【Python语言程序设计】20级实验参考合集
文章目录
- 实验1 Python程序控制结构
-
- 实验目的及要求:
- 问题1:
- 问题2:
- 问题3:
- 问题4:
- 实验2 组合数据类型的应用
-
- 实验目的及要求:
- 问题1:
- 问题2:
- 问题3:
- 问题4:
- 实验3 函数的设计和使用
-
- 实验目的及要求
- 问题1:
- 问题2:
- 问题3:
- 实验4 面向对象的程序设计
-
- 实验目的及要求
- 问题1:
- 问题2:
- 实验5 文件操作和异常处理
-
- 实验目的及要求
- 问题1:
- 问题2:
- 问题3:
- 问题4:
- 问题5:
- 实验6 Python模块
-
- 实验目的及要求
- 问题1:
- 问题2:
- 实验7 文本处理和正则表达式
-
- 实验目的及要求
- 问题1:
- 问题2:
- 问题3:
- 实验8 网络数据爬取
-
- 实验目的及要求
- 问题1:
- 问题2:
- 实验9 GUI图形化用户界面
-
- 问题:口算题生成系统
仅供参考!
实验1 Python程序控制结构
实验目的及要求:
-
掌握分支结构、循环结构和range()函数的使用;
-
理解Python中选择和循环结构与C/C++等语言的异同点;
-
能够熟练使用input()和 print()函数进行数据的读入和输出;
-
能够通过设置print()函数的参数来控制数据的输出格式;
-
熟练掌握循环语句块的定义和使用。
问题1:
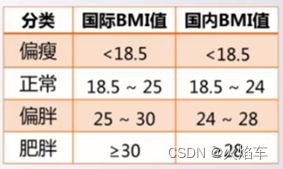
输入体重和身高值,根据BMI计算公式和国内、国际的BMI分类指标,分别输出国内、国际评价标准中“偏瘦”、“正常”等信息。

w = float(input("请输入体重(kg)"))
h = float(input("请输入身高(m)"))
h = h * h
bmi = w/h
if bmi < 18.5 :
print("国际评价:偏瘦")
print("国内评价:偏瘦")
elif bmi < 24 :
print("国际评价:正常")
print("国内评价:正常")
elif bmi < 28 :
if bmi < 25 :
print("国际评价:正常")
else:
print("国际评价:偏胖")
print("国内评价:偏胖")
else:
if bmi < 30 :
print("国际评价:偏胖")
else:
print("国际评价:肥胖")
print("国内评价:肥胖")
问题2:
使用循环结构和range()函数求1-100内所有奇数的和,并输出;
s = 0
for i in range(1,101,2):
s += i
print(s)
问题3:
接收用户输入的起始整数和终止整数(三位),计算两个整数范围内所有的水仙花数并输出;
start = int(input("请输入起始点(三位数)"))
end = int(input("请输入终止点(三位数)"))
def Func(x) :
a = x//100
b = x//10%10
c = x%10
s = a**3+b**3+c**3
if s == x :
return 1
else :
return 0
for i in range(start,end+1) :
if Func(i) == 1 :
print(i)
问题4:
按要求格式实现进度条程序的设计、实现和调试。
提示:
perf_counter()是第三方库time的函数
perf_counter()返回当前的计算机系统时间
只有连续两次perf_counter()进行差值才能有意义,一般用于计算程序运行时间。
版本1:

版本2:

版本3:

import time
scale = 100
print("执行开始".center(scale//2,"-"))
cnt = 0
start = time.perf_counter()
for i in range(0,101):
cnt += 1
a = '*' * i
b = '.' * (scale-i)
c = (i/scale)*100
print('%3.0f' % c + "%", end='')
if cnt % 13 == 0 :
print()
dur = time.perf_counter() - start
#print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='')
time.sleep(0.1)
print("\n"+"执行结束".center(scale//2,'-'))
print("执行开始".center(scale//2,"-"))
cnt = 0
start = time.perf_counter()
for i in range(scale+1):
cnt += 1
a = '*' * i
b = '.' * (scale-i)
c = (i/scale)*100
dur = time.perf_counter() - start
print("{:^3.0f}%[{}->{}]".format(c, a, b))
#print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='')
time.sleep(0.1)
print("\n"+"执行结束".center(scale//2,'-'))
import time
scale = 10
