【Java】文件操作与IO流(看完这一篇就够了)
文章目录
- 认识文件
- 文件的类型
- 操作文件
-
- 属性
- 构造方法
- 常用方法
- IO流
-
- 字节流
-
- InputStream
- OutputStream
- flush刷新
- 关闭文件close
- 字节缓冲流
- 字符流
-
- Reader
- Writer
- Scanner
- 字符缓冲流
- 复制文件
-
- 字节流复制图片
- 缓冲字节流复制图片
- 字符流复制Java文件
- 缓冲字符流复制Java文件
- 耗时对比
认识文件
- 侠义上的文件:硬盘上的文件和目录(文件夹)
- 广义上的文件:泛指计算机中很多的软硬件资源,操作系统中,把很多的硬件设备和软件资源抽象成文件,按照文件的方式统一管理
此处只讨论侠义上的文件,也就是硬盘上的文件
每个文件在硬盘上都有一个具体的路径,表示一个文件的具体位置路径,就可以使用/(斜杠)或\(反斜杠)来分割不同的目录级别
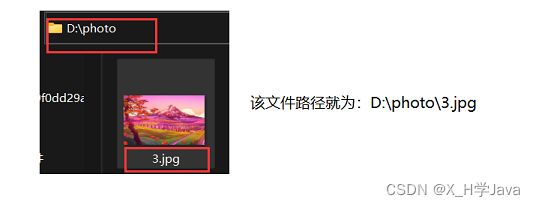
路径有两种表示风格:
- 绝对路径:以盘符
c:,d:这样开头的 - 相对路径:以当前所在的目录(工作目录)为基准,
./或../开头,./有时候可以省略
说明: 每个程序运行的时候都有一个工作目录,./为当前目录,../为上级目录,打开idea,下面的路径就是idea的工作目录,我们在程序中要是写相对目录的话,就是以该路径为基准的
![]()
文件的类型
我们一般将文件分为两种类型,文本文件与二进制文件
文本文件存的是文本也就是字符串,字符串是由字符构成的,每个字符是由一个整数数字表示的
二进制文件存储的是二进制数据
小技巧:如何区分文本文件与二进制文件?
使用记事本打开文件,看的懂就是文本文件,看不懂(乱码)的就是二进制文件
操作文件
Java标准库提供了File这个类
属性
separator是File类里的一个静态变量,表示的是系统里的路径分割符
System.out.println(File.separator);

