LevelDb(二):LevelDb整体架构
1. LevelDb组成
2. Log文件
3. MemTable和Immutable Memtable
4. SSTable文件
5. Manifest文件
6. Current文件
7. 关于Sequence Number
1. LevelDb组成
LevelDb作为存储系统,数据记录的存储介质包括内存以及磁盘文件,当LevelDb运行了一段时间,从静态角度看,LevelDb的组成如下图所示:
从图中可以看出,构成LevelDb静态结构的包括六个主要部分:
- 内存的数据结构:MemTable和Immutable MemTable
- 磁盘4种主要文件:Current文件,Manifest文件,log文件,SSTable文件
当然,LevelDb除了这六个主要部分还有一些辅助的文件,但是以上六个文件和数据结构是LevelDb的主体构成元素。这六个部分的配合关系如下,当往系统中插入一条键值对记录时:
(1)LevelDb会先往log文件里写入,Log文件在系统中的作用主要是用于系统崩溃恢复而不丢失数据,一个log文件对应一个Memtable
(2)log文件写入成功后将记录插进Memtable中,Memtable的底层数据结构是一个SkipList
(3)Memtable插入的数据占用内存到了一个界限后,LevleDb会生成新的Log文件和Memtable,原先的Memtable就成为Immutable Memtable,Immutable Memtable只接受读操作,不再接受写操作
(4)LevelDb后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件
(5)SSTable中的某个文件属于特定层级,而且其存储的记录是key有序的,Manifest文件记载了SSTable各个文件的管理信息,比如属于哪个Level,文件名,最小key和最大key各自是多少,manifest会记载所有SSTable文件的这些信息
(6)Current文件的内容只有一个信息,就是记载当前的manifest文件名。因为在LevleDb的运行过程中,随着Compaction的进行,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化,而Current则用来指出哪个Manifest文件才是我们关心的那个Manifest文件
2. Log文件
上节内容讲到log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据。因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据log文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据,在这点上LevelDb和Bigtable是一致的。下面看看log文件的具体物理和逻辑布局是怎样的:
(1)物理布局
LevelDb对于一个log文件,会把它切割成以32K为单位的物理Block,每次读取的单位以一个Block作为基本读取单位,所以从物理布局来讲,一个log文件就是由连续的32K大小Block构成的,一个Block可能只包含一条记录,也可能包含多条记录。
(2)逻辑布局
在应用的视野里是看不到这些Block的,应用看到的是一系列的Key:Value对,在LevelDb内部,会将一个Key:Value对看做一条记录的数据,另外在这个数据前增加一个记录头,用来记载一些管理信息,以方便内部处理。

记录头包含三个字段:
- ChechSum:该字段是对“类型”和“数据”字段的校验码,大小为4B,为了避免处理不完整或者是被破坏的数据,当LevelDb读取记录数据时候会对数据进行校验,如果发现和存储的CheckSum相同,说明数据完整无破坏,可以继续后续流程
- Length:该字段记载了数据的大小
- payload:该字段则是上面讲的Key:Value数值对
- Type:该字段则指出了每条记录的逻辑结构和log文件物理分块结构之间的关系,具体而言,主要有以下四种类型:FULL/FIRST/MIDDLE/LAST
