hadoop分布式安装
文章目录
-
- 1. 将安装包hadoop-3.1.3.tar.gz上次至linux中
- 2. 进行解压操作
- 3. 修改目录名称
- 4. 配置环境变量
- 5. 远程传输
-
- 5.1 scp远程传输
- 6. 免密登录
- 7. 集群规划
- 8. 修改自定义配置文件
-
- 8.1 hadoop-env.sh
- 8.2 core-site.xml
- 8.3 hdfs-site.xml
- 8.4 mapred-site.xml
- 8.5 yarn-site.xml
- 8.6 workers
- 9. rsync差异化远程传输
- 10. 格式化集群
- 11.在NameNode节点上(此处为bigdata03)启动hdfs
- 12.在ResourceManager节点上(此处为bigdata05)启动yarn
- 13.在NameNode节点上关闭hdfs
- 14.在ResourceManager节点上(此处为bigdata05)关闭yarn
- 15.通过web访问hdfs和yarn
1. 将安装包hadoop-3.1.3.tar.gz上次至linux中
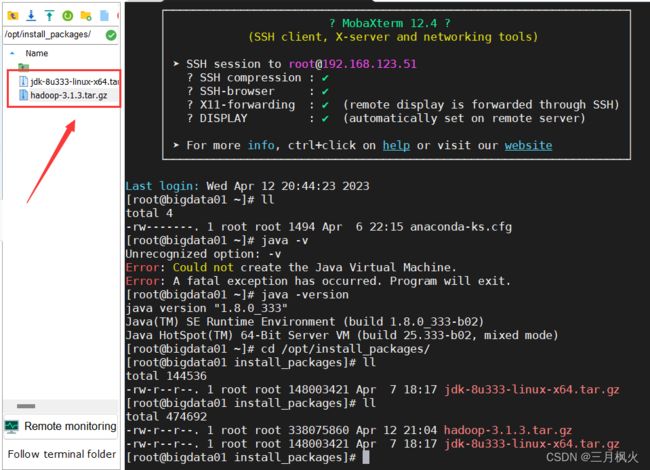
2. 进行解压操作
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/softs/
##tar: 解压打包的命令
##z: 当前压缩类型为.tar. gz
##x: 代表是解压命令
##v: 代表在解压过程中显示执行过程
##f: 代表指定打包后的文件名
##C: 指定解压后的目录
3. 修改目录名称
--替换目录
cd /opt/softs
--修改目录名称
mv hadoop-3.1.3/ hadoop3.1.3/
4. 配置环境变量
-- 编辑环境变量配置文件
vim /etc/profile
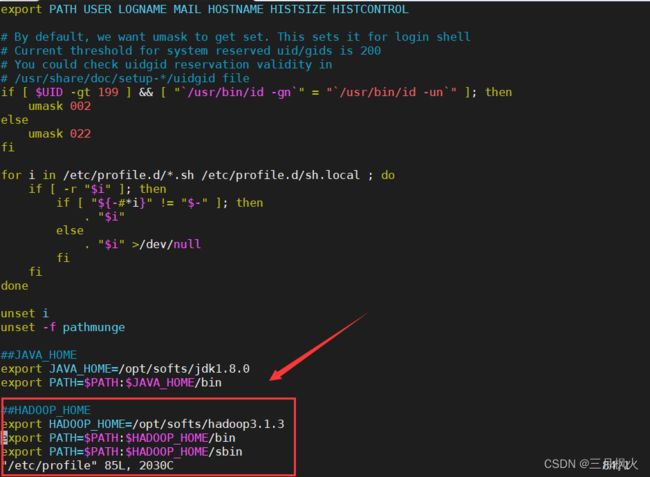
-- 在文件添加如下配置项
##JAVA_HOME
export JAVA_HOME=/opt/softs/jdk1.8.0
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/softs/hadoop3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
-- 保存退出后需要使环境变量配置文件的改动生效
source /etc/profile
输出hadoop环境变量 :
echo $HADOOP_HOME

修改linux本地hosts,使能通过主机名映射识别对应的ip地址
vim /etc/hosts
192.168.123.51 bigdata01
192.168.123.52 bigdata02
192.168.123.53 bigdata03
192.168.123.54 bigdata04
192.168.123.55 bigdata05
192.168.123.50 bigdatademo
5. 远程传输
5.1 scp远程传输
-- 远程传输/etc/hosts文件
-- scp 需要传输的文件路径目标节点 用户名@ip地址(hostname):文件的目标位置
scp /etc/hosts root@192.168.123.52:/etc
scp /etc/hosts root@192.168.123.53:/etc
scp /etc/hosts root@192.168.123.54:/etc
scp /etc/hosts root@192.168.123.55:/etc
-- 远程传输/etc/profile文件
-- 注意点:远程传输/etc/proflie后需要在目标节点上重新source /etc/profi1e
scp /etc/profile root@bigdata02:/etc
scp /etc/profile root@bigdata03:/etc
scp /etc/profile root@bigdata04:/etc
