Sentinel学习笔记
Sentinel
官方文档: https://github.com/alibaba/Sentinel/wiki/%E4%B8%BB%E9%A1%B5
SpringCloud Alibaba: https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html#_spring_cloud_alibaba_sentinel
是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
Sentinel 基本概念
资源
资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则
围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
Sentinel 功能和设计理念
流量控制
什么是流量控制
流量控制在网络传输中是一个常用的概念,它用于调整网络包的发送数据。然而,从系统稳定性角度考虑,在处理请求的速度上,也有非常多的讲究。任意时间到来的请求往往是随机不可控的,而系统的处理能力是有限的。我们需要根据系统的处理能力对流量进行控制。Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状,如下图所示:
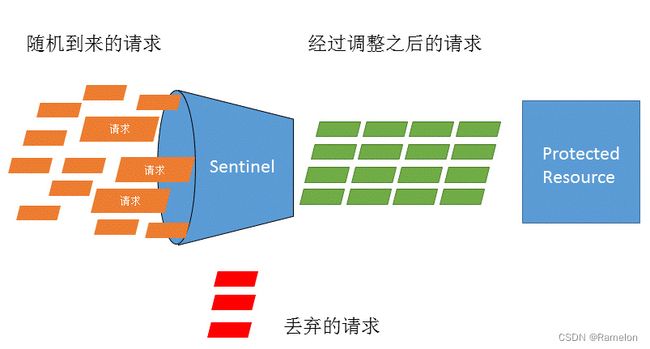
流量控制设计理念
流量控制有以下几个角度:
- 资源的调用关系,例如资源的调用链路,资源和资源之间的关系;
- 运行指标,例如 QPS、线程池、系统负载等;
- 控制的效果,例如直接限流、冷启动、排队等。
Sentinel 的设计理念是让您自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
熔断降级
什么是熔断降级
除了流量控制以外,及时对调用链路中的不稳定因素进行熔断也是 Sentinel 的使命之一。由于调用关系的复杂性,如果调用链路中的某个资源出现了不稳定,可能会导致请求发生堆积,进而导致级联错误。
Sentinel 和 Hystrix 的原则是一致的: 当检测到调用链路中某个资源出现不稳定的表现,例如请求响应时间长或异常比例升高的时候,则对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障。
熔断降级设计理念
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。
Hystrix 通过 线程池隔离 的方式,来对依赖(在 Sentinel 的概念中对应 资源)进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本(过多的线程池导致线程数目过多),还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
- 通过并发线程数进行限制
和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
- 通过响应时间对资源进行降级
除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
系统自适应保护
Sentinel 同时提供系统维度的自适应保护能力。防止雪崩,是系统防护中重要的一环。当系统负载较高的时候,如果还持续让请求进入,可能会导致系统崩溃,无法响应。在集群环境下,网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,这个增加的流量就会导致这台机器也崩溃,最后导致整个集群不可用。