如果记录类型是FULL,代表了当前记录内容完整地存储在一个物理Block里,没有被不同的物理Block切割开;如果记录被相邻的物理Block切割开,则类型会是其他三种类型中的一种。假设目前存在三条记录,Record A,Record B和Record C,其中Record A大小为10K,Record B 大小为80K,Record C大小为12K,那么其在log文件中的逻辑布局会如下图所示:
- Record A因为大小为10K < 32K,能够放在一个物理Block中,所以其类型为FULL
- Record B 大小为80K,而Block 1因为放入了Record A,所以还剩下22K,不足以放下Record B,所以在Block 1的剩余部分放入Record B的开头一部分,类型标识为FIRST,代表了是一个记录的起始部分;Record B还有58K没有存储,这些只能依次放在后续的物理Block里面,因为Block 2大小只有32K,仍然放不下Record B的剩余部分,所以Block 2全部用来放Record B,且标识类型为MIDDLE,意思是这是Record B中间一段数据;Record B剩下的部分可以完全放在Block 3中,类型标识为LAST,代表了这是Record B的末尾数据
- Record C因为大小为12K,Block 3剩下的空间足以全部放下它,所以其类型标识为FULL
3. MemTable和Immutable Memtable
Memtable在整个体系中的重要地位也不言而喻。总体而言,所有KV数据都是存储在Memtable,Immutable Memtable和SSTable中的,Immutable Memtable从结构上讲和Memtable是完全一样的,区别仅仅在于其是只读的,不允许写入操作,而Memtable则是允许写入和读取的。当Memtable写入的数据占用内存到达指定数量,则自动转换为Immutable Memtable,等待Dump到磁盘中,系统会自动生成新的Memtable供写操作写入新数据,理解了Memtable,那么Immutable Memtable自然不在话下。
LevelDb的MemTable提供了将KV数据写入,删除以及读取KV记录的操作接口,但是事实上Memtable并不存在真正的删除操作,删除某个Key的Value在Memtable内是作为插入一条记录实施的,但是会打上一个Key的删除标记,真正的删除操作是Lazy的,会在以后的Compaction过程中去掉这个KV。
需要注意的是,LevelDb的Memtable中KV对是根据Key大小有序存储的,在系统插入新的KV时,LevelDb要把这个KV插到合适的位置上以保持这种Key有序性。其实,LevelDb的Memtable类只是一个接口类,真正的操作是通过背后的SkipList来做的,包括插入操作和读取操作等,所以Memtable的核心数据结构是一个SkipList。
SkipList是平衡树的一种替代数据结构,但是和红黑树不相同的是,SkipList对于树的平衡的实现是基于一种随机化的算法的,这样也就是说SkipList的插入和删除的工作是比较简单的。关于SkipList的详细介绍可以参考这篇文章,LevelDb的SkipList基本上是一个具体实现,并无特殊之处。SkipList不仅是维护有序数据的一个简单实现,而且相比较平衡树来说,在插入数据的时候可以避免频繁的树节点调整操作,所以写入效率是很高的,LevelDb整体而言是个高写入系统,SkipList在其中应该也起到了很重要的作用。Redis为了加快插入操作,也使用了SkipList来作为内部实现数据结构。
4. SSTable文件
当Memtable插入的数据占用内存到了一个界限后,需要将内存的记录导出到外存文件中,LevelDb后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDb的原因。至于这个层级结构是如何形成的我们放在后面Compaction博客中细说。本节主要介绍SSTable某个文件的物理布局和逻辑布局结构。