print("执行开始".center(scale//2,"-"))
cnt = 0
start = time.perf_counter()
for i in range(scale+1):
cnt += 1
a = '*' * i
b = '.' * (scale-i)
c = (i/scale)*100
dur = time.perf_counter() - start
print("{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur))
time.sleep(0.1)
print("\n"+"执行结束".center(scale//2,'-'))
实验2 组合数据类型的应用
实验目的及要求:
-
熟悉Python列表、元组、字典、集合的创建与删除,;
-
熟练掌握列表推导式的用法;
-
熟练掌握切片的用法,能够使用切片访问列表、元组、range对象的元素,能够使用切片为列表增加、删除、修改元素;
-
了解列表和元组的区别;
-
能够利用列表和字典解决实际问题。
问题1:
输入一个字符串判断是否是回文字符串(利用列表切片和不用切片分别完成)。
s = input("输入一个字符串:")
t = s[::-1]
if(t == s) :
print("是回文字符串")
else :
print("不是回文字符串")
s = input("输入一个字符串:")
l = len(s)
left = 0
right = l - 1
while left <= right :
if s[left] == s[right] :
left += 1
right -= 1
else :
break
if left > right :
print("是回文字符串")
else :
print("不是回文字符串")
问题2:
随机生成10个[0,10]范围的整数,分别组成集合A和集合B,输出A和B的内容、长度、最大值、最小值以及它们的并集、交集和差集。
import random
random.randint(start,stop) #生成[start,stop)的整数
import random
a = []
b = []
for i in range(0,10) :
x = random.randint(0,10)
y = random.randint(0,10)
a.append(x)
b.append(y)
print("a的内容:" ,end=' ')
print(a)
print("a的长度:",end = ' ')
print(len(a))
print("a的最大值:",end = ' ')
print(max(a))
print("a的最小值:",end=' ')
print(min(a))
print("b的内容:" ,end=' ')
print(b)
print("b的长度:",end = ' ')
print(len(b))
print("b的最大值:",end = ' ')
print(max(b))
print("b的最小值:",end=' ')
print(min(b))
print("a和b的交集:",end=' ')
print (list(set(a).intersection(set(b))))
print("a和b的并集:",end=' ')
print (list(set(a).union(set(b))))
print("a和b的差集:",end=' ')
print (list(set(b).difference(set(a))))
问题3:
取出"My house is full of toys"中每个单词的首字母并存储到列表对象中,要求给出两个版本的实现:不使用列表推导式和使用列表推导式。
s.split() #将字符串s按照空格分隔,返回分隔后的字符串列表
s = "My house is full of toys"
list_s = [i[0] for i in s.split(" ")]
print(list_s)
s = "My house is full of toys"
list_s = []
l = len(s)
for i in range(0,l):
if(i == 0 or s[i-1] == ' '):
list_s.append(s[i])
print(list_s)
问题4:
已知,以下食物每100g的卡路里如下:
小米粥 45,粗粮馒头 223,全麦面包 235,瘦猪肉 143,鸡翅 194,培根 181,火腿肠 212。
①建立一个空的字典,把上述键值对依此添加进去。通过循环形式,依次显示所有元素,显示格式如“我吃了二两”+“小米粥”,“增加了”+“45”卡路里。
②设计一个“你想知道哪种食物的卡路里?”系统,系统运行时用户可以输入要查询的食物名称,系统显示该食物对应的热量,如果用户输入了不存在的食物,则系统提示“没有该食物的数据!”
mp = {"小米粥":45,"粗粮馒头":223,"全麦面包":235,"瘦猪肉":143,"鸡翅":194,"培根":181,"火腿肠":212 }
for x in mp :
print("我吃了二两" + x + "增加了" + str(mp[x]) + "卡路里")
mp = {"小米粥":45,"粗粮馒头":223,"全麦面包":235,"瘦猪肉":143,"鸡翅":194,"培根":181,"火腿肠":212 }
x = input("你想知道哪种食物的卡路里?")
if(x not in mp) :
print("没有该食物的数据!")