针对这个情况,Sentinel 提供了对应的保护机制,让系统的入口流量和系统的负载达到一个平衡,保证系统在能力范围之内处理最多的请求。
Sentinel 是如何工作的
Sentinel 的主要工作机制如下:
- 对主流框架提供适配或者显示的 API,来定义需要保护的资源,并提供设施对资源进行实时统计和调用链路分析。
- 根据预设的规则,结合对资源的实时统计信息,对流量进行控制。同时,Sentinel 提供开放的接口,方便您定义及改变规则。
- Sentinel 提供实时的监控系统,方便您快速了解目前系统的状态。
Demo
cloudalibaba-sentinel-service8401
依赖
<dependencies>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
dependency>
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-datasource-nacosartifactId>
dependency>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-openfeignartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>cn.hutoolgroupId>
<artifactId>hutool-allartifactId>
<version>4.6.3version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
配置
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
#Nacos服务注册中心地址
server-addr: localhost:8848
sentinel:
transport:
#配置Sentinel dashboard地址
dashboard: localhost:8080
#默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
port: 8719
management:
endpoints:
web:
exposure:
include: '*'
主启动类
@EnableDiscoveryClient
@SpringBootApplication
public class MainApp8401
{
public static void main(String[] args) {
SpringApplication.run(MainApp8401.class, args);
}
}
控制层
@RestController
public class FlowLimitController{
@GetMapping("/testA")
public String testA(){
return "------testA";
}
@GetMapping("/testB")
public String testB(){
return "------testB";
}
}
流控规则
文档: https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
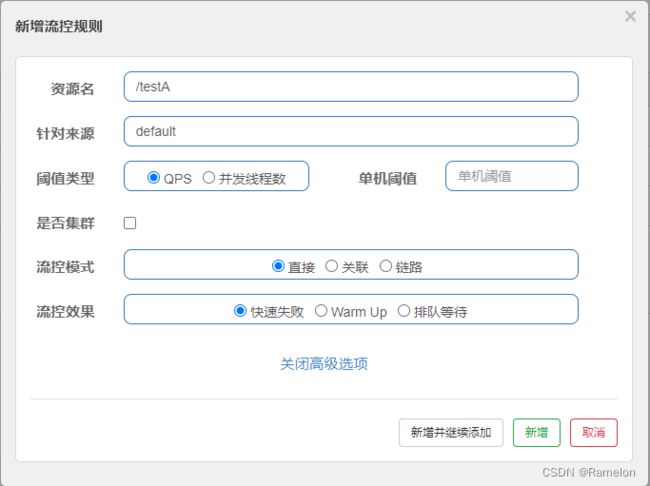
- 资源名:需要流控的资源路径
- 针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认为default(不区分来源)
- 阈值类型:
- QPS:Queries Per Second是衡量信息检索系统(例如搜索引擎或数据库)在一秒钟内接收到的搜索流量的一种常见度量
- 并发线程数:并发数是指系统同时能处理的请求数量
