一图看懂 CSV 模块:csv文件的处理, 资料整理+笔记(大全)
本文由 大侠(AhcaoZhu)原创,转载请声明。
链接: https://blog.csdn.net/Ahcao2008

一图看懂 CSV 模块:csv文件的处理, 资料整理+笔记(大全)
- 摘要
- 模块图
- 类关系图
- 模块全展开
-
- 【csv】
- 统计
- 常量
-
- int
- 模块
- 类
-
- 6 _csv.Error
- 7 _csv.Dialect
-
- data
- 8 collections.OrderedDict
-
- method
- 1 clear(self)
- 2 copy(self)
- 3 items(self)
- 4 keys(self)
- 5 move_to_end(self, key, last=True)
- 6 pop(self, key, default=__marker)
- 7 popitem(self, last=True)
- 8 setdefault(self, key, default=None)
- 9 update(*args, **kwds)
- 10 values(self)
- class method
- 11 fromkeys(cls, iterable, value=None)
- 9 _io.StringIO
- 10 csv.Dialect
-
- data
- 11 csv.excel
-
- data
- 12 csv.excel_tab
-
- data
- 13 csv.unix_dialect
-
- data
- 14 csv.DictReader
-
- property
- 15 csv.DictWriter
-
- method
- 1 writeheader(self)
- 2 writerow(self, rowdict)
- 3 writerows(self, rowdicts)
- 16 csv.Sniffer
-
- method
- 1 has_header(self, sample)
- 2 sniff(self, sample, delimiters=None)
- 内嵌函数或方法
- 私有或局部
- 【re】
摘要
全文介绍系统内置 csv 模块、函数、类及类的方法和属性。
它通过代码抓取并经AI智能翻译和人工校对。
是一部不可多得的权威字典类工具书。它是系列集的一部分。后续陆续发布、敬请关注。【原创:AhcaoZhu大侠】
模块图
无
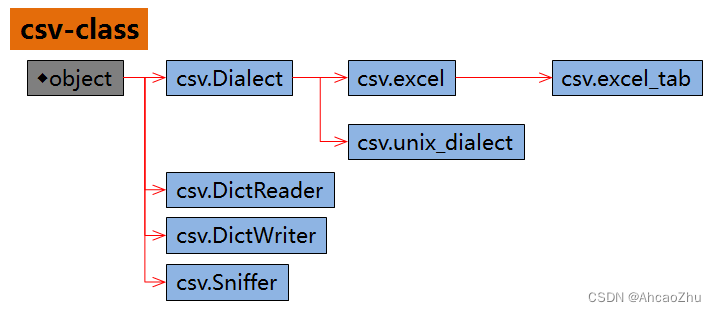
类关系图
模块全展开
【csv】
csv, fullname=csv, file=csv.py
CSV解析和写入。
这个模块提供了帮助读取和写入逗号分隔值(CSV)文件的类,并实现了PEP 305描述的接口。
尽管许多CSV文件解析起来很简单,但是格式并不是由一个稳定的规范正式定义的,而且这种格式非常微妙,
以至于用 line.split(",") 之类的东西解析CSV文件的行注定会失败。
该模块支持三个基本api:方言的读取、写入和注册。
DIALECT注册:
读取器和写入器都支持DIALECT参数,这是一组设置的方便处理方法。
当dialect参数为字符串时,它标识先前在模块中注册的一种方言。
如果它是一个类或实例,则实参的属性用作读取器或写入器的设置:
class excel:
delimiter = ','
quotechar = '"'
escapechar = None
doublequote = True
skipinitialspace = False
lineterminator = '\r\n'
quoting = QUOTE_MINIMAL
设置:
* quotechar - 指定一个字符串作为引用字符。默认为 '"'.
* delimiter - 指定一个字符串作为字段分隔符。默认为 ','.