4.1 SSTable文件布局
LevelDb不同层级有很多SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块,但是两者逻辑布局大不相同,根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。下图展示了.sst文件的内部逻辑解释。

从上图可以看出,从大的方面,可以将.sst文件划分为数据存储区和数据管理区,数据存储区存放实际的Key:Value数据,数据管理区则提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。两个区域都是在上述的分块基础上的,就是说文件的前面若干块实际存储KV数据,后面数据管理区存储管理数据。管理数据又分为四种不同类型:
(1)元数据块(Meta Block):LevelDb 1.2版对于Meta Block尚无实际使用;
(2)元数据块索引(MetaBlock Index):LevelDb 1.2版对于Meta Block尚无实际使用;
(3)数据块索引(Index block):
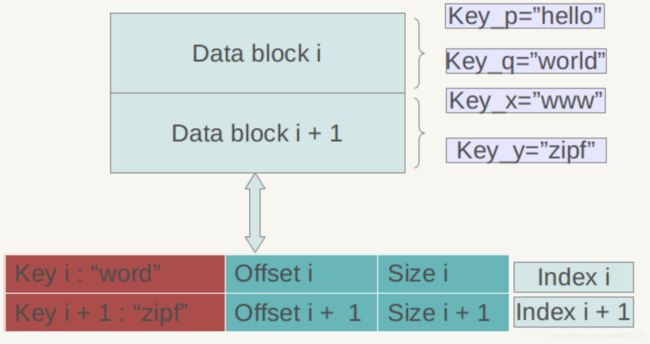
上图是数据索引的内部结构示意图。Data Block内的KV记录是按照Key由小到大排列的,数据索引区的每条记录是对某个Data Block建立的索引信息,每条索引信息包含三个内容:1)第一个字段记载大于等于数据块i中最大的Key值的那个Key;2)第二个字段指出数据块 i 在.sst文件中的起始位置;3)第三个字段指出Data Block i 的大小(有时候是有数据压缩的)。
三个字段中后面两个字段好理解,是用于定位数据块在文件中的位置的,第一个字段需要详细解释一下,在索引里保存的这个Key值未必一定是某条记录的Key, 以上图例子来说,假设数据块 i 的最小Key=“samecity”,最大Key=“the best”; 数据块 i +1的最小Key=“the fox”,最大Key=“zoo”, 那么对于数据块 i 的索引Index i来说,其第一个字段记载大于等于数据块 i 的最大Key(“the best”)同时要小于数据块 i + 1的最小Key(“the fox”),所以如果例子中Index i 的第一个字段是:“the c”,这个是满足要求的;而Index i+1的第一个字段则是“zoo”,即数据块 i + 1的最大Key。
(4)文件尾部块(Footer):
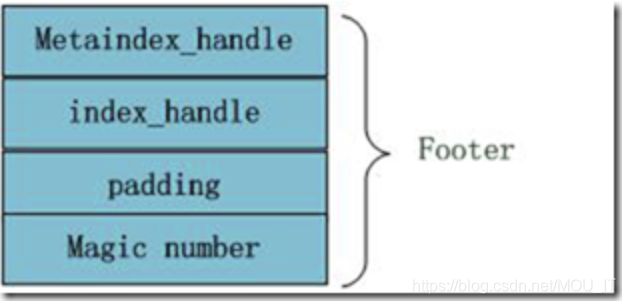
metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数。
4.2 Datablock布局
下图展示了Datablock的物理划分结构:
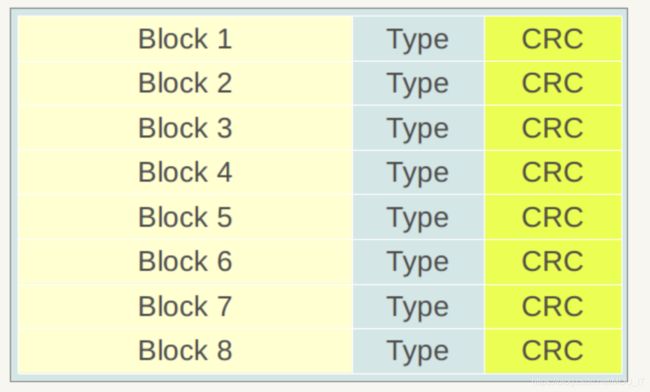
同Log文件一样,也是划分为固定大小的存储块,每个Block分为三个部分:
- 数据存储区:用于存储具体的数据
- Type区:用于标识数据存储区是否采用了数据压缩算法(Snappy压缩或者无压缩两种)
- CRC:该部分则是数据校验码,用于判别数据是否在生成和传输中出错
下面我们看看数据区的一个Block的数据部分内部是如何布局的:
从图中可以看出,其内部也分为两个部分,前面是一个个KV记录,其顺序是根据Key值由小到大排列的,在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。“重启点”是干什么的呢?Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the Car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。Block尾部就是指出哪些记录是这些重启点的。

在Block内容区,每个KV记录的内部结构是怎样的?上图给出了其详细结构,每个记录包含5个字段:
- key共享长度,比如上面的“olor”记录, 其key和上一条记录共享的Key部分长度是“the c”的长度,即5;