- 单机阈值:比如选中QPS,单机阈值为5。意思为一秒钟点击超过五次除法流控。
- 是否集群:是否为集群
- 流控模式:
- 直接:当api大达到限流条件时,直接限流(比如到达多少点击次数)
- 关联:当关联的资源到达阈值,就限流自己
- 链路:只记录指定路上的流量,指定资源从入口资源进来的流量,如果达到阈值,就进行限流,api级别的限流
- 流控效果:
-
快速失败:直接快速失败(默认的流控处理)
-
Warm Up:当流量突然增大的时候,我们常常会希望系统从空闲状态到繁忙状态的切换的时间长一些。即如果系统在此之前长期处于空闲的状态,我们希望处理请求的数量是缓步的增多,经过预期的时间以后,到达系统处理请求个数的最大值。Warm Up(冷启动,预热)模式就是为了实现这个目的的。
- https://github.com/alibaba/Sentinel/wiki/%E9%99%90%E6%B5%81—%E5%86%B7%E5%90%AF%E5%8A%A8
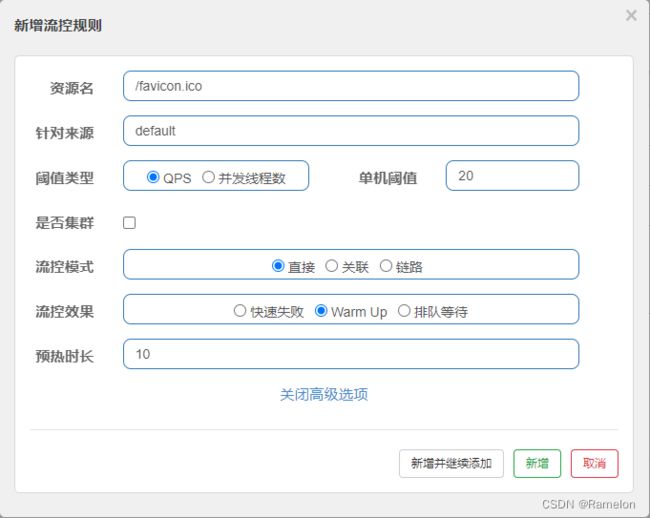
- https://github.com/alibaba/Sentinel/wiki/%E9%99%90%E6%B5%81—%E5%86%B7%E5%90%AF%E5%8A%A8
-
先在单机阈值20/3(coldFactor默认为3)=7的时候,预热10秒后,慢慢将阈值升至20。刚开始刷/favicon.ico,会出现默认错误,预热时间到了后,阈值增加,没超过阈值刷新,请求正常。
-
排队等待:匀速排队(
RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
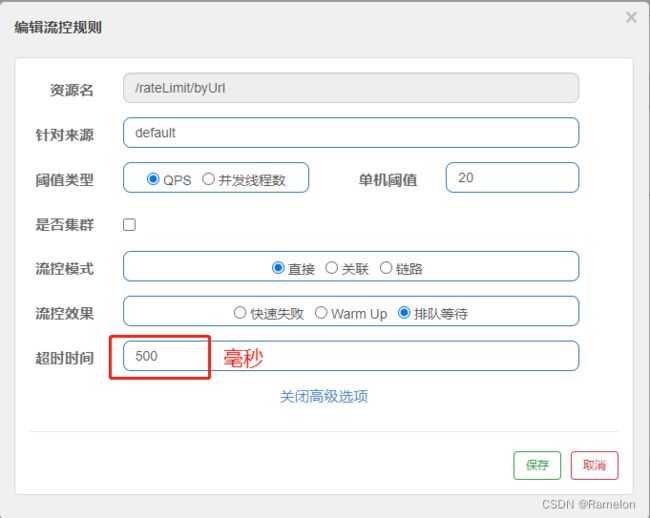
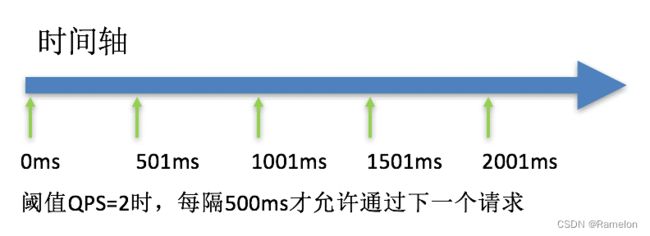
- 这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
- 注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
-
熔断降级
官方文档: https://github.com/alibaba/Sentinel/wiki/%E7%86%94%E6%96%AD%E9%99%8D%E7%BA%A7
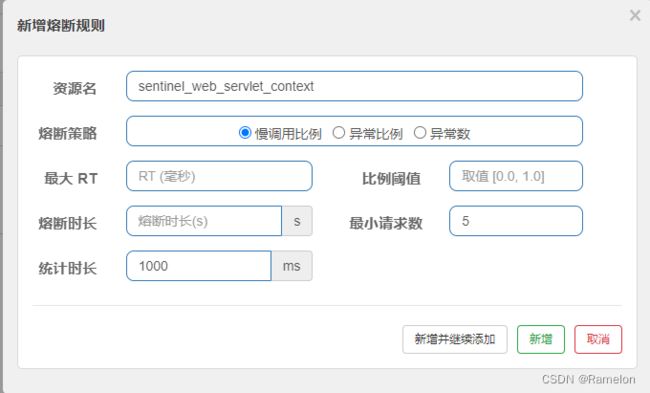
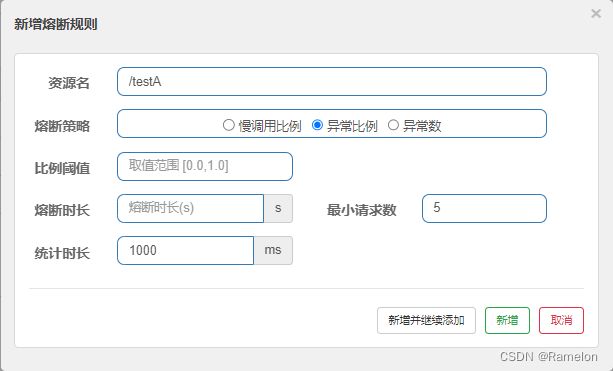
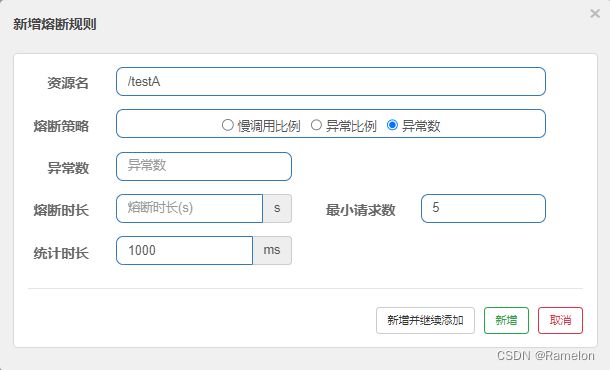
- 资源名:需要降级的资源路径
- 熔断策略:
- 慢调用比例(
SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。 - 异常比例(
ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是[0.0, 1.0],代表 0% - 100%。 - 异常数(
ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
- 慢调用比例(
- RT:最大响应时间
- 比例阈值: 慢调用次数 / 调用次数
- 熔断时长:需要经过熔断的时长
- 最小请求数:即单位时长允许的最小请求数目
- 统计时长:即单位时长
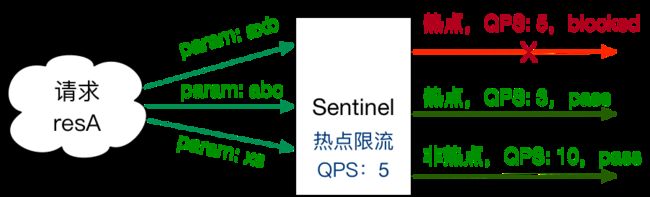
热点参数限流
官方文档: https://github.com/alibaba/Sentinel/wiki/%E7%83%AD%E7%82%B9%E5%8F%82%E6%95%B0%E9%99%90%E6%B5%81
演示图如下:
页面说明:
