Guass Rank(深度学习数值特征归一化方法)
Gauss rank是在学习中见识到的,主要应用于深度学习模型中连续性数值特征归一化的一种方式,可以看出,对最终结果有一定增益。
| minmax | norm | guassrank |
|---|---|---|
| Loss | 0.01669 | 0.01669 |
| AUC | 0.74477 | 0.74274 |
主要的步骤如下:
1.将原始数值进行排序,得到其排序特征,这里使用的是numpy.argsort函数实现,第一次argsort,是应该在该索引位置的数字索引,第二次argsort是该位置数值的实际排序。
2.尺度转化为[-1,1], 将该位置的排序除以最大排序,在扩大2倍,本文还增加了一个bound,避免数值为-1或者1从而导致erfinv为无穷。
3.调整极值,主要使用的工具是numpy.clip
4.erfinv,使用的scipy的sepcial接口
对自己的数据做了一个测试,转化后的数据服从标准正态分布
转化前:
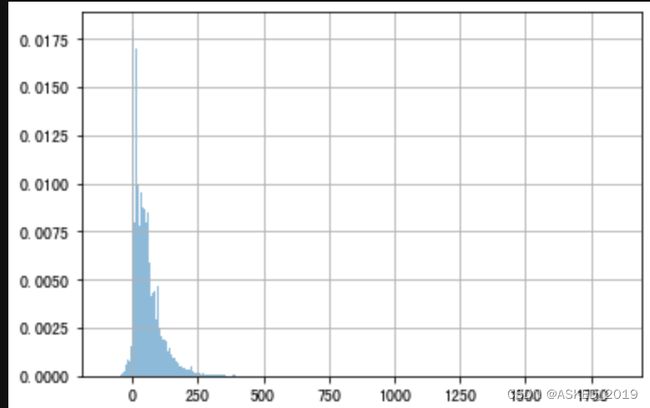
转化后:
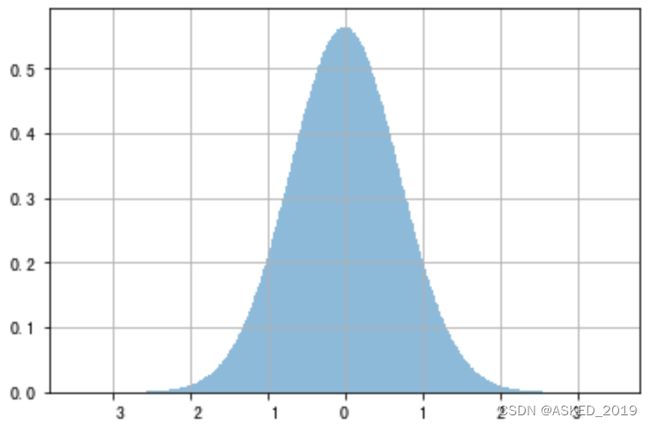
代码:
import numpy as np
from joblib import Parallel, delayed
from scipy.interpolate import interp1d
from scipy.special import erf, erfinv
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import FLOAT_DTYPES, check_array, check_is_fitted
class GaussRankScaler(BaseEstimator, TransformerMixin):
"""Transform features by scaling each feature to a normal distribution.
Parameters
----------
epsilon : float, optional, default 1e-4
A small amount added to the lower bound or subtracted
from the upper bound. This value prevents infinite number
from occurring when applying the inverse error function.
copy : boolean, optional, default True
If False, try to avoid a copy and do inplace scaling instead.
This is not guaranteed to always work inplace; e.g. if the data is
not a NumPy array, a copy may still be returned.
n_jobs : int or None, optional, default None
Number of jobs to run in parallel.
``None`` means 1 and ``-1`` means using all processors.
interp_kind : str or int, optional, default 'linear'
Specifies the kind of interpolation as a string
('linear', 'nearest', 'zero', 'slinear', 'quadratic', 'cubic',
'previous', 'next', where 'zero', 'slinear', 'quadratic' and 'cubic'
refer to a spline interpolation of zeroth, first, second or third
order; 'previous' and 'next' simply return the previous or next value
of the point) or as an integer specifying the order of the spline
interpolator to use.
interp_copy : bool, optional, default False
If True, the interpolation function makes internal copies of x and y.
If False, references to `x` and `y` are used.
Attributes
----------
interp_func_ : list
The interpolation function for each feature in the training set.