else:
print(mp[x])
实验3 函数的设计和使用
实验目的及要求
-
理解默认值参数、关键参数和可变长度参数的用法;
-
理解并熟练运用lambda表达式,尤其是lambda表达式做其他函数参数的用法;
-
理解变量作用域、局部变量、全局变量的概念。
-
掌握自定义函数的定义和调用方法。
问题1:
定义函数sum1(),函数可以接收用户输入的若干个整数,函数返回值为这些数中所有偶数的和。调用函数,分别求2,1,6,8,9,10,5所有数的和并输出。
num = [2,1,6,8,9,10,5]
def sum1() :
s = 0
for i in num:
if i % 2 == 0 :
s += i
return s
print(sum1())
问题2:
定义函数calScore1(),函数可接收某门课程的名称以及若干同学该课程的分数,函数返回最高分和学生名。调用函数,对以下两组数据进行处理。


import operator
dict1 = {}
def calScore1() :
course = input()
while True :
try:
a,b = input().split()
dict1[a] = int(b)
except:
break
print(course + "最高分名字及分数:")
return max(dict1.items(),key=operator.itemgetter(1))
res = calScore1()
print(res)
问题3:
定义函数,接收若干个整数,返回所有的全数字(pandigital)。调用函数,输入一组数据进行处理。
如果一个n位数刚好包含了1至n中所有数字各一次则称它们是全数字(pandigital)的,例如321、1324、1243就是全数字的,2354、322不是全数字。
def pandigital(x) :
mp = {}
lenth = len(x)
x = int(x)
while(x) :
t = x % 10
if t not in mp :
mp[t] = 1
else :
mp[t] = 2
if t<1 or t>lenth or mp[t] != 1:
return False
x = x//10
return True
a = input()
if(pandigital(a)) :
print("是全数字")
else :
print("不是全数字")
实验4 面向对象的程序设计
实验目的及要求
-
熟练Python类定义语法;
-
掌握类成员、实例成员和私有成员、公有成员的概念;
-
理解继承的机制;
-
能够定义类及成员并创建对象。
问题1:
定义point类,具体要求如下:
(1)类中定义构造函数,实现对实例属性x和y的初始化
(2)类中定义+运算符重载函数,实现两个点对象相加运算,返回点对象,其x和y坐标分别为参与运算的两个点对象的x坐标和,y坐标和;
(3)类中定义点对象(x1,y1)转字符串方法,返回“(x1, y1)”字符串;
(4)类中定义*运算符重载函数,实现1个点对象(x1,y1)和整数K的乘法运算,返回点对象,其x和y坐标分别为(kx1, ky1);。
(5)设计point类的测试数据,并实现对point类的测试程序。
class point :
def __init__(self,x,y):
self.x = x
self.y = y
def __add__(self, other):
return point(self.x+other.x,self.y+other.y)
def __str__(self):
return "({},{})".format(self.x,self.y)
def __mul__(self, other):
return point(other*self.x,other*self.y)
p1 = point(3,6)
p2 = point(6,9)
r1 = p1 + p2
print(r1)
r2 = p1 * 5
print(r2)
问题2:
建立Person类,Student类和Employee类,设计类之间的继承关系,通过实现类来验证类中私有数据成员,子类和父类的继承关系,子类构造函数中调用父类构造函数,以及多态机制等知识点。
class Person :
def __init__(self):
self.pname = 'AA'
def talk(self):
print("Person is talking...")
class Student(Person) :
def __init__(self):
self.sname = 'BB'
Person.__init__(self)
def walk(self):
print("Student is walking...")
class Employee(Person) :
def __init__(self):
self.ename = 'CC'
super(Employee,self).__init__()
def talk(self):
print("Employee is talking...")