- key非共享长度,对于“olor”来说,是4;
- value长度指出Key:Value中Value的长度;
- Value内容字段中存储实际的Value值;
- key非共享内容则实际存储“olor”这个Key字符串。
5. Manifest文件
提到manifest文件,它和3个数据结构有关,分别是Version、VersionSet和VersionEdit,这3者的关系如下图所示:
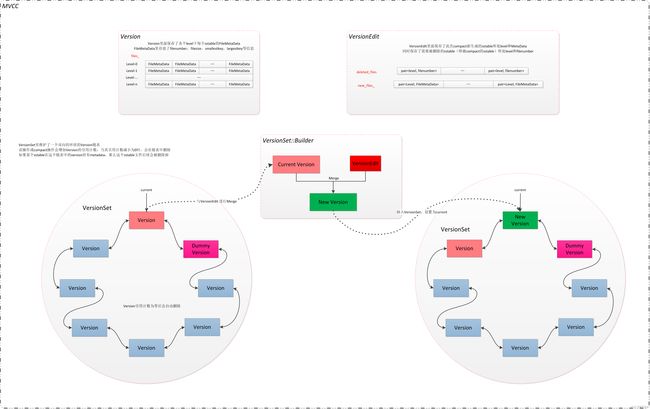
(1)Version
Version代表一个版本,记录了rocksDB的LSM树的状态信息,它保存了各个level下每个sstable的FileMetaData。例如,通过读取Version的数据,我们可以知道L0、L1、L2......Ln各有哪些SST文件,以及每个SST的元数据信息FileMetaData,里面记录了该文件的smallest_seqno、largest_seqno、filenumber、filesize、smallestkey和largestkey等信息。
一般只有一个Version叫做"current" version(当前版本)。Leveldb还保存了一系列的历史版本,当一次Compaction结束后(会生成新的文件,合并前的文件需要删除),Leveldb会创建一个新的版本作为当前版本,原先的当前版本就会变为历史版本,这些历史版本有什么用呢 ? 由于某些时候compact会在某个level上新加入或者删除一些sstable,如果这个时候,这些sstable正在被读,为了处理这样的读写竞争,基于sstable一旦生成就不会改动的特点,每个version加入引用计数refs_,这样db中可能有多个version同时存在,他们通过链表链接。当version的引用计数为0并且不是当前最新的version,他会从链表中移除,对应的,该version的sstable就可以删除了。其实这就是RocksDB的MVCC机制,历史版本的Version就是为了处理读写并发而设计出来的。
Version的结构体定义如下:
class version{
VersionSet* vset_; // 当前Version属于哪个VersionSet
Version* next_; // 链表中的下一个Version
Version* prev_; // 链表中的前一个Version
int refs_; // 这个Version的引用计数
std::vector files_[config::kNumLevels]; // 每个level的SSTable文件元数据列表
FileMetaData* file_to_compact_; // 基于seek stats来决定下一个要compact的文件
int file_to_compact_level_; // file_to_compact_所在的层级
double compaction_score_; // compaction 分值,如果分值小于1,意味着compaction不是必须的
int compaction_level_; // 下一个需要做compact的层级;
} FileMetaData的结构体定义如下:
struct FileMetaData {
FileDescriptor fd;
InternalKey smallest; // Smallest internal key served by table
InternalKey largest; // Largest internal key served by table
// Needs to be disposed when refs becomes 0.
Cache::Handle* table_reader_handle;
FileSampledStats stats;
// Stats for compensating deletion entries during compaction
// File size compensated by deletion entry.