\反斜杠是windows系统中路径的分割符
构造方法
| 构造方法 | 说明 |
|---|---|
| File(String pathName) | 根据文件路径创建一个File实例,路径可以为绝对或者相对路径 |
| File(File parent, String child) | 根据父目录与孩子文件创建一个File实例,父目录用File表示 |
| File(String parent, String child) | 根据父目录与孩子路径创建一个File实例,父目录用String表示 |
注意: 使用路径创建File实例的时候,不要求文件真实存在
File file1 = new File("D:/photo/1.jpg"); //最常用
File file2 = new File("D:/photo/","2.jpg");
File file3 = new File(new File("D:/photo/"),"3.jpg");
常用方法
| 返回值 | 方法 | 说明 |
|---|---|---|
| boolean | exists() | 目录或文件是否存在 |
| String | getName() | 返回目录或文件的名称 |
| String | getPath() | 返回文件路径(使用啥路径创建FIle,返回啥路径) |
| String | getAbsolutePath() | 返回绝对路径 |
| boolean | isDirectory() | 是否是目录 |
| boolean | isFile() | 是否是文件 |
| File[] | listFiles() | 返回目录下一级的子文件夹或子文件 |
| boolean | mkdir() | 创建目录 |
| boolean | mkdirs() | 创建多级目录 |
| boolean | createNewFile() | 创建文件 |
| boolean | delete() | 删除文件 |
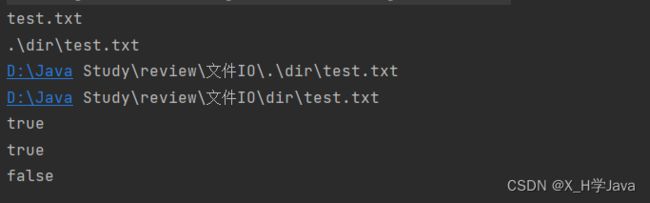
示例1:
File file = new File("./dir/test.txt"); //此路径不要求真实存在
System.out.println(file.getName()); //获取目录或文件名称
System.out.println(file.getPath()); //获取文件路径(用啥路径创建File,返回啥路径)
System.out.println(file.getAbsoluteFile()); //获取文件绝对路径
System.out.println(file.getCanonicalPath()); //获取使用File修饰过的绝对路径
System.out.println(file.exists()); //判断目录或文件是否存在
System.out.println(file.isFile()); //判断是否是文件
System.out.println(file.isDirectory()); //判断是否是目录
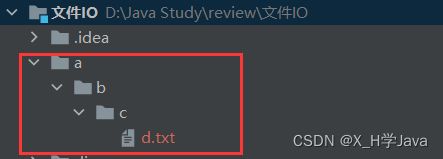
示例2:
File file = new File("./a/b/c");
file.mkdirs(); //创建多级目录
File file1 = new File("./a/b/c/d.txt");
file1.createNewFile(); //创建文件
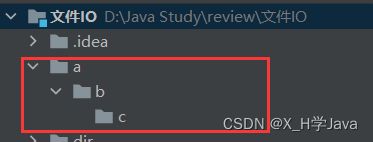
示例3:
File file1 = new File("./a/b/c/d.txt");
file1.delete(); //删除文件
IO流
针对文件内容的读写,使用流对象来操作
流对象从类型上分为两个大类别
- 字节流:操作二进制数据
InputStream(字节输入流)
OutputStream(字节输出流) - 字符流:操作文本数据
Reader(字符输入流)
Writer(字符输出流)
这些类的使用方式比较固定
- 打开文件
- 读文件
- 写文件
- 关闭文件
输入输出的方向
- 数据从硬盘到内存称为读(input)
- 数据从内存到硬盘称为写(output)
对于文本文件,推荐使用字符流进行读写,使用二进制读写也行,只是推荐使用字符流
对于二进制文件(图片,视频等),使用字节流进行读写
字节数组可以和字符串相互转换
字节数组转字符串
byte[] bytes = new byte[1024];
String str = new String(bytes);
还可以指定字节数组的范围
int len = 10;
String str = new String(bytes,0,len);
字符串转字节数组
String str = "hello";
byte[] bytes = str.getBytes();
字符转字节是编码,字节转字符是解码,解码编码如果不一致会发生乱码,所以在字符串与字节数组进行转换的时候可以指定编码集:
byte[] bytes = str.getBytes("utf-8");
String s = new String(bytes,"utf-8");
不同编码类型说明
- GBK:英文占1个字节,中文占2个字节
- UTF-8:英文占1个字节,中文占3个字节
- Unicode:英文占2个字节,中文占2个字节
- Ascll:单字节编码,无中文
字节流
InputStream
InputStream是一个抽象类不能创建实例,要创建实例得使用它的子类,我们使用FileInputStream创建字节输入流对象
InputStream的方法
| 方法 | 说明 |
|---|---|
| int read() | 一次读一个字节,返回读到的内容,返回-1代表读完 |
| int read(byte[] b) | 一次读一个字节数组,返回实际读到的长度,返回-1代表读完 |
| int read(byte[] b, int off, int len) | 往字节数组b从off开始,读取len个长度,返回读到的长度,返回-1代表读完 |
| void close() | 关闭字节输入流 |
FileInputStream的构造方法
| 构造方法 | 说明 |
|---|---|
| FileInputStream(String fileName) | 使用文件路径构建输入流对象(可以是绝对路径或相对路径) |
| FileInputStream(File file) | 使用File对象构建输入流对象 |
注意: 创建输入流的时候必须要保证文件存在,否则会抛出异常,因为是在读文件
一个字节一个字节的读:
public class Demo2 {
public static void main(String[] args) throws IOException {
//该文件路径必须存在,因为是读文件
InputStream is = new FileInputStream("./dir/test.txt");
int n;
while((n = is.read()) != -1){
System.out.println(n);
}
is.close();
}
}

上述代码是一次读一个字节,导致读的次数多,而单次IO操作是要访问硬盘设备的,单词操作是比较耗时的,如果频繁进行这样的IO操作,效率肯定低
一次读一个字节数组:
public class Demo3 {
public static void main(String[] args) throws IOException {
InputStream is = new FileInputStream("./dir/test.txt");
byte[] bytes = new byte[1024];
int len;
while((len = is.read(bytes)) != -1){
for(int i = 0;i < len;i++){
System.out.println(bytes[i]);
}
}
is.close();
}
}

