结束时,因为结束发生引擎O路径来向的活动轨迹需要回收,应用回收器进行回收,此时发现有一段重叠的轨迹,即A=》B,那么这段路径不应该被回收。而B到O之间的段的轨迹实例需要被回收。
关于业务补偿
业务补偿是一个很重要的概念,在回退的情况下需要相应的回退部分业务操作。
这里由引擎提供统一的接口,返回回退路径,由客户自定义代码进行匹配处理。
关于实现
很多工作流引擎通过流程定义时绘出回退迁移线来显式的支持回退,即使用迁移的方式来作为回退,实际这种不叫回退,只是用迁移发向前发送,
只是这种发送是之前的环节而已,这种实现在业务复杂的情况下会造成流程图的异常烦琐(将有非常多的杂线),
但是比较清晰,实现比较容易与向后续环节迁移没有区别。 隐式实现相比而言优点更多,也更符合中国特色和中国人的思维习惯,
也显得引擎对回退的支持力度更强大。
这也是评价一个工作流引擎是否灵活强大的重要指标。