// This is updated in Version::UpdateAccumulatedStats() first time when the
// file is created or loaded. After it is updated (!= 0), it is immutable.
uint64_t compensated_file_size;
// These values can mutate, but they can only be read or written from
// single-threaded LogAndApply thread
uint64_t num_entries; // the number of entries.
uint64_t num_deletions; // the number of deletion entries.
uint64_t raw_key_size; // total uncompressed key size.
uint64_t raw_value_size; // total uncompressed value size.
int refs; // Reference count
bool being_compacted; // Is this file undergoing compaction?
bool init_stats_from_file; // true if the data-entry stats of this file
// has initialized from file.
bool marked_for_compaction; // True if client asked us nicely to compact this
// file.
... ...
}(2)VersionSet
知道了Version之后,VersionSet就比较好理解了, VersionSet是所有Version的集合,管理着所有存活的Version,所有的Version保存在一个双向循环链表中。在所有的version中,只有一个是CURRENT。
(3)VersionEdit
Compaction过程中会有一系列改变当前Version的操作(FileNumber增加,删除input的SSTable, 增加输出的SSTable),为了缩小Version切换的时间点,将这些操作封装成VersionEdit,Compaction完成时,将Version Edit中的操作一次应用到当前Version即可得到最新状态的Version。因此Version Edit表示Version之间的变化,相当于delta 增量,表示有增加了多少文件,删除了多少文件。它们之间的关系可以表示为:
Version0 + VersionEdit --> Version1
VersionEdit是Version对象的变更记录,用于写入MANIFEST文件,VersionEdit就相当于MANIFEST文件中的一条记录。这样通过原始的Version加上一系列的VersionEdit的记录,就可以恢复到最新状态。当新打开一个levelDB数据库做数据恢复时,就会从manifist文件中读出来重建数据。VersionEdit的成员如下:
class VersionEdit {
typedef std::set> DeletedFileSet;
std::string comparator_; // 比较器的名称;
uint64_t log_number_; // 日志文件编号;
uint64_t prev_log_number_; // 前一个日志文件的编号;
uint64_t next_file_number_; // 下一个文件编号;
SequenceNumber last_sequence_; // 上一个序列号
bool has_comparator_; // 是否有比较器;
bool has_log_number_; // 是否有日志文件编号;
bool has_prev_log_number_; // 是否有前一个日志文件编号;
bool has_next_file_number_; // 是否有下一个文件编号;
bool has_last_sequence_; // 是否有上一个序列号;
/* 这是一个vector,里面的每项是一个由level,internalkey组成的pair,也就是说里面记录的是,compact到哪一层的,哪个key了 */
std::vector> compact_pointers_;
/* 这是一个set,里面的每一项是一个由level,sst文件的编号组成的pair,也就是说,里面记录的是哪里一层被删除的哪个文件 */
DeletedFileSet deleted_files_;
/* 这是一个vector,里面的每一项是一个由level,FileMetaData组成的pair,也就是说,里面记录的是在哪一层增加了什么文件 */
std::vector> new_files_;
} 简单来说,VersionEdit记录的就是数据库的变更信息的(如这次将要删除哪些文件,新增哪些文件,以及各层下次合并点的信息)。由于VersionEdit记录了数据库从一个版本到下一个版本的变更信息,如果只放在内存中,掉电后我们将很难快速恢复出数据库的最新版本,所以我们需要将VersionEdit持久化,这便是MANIFEST文件的作用。
(4)manifest文件
