3D目标检测概要及VoxelNet论文和代码解读(0)--Pillarization
文章目录
-
- 一、论文动机
- 二、论文方法
- 三、网络结构
-
- 1. Feature Learning Network
-
- 1.1 Voxel划分
- 1.2 Grouping(将每个点分配给对应的Voxel)和Sampling(voxel中点云的采样)
- 1.3VFE堆叠
- 1.4稀疏特征表示
- 2.中间卷积层(Convolution middle layers)
- 3.RPN层
-
- 3.1 RPN层设计
- 3.2 anchor的参数设计
- 四、损失函数及其余创新点
-
-
- 4.1损失函数
- 4.2点云的数据增强
- 4.3高效实现堆叠VFE
-
- 五、论文实验结果
- 六、点云数据体素化代码(Pillarization模块)
- 七、参考
论文地址:https://arxiv.org/abs/1711.06396
代码地址(pytorch版):https://github.com/skyhehe123/VoxelNet-pytorch
VoxelNet解决了点云无序化数据结构的提取问题后,便采用了Voxel的方法。Voxel是将三维世界中的空间按照一定的大小划分成格子,使用pointnet网络对每个小格子的数据进行特征提取,并将提取出来的特征作为该小格子的代表放回到3D空间中。这样,无序的点云数据就被转换为一组有序的高维特征数据。接着,采用三维卷积来提取这些三维的voxel数据,将图像检测思路应用于这个特征图上。

voxel和点云的关系图
一、论文动机
-
传统的手工点云特征提取方法存在很大的局限性,不能适应点云检测场景的多变性。
-
PointNet和PointNet++算法主要处理小规模点云数据,通常仅处理几千个点左右的数据。然而,激光雷达点云数据通常包含几万个点,甚至更多,因此需要一种能够处理大规模点云数据的算法。
二、论文方法
-
三维体素表示:VoxelNet算法使用三维体素格子将点云数据转换为规则的三维数据结构,使得点云数据可以方便地用于卷积神经网络中进行处理和学习。
-
点云数据的特征提取:VoxelNet算法通过在三维体素格子上应用卷积神经网络,提取每个体素的特征,从而学习点云数据的语义信息。
-
物体检测的端到端学习:VoxelNet算法将点云数据输入到一个神经网络中,同时输出物体的位置和大小信息,实现端到端的物体检测。
-
模型性能的优化:VoxelNet算法采用了一些有效的技巧来优化模型的性能,如使用稀疏卷积来减少计算量和参数数量,以及使用多尺度特征来提高检测性能等。
具体来说,VoxelNet算法通过将点云数据转换为等间距的3D体素格子,通过堆叠 VFE 层对每个体素进行编码,并将每个体素的局部特征编码成高维特征向量,将点云数据转换为高维特征表示。然后,通过使用三维卷积神经网络对体素格子中的局部特征进行聚合,进一步提取点云数据的语义信息。最后,通过RPN(Region Proposal Network)产生检测结果。
这种高效的算法受益于点云数据的稀疏结构和体素网格上的高效并行处理,因此能够实现端到端的点云检测,同时具有较高的检测精度和较快的检测速度。
三、网络结构
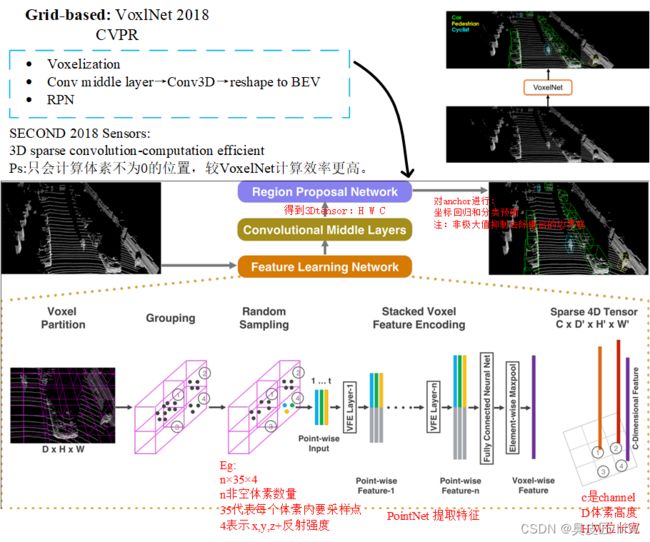
1. Feature Learning Network
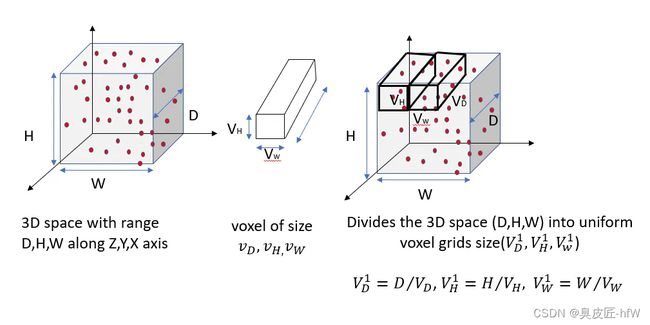
1.1 Voxel划分
将点云在空间上划分为许多体素,设定体素的长宽高,并对点云裁剪,太边缘的不要,因为很稀疏没啥用。论文中划分后为[352,400,10]个voxel
1.2 Grouping(将每个点分配给对应的Voxel)和Sampling(voxel中点云的采样)