这种操作一次最多可读1024个字节,大大减少了IO操作的次数,也就是减少了访问硬盘设备的次数,所以效率大大提高了
将读到的字节数组转换为字符串输出:
public class Demo3 {
public static void main(String[] args) throws IOException {
InputStream is = new FileInputStream("./dir/test.txt");
byte[] bytes = new byte[1024];
int len;
while((len = is.read(bytes)) != -1){
String s = new String(bytes,0,len);
System.out.println(s);
}
}
}

OutputStream
OutputStream也是一个抽象类,不可以创建实例,我们使用它的子类FileOutputStream创建字节输出流对象
注意: 使用FileOutputStream创建对象时,文件不要求真实存在,如果文件不存在,则会创建文件

运行程序后,发现文件被创建

方法
| 方法 | 说明 |
|---|---|
| void write(int b) | 一次写一个字节 |
| void write(byte[] b) | 一次写一个字节数组 |
| int write(byte[] b, int off, int len) | 从字节数组off位置开始写,一次写len长度 |
| void close() | 关闭字节输出流 |
写文件之前,文件中存在内容hello

public class Demo5 {
public static void main(String[] args) throws IOException {
OutputStream os = new FileOutputStream("./dir/test.txt");
os.write(97);
os.write(98);
os.write(99);
os.write(100);
os.close();
}
}
写文件后,文件内容被更新为abcd

使用OutputStream打开文件,
默认会清空文件原有的内容,如果想在原文件的基础上追加写,则在创建输出流对象时添加一个参数true,true代表不清空文件原有内容追加写
public class Demo5 {
public static void main(String[] args) throws IOException {
OutputStream os = new FileOutputStream("./dir/test.txt",true);
os.write(97);
os.write(98);
os.write(99);
os.write(100);
os.close();
}
}
发现在abcd的基础上又多了abcd

一次写一个字节数组:
public class Demo6 {
public static void main(String[] args) {
try(OutputStream os = new FileOutputStream("./dir/test.txt")){
byte[] bytes = {96,97,98,99,100};
os.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}
}
}
flush刷新
IO操作是很慢的,所以OutputStream为了减少IO次数,写数据的时候会先将数据写到内存的一个指定区域里,该区域称为
缓冲区,直到该区域满了或者满足其他指定条件时,才会把数据真正的写入到硬盘中,所以我们写文件的时候,很可能数据还存在缓冲区中,我们常常在合适的位置调用flush(),将数据刷新到硬盘中
public class Demo6 {
public static void main(String[] args) {
try(OutputStream os = new FileOutputStream("./dir/test.txt")){
byte[] bytes = {96,97,98,99,100};
os.write(bytes);
os.flush(); //刷新操作
} catch (IOException e) {
e.printStackTrace();
}
}
}
关闭文件close
在写或者读完文件,都要调用close来关闭文件,那调用close到底关闭的是什么?
在内核里,使用
PCB这样的数据结构来表示进程,一个进程可以用一个或者多个PCB来表示,而一个线程对应一个PCB,PCB中有一个属性,文件描述符表(类似与数组)记录了该进程打开了哪些文件
一个进程里有多个线程,有多个PCB,这些PCB公用一个文件描述符表
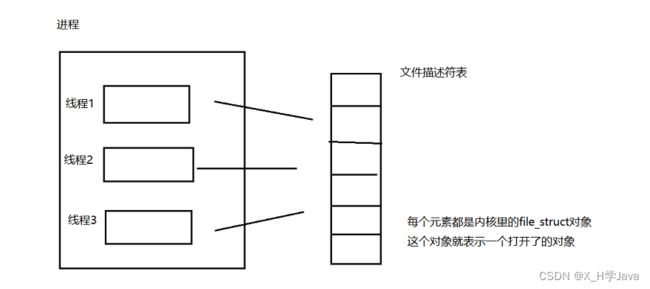
- 每次打开文件,就会在文件描述符表中申请一个空间,然后把该文件的信息放进去
- 每次关闭文件(close),就会把这个文件描述符表对应的表项释放掉
如果文件没关闭,也就是没有调用close会怎样呢?
如果没有调用close,那文件描述符中对应的表项就不会及时的被释放掉,虽然Java中有GC操作,但是这个GC不一定及时,也就是不手动调用close释放,会导致文件描述符表很快被占满了(文件描述符表的容量大小一定,不能自动扩容)如果被占满了,后续在打开文件向文件描述符表申请空间的时候就会失败,所以文件就打不开了
一般来说close要被手动执行的,但是如果该文件始终伴随着程序,那么不关闭问题也不大,因为随着程序的运行结束,进程的销毁,PCB也就跟着销毁了,文件描述符表也就销毁了,对应的资源,操作系统就自动回收了
一般写代码都是要手动调用close的,那么如果保证close一定被执行到呢?
使用try-finally
public class Demo5 {
public static void main(String[] args) throws IOException {
OutputStream os = null;
try{
os = new FileOutputStream("./dir/test.txt",true);
os.write(97);
os.write(98);
os.write(99);
os.write(100);
}finally{
os.close();
}
}
}
这种方式代码写着不优雅,有一种更推荐的写法
public class Demo5 {
public static void main(String[] args) throws IOException {
try(OutputStream os = new FileOutputStream("./dir/test.txt",true)){
os.write(97);
os.write(98);
os.write(99);
os.write(100);
}
}
}
这样写对然没有显式调用close,但是在try语句块执行完,会自动调用close,try()中满足自动释放的有一定要求的,类必须实现Closeable接口,才可以自动调用close释放资源