st = Student()
em = Employee()
st.walk()
st.talk()
em.talk()
print(st.sname)
print(st.pname)
print(em.ename)
print(em.pname)
实验5 文件操作和异常处理
实验目的及要求
-
掌握数据文件操作的一般流程;
-
理解数据编码和解码的含义;
-
掌握文本数据文件常用的数据读写方法;
-
掌握二进制数据文件常用的数据读写方法;
-
能够根据要求实现对数据文件的读取和分析。
问题1:
在只打开给定的data.txt文件一次的情况下,实现对文件内容的两次读取:第一次连续读取全部奇数行的数据并输出;第二次连续读取全部偶数行的数据,对数据进行utf-8编码后输出。
i = 1
j = 1
odd = []
even = []
with open('data.txt','r') as fp :
for line in fp.readlines() :
if i % 2 == 1 :
odd.append(line)
else :
even.append(line)
i = i + 1
for x in odd :
print(x)
for x in even :
print(x.encode("utf-8"))
问题2:
输入一个路径,输出该路径下的所有文件列表;计算实验数据目录中的sea.jpg图片文件的大小并输出;对实验数据目录中的osData.txt文件进行操作:判断osData.txt文件是否存在,如果存在则在文件的末尾追加“I am ok.”字符串,如果文件不存在,则通过程序建立新文件并在文件中写入“My name is jack ”。
import os
#输出文件列表
filepath = input("请输入一个路径:")
for x in os.listdir(filepath) :
print(os.path.join(filepath,x))
#输出图片大小
print("图片大小:" + str(os.path.getsize("./sea.jpg")) + " B")
#判断
if os.path.exists("./osData.txt") :
with open("./osData.txt",'a') as fp :
fp.write("I am OK")
else :
with open("./osData.txt",'a') as fp :
fp.write("My name is Jack")
问题3:
编写程序接收用户输入的水果销售单价和数量,计算并输出水果的销售总额。要求程序能够捕获并处理当用户输入非数值类型的单价和数量时系统产生的异常,当捕获到异常时,使用单价和数量的默认值0进行总额的计算,并给用户输出相应的错误提示信息。
count = int(input("Enter count: "))
price = float(input("Enter price for each one: "))
Pay = count * price
print("The price is: ", Pay)
count = 0
price = 0
try:
count = int(input("Enter count:"))
price = float(input("Enter price for each one:"))
except ValueError:
print("请输入整数或浮点数")
Pay = count * price
print("The price is:",Pay,"yuan")
问题4:
读取给定的score.txt中保存的分数信息,按用户输入的学号或者姓名对学生的信息进行查询和输出(用户只输入一个查询数据),要求实现模糊条件查询,如姓胡的同学的成绩,学号中包括19字符的同学的成绩,将查询到的学生学号、姓名、总成绩写入到sum_score.csv文件。
import operator as op
k = input("输入需要查询的数据:")
with open('.\score.txt', "r") as fp:
for line in fp.readlines():
if op.contains(line, str(k)):
line = line[:-1]
dic = line.split('\t')
i = 1
s = 0
with open("./sum_score.csv","a") as fp :
for x in dic :
if i == 1 or i == 2 :
fp.write(x+' ')
else :
s += float(x)
i+=1
fp.write(str(s) + '\n')
问题5:
编写程序实现:在实验数据目录中建立子目录copyImg;将实验数据目录中的sea.jpg图片文件拷贝10份到建立的copyImg目录中,文件名依次为seaCopy1.jpg , … , seaCopy10.jpg。
import os
os.mkdir('copyImg')
img = open('sea.jpg','rb')
data = img.read()
img.close()
for i in range (1,11) :
fnew = open(f".\copyImg\seaCopy{i}.jpg",'wb')
fnew.write(data)
fnew.close()
print('图片拷贝完成')
实验6 Python模块
实验目的及要求
-
理解模块在提高程序可扩展性和复用性方面的作用;
-
掌握模块定义和调用的基本语法结构;
-
能够根据需求定义模块文件,并实现函数成员和类等组成部分;
-
理解py文件两种不同执行方式的差异;
-
能够根据需求在使用的开发环境中安装需要的第三方库;
-
能够使用jieba和wordcloud等库分析文本数据,并制作词云对象。
问题1:
(1)定义calculation模块(module),具体要求如下:
-
模块中定义Sum1函数,可以计算两个数值的和并返回;
-
模块中定义Mul函数,可以计算两个数值的乘积并返回;
-
在模块中定义CountV函数,可以计算列表或元组数据中的最大和最小值,并返回;