* skipinitialspace - 指定如何解释紧接在分隔符后面的空格。它默认为False,这意味着紧跟着分隔符的空格是下面字段的一部分。
* lineterminator - 指定终止行的字符序列。
* quoting - 控制何时应该由写入器生成引号。它可以取以下模块常量中的任何一个:
csv.QUOTE_MINIMAL 表示仅当需要时,例如当字段包含引号字符或分隔符时。
csv.QUOTE_ALL 意味着引号总是放在字段周围。
csv.QUOTE_NONNUMERIC 意味着引号总是放在不能解析为整数或浮点数的字段周围。
csv.QUOTE_NONE 意味着引号永远不会放在字段周围。
* escapechar - 指定一个字符串,用于在引号设置为QUOTE_NONE时转义分隔符。
* doublequote - 控制字段内引号的处理。当为True时,两个连续的引号在读取时被解释为一个,而在写入时,嵌入在数据中的每个引号字符被写入为两个引号
统计
| 序号 | 类别 | 数量 |
|---|---|---|
| 1 | int | 4 |
| 4 | str | 6 |
| 6 | list | 1 |
| 8 | dict | 1 |
| 9 | module | 1 |
| 10 | class | 11 |
| 12 | builtin_function_or_method | 7 |
| 13 | residual | 2 |
| 14 | system | 10 |
| 15 | private | 1 |
| 16 | all | 33 |
常量
int
1 QUOTE_MINIMAL 0
2 QUOTE_ALL 1
3 QUOTE_NONNUMERIC 2
4 QUOTE_NONE 3
模块
5
re
re, fullname=re, file=re.py
类
6 _csv.Error
Error, _csv.Error, module=_csv, line:0 at
7 _csv.Dialect
Dialect, _csv.Dialect, module=_csv, line:0 at
CSV方言
方言类型记录了CSV解析和生成选项。
CSV dialect
data
1 delimiter=
kind:data type:getset_descriptor class:
2 doublequote=kind:data type:member_descriptor class:
3 escapechar=kind:data type:getset_descriptor class:
4 lineterminator=kind:data type:getset_descriptor class:
5 quotechar=kind:data type:getset_descriptor class:
6 quoting=kind:data type:getset_descriptor class:
7 skipinitialspace=kind:data type:member_descriptor class:
8 strict=kind:data type:member_descriptor class:
8 collections.OrderedDict
OrderedDict, collections.OrderedDict, module=collections, line:81 at collections_init_.py
记忆插入顺序的字典
method
1 clear(self)
kind=method class=OrderedDict objtype=method_descriptor line:160 at …\lib\collections_init_.py
od.clear() -> None 从od中移除所有项目。
2 copy(self)
kind=method class=OrderedDict objtype=method_descriptor line:280 at …\lib\collections_init_.py
od.copy() -> od.copy的浅拷贝
3 items(self)
kind=method class=OrderedDict objtype=method_descriptor line:230 at …\lib\collections_init_.py
4 keys(self)
kind=method class=OrderedDict objtype=method_descriptor line:226 at …\lib\collections_init_.py
5 move_to_end(self, key, last=True)
kind=method class=OrderedDict objtype=method_descriptor line:190 at …\lib\collections_init_.py
将现有元素移到末尾(如果last为false则移到开头)。
如果元素不存在则引发KeyError。
6 pop(self, key, default=__marker)
kind=method class=OrderedDict objtype=method_descriptor line:242 at …\lib\collections_init_.py
od.pop(k[,d]) -> v,删除指定键并返回相应值。如果没有找到key,则返回d,否则引发KeyError。
7 popitem(self, last=True)
kind=method class=OrderedDict objtype=method_descriptor line:167 at …\lib\collections_init_.py
从字典中删除并返回一个(键,值)对。如果last为真,则按后进先出顺序返回,如果为假,则按先进先出顺序返回。
8 setdefault(self, key, default=None)
kind=method class=OrderedDict objtype=method_descriptor line:256 at …\lib\collections_init_.py
如果key不在字典中,则插入值为default的key。如果key在字典中,则返回key的值,否则为default。
9 update(*args, **kwds)
kind=method class=OrderedDict objtype=method_descriptor line:619 at …\lib\collections_init_.py
10 values(self)
kind=method class=OrderedDict objtype=method_descriptor line:234 at …\lib\collections_init_.py
class method
11 fromkeys(cls, iterable, value=None)
kind=class method class=OrderedDict objtype=classmethod_descriptor line:285 at …\lib\collections_init_.py
创建一个新的有序字典,键来自iterable,值设置为value。
9 _io.StringIO
StringIO, _io.StringIO, module=_io, line:0 at
10 csv.Dialect
Dialect, csv.Dialect, module=csv, line:0 at
描述CSV方言。
这必须被子类化(参见csv.excel)。
有效的属性是:
delimiter, quotechar, escapechar, doublequote, skipinitialspace,
lineterminator, quoting.
data
1 delimiter=None kind:data type:NoneType class:
2 doublequote=None kind:data type:NoneType class:
3 escapechar=None kind:data type:