结合 Swin-Transformer 的 LAVT: Language-Aware Vision Transformer for Referring Image Segmentation 论文笔记
结合 Swin-Transformer 的 LAVT: Language-Aware Vision Transformer for Referring Image Segmentation 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 参考图像分割
- 3.2 Transformer
- 四、方法
-
- 4.1 语言感知视觉编码
- 4.2 像素-词注意力模块 (PWAM)
- 4.3 语言路径
- 4.4 分割
- 4.5 实施细节
- 五、实验
-
- 5.1 数据集与评估指标
- 5.2 与其他方法的比较
- 5.3 消融实验
-
- 5.3.1 语言路径 LP
- 5.3.2 像素-单词注意力模块 PWAM
- 5.3.3 语言门中的激活函数
- 5.3.4 PWAM 中的归一化层
- 5.3.5 用于预测的特征
- 5.3.6 多模态注意力模块
- 5.4 预测可视化
- 5.5 同相关方法的公平比较
- 六、结论
- 七、附录
-
- A 语言模型中潜在的偏见
- B 语言路径
- C 准确率-召回率分析
- D MIoU
- E 可视化
写在前面
这篇文章同样是参考图像分割,区别于上一篇: 无卷积结构(那就纯ransformer)的参考图像分割:ReSTR: Convolution-free Referring Image Segmentation Using Transformers,这篇结合了当下最主流的 Swim-Transformer 网络,性能着实强悍,且新颖度很高,是篇好论文。
- 论文地址:LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
- 代码地址:GitHub
- 收录于:CVPR 2022
一、Abstract
摘要不同寻常,上来夸下同行们用 “cross-modal” 解码器 / Transformer 架构做的好,吹了一半的摘要都是这个。接下来一半提出自己的方法,在视觉编码器中间层进行“提前融合”效果会好很多,RefCOCO、RefCOCO+、G-Ref 数据集上超越了目前的主流方法一大截。
二、引言
照例,第一段给出参考图像分割的定义、应用以及挑战。
第二段对目前已有方法的介绍:采用不同的编码器提取视觉和语言特征,送入跨模态解码器。
第三段强调之前的方法未能在编码器中利用多模态上下文特征,因此一个可能的解决办法是在视觉编码阶段同时进行视觉和语言 embedding。
第四段描述本文提出的方法,语言感知的视觉 Transformer 网络 (LAVT):
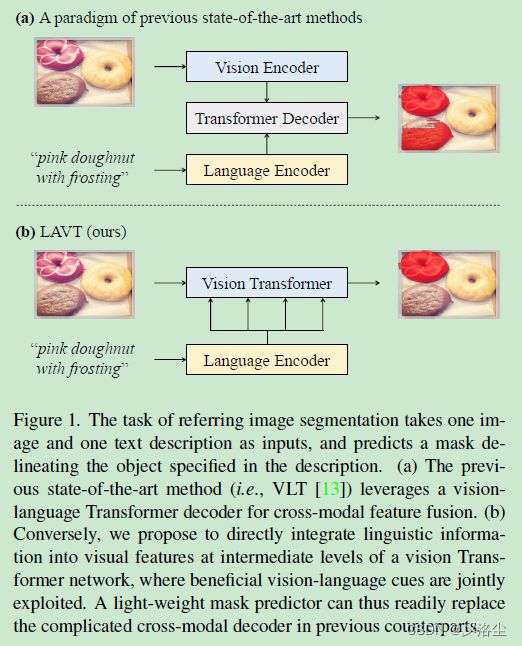
通过逐词注意力机制将语言特征整合到视觉特征中,去掉了跨模态解码器,取而代之的是一个轻量化的 mask 预测器。
第四段讲本文的实验在 RefCOCO、RefCOCO+、G-Ref、G-Ref 数据集上性能很强。
最后本文贡献:提出 LAVT,去掉了跨模态融合;在三个数据集上性能很牛皮。
三、相关工作
3.1 参考图像分割
一般的做法:从文本和图像上分别提取特征,融合多模态特征来预测分割的 mask。接下来对之前的多模态融合方法进行介绍。
与本文最相关的方法是 VLT 和 EFN:
【VLT】Henghui Ding, Chang Liu, SuchenWang, and Xudong Jiang. Vision-language transformer and query generation for referring segmentation. In ICCV, 2021. 1, 2, 6, 8
【EFN】 Guang Feng, Zhiwei Hu, Lihe Zhang, and Huchuan Lu. Encoder fusion network with co-attention embedding for referring image segmentation. In CVPR, 2021. 2, 4, 6, 8
其中 VLT 采用 Transformer decoder 融合视觉-语言特征,EFN 采用卷积网络编码语言信息。本文提出的方法不同于这两者,在 Transformer encoder 中对特征进行提前融合。
3.2 Transformer
老生常谈的,略过。最后补刀:很少有尝试设计统一的 Transformer 模型建模推理图像分割。
四、方法