体素化后,有好多网格里面没有点,有些点又过多,这时我们对非空的voxel进行降采样,每个里面随机采样T个点,不足的用0补充。因此在grouping之后,得到的数据为[N,T,C],N为非空体素的个数,T为每个体素里面采样的点,C为特征。论文里T为35,C为7, [xi , yi , zi , ri, xi_offset,yi_offset,zi_offset],先求出每个体素里面35个点的均值,每个点xyz都减去均值,得到xyz偏移。
1.3VFE堆叠
VoxelNet 算法的 VFE 模块将每个体素中的点通过全连接层转换为高维空间,并使用 max pooling 对体素的聚合特征进行提取。具体而言,每个体素通过一个全连接层(包括 FC、ReLU、BN 等层),将点的维度从 (N,35,7) 转换为 (N,35,C1)。然后,通过 max pooling 对体素的特征进行聚合,将聚合特征拼接到每个高维点云特征中,得到 (N,35,2*C1) 的特征表示。整个过程被称为 VFE 模块,原论文中使用两个 VFE 模块分别得到 (N,35,32) 和 (N,35,128) 的特征表示。接下来,通过一个 FC 层对点特征和聚合特征进行融合,输入输出维度均为 (N,35,128)。最后,再通过一次 max pooling 得到 (N,128) 的特征表示。
1.4稀疏特征表示
前面的操作都是对非空体素的操作,这些voxel仅仅对应3D空间中很小一部分,现在将那些非空的体素还原到3D空间中,得到一个稀疏的4D张量(128,10,400,352)
2.中间卷积层(Convolution middle layers)
得到稀疏张量之后,我们使用三维卷积来聚合voxel之间的局部关系,扩大感受野获取更丰富的形状信息,方便RPN预测。论文里使用了三个三维卷积(cin,cout,K,S,P)
Conv3D(128, 64, 3, (2,1,1), (1,1,1)),
Conv3D(64, 64, 3, (1,1,1), (0,1,1)),
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
最终得到的张量为 (64,2,400,352),将数据整理成RPN网络需要的特征体,reshape成(64*2,400,352),这样维度就变成了C,Y,X,不考虑Z的原因是kitti的3D空间在高度上没有堆叠,这样也减少了网络后期RPN的设计难度和anchor数量。
3.RPN层
3.1 RPN层设计
RPN层的概念最初在FasterRCNN中被提出,其主要目的是根据特征图中学习到的特征和锚点信息生成对应的目标预测结果。相比之下,我认为VoxelNet的预测头更类似于SSD和YOLO等目标检测算法中的头部预测。在FasterRCNN中,RPN层会根据锚点的设置,在每个像素和像素中心位置上对锚点进行分类和回归预测。而在VoxelNet中也采用了类似的方法。
VoxelNet论文中RPN的详细结构如下图:

注:这里每一层卷积都是二维的卷积操作,每个卷积后面都接一个BN和RELU层。最终的预测结果只针对一类,两个角度的预测,所以是(B,2,200,176)和(B,14,200,176),anchor沿着xy间隔放置。
VoxelNet的RPN结构在经过前面的Convolutional middle layers和tensor重组得到的特征图后,对这个特征图分别的进行了多次下采样,然后再将不同下采样的特征进行反卷积操作,变成相同大小的特征图。再拼接这些来自不同尺度的特征图,用于最后的检测。给人的感觉有点像图像目标检测的NECK模块中PAN。只不过这里只有一张特征图。将不同尺度的信息融合在了一起。这里每一层卷积都是二维的卷积操作,每个卷积后面都接一个BN和RELU层,最终的输出结果是一个分类预测结果和anchor回归预测结果。