(2)构建test.py文件,在文件中通过调用calculation模块,实现计算对模块的测试,具体要求如下。
-
建立列表ls1=[10,30,90,94,99,60,80,6,89],通过calculation模块的CountV函数计算最大和最小值,并输出;
-
通过calculation模块的Sum1函数,计算100和 200的和并输出;
-
统计calculation模块的Mul函数,计算100和 200的乘积并输出。
def Sum1(a, b):
return a + b
def Mul(a, b):
return a * b
def CountV(list):
return [max(list),min(list)]
from calculation import *
list1 = [10,30,90,94,99,60,80,6,89]
print("list1最大值最小值分别为:",CountV(list1))
print("100和200的和为:",Sum1(100, 200))
print("100和200的乘积为:",Mul(100, 200))
问题2:
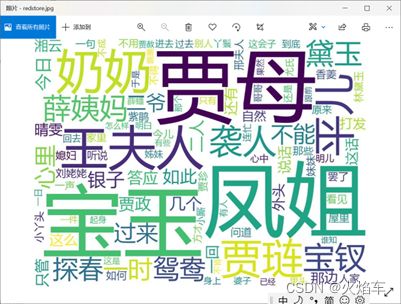
通过读取红楼梦.txt文本数据,使用jieba和wordcloud库,基于红楼梦中人物的出现频次制作词云对象。
(1)输出出现次数最多的五个人;
(2)制作红楼梦人物词云。要求能够对词云对象中出现的常见问题进行处理(如词云中显示的主要词语不能为非人物名称数据,且同一人物名称不能重复出现)。将红楼梦中的下列词忽略:
{‘什么’,‘一个’,‘我们’,‘那里’,‘你们’,‘如今’,
‘说道’,‘知道’,‘起来’,‘姑娘’,‘这里’,‘出来’,
‘他们’,‘众人’,‘自己’,‘一面’, ‘太太’,‘只见’,
‘两个’,‘没有’,‘怎么’, ‘不是’, ‘不知’,‘这个’,
‘听见’, ‘这样’, ‘进来’, ‘东西’, ‘告诉’,‘就是’,
‘咱们’, ‘回来’, ‘大家’, ‘只是’, ‘只得’,
‘老爷’, ‘丫头’, ‘这些’, ‘不敢’,‘出去’,‘所以’,
‘不过’, ‘的话’, ‘姐姐’, ‘不好’}
import jieba
import wordcloud
txt = open('红楼梦.txt', 'r', encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
counts[word] = counts.get(word, 0) + 1
excludes = {'什么','一个','我们','那里','你们','如今',
'说道','知道','起来','姑娘','这里','出来',
'他们','众人','自己','一面', '太太','只见',
'两个','没有','怎么', '不是', '不知','这个',
'听见', '这样', '进来', '东西', '告诉','就是',
'咱们', '回来', '大家', '只是', '只得',
'老爷', '丫头', '这些', '不敢','出去','所以',
'不过', '的话', '姐姐', '不好'}
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
i=1
for item in items:
if i>5:
break
i+=1
print(item[0], '出现了:', item[1], '次')
newtxt=' '.join(words)
wc=wordcloud.WordCloud(background_color='white',font_path='msyh.ttc',height=500,width=500,max_words=40,max_font_size=80,stopwords=excludes,min_word_length=2)
word=wc.generate(newtxt)
word.to_file(r'.\hongloumeng.png')
实验7 文本处理和正则表达式
实验目的及要求
-
熟悉使用正则表达式提取数据的一般流程;
-
掌握正则表达式的基本语法结构;
-
能够根据数据提取需求设计正则表达式;
-
理解正则表达式贪婪匹配模式的工作原理;
-
能够根据设计的正则表达式使用python中的re库进行实现。
问题1:
给定music.html文件,请从其中提取出所有歌曲的演唱者、歌名和链接的歌曲文件名数据,并将结果写入到songlist.txt文件中,其中每行存储一条歌曲数据,每条歌曲信息:歌曲名称、作者、歌曲文件名使用空格进行间隔。参照结果如下:
沧海一声笑 任贤齐 2.mp3
import re
musicinfo = ''
with open('music.html','r', encoding='utf-8') as f :
musicinfo = f.read()
pat = r"""(.+?)"""
datas = re.findall(pat,musicinfo)
with open('songlist.txt','w') as f :
for i in datas :
x = i[::-1]
for j in x :
f.write(j+' ')
f.write('\n')
问题2:
为了分析客户对屏幕的评论数据,需对数据进行标准化处理,如把多个同义词替换为同一个词。请将下列评论数据中的“触摸屏”和“显示屏”替换为“屏幕”:“广告说这个触摸屏很好,推销的人也说屏幕好,但我觉得这个显示屏糟透了”。
import re
info = "广告说这个触摸屏很好,推销的人也说屏幕好,但我觉得这个显示屏糟透了"
pat = "(触摸屏)|(显示屏)"
s = re.sub(pat,'屏幕',info)
print(s)
问题3:
给定网页数据文件ldu.html,请从其中提取出所有学院的名称并输出。
import re
info= ''
with open('ldu.html','r', encoding='utf-8') as f :
info = f.read()
pat = r"""(.+?)"""
