学习曲线和验证曲线
文章目录
- 学习曲线和验证曲线
-
- 学习曲线
- 验证曲线
- 误差曲线
- 偏差、方差与模型复杂度的关系
学习曲线
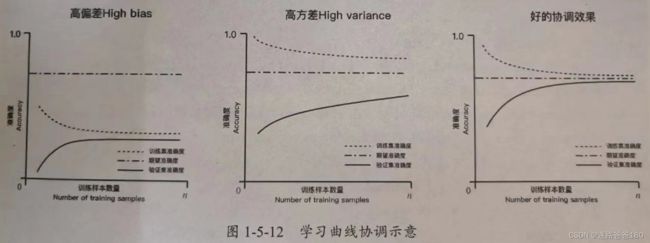
- 学习曲线是在训练集大小不同时,通过绘制模型训练集和交叉验证集上的准确率来观察模型在新数据上的表现,进而判断模型的方差或偏差是否过高,以及增大训练集是否可以减小过拟合。
- 最左边和最右边的区别就看准确率是否收敛到 0.5 以上。
- 学习曲线代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import ShuffleSplit
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import learning_curve
plt.figure(figsize=(18,10),dpi=150)
def plot_learning_curve(estimator, title, x, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes,train_scores,test_scores=learning_curve(estimator,X,y,cv=cv,n_jobs=n_jobs,train_sizes=train_sizes)
train_scores_mean=np.mean(train_scores,axis=1)
train_scores_std=np.std(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
test_scores_std=np.std(test_scores,axis=1)
plt.grid()
plt.fill_between(train_sizes,test_scores_mean-train_scores_std,train_scores_mean+test_scores_std,alpha=0.1,color="r")
plt.fill_between(train_sizes,test_scores_mean-train_scores_std,train_scores_mean+test_scores_std,alpha=0.1,color="g")
plt.plot(train_sizes,train_scores_mean,"o-",color="r",label="Training score")
plt.plot(train_sizes,test_scores_mean,"o-",color="g",label="Cross-validation score")
plt.legend(loc="best")
return plt
train_data2 = pd.read_csv('./data/zhengqi_train.txt', sep='\t')
test_data2 = pd.read_csv('./data/zhengqi_test.txt', sep='\t')
X = train_data2[test_data2.columns].values
y = train_data2["target"].values
title = "LinearRegression"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = SGDRegressor()
plot_learning_curve(estimator, title, X, y, ylim=(0.7,1.01), cv=cv, n_jobs=-1)
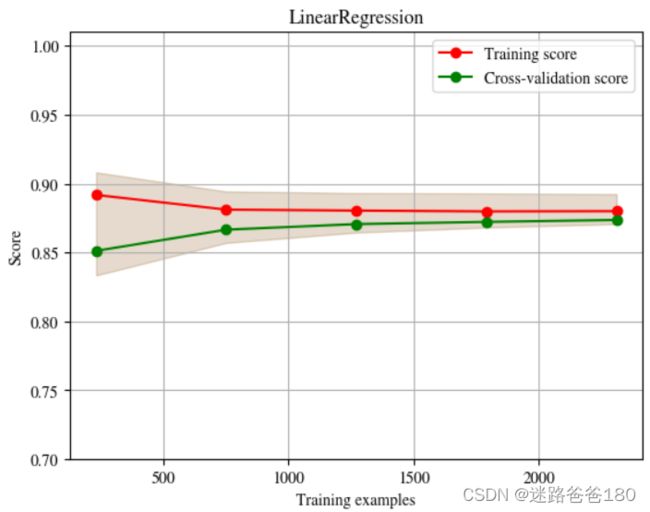
- 程序画出来的图如下:
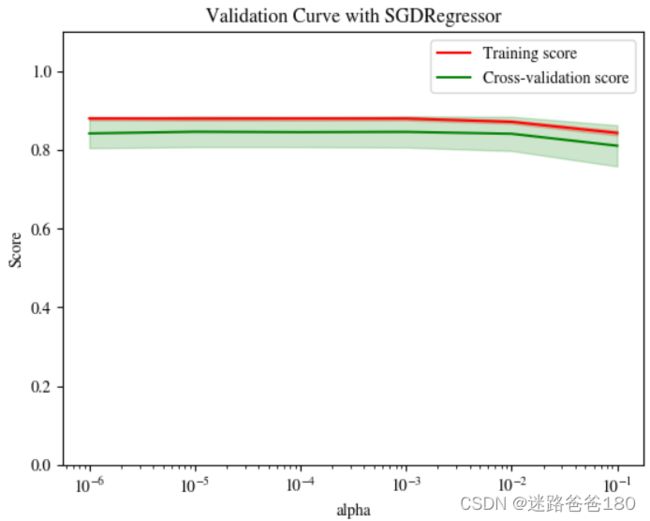