3.2 anchor的参数设计
在VoxelNet中,只使用了一个anchor的尺度,不像FrCNN中的9个anchor。其中anchor的长宽高分别是3.9m、1.6m、1.56m。同时与FrCNN中不同的是,真是的三维世界中,每个物体都是有朝向信息的。所以VoxelNet为每个anchor加入了两个朝向信息,分别是0度和90度(激光雷达坐标系)。
注:由于在原论文中作者分别为车、行人、自行车设计了不同的anchor尺度,并且行人和自行车有自己单独的网络结构(仅仅在Convolutional middle layers的设置上有区别)。为了方便解析,这里仅以车的网络设计作为参考。
四、损失函数及其余创新点
4.1损失函数
正负样本匹配
每个类别的先验证只有一种尺度信息;分别是车 [3.9, 1.6, 1.56],anchor的中心在-1米、人[0.8, 0.6, 1.73],anchor的中心在-0.6米、自行车[1.76, 0.6, 1.73],anchor的中心在-0.6米(单位:米)。
在anchor匹配GT的过程中,使用的是2D IOU匹配方式,直接从生成的特征图也就是BEV视角进行匹配;不需要考虑高度信息。原因有二:
①因为在kitti数据集中所有的物体都是在三维空间的同一个平面中的,没有车在车上面的一个情况。 ② 所有类别物体之间的高度差别不是很大,直接使用SmoothL1回归就可以得到很好的结果。
其次是每个anchor被设置为正负样本的iou阈值是:
-
车匹配iou阈值大于等于0.6为正样本,小于0.45为负样本,中间的不计算损失。
-
人匹配iou阈值大于等于0.5为正样本,小于0.35为负样本,中间的不计算损失。
-
自行车匹配iou阈值大于等于0.5为正样本,小于0.35为负样本,中间的不计算损失。
损失函数详情
在一个3D的数据的标注中,包含了7个参数(x, y ,z, l, w, h, θ),其中xyz代表了一个物体的中心点在雷达坐标系中的位置。lwh代表了这个物体的长宽高。θ代表了这个物体绕Z轴旋转角度(偏航角)。因此生成的anchor也包含对应的7个参数(xa, ya ,za, la, wa, ha, θa),其中xa, ya ,za表示这个anchor在雷达坐标系中的位置。 la, wa, ha反应了这个anchor的长宽高。θa表示这个anchor的角度。
因此编码每个anchor和GT的损失函数时,公式如下:

其中d^a表示一个anchor的底面对角线长度。上面直接定义了每个anchor回归的7个参数;但是总的损失函数还包含了对每个anchor的分类预测,因此总的损失函数定义如下:

其中 pi^pos
表示经过softmax函数后该anchor为正样本,pj^neg表示经过softmax函数后该anchor为负样本。ui和ui*仅仅需要对正样本anchor回归计算loss。同时背景分类和类别分类都采用了BCE损失函数;1/Npos和1/Nneg用来normalize各项的分类损失。α, β为两个平衡系数,在论文中分别是1.5和1。最后的回归损失采用了SmoothL1函数。
4.2点云的数据增强
1.由于标注的时候一个GTbox已经标注出来了有哪些点,所以可以同时移动或者旋转这些点来创造大量的变化数据,移动后还要进行碰撞检测,删掉碰撞的那些GT。
2.对所有的GTbox进行放大或者缩小,放大缩小尺度在[0.95,1.05]之间,引入缩放可以使得网络在检测不同大小物体上有更好的泛化性能。
3.对所有的GT box进行随机的旋转操作,角度在[-45,45]均匀分布中抽取,旋转物体的偏航角可以模拟其转了一个弯。
4.3高效实现堆叠VFE