"""
def __init__(
self,
epsilon=1e-4,
copy=True,
n_jobs=None,
interp_kind="linear",
interp_copy=False,
):
self.epsilon = epsilon
self.copy = copy
self.interp_kind = interp_kind
self.interp_copy = interp_copy
self.fill_value = "extrapolate"
self.n_jobs = n_jobs
self.bound = 1.0 - self.epsilon
def fit(self, X, y=None):
"""Fit interpolation function to link rank with original data for future scaling
Parameters
----------
X : array-like, shape (n_samples, n_features)
The data used to fit interpolation function for later scaling along the features axis.
y
Ignored
"""
X = check_array(
X, copy=self.copy, estimator=self, dtype=FLOAT_DTYPES, force_all_finite=True
)
self.interp_func_ = Parallel(n_jobs=self.n_jobs)(
delayed(self._fit)(x) for x in X.T
)
return self
def _fit(self, x):
x = self.drop_duplicates(x)
rank = np.argsort(np.argsort(x))
factor = np.max(rank) / 2.0 * self.bound
scaled_rank = np.clip(rank / factor - self.bound, -self.bound, self.bound)
return interp1d(
x,
scaled_rank,
kind=self.interp_kind,
copy=self.interp_copy,
fill_value=self.fill_value,
)
def transform(self, X, copy=None):
"""Scale the data with the Gauss Rank algorithm
Parameters
----------
X : array-like, shape (n_samples, n_features)
The data used to scale along the features axis.
copy : bool, optional (default: None)
Copy the input X or not.
"""
check_is_fitted(self, "interp_func_")
copy = copy if copy is not None else self.copy
X = check_array(
X, copy=copy, estimator=self, dtype=FLOAT_DTYPES, force_all_finite=True
)
X = np.array(
Parallel(n_jobs=self.n_jobs)(
delayed(self._transform)(i, x) for i, x in enumerate(X.T)
)
).T
return X
def _transform(self, i, x):
clipped = np.clip(self.interp_func_[i](x), -self.bound, self.bound)
return erfinv(clipped)
def inverse_transform(self, X, copy=None):
"""Scale back the data to the original representation
Parameters
----------
X : array-like, shape [n_samples, n_features]
The data used to scale along the features axis.
copy : bool, optional (default: None)
Copy the input X or not.
"""
check_is_fitted(self, "interp_func_")
copy = copy if copy is not None else self.copy
X = check_array(
X, copy=copy, estimator=self, dtype=FLOAT_DTYPES, force_all_finite=True
)
X = np.array(
Parallel(n_jobs=self.n_jobs)(
delayed(self._inverse_transform)(i, x) for i, x in enumerate(X.T)
)
).T
return X
def _inverse_transform(self, i, x):
inv_interp_func = interp1d(
self.interp_func_[i].y,
self.interp_func_[i].x,
kind=self.interp_kind,
copy=self.interp_copy,
fill_value=self.fill_value,
)
return inv_interp_func(erf(x))
@staticmethod
def drop_duplicates(x):
is_unique = np.zeros_like(x, dtype=bool)
is_unique[np.unique(x, return_index=True)[1]] = True
return x[is_unique]
问题解决:
高斯排序变化是将一组连续特征转化为相对的排序特征,在应用中最大的问题就是如果在测试集中出现训练集中没有的数字该怎么处理?
而这一问题的解决方案是插值,通过插值的方法拟合相对的数值,从而达到一定的效果。
其他
本文代码主要学习于[3], 其中对于不同特征使用了parrallel进行了加速
使用:
from gauss_rank_scaler.gauss_rank_scaler import GaussRankScaler
import pandas as pd
from sklearn.datasets import load_boston
%matplotlib inline
# prepare some data
bunch = load_boston()
df_X_train = pd.DataFrame(bunch.data[:250], columns=bunch.feature_names)
df_X_test = pd.DataFrame(bunch.data[250:], columns=bunch.feature_names)
# plot histograms of two numeric variables
_ = df_X_train[['CRIM', 'DIS']].hist()
# scale the numeric variables with Gauss Rank Scaler
scaler = GaussRankScaler()
df_X_new_train = scaler.fit_transform(df_X_train[['CRIM', 'DIS']])
# plot histograms of the scaled variables
_ = pd.DataFrame(df_X_new_train, columns=['CRIM', 'DIS']).hist()
ref:
1.特征工程文章
2.知乎
3.github
4. scipy.interpolate.interp1d
5. interp1d_1
6. interpolate