字节缓冲流
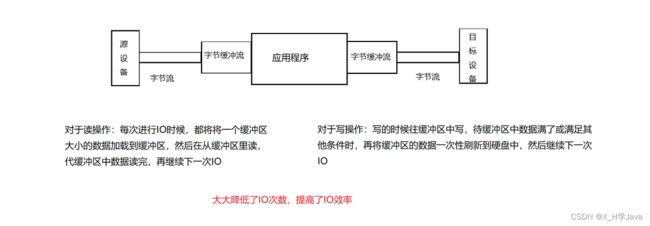
一个字节一个字节的读会频繁进行IO操作,也就是频繁发生系统内核调用,这个操作是很耗时的,使用字节缓冲流,类似“池子”快速读写,减少系统内核调用频率
- 字节缓冲输入流:BufferedInputStream(InputStream is)
- 字节缓冲输出流:BufferedOutputStream(OutputStream os)
注意: 字节缓冲流构造函数的参数是字节流对象不是文件路径
缓冲流在内存提供一个区域为缓冲区,做了封装以块形式读写数据,但是读写数据还是依赖字节流对象,缓冲区的大小默认是8k(8192字节)
缓冲流和字节流之间的关系图:
缓冲字节输入流读数据
public class Demo10 {
public static void main(String[] args) throws IOException {
try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream("./dir/test.txt"))){
int n;
byte[] bytes = new byte[1024];
while((n = bis.read(bytes)) != -1){
String str = new String(bytes,0,n);
System.out.print(str);
}
}
}
}

缓冲字节输出流写数据
public class Demo11 {
public static void main(String[] args) throws IOException {
try(BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("./dir/test.txt"))){
String str = "世界,你好";
byte[] bytes = str.getBytes();
bos.write(bytes);
bos.flush();
}
}
}

字符流
字符流其实就是带编码的字节流,对于文本类型的文件,优先使用字符流,字符流的使用和字节流差不多
Reader
Reader是一个抽象类,必须new其子类FileReader
| 方法 | 说明 |
|---|---|
| int read() | 一次读一个字符,返回读的内容,返回-1代表读完 |
| int read(char[] c) | 一次读一个字符数组,返回读的长度,返回-1待变读完 |
| int read(char[] c, int off, int len) | 一次读一个字符数组的范围 |
一次读一个字符
public class Demo8 {
public static void main(String[] args) throws IOException {
try(Reader r = new FileReader("./dir/test.txt")){
int n;
while((n = r.read()) != -1){
System.out.println(n);
}
}
}
}
往字符数组中读
public class Demo8 {
public static void main(String[] args) throws IOException {
try(Reader r = new FileReader("./dir/test.txt")){
char[] c = new char[100];
int n;
while((n = r.read(c)) != -1){
String s = new String(c,0,n);
System.out.print(s);
}
}
}
}