datas = re.findall(pat,info)
for x in datas :
print(x)
实验8 网络数据爬取
实验目的及要求
-
熟悉互联网数据爬取的一般流程;
-
掌握requests库的常用函数;
-
能够根据数据获取需求设计数据爬取方案;
-
理解requests库的get方法的工作原理;
-
能够基于python中的re库和requests库对网络爬虫方案进行实现。
问题1:
给定学校新闻页面url列表,内容为https://www.news1.ldu.edu.cn/ldyw1/87.htm到https://www.news1.ldu.edu.cn/ldyw1/1.htm,请依次从每个页面中提取出所有的新闻标题和发布时间数据,并将结果写入到newsData.txt文件中,其中每行存储一条新闻数据,每条新闻的标题数据和发布时间数据使用逗号进行间隔。参照结果如下:
西北师范大学郭炯教授给鲁东大学师生作线上学术报告, 2022-05-06
鲁东大学党委书记徐东升为团员青年讲授思政课, 2022-05-05
import re
import requests
pat = r''''''
pat2 = '''(.+?) '''
with open('newsData.txt','a',encoding='UTF-8') as fp :
for i in range(87,0,-1) :
print(f"正在抓取第{88-i}页……")
url = f"https://www.news1.ldu.edu.cn/ldyw1/{i}.htm"
r = requests.get(url)
r.encoding = 'UTF-8'
text = r.text
time = re.findall(pat2,text)
data = re.findall(pat,text)
for i in range(23) :
s = data[i] + ',' + time[i]
fp.write(s)
fp.write('\n')
问题2:
给定网页url为http://www.news1.ldu.edu.cn/info/1008/18765.htm,请从页面中提取出所有图片的url并将图片下载到本地,本地图片文件的编号依次为1.jpg,2.jpg…。
import re
import requests
pat = r'''
url = "http://www.news1.ldu.edu.cn/info/1008/18765.htm"
r = requests.get(url)
r.encoding = 'UTF-8'
text = r.text
data = re.findall(pat,text)
n = 1
for i in data :
pic ='https://www.news1.ldu.edu.cn' + i
picture = requests.get(pic)
with open(f'./img{n}.png', 'wb') as f:
f.write(picture.content)
n += 1
实验9 GUI图形化用户界面
问题:口算题生成系统
(1)单击“出题”按钮生成10以内的加减法。
(2)单击“判分”按钮对用户输入的结果进行判断,将判断结果显示在listbox组件中。
import random
import tkinter as tk
from tkinter import *
def GetProblems():
a = random.randint(1,9)
b = random.randint(1,9)
oper = random.randint(1,2)
s = str(a) + " "
if oper == 1 :
s += "- "
else:
s += "+ "
s += str(b) + " ="
label["text"] = s
def Calc():
num = label["text"]
getnum = int(result.get())
re = 0
aa = int(num[0])
bb = int(num[4])
op = num[2]
if op == '+' :
re = aa + bb
else :
re = aa - bb
if re == getnum :
out = str(aa)+op+str(bb)+'='+str(getnum)+' √'
listbox.insert(END,out)
else:
out = str(aa) + op + str(bb) + '=' + str(getnum) + ' ×'
listbox.insert(END, out)
result.delete(0,END)
root = tk.Tk()
root.title("自动出题并判分")
root.geometry("300x320")
label = tk.Label(root) # 文本框
result = tk.Entry(root) # 输入框
listbox = tk.Listbox(root)
button1 = tk.Button(root, text="出题", command=GetProblems)
button2 = tk.Button(root, text="判分", command=Calc)
button1.place(x=80 ,y=80 ,width=50,height=30)
button2.place(x=150,y=80,width=50,height=30)
label.place(x=80 ,y = 50 ,width=60)
result.place(x=150,y=50,width=60)
listbox.place(x=80,y=120)
root.mainloop()