scp /etc/profile root@bigdata05:/etc
-- 远程传输/opt/softs/hadoop3.1.3目录
scp -r /opt/softs/hadoop3.1.3 root@bigdata02:/opt/softs
scp -r /opt/softs/hadoop3.1.3 root@bigdata03:/opt/softs
scp -r /opt/softs/hadoop3.1.3 root@bigdata04:/opt/softs
scp -r /opt/softs/hadoop3.1.3 root@bigdata05:/opt/softs
-r 递归
6. 免密登录
-- 切换到/root目录
cd /root
-- 查看隐藏目录
1s -al
#a 显示所有的文件(包含隐藏文件)
#l 详细信息显示
-- 切换目录
cd .ssh
--执行创建公钥和私钥的命令
ssh-keygen -t rsa
然后可以回车3次生成两个文件: id_rsa(私钥),id_rsa.pub(公钥)
--将公钥拷贝到要免密登录的节点上
ssh-copy-id bigdata03
ssh-copy-id bigdata04
ssh-copy-id bigdata05
-- 在bigdata04和bigdata05上也进行同样的免密登录操作
-- ssh登录测试
ssh root@bigdata03
ssh root@bigdata04
ssh root@bigdata05
7. 集群规划
集群规划时需要注意
(1)NameNode和SecondaryNameNode不要放置在同一节点上
(2)ResourceManager本身很消耗内存,不要和NameNode或SecondaryNameNode放置在同一节点上
| bigdata03 | bigdata04 | bigdata05 | |
|---|---|---|---|
| HDFS | NameNode,DataNode | SecondaryNameNode,DataNode | DataNode |
| YARN | NodeManager | NodeManager | ResourceManager,NodeManager |
8. 修改自定义配置文件
自定义文件的路径: $HADOOP_HOME/etc/hadoop
8.1 hadoop-env.sh
配置如下
cd /opt/softs/hadoop3.1.3/etc/hadoop
ll
vim hadoop-env.sh
-- 修改JAVA_HOME的配置
export JAVA_HOME=/opt/softs/jdk1.8.0
8.2 core-site.xml
配置如下
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://bigdata03:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/softs/hadoop3.1.3/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>rootvalue>
property>
configuration>
8.3 hdfs-site.xml
配置如下
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/opt/softs/hadoop3.1.3/data/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/opt/softs/hadoop3.1.3/data/dfs/datavalue>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>bigdata03:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>bigdata04:9868value>
property>
configuration>