Writer
Writer是一个抽象类,new的时候必须new其子类FileWriter
| 方法 | 说明 |
|---|---|
| void write(int c) | 一次写一个字符 |
| void write(String str) | 一次写一个字符串 |
| void write(char[] c) | 一次写一个字符数组 |
| void write(String str, int off, int len) | 一次写字符串的部分数据 |
| void write(char[] c, int off, int len) | 一次写字符数组的部分数据 |
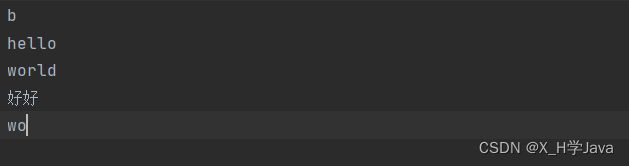
public class Demo9 {
public static void main(String[] args) throws IOException {
try(Writer w = new FileWriter("./dir/test.txt")){
w.write(98);
w.write('\n');
w.write("hello");
w.write('\n');
char[] c = {'w','o','r','l','d'};
w.write(c);
w.write('\n');
w.write("好好学习",0,2);
w.write('\n');
w.write(c,0,2);
w.flush();
}
}
}
Scanner
Scanner是搭配流对象使用的
| 构造方法 | 说明 |
|---|---|
| Scanner(InputStream is, String charset) | 使用charset字符集对is的扫描进行读取 |
我们常常写的这句代码:System.in就是一个输入流对象
Scanner sc = new Scanner(System.in);
也可以使用我们存在的文件构建流对象传入:
public class Demo7 {
public static void main(String[] args) {
try(Scanner sc = new Scanner(new FileInputStream("./dir/test.txt"))){
while(sc.hasNext()){
System.out.println(sc.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
字符缓冲流
字符缓冲流的用法和字节缓冲流一样,是对字符流进行了封装,缓冲区的大小默认也是8k
- 字符缓冲输入流:BufferedReader(FileReader fr)
- 字符串冲输出流:BufferedWriter(FileWriter fw)
字符缓冲流读数据
public class Demo12 {
public static void main(String[] args) throws IOException {
try(BufferedReader br = new BufferedReader(new FileReader("./dir/test.txt"))){
int len;
char[] c = new char[10];
while((len = br.read(c)) != -1){
String str = new String(c,0,len);
System.out.print(str);
}
}
}
}

字符缓冲流写数据
public class Demo12 {
public static void main(String[] args) throws IOException {
try(BufferedWriter bw = new BufferedWriter(new FileWriter("./dir/test.txt"))){
String str = "好好学习 找好工作";
bw.write(str);
bw.flush();
}
}
}

复制文件
复制文件前提说明:
- 用字节流复制图片文件(.jpg)
- 用字符流复制普通的xml文件(.xml)
字节流复制图片
public static void method1() throws IOException {
InputStream is = new FileInputStream("./dir/图片.jpg");
OutputStream os = new FileOutputStream("./dir/图片复制.jpg");
int len;
byte[] bytes = new byte[1024];
while((len = is.read(bytes)) != -1){
os.write(bytes,0,len);
}
os.flush();
os.close();
is.close();
}
缓冲字节流复制图片
public static void method2() throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("./dir/图片.jpg"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("./dir/图片复制1.jpg"));
int len;
byte[] bytes = new byte[1024];
while((len = bis.read(bytes)) != -1){
bos.write(bytes);
}
bos.flush();
bos.close();
bis.close();
}
字符流复制Java文件
public static void method3() throws IOException {
FileReader fr = new FileReader("./dir/server.xml");
FileWriter fw = new FileWriter("./dir/server1.xml");
int len;
char[] c = new char[255];
while((len = fr.read(c)) != -1){
fw.write(c,0,len);
}
fw.flush();
fw.close();
fr.close();
}
缓冲字符流复制Java文件
public static void method4() throws IOException {
BufferedReader br = new BufferedReader(new FileReader("./dir/server.xml"));
BufferedWriter bw = new BufferedWriter(new FileWriter("./dir/server2.xml"));
int len;
char[] c = new char[255];
while((len = br.read(c)) != -1){
bw.write(c,0,len);
}
bw.flush();
bw.close();
br.close();
}
耗时对比
我们对上述的四个操作的耗时进行分组对比
- 字节流与缓冲字节流对比
- 字符流与缓冲字符流对比
看看哪个效率更高?
public static void main(String[] args) throws IOException {
long start1 = System.currentTimeMillis();
method1();
long end1 = System.currentTimeMillis();
System.out.println("字节流耗时:"+(end1-start1));
long start2 = System.currentTimeMillis();
method2();
long end2 = System.currentTimeMillis();
System.out.println("缓冲字节流耗时:"+(end2-start2));
long start3 = System.currentTimeMillis();
method3();
long end3 = System.currentTimeMillis();
System.out.println("字符流耗时:"+(end3-start3));
long start4 = System.currentTimeMillis();
method4();
long end4 = System.currentTimeMillis();
System.out.println("缓冲字符流耗时:"+(end4-start4));
}

从中发现,
带缓冲的流比不带缓冲的流效率高,但是这里好像差别不大,那是因为这里举例的文件本身不大,如果换成稍微大的文件,效果更明显