爬取app内的数据!mitmproxy入门教程!python爬虫入门实战
如何获取手机app内数据源信息?接下来以taptap手机app为例,获取单机排行榜数据。
第一步:配置环境
首先在电脑上安装好 mitmproxy ,安装方法可以参考官网,以下是以macOS为例。
brew install mitmproxy
python3 和 requests 库, openpyxl 库,国内可以用镜像安装,参考如下。
pip3 install openpyxl -i http://pypi.douban.com/simple --trusted-host=pypi.douban.com
pip3 install requests -i http://pypi.douban.com/simple --trusted-host=pypi.douban.com
还要引入一些系统库
import requests
from openpyxl import Workbook
from openpyxl.drawing.image import Image
import os
import random
import time
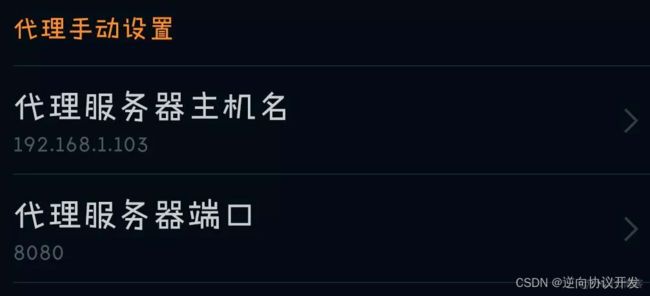
手机上用浏览器打开网页,安装证书。
第二步:数据获取
安装好 mitmproxy 之后, 直接在电脑命令终端中执行 mitmproxy 。
然后在手机上打开TapTap应用,选择发现->单机。可以在电脑终端看到许多http请求。

逐个点击进去后,选择 Response ,可以找到我们需要的数据的链接。
点击 Request 可以看到请求链接和参数,这些就是获取数据源的链接和参数。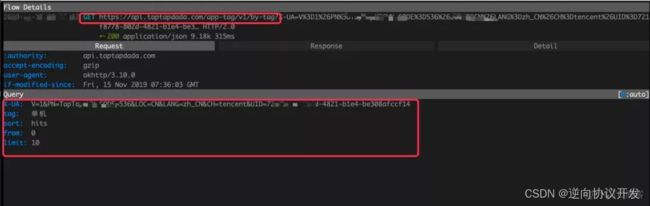
在手机上多翻几页,多点几个链接详情,可以发现 from 参数是翻页参数。那么在 python3 中如何获取呢?参考如下
headers = {
'Accept': 'application/json'
}
def scrapy(index):
params = {
'X-UA': 'V=1&PN=TapTap&VN_CODE=536&LOC=CN&LANG=zh_CN&CH=tencent',#'V%3D1%26PN%3DTapTap%26VN_CODE%3D536%26LOC%3DCN%26LANG%3Dzh_CN%26CH%3Dtencent',
'tag': '单机',#'%E5%8D%95%E6%9C%BA',
'sort': 'hits',
'from': f'{index*10}',
'limit': '10',
}
requests_url = 'https://api.taptapdada.com/app-tag/v1/by-tag'
requests_page=requests.get(requests_url,headers=headers,params=params);
if requests_page.status_code == 200:
decode(requests_page.json())
使用 requests 的 get 方法可以传入 hearders 和 参数。因为返回的是 json 可以直接调用 json() 方法解析结构。
第三部:数据分析
通过查看返回 json 里的内容和手机应用内的显示数据,大致可以找出对应数据的字段。
一起看下在 python 中如何处理的吧。
data_list=content['data']['list']
for data in data_list:
data_id = data['id']
data_title = data['title']
data_stat = data['stat']
link = f'https://www.taptap.com/app/{data_id}/'
tags = ','.join([tag['value'] for tag in data['tags']])
icon_url = data['icon']['url']
score = data_stat['rating']['score']
fans_count = data_stat['fans_count'] #关注
hits_total = data_stat['hits_total'] #下载
第四部:数据存储
这次我们用 Excel 保存数据,用到 openpyxl 库的处理。另外,我们还可以插入 icon 图标,可以先把图片下载到 icon 文件夹中,再读取数据时把图片插入表中。
先初始化表格第一行的内容,新建一个 icon 文件夹。
ICON_TEMP='icon'
if os.path.isdir(ICON_TEMP)==False:
os.mkdir(ICON_TEMP)
TITLE_LIST=['排名','id','游戏名称','地址','评分','关注','下载量','icon']
wb = Workbook()
dest_filename = 'taptap_rank.xlsx'
ws1 = wb.active
for col in range(0, len(TITLE_LIST)):
_ = ws1.cell(column=col+1, row=1, value="{0}".format(TITLE_LIST[col]))
row_count = 1
接着在读取每一条数据时,下载 icon 图片,将对应数据插入表中
row_count = row_count+1
icon_path = os.path.join('.',ICON_TEMP, f'{data_id}.png')
if os.path.isfile(icon_path)==False:
time.sleep(random.random()*2)
icon_r = requests.get(icon_url);
with open(icon_path, 'wb') as fd:
fd.write(icon_r.content)
_ = ws1.cell(column=1, row=row_count, value="{0}".format(row_count-1))
_ = ws1.cell(column=2, row=row_count, value="{0}".format(data_id))
_ = ws1.cell(column=3, row=row_count, value="{0}".format(data_title))
_ = ws1.cell(column=4, row=row_count, value="{0}".format(link))
_ = ws1.cell(column=5, row=row_count, value="{0}".format(score))
_ = ws1.cell(column=6, row=row_count, value="{0}".format(fans_count))
_ = ws1.cell(column=7, row=row_count, value="{0}".format(hits_total))
img = Image(icon_path)
img.width=img.height=50
ws1.add_image(img, f'H{row_count}')
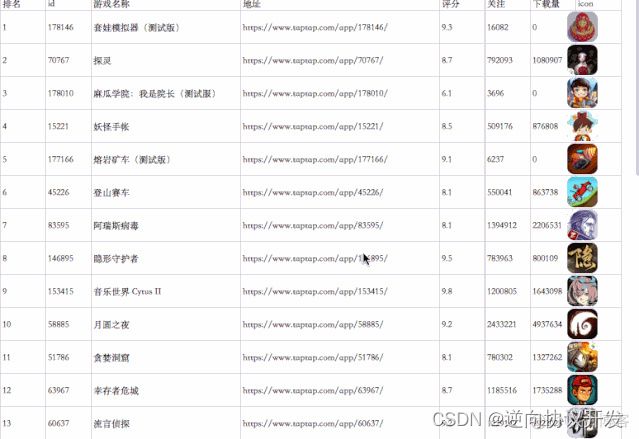
结果预览:
总结:
首先通过 mitmproxy 代理获取数据链接和参数,接着对用手机的数据查找我们需要的参数,编写对应的处理代码,保存在 excel 表中。
以上就是我最新学到的东西,如果有错误或新想法欢迎留言指出!如果我学到新的东西,会第一时间分享给大家哦!
本文使用图片素材来自网络!版权归原作者所有,如有侵权还请联系!
本文仅供个人交流学习使用,请勿用于其他用途。