由于每个voxel中包含的点个数不一样,所以作者将所有点云数据转换成了一种密集的数据结构,使得后面堆叠VFE可以在所有点和voxel的特征上平行处理。
1、首先创建一个KT7的张量(voxel input feature buffer)用来存储每个点或者中间的voxel特征数据,K是最大的非空voxel数量,T是每个voxel中最大的点数,7是每个点的编码特征。所有的点都是被随机处理的。
2、遍历整个点云数据,如果一个点对应的voxel在voxel coordinate buffer中,并且与之对应的voxel input feature buffer中点的数量少于T个,直接将这个点插入其中,否则直接抛弃。如果一个点对应的voxel不在voxel coordinate buffer中,需要在voxel coordinate buffer中直接使用这个voxel的坐标初始化这个voxel,并储存这个点到voxel input feature buffer中。这整个操作都是用哈希表完成,因此时间复杂度都是O(1)。整个Voxel Input Feature Buffer和voxel coordinate buffer的创建只需要遍历一次点云数据就可以,时间复杂度只有O(N),同时为了进一步提高内存和计算资源,对voxel中点的数量少于m数量的voxel直接忽略该voxel的创建。
3、在创建完Voxel Input Feature Buffer和voxel coordinate buffer后Stacked Voxel Feature Encoding就可以直接在点的基础上或者voxel的基础上进行平行计算。再经过VFE模块的concat操作后,就将之前为空的点的特征置0,保证了voxel的特征和点的特征的一致性。最后,使用存储在voxel coordinate buffer的内容恢复出稀疏的4D张量数据,完成后续的中间特征提取和RPN层。
五、论文实验结果

六、点云数据体素化代码(Pillarization模块)
import sys
import numpy as np
import torch
from opencood.data_utils.pre_processor.base_preprocessor import \
BasePreprocessor
# 该类的主要作用是将点云数据转换为体素表示形式,即Pillarization模块
class VoxelPreprocessor(BasePreprocessor):
def __init__(self, preprocess_params, train):
super(VoxelPreprocessor, self).__init__(preprocess_params, train)
# TODO: add intermediate lidar range later
self.lidar_range = self.params['cav_lidar_range']
self.vw = self.params['args']['vw']
self.vh = self.params['args']['vh']
self.vd = self.params['args']['vd']
self.T = self.params['args']['T'] # self.T表示每个体素内点的最大数量
def preprocess(self, pcd_np):
"""
Preprocess the lidar points by voxelization.
Parameters
----------
pcd_np : np.ndarray
The raw lidar.
Returns
-------
data_dict : the structured output dictionary.