8.4 mapred-site.xml
配置如下
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
8.5 yarn-site.xml
配置如下
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>bigdata05value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://bigdata03:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
8.6 workers
配置作为datanode节点的hostname
bigdata03
bigdata04
bigdata05
9. rsync差异化远程传输
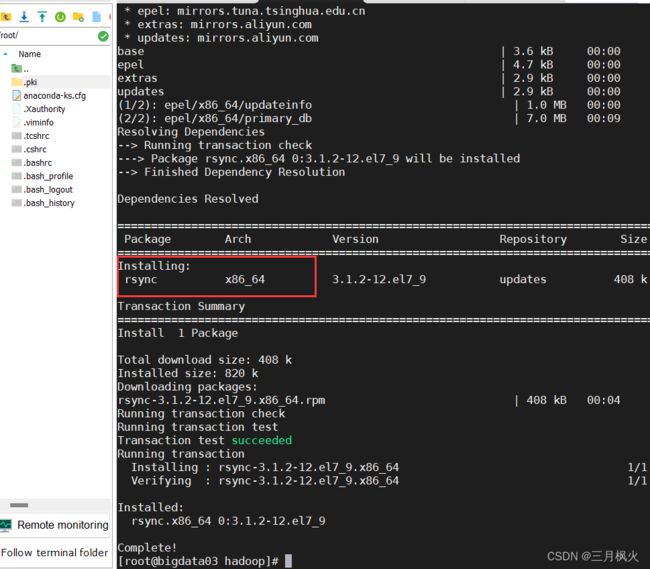
-- 安装rsync命令
yum install -y rsync
-- 上述安装命令在集群中每一节点上都执行
-- 进行差异化传输
-- rsync -av 差异化比较的源路径 目标节点用户名@hostname:差异化比较的目标路径
-- a 归档拷贝
-- v 显示复制过程
rsync -av /opt/softs/hadoop3.1.3/etc/hadoop/ root@bigdata04:/opt/softs/hadoop3.1.3/etc/hadoop/
注意:如果传输是个文件夹目录的话,文件夹名后面的/不能省略,即hadoop后的/不能省略。
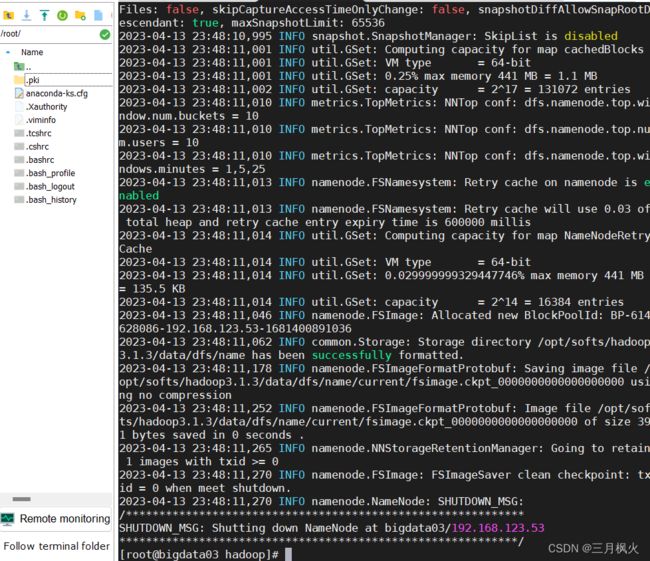
10. 格式化集群
如果集群是第一次启动,需要在NameNode节点处进行格式化,格式化后,会产生新的集群id
如果对集群进行重新格式化时,需要先停止NameNode和DataNode的运行,并且需要删除所有节点上data和logs目录。然后再进行重新格式化
--格式化命令
hdfs namenode -format
11.在NameNode节点上(此处为bigdata03)启动hdfs
| bigdata03 | bigdata04 | bigdata05 | |
|---|---|---|---|
| HDFS | NameNode,DataNode | SecondaryNameNode,DataNode | DataNode |
| YARN | NodeManager | NodeManager | ResourceManager,NodeManager |
--启动hdfs命令
start-dfs.sh
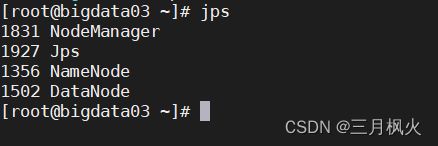
在对应的节点上查看服务启动情况,根据集群规划中服务设置节点进行检查
jps



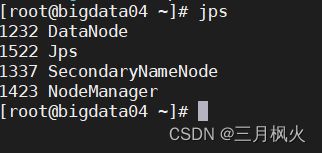
有DataNode、NameNode、SecondaryNameNode进程服务时,说明hdfs启动成功
12.在ResourceManager节点上(此处为bigdata05)启动yarn
-- 启动yarn命令
start-yarn.sh
在对应的节点上查看服务启动情况,根据集群规划中服务设置节点进行检查
jps

13.在NameNode节点上关闭hdfs
stop-dfs.sh
14.在ResourceManager节点上(此处为bigdata05)关闭yarn
stop-yarn.sh
15.通过web访问hdfs和yarn
首先需要在windows下配置虚拟机ip和hostname的映射
编辑文件 C:WindowsiSystem32%driversletchosts ,添加如下内容
192.168.123.53 bigdata03
192.168.123.54 bigdata04
192.168.123.55 bigdata05
访问hdfs
在浏览器中输入 http://bigdata03:9870
访问yarn
在浏览器中输入 http://bigdata05:8088