Python 统计学生成绩并进行可视化统计
Python 统计学生成绩并进行可视化统计
实验目的
对学生学习情况进行数据可视化分析
实验数据
xAPI-Edu-Data 来源于阿里云天池
实验内容
- 分析学校的男女比例,并判断男女学生的选课情况和学习情况
- 看各学科的选课情况及成绩分布
- 看缺课与成绩的关系
- 看成绩和班级的关系
列索引
'''
'gender', 'NationalITy', 'PlaceofBirth', 'StageID', 'GradeID',
'SectionID', 'Topic', 'Semester', 'Relation', 'raisedhands',
'VisITedResources', 'AnnouncementsView', 'Discussion',
'ParentAnsweringSurvey', 'ParentschoolSatisfaction',
'StudentAbsenceDays', 'Class'
'''
- Class :班级
- gender:性别
- Topic:课程名称
- StudentAbsenceDays:缺课天数
- SectionID:班级号
内容一
#首先看一下学生的男女比例
gender = stu['gender'].value_counts(ascending=True) #求每一个元素的个数并排序
gender.plot(kind='pie',shadow=True,explode=(0,0.1),autopct='%1.1f%%',startangle=90,legend=False,colormap='Set3')
#画饼状图

#成绩人数比以及男女选课情况
dic = {}
dic2 = {}
for i in range(len(gender)):
temp = stu['gender'] == gender.index[i] #筛查找出同性别的学生
dic[gender.index[i]] = stu[temp]['Class']
dic[gender.index[i]] = dic[gender.index[i]].value_counts(ascending=True)
dic2[gender.index[i]] = stu[temp]['Topic']
dic2[gender.index[i]] = dic2[gender.index[i]].value_counts(ascending=True)
dic_gen = pd.DataFrame(dic)
dic_gen['F'] = dic_gen['F']/np.sum(dic_gen['F'])
dic_gen['M'] = dic_gen['M']/np.sum(dic_gen['M'])
dic_gen.plot(kind='bar',rot=0,colormap='Set3')
dic2_sel = pd.DataFrame(dic2)
dic2_sel.plot(kind='pie',subplots=True,figsize=(20,20),legend=None,colormap='Set3',fontsize=15)
#从图中可以看出,女生成绩好一点,但男生成绩更加集中
#从选课情况看女生选语言选得要比男生多,但男生选IT和数学选得比女生多


#最后看一下全体同学情况
grade = stu['Class'].value_counts(ascending=True)
grade = grade[['L','M','H']]
grade.plot(kind='bar',rot=0)
#看起来也比较服从正态分布

内容二
course = stu['Topic'].value_counts(ascending=True)
course.plot(kind='bar',rot=0,figsize=(15,10),colormap='Set3',fontsize=15) #各科选课人数多少
#可以看出选IT的人最多,选历史的人最少

#查看每一科的成绩
dic = {}
for i in range(len(course)):
temp = stu['Topic'] == course.index[i]
dic[course.index[i]] = stu[temp]['Class']
dic[course.index[i]] = dic[course.index[i]].value_counts(ascending=True)
dic_cour = pd.DataFrame(dic).T
dic_cour.plot(kind='bar',rot=0,colormap='Set3',figsize=(15,9))

内容三
#看缺课和成绩的关系
absence = stu['StudentAbsenceDays'].value_counts(ascending=True)
dic = {}
for i in range(len(absence)):
temp = stu['StudentAbsenceDays'] == absence.index[i]
dic[absence.index[i]] = stu[temp]['Class']
dic[absence.index[i]] = dic[absence.index[i]].value_counts(ascending=True)
dic_ab = pd.DataFrame(dic)
dic_ab['Above-7'] = dic_ab['Above-7']/np.sum(dic_ab['Above-7'])
dic_ab['Under-7'] = dic_ab['Under-7']/np.sum(dic_ab['Under-7'])
dic_ab.plot(kind='bar',colormap='Set3',rot=0,figsize=(10,8),fontsize=12)
#从图上看,L成绩段中有很多缺课大于7天的学生,H成绩段中只有少部分人缺课大于7天

内容四
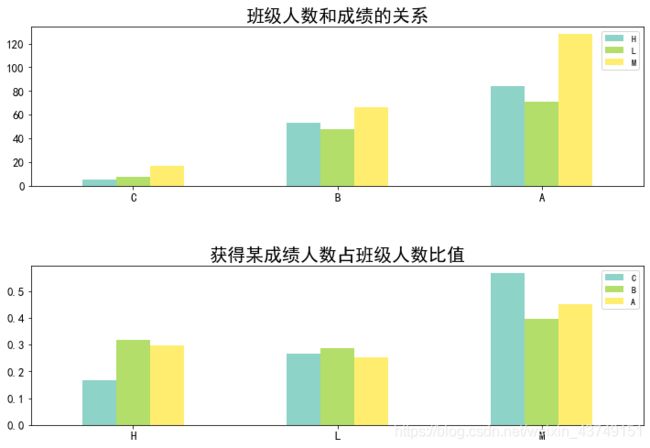
#看成绩和班级的关系
sec = stu['SectionID'].value_counts(ascending=True)
dic = {}
for i in range(len(sec)):
temp = stu['SectionID'] == sec.index[i]
dic[sec.index[i]] = stu[temp]['Class']
dic[sec.index[i]] = dic[sec.index[i]].value_counts(ascending=True)
dic_se = pd.DataFrame(dic).T
dic_se.plot(kind='bar',colormap='Set3',rot=0,figsize=(12,8),fontsize=13)