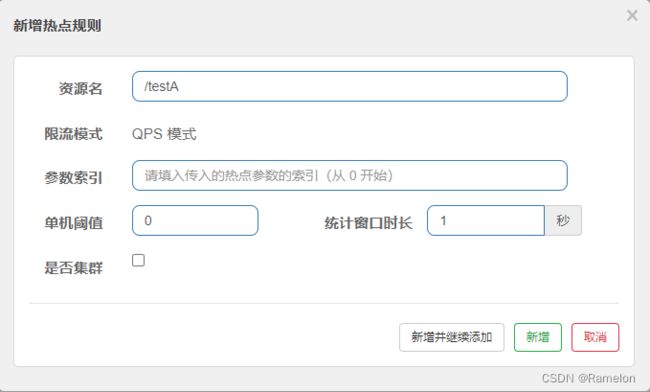
- 资源名:资源路径
- 限流模式:目前仅支持QPS,sentinel1.8.5
- 参数索引:热点参数的索引,必填,对应
SphU.entry(xxx, args)中的参数索引位置 - 单机阈值:单位时间点击多少次上限
- 统计窗口时长:顾名思义-单位时间
- 是否集群:是否为集群模式
系统规则
官方文档: https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。 - CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
原理

我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候,请求不需要排队,直接从水管中穿过,这个请求的RT(响应时间)是最短的;反之,当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间。
- 推论一: 如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。
我们用 T 来表示(水管内部的水量),用RT来表示请求的处理时间,用P来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 P * RT 个请求。换一句话来说,当 T ≈ QPS * Avg(RT) 的时候,我们可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
- 推论二: 当保持入口的流量是水管出来的流量的最大的值的时候,可以最大利用水管的处理能力。
然而,和 TCP BBR 的不一样的地方在于,还需要用一个系统负载的值(load1)来激发这套机制启动。
注:这种系统自适应算法对于低 load 的请求,它的效果是一个“兜底”的角色。对于不是应用本身造成的 load 高的情况(如其它进程导致的不稳定的情况),效果不明显。
@SentinelResource
官方文档: https://sentinelguard.io/zh-cn/docs/annotation-support.html
注意:注解方式埋点不支持 private 方法。
@SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项。 @SentinelResource 注解包含以下属性:
-
value:资源名称,必需项(不能为空) -
entryType:entry 类型,可选项(默认为EntryType.OUT) -
blockHandler/blockHandlerClass:blockHandler对应处理BlockException的函数名称,可选项。blockHandler 函数访问范围需要是public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为BlockException。blockHandler 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定blockHandlerClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。 -
fallback
:fallback 函数名称,可选项,用于在抛出异常的时候提供 fallback 处理逻辑。fallback 函数可以针对所有类型的异常(除了