验证曲线
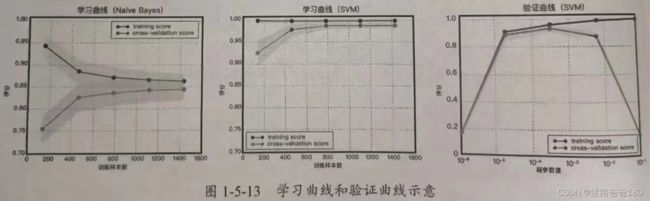
- 和学习曲线不同,验证曲线的横轴为某个超参数的一系列值,由此比较不同参数设置下(而非不同训练集大小)模型的准确率。
- 从下图验证曲线上可以看到,随着超参数设置的改变,模型可能会有从欠拟合到合适再到过拟合的过程,进而可以选择一个合适的设置来提高模型的性能。
- 验证曲线代码
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import validation_curve
import matplotlib as mpl
mpl.rcParams.update({
"text.usetex": False,
"font.family": "stixgeneral",
"mathtext.fontset": "stix",
})
X = train_data2[test_data2.columns].values
y = train_data2["target"].values
param_range = [0.1,0.01,0.001,0.0001,0.00001,0.000001]
train_scores, test_scores = validation_curve(SGDRegressor(max_iter=1000, tol=1e-3, penalty="L1"), X, y, param_name="alpha", param_range=param_range, cv=10, scoring="r2", n_jobs=1)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with SGDRegressor")
plt.xlabel("alpha")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
plt.semilogx(param_range, train_scores_mean, label="Training score", color="r")
plt.fill_between(param_range,
train_scores_mean-train_scores_std,
train_scores_mean+train_scores_std,
alpha=0.2,
color="r")
plt.semilogx(param_range,test_scores_mean,
label="Cross-validation score",
color="g")
plt.fill_between(param_range,
test_scores_mean-test_scores_std,
test_scores_mean+test_scores_std,
alpha=0.2,
color="g")
plt.legend(loc="best")
plt.show()
- 程序画出来的图如下:
误差曲线
- 训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已经非常强了,训练数据发生的轻微扰动都会导致学习器发生显著鲜花,若训练数据自身的、非全局的特性倍学习器学到了,则将发生过拟合。
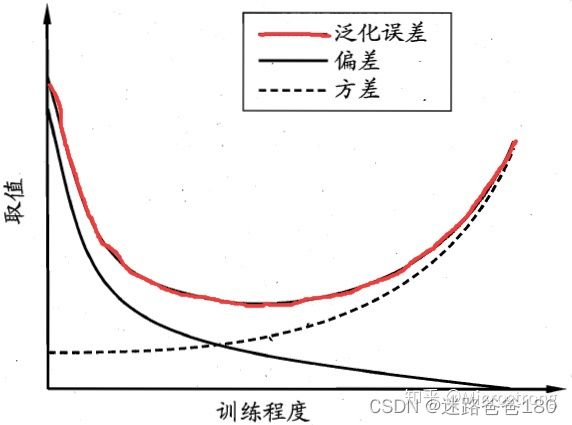
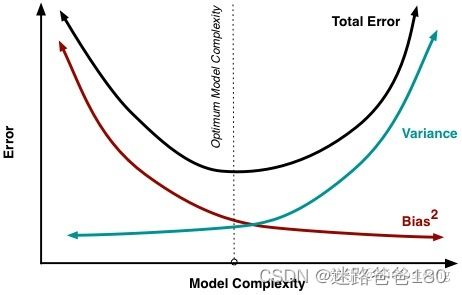
偏差、方差与模型复杂度的关系
- 方差和偏差无法避免,那么有什么办法尽量减少它对模型的影响呢?
- 一个好的办法就是正确选择模型的复杂度。复杂度高的模型通常对训练数据有很好的拟合能力,但是对测试数据就不一定了。而复杂度太低的模型又不能很好的拟合训练数据,更不能很好的拟合测试数据。因此,模型复杂度和模型偏差和方差具有如下图的所示关系。