4.1 语言感知视觉编码
采用视觉表示模型 (BERT) 从表达式中提取 embedding 向量 L ∈ R C t × T L\in\mathbb {R}^{{C}_{t}\times T} L∈RCt×T, C t {C}_{t} Ct 和 T T T 分别是通道数和最大词数。
另外一边,根据 Swin Transformer 的四个阶段,本文也设计了这样四个阶段,不同的是采用 pixel-word attention module (PWAM) 模块进行多模态融合,其中主要部分:语言门 Language gate (LG),用于管理语言在语言路径 Language pathway (LP) 上的信息流动。
4.2 像素-词注意力模块 (PWAM)

重点来了:给定视觉特征 V i ∈ R C i × H i × W i V_{i}\in{\mathbb{R}^{C_{i}\times{H}_{i}\times{W}_{i}}} Vi∈RCi×Hi×Wi 和语言特征 L ∈ R C t × T L\in\mathbb {R}^{{C}_{t}\times T} L∈RCt×T,根据上图有:
V i q = flatten ( ω i q ( V i ) ) , L i k = ω i k ( L ) , L i v = ω i v ( L ) , G i ′ = softmax ( V i q T L i k C i ) L i v T , G i = ω i w ( unflatten ( G i ′ T ) ) , \begin{aligned} V_{i q} &=\text { flatten }\left(\omega_{i q}\left(V_{i}\right)\right), \\ L_{i k} &=\omega_{i k}(L), \\ L_{i v} &=\omega_{i v}(L), \\ G_{i}^{\prime} &=\operatorname{softmax}\left(\frac{V_{i q}^{T} L_{i k}}{\sqrt{C_{i}}}\right) L_{i v}^{T}, \\ G_{i} &=\omega_{i w}\left(\operatorname{unflatten}\left(G_{i}^{\prime T}\right)\right), \end{aligned} ViqLikLivGi′Gi= flatten (ωiq(Vi)),=ωik(L),=ωiv(L),=softmax(CiViqTLik)LivT,=ωiw(unflatten(Gi′T)),其中 ω i q \omega_{i q} ωiq、 ω i k \omega_{i k} ωik、 ω i v \omega_{i v} ωiv、 ω i w \omega_{i w} ωiw 都是可学习的 1 × 1 1\times 1 1×1 卷积权重。之后联合语言特征 G i G_{i} Gi 和视觉特征 V i V_{i} Vi,通过逐元素乘积得到多模态特征图:
V i m = ω i m ( V i ) F i = ω i o ( V i m ⊙ G i ) \begin{aligned} V_{i m} &=\omega_{i m}\left(V_{i}\right) \\ F_{i} &=\omega_{i o}\left(V_{i m} \odot G_{i}\right) \end{aligned} VimFi=ωim(Vi)=ωio(Vim⊙Gi)注意每次的 1 × 1 1\times 1 1×1 卷积后面都会跟着 R e L U ReLU ReLU 激活函数。
4.3 语言路径
为防止 F i F_i Fi 占据太大比重,淹没视觉信息 V i V_i Vi,设计语言门 LG 来学习逐元素权重图,从而对 F i F_i Fi 放缩。
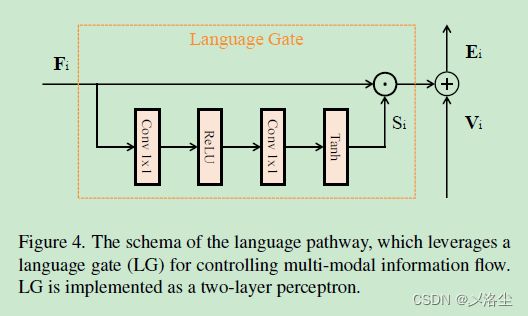
用公式表示为:
S i = γ i ( F i ) E i = S i ⊙ F i + V i \begin{array}{l} S_{i}=\gamma_{i}\left(F_{i}\right) \\ E_{i}=S_{i} \odot F_{i}+V_{i} \end{array} Si=γi(Fi)Ei=Si⊙Fi+Vi其中 ⊙ \odot ⊙ 表示逐元素乘积, γ i \gamma_{i} γi 为双层感知机: 1 × 1 1\times 1 1×1 卷积 + R e L U ReLU ReLU + 1 × 1 1\times 1 1×1 卷积 + T a n h Tanh Tanh。
4.4 分割
联合多尺度特征图 F i , i ∈ { 1 , 2 , 3 , 4 } F_i,i\in \left\{1,2,3,4\right\} Fi,i∈{1,2,3,4},以自上而下的方式进行解码:
{ Y 4 = F 4 Y i = ρ i ( [ v ( Y i + 1 ) ; F i ] ) , i = 3 , 2 , 1. \left\{\begin{aligned} Y_{4} &=F_{4} \\ Y_{i} &=\rho_{i}\left(\left[v\left(Y_{i+1}\right) ; F_{i}\right]\right), \quad i=3,2,1 . \end{aligned}\right. {Y4Yi=F4=ρi([v(Yi+1);Fi]),i=3,2,1.其中 [ ; ] \left [ ; \right] [;] 表示特征通道上的拼接操作, v v v 表示双线性上采样插值, ρ \rho ρ 表示两层的 3 × 3 3\times 3 3×3 卷积 + Batch Norm + R e L U ReLU ReLU,最终的 Y 1 Y_1 Y1 通过 1 个 1 × 1 1\times 1 1×1 卷积投影到两个分类得分图中。
4.5 实施细节
Transformer 层初始化权重来自于 Swin Transformer,预训练在 ImageNet-22K 上,维度 512,语言编码器为 BERT,12层,维度 768, Cross-entropy 损失,AdamW 优化器,权重衰减 0.01,初始学习率 0.0000 5,40 个 epoch,batch 32,图像尺寸 480 × 480 480\times 480 480×480,无图像增强策略。
五、实验
5.1 数据集与评估指标
数据集:RefCOCO、RefCOCO+、G-Ref。
评估指标:整体 IoU:oIoU;平均 IoU:0.5,0.7,0.9
5.2 与其他方法的比较