MANIFEST是跟版本变更有关的磁盘文件,MANIFEST文件的内容就是VersionEdit序列化后的内容,可用来恢复。MANIFEST中record存储的方式跟log存储方式一样。MANIFEST的内容如下图所示:
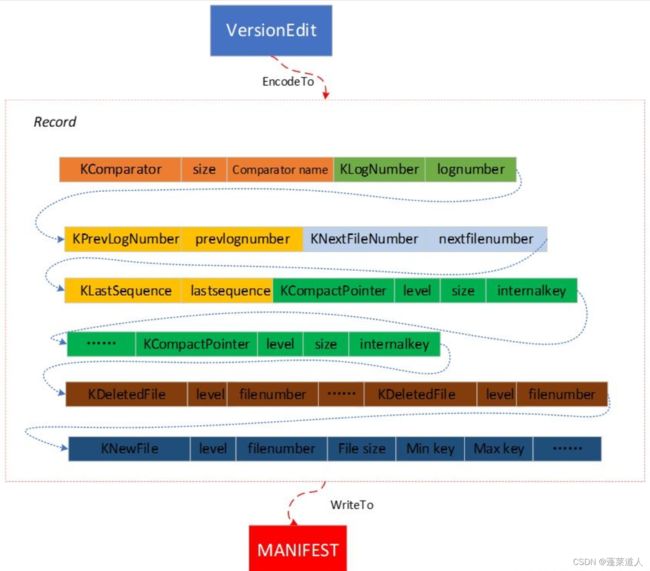
一次版本的变更信息保存在VersionEdit中,VersionEdit中的信息经过Encode后形成Record,一个Record有可能很大,MANIFEST存储Record的方式与WAL日志中存储Record方式一样,也分为:KFullType、KFirstType、KMiddleType、KLastType。随着系统不断的运行,发生版本变化的次数会越来越多,MANIFEST文件数也会变多,需要一个类似指针的东西指向当前使用的MANIFEST,CURRENT文件就充当这个指针的作用,它存储了当前使用的MANIFEST的文件名。VersionEdit的序列化过程如下代码所示:
Status DBImpl::NewDB() {
VersionEdit new_db;
new_db.SetLogNumber(0);
new_db.SetNextFile(2);
new_db.SetLastSequence(0);
Status s;
ROCKS_LOG_INFO(immutable_db_options_.info_log, "Creating manifest 1 \n");
const std::string manifest = DescriptorFileName(dbname_, 1);
{
std::unique_ptr file;
EnvOptions env_options = env_->OptimizeForManifestWrite(env_options_);
s = NewWritableFile(env_, manifest, &file, env_options);
if (!s.ok()) {
return s;
}
file->SetPreallocationBlockSize(
immutable_db_options_.manifest_preallocation_size);
std::unique_ptr file_writer(new WritableFileWriter(
std::move(file), manifest, env_options, nullptr /* stats */,
immutable_db_options_.listeners));
log::Writer log(std::move(file_writer), 0, false);
std::string record;
new_db.EncodeTo(&record);
s = log.AddRecord(record);
if (s.ok()) {
s = SyncManifest(env_, &immutable_db_options_, log.file());
}
}
if (s.ok()) {
// Make "CURRENT" file that points to the new manifest file.
s = SetCurrentFile(env_, dbname_, 1, directories_.GetDbDir());
} else {
env_->DeleteFile(manifest);
}
return s;
} 6. Current文件
Current文件是干什么的呢?这个文件的内容只有一个信息,就是记载当前的manifest文件名。因为在LevleDb的运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化,而Current则用来指出哪个Manifest文件才是我们关心的那个Manifest文件。
7. 关于Sequence Number
sequence number 是一个由VersionSet直接持有的全局的编号,每次写入(注意批量写入时sequence number是相同的),就会递增。根据我们之前对写入操作的分析,当插入一条key的时候,实际参与排序的key和sequence number以及type组成的 InternalKey。
void AppendInternalKey(std::string* result, const ParsedInternalKey& key) {
result->append(key.user_key.data(), key.user_key.size());
#ifdef USE_TIMESTAMPS
PutFixed64(result, key.timestamp);
#endif // USE_TIMESTAMPS
PutFixed64(result, PackSequenceAndType(key.sequence, key.type));
}当我们进行Get操作时,我们只需要找到目标key,同时其sequence number 小于等于VersionSet持有的last sequence number:
- 普通的读取,sepcific sequence number <= last sequence number
- snapshot读取,sepcific sequenc number <= snapshot sequence number
snapshot 其实就是一个sequence number,获取snapshot,即获取当前的last sequence number。
参考:数据分析与处理之二(Leveldb 实现原理) - Haippy - 博客园