"""
data_dict = {} # 搞成字典格式
# calculate the voxel coordinates
voxel_coords = ((pcd_np[:, :3] -
np.floor(np.array([self.lidar_range[0],
self.lidar_range[1],
self.lidar_range[2]])) / (
self.vw, self.vh, self.vd))).astype(np.int32) # 体素的宽度、高度、深度
# convert to (D, H, W) as the paper
voxel_coords = voxel_coords[:, [2, 1, 0]] # voxel_coords[:, [2, 1, 0]] 将体素坐标的x,y,z坐标转换为深度(D),高度(H),宽度(W)
voxel_coords, inv_ind, voxel_counts = np.unique(voxel_coords, axis=0,
return_inverse=True,
return_counts=True)
# np.unique将点云中的点按照体素坐标聚合,并统计每个体素内的点的数量和点在体素坐标系中的索引
voxel_features = []
for i in range(len(voxel_coords)):
voxel = np.zeros((self.T, 7), dtype=np.float32) # 创建体素 T×7
pts = pcd_np[inv_ind == i] # 选出与当前体素索引 i 相对应的点云,将其存储到 pts 中
if voxel_counts[i] > self.T:
pts = pts[:self.T, :] # 限制一个体素中最多的点的数量为T
voxel_counts[i] = self.T
# augment the points
voxel[:pts.shape[0], :] = np.concatenate((pts, pts[:, :3] -
np.mean(pts[:, :3], 0)),
axis=1) # 减去几何中心,拼接
voxel_features.append(voxel)
data_dict['voxel_features'] = np.array(voxel_features)
data_dict['voxel_coords'] = voxel_coords
return data_dict
def collate_batch(self, batch):
"""
Customized pytorch data loader collate function.
# 定制的pytorch数据加载器整理功能。
Parameters
----------
batch : list or dict
List or dictionary.
Returns
-------
processed_batch : dict
Updated lidar batch.
"""
if isinstance(batch, list):
return self.collate_batch_list(batch)
elif isinstance(batch, dict):
return self.collate_batch_dict(batch)
else:
sys.exit('Batch has too be a list or a dictionarn')
@staticmethod
def collate_batch_list(batch):
"""
Customized pytorch data loader collate function.
Parameters
----------
batch : list
List of dictionary. Each dictionary represent a single frame.
Returns
-------
processed_batch : dict
Updated lidar batch.
"""
voxel_features = []
voxel_coords = []
for i in range(len(batch)):
voxel_features.append(batch[i]['voxel_features'])
coords = batch[i]['voxel_coords']
voxel_coords.append(
np.pad(coords, ((0, 0), (1, 0)),
mode='constant', constant_values=i))
voxel_features = torch.from_numpy(np.concatenate(voxel_features))
voxel_coords = torch.from_numpy(np.concatenate(voxel_coords))
return {'voxel_features': voxel_features,
'voxel_coords': voxel_coords}
@staticmethod
def collate_batch_dict(batch: dict):
"""
Collate batch if the batch is a dictionary,
eg: {'voxel_features': [feature1, feature2...., feature n]}
Parameters
----------
batch : dict
Returns
-------
processed_batch : dict
Updated lidar batch.
"""
voxel_features = \
torch.from_numpy(np.concatenate(batch['voxel_features']))
coords = batch['voxel_coords']
voxel_coords = []
for i in range(len(coords)):
voxel_coords.append(
np.pad(coords[i], ((0, 0), (1, 0)),
mode='constant', constant_values=i))
voxel_coords = torch.from_numpy(np.concatenate(voxel_coords))
return {'voxel_features': voxel_features,
'voxel_coords': voxel_coords}

七、参考
[1] Zhou Y, Tuzel O. Voxelnet: End-to-end learning for point cloud based 3d object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4490-4499.
[2] https://github.com/open-mmlab/OpenPCDet
[3] https://zhuanlan.zhihu.com/p/352419316
[4] https://github.com/jjw-DL/OpenPCDet-Noted
[5] https://blog.csdn.net