exceptionsToIgnore里面排除掉的异常类型)进行处理。fallback 函数签名和位置要求:- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要和原函数一致,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。 - fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。
-
defaultFallback
(since 1.6.0):默认的 fallback 函数名称,可选项,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)。默认 fallback 函数可以针对所以类型的异常(除了
exceptionsToIgnore里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效。defaultFallback 函数签名要求:- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要为空,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。 - defaultFallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。
-
exceptionsToIgnore(since 1.6.0):用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出。
注:1.6.0 之前的版本 fallback 函数只针对降级异常(
DegradeException)进行处理,不能针对业务异常进行处理。
特别地,若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出 BlockException 时只会进入 blockHandler 处理逻辑。若未配置 blockHandler、fallback 和 defaultFallback,则被限流降级时会将 BlockException 直接抛出。
规则持久化
demo
修改cloudalibaba-sentinel-service8401
依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-datasource-nacosartifactId>
配置
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard地址
port: 8719
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
management:
endpoints:
web:
exposure:
include: '*'
feign:
sentinel:
enabled: true # 激活Sentinel对Feign的支持
nacos新建配置
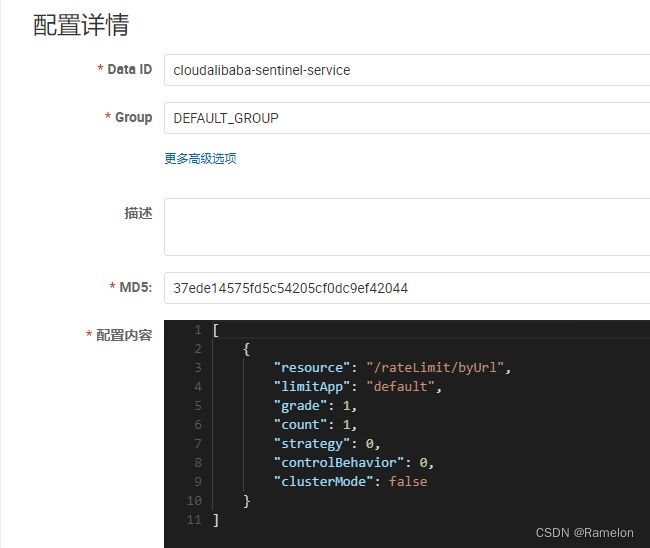
[
{
"resource": "/rateLimit/byUrl",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
测试:重启项目配置并未丢失!!!!
include: '*'
feign:
sentinel:
enabled: true # 激活Sentinel对Feign的支持
### nacos新建配置
[外链图片转存中...(img-tvq0Eosg-1681275410470)]
```python
[
{
"resource": "/rateLimit/byUrl",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
测试:重启项目配置并未丢失!!!!