5.3 消融实验
5.3.1 语言路径 LP

5.3.2 像素-单词注意力模块 PWAM
同上图。
5.3.3 语言门中的激活函数

5.3.4 PWAM 中的归一化层
上图 3(b)。
5.3.5 用于预测的特征
上图 3(c)。
5.3.6 多模态注意力模块
上图 3(d)。
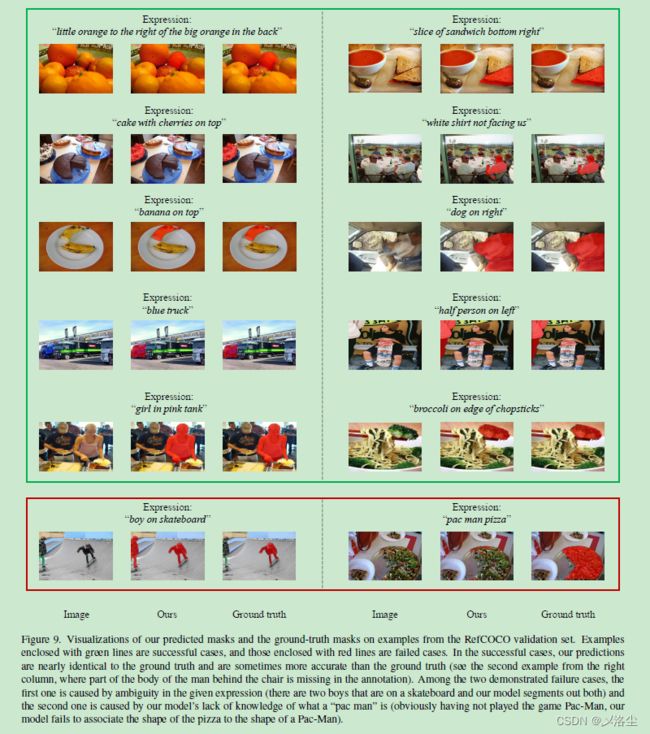
5.4 预测可视化

5.5 同相关方法的公平比较

六、结论
提出了 LAVT,实验效果牛批。
七、附录
A 语言模型中潜在的偏见
源于 BERT。
B 语言路径
作者也尝试了其他方法:
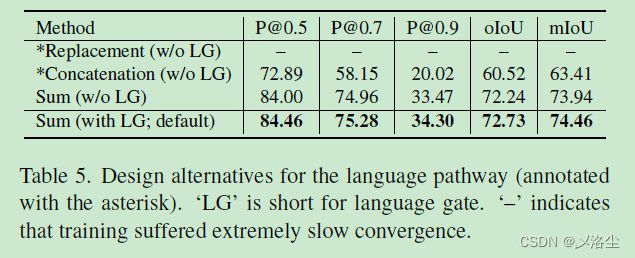
C 准确率-召回率分析
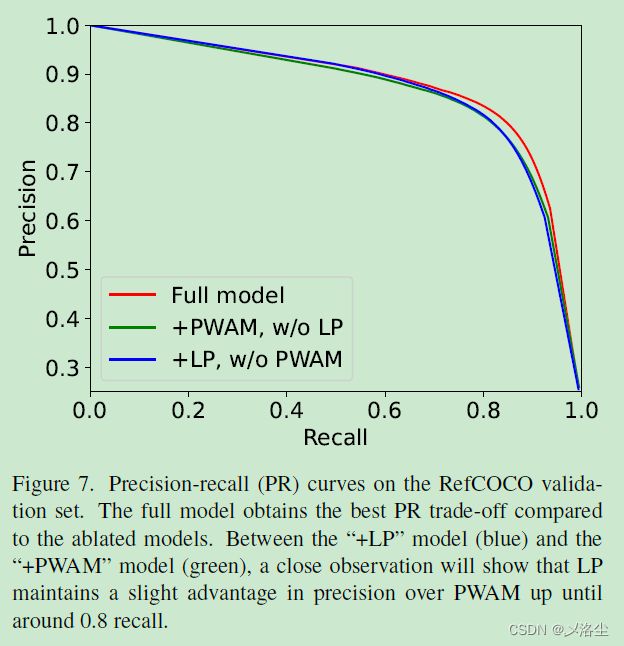
D MIoU

E 可视化
写在后面
这几篇论文都是快速的过了~~
随着大量论文的阅读,咱们浏览/精读论文的速度应该只会越来越快,好好加油