#但这么看没什么用,需要看比值,换句话说就是看平均分或者好坏成绩的学生占班级总人数的比
dic_se2 = dic_se.T
dic_se2['A'] = dic_se.T['A']/np.sum(dic_se.T['A'])
dic_se2['B'] = dic_se.T['B']/np.sum(dic_se.T['B'])
dic_se2['C'] = dic_se.T['C']/np.sum(dic_se.T['C'])
dic_se2.plot(kind='bar',colormap='Set3',rot=0,figsize=(12,8),fontsize=13)
#求平均值后得到下图,可以看出

总代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#导入数据
stu = pd.read_csv("student.csv")
columns = stu.columns #获得列索引
plt.rcParams['font.family']='simhei'
#构建一段经常用的代码,没什么意思,主要是要不这么搞后面一直重复
def inters(data, index1, index2):
dic = {}
for i in range(len(data)):
temp = stu[index1] == data.index[i]
dic[data.index[i]] = stu[temp][index2]
dic[data.index[i]] = dic[data.index[i]].value_counts(ascending=True)
dic_temp = pd.DataFrame(dic)
return dic_temp
#首先看一下学生的男女比例
gender = stu['gender'].value_counts(ascending=True) #求每一个元素的个数并排序
gender.plot(kind='pie',shadow=True,explode=(0,0.1),autopct='%1.1f%%',startangle=90,legend=False,colormap='Set3',
label=' ',title = '男女比例',fontsize=20,figsize=(10,10)) #画饼状图
#看以下性别和成绩的关系以及性别和选课的关系
fig, ax = plt.subplots(1,3, figsize=(60,20))
#看男女成绩分布情况
dic_gen = inters(gender, 'gender', 'Class')
ax[2].set_title("男女成绩分布情况",fontsize=20)
dic_gen.plot(kind='bar',rot=0,colormap='Set3',ax=ax[2],fontsize=20)
#看男女选课情况,并用饼状图表示
dic_sel = inters(gender, 'gender', 'Topic')
ax[0].set_title("女生选课情况",fontsize=20)
ax[1].set_title("男生选课情况",fontsize=20)
dic_sel.plot(kind='pie',subplots=True,figsize=(20,20),fontsize=20,legend=None,colormap='Set3',label=' ',ax=ax[0:2])
#看各学科的选课情况及成绩分布
#创建子图
fig, ax = plt.subplots(3,1, figsize=(100,60))
plt.subplots_adjust(hspace=0.5)
#看选课人数与科目关系
course = stu['Topic'].value_counts(ascending=True)
ax[0].set_title("课程与选课人数",fontsize=20)
course.plot(kind='bar',rot=0,figsize=(15,10),colormap='Set3',fontsize=15,ax=ax[0]) #各科选课人数多少
#可以看出选IT的人最多,选历史的人最少
#查看每一科的成绩
dic_cour = inters(course, 'Topic', 'Class')
ax[1].set_title("每一科的成绩",fontsize=20)
dic_cour.T.plot(kind='bar',rot=0,colormap='Set3',ax=ax[1])
#查看哪些科目高分的人多
ax[2].set_title("成绩与科目分布",fontsize=20)
#ax[2].legend(loc=10)
dic_cour.plot(kind='bar',rot=0,colormap='Set3',ax=ax[2],figsize=(20,15))
ax[2].legend(loc=5)
#看缺课和成绩的关系
absence = stu['StudentAbsenceDays'].value_counts(ascending=True) #按照元素出现多少进行排序
dic_ab = inters(absence, 'StudentAbsenceDays', 'Class')
dic_ab['Above-7'] = dic_ab['Above-7']/np.sum(dic_ab['Above-7'])
dic_ab['Under-7'] = dic_ab['Under-7']/np.sum(dic_ab['Under-7'])
dic_ab.plot(kind='bar',colormap='Set3',rot=0,figsize=(10,8),fontsize=12,title="缺课与成绩")
#从图上看,L成绩段中有很多缺课大于7天的学生,H成绩段中只有少部分人缺课大于7天
#看成绩和班级的关系
#创建子图
fig, ax = plt.subplots(2,1, figsize=(60,100))
plt.subplots_adjust(hspace=0.5)
sec = stu['SectionID'].value_counts(ascending=True)
dic_se = inters(sec, 'SectionID', 'Class')
dic_se = dic_se.T
ax[0].set_title("班级人数和成绩的关系",fontsize=20)
dic_se.plot(kind='bar',colormap='Set3',rot=0,figsize=(12,8),fontsize=13,ax=ax[0])
#但这么看没什么用,需要看比值,换句话说就是看平均分或者好坏成绩的学生占班级总人数的比
dic_se2 = dic_se.T
dic_se2['A'] = dic_se.T['A']/np.sum(dic_se.T['A'])
dic_se2['B'] = dic_se.T['B']/np.sum(dic_se.T['B'])
dic_se2['C'] = dic_se.T['C']/np.sum(dic_se.T['C'])
ax[1].set_title("获得某成绩人数占班级人数比值",fontsize=20)
dic_se2.plot(kind='bar',colormap='Set3',rot=0,figsize=(12,8),fontsize=13,ax=ax[1])