Python基于机器学习实现的股票价格预测、股票预测源码+数据集,机器学习大作业
Feature与预测目标的选取
选择的feature:
- 开盘价
- 最高成交价
- 最低成交价
- 成交量
选择的预测目标:
- 收盘价
因为股票价格的影响因素太多,通过k线数据预测未来的价格变化基本不可行,只有当天之内的数据还有一定的关联,故feature与target都选择的是当天的数据。
加载数据
为了加快数据的处理速度,提前将mariadb数据库中的数据查询出来,保存成feather格式的数据,以提高加载数据的速度。关键代码如下:
def main_code_to_feather():
# Get Cursor, Fieldinfo And Total Rows
cur = conn.cursor()
labels = [fld[0] for fld in get_fieldinfo(cur)] # 获取所有的字段信息
codes = get_all_stock_code(cur) # 获取所有的股票代码
code_inedx = 0
for code in codes:
print("Processing:", code_inedx, "/", len(codes))
code_inedx += 1
data = fetch_by_code(cur, code, None, None).fetchall() # 获取对应股票的数据
df = pd.DataFrame(data=data, columns=labels) # 将数据放入pd的表
df.drop(columns=["id"], inplace=True) # 数据库中的id字段没有意义,drop掉
os.makedirs("data_by_code", exist_ok=True)
save_path = os.path.join("data_by_code", code+".feather") # 将股票数据保存成feather格式的数据
df.to_feather(save_path)
if __name__ == "__main__":
main_code_to_feather()
经过处理,不同股票的数据保存在了不同的文件中,列名还保持着数据库中的字段名。我选择了股票代码为sh600010的这只股票作为数据分析的数据来源。
从文件中加载数据的代码如下:
df = pd.read_feather("data_by_code/sh600010.feather")
处理数据
从股票数据中取出开盘价、最高成交价、最低成交价和成交量作为feature,取出收盘价作为预测的目标,最后取出日期作为绘图的横座标数据。关键代码如下:
x_tmp = []
y_tmp = []
date_tmp = []
for row in range(df.shape[0]):
today = df.loc[row]
# 当天信息
x_tmp.append(tuple([
today["popen"] / 1e1,
today["phigh"] / 1e1,
today["plow"] / 1e1,
today["vol"] / 1e4, # 防止loss溢出
]))
# 收盘价格
y_tmp.append(today["pclose"] / 1e1) # y/10防止loss溢出
# 日期
date_tmp.append(today["deal_date"])
x = tf.constant(x_tmp, dtype=tf.float32)
y = tf.constant(y_tmp, dtype=tf.float32)
这里将关键指标都除以了一个固定的数,可以防止loss溢出导致模型无法优化。
划分训练集与测试集,取最后5%的数据作为测试集。代码如下:
data_size = len(x_data) test_size = int(data_size * 0.05) x_train = x_data[:data_size - test_size] y_train = y_data[:data_size - test_size] x_test = x_data[data_size - test_size:] y_test = y_data[data_size - test_size:] date_test = date_data[data_size - test_size:]
选取模型并进行训练
我选取的是线性模型,使用线性模型进行训练,在训练时使用了tensorflow的keras库来简化代码的编写:
model = keras.Sequential(
[
layers.Dense(1, name="layer1"), # 输出size为1,即线性回归模型
]
)
model.compile(
optimizer = optimizers.SGD(learning_rate=0.01),
loss = losses.MeanSquaredError(),
)
history = model.fit(x_train, y_train, batch_size=256, epochs=128, validation_split=0.2)
使用模型进行预测
使用训练过的模型对测试数据集进行预测:
y_predict = model.predict(x_test)
y_pred = []
for i in range(len(y_test)):
y_pred.append(y_predict[i][0])
绘制真实值与预测值的图像
使用matplotlib绘制图表,使用日期作为横座标,使用收盘价÷10作为纵座标。
plt.figure(figsize=(16, 8)) plt.plot(date_test, y_test, label="real") plt.plot(date_test, y_pred, label="predict")
对预测结果的分析
根据预测结果绘制的函数图像如图所示:
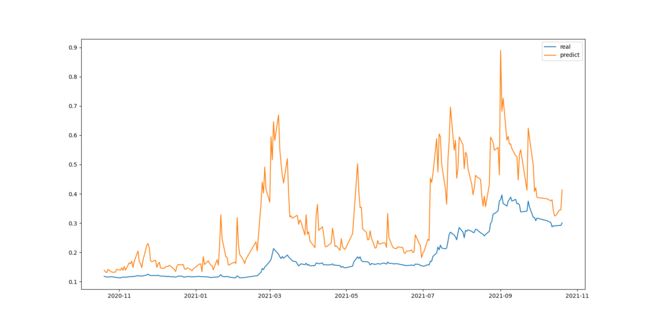
根据图像可以看出,预测值和真实值差距较大。这是由于影响股票价格的因素很多,选取的几个参数不能准确预测。
但是同时也可以看出,预测出来的结果与真实值变化趋势相近,说明线性回归模型在一定程度上能够解释收盘价与选取的feature之间的关系。
完整代码下载地址:
Python基于机器学习实现的股票价格预测、股票预测源码+数据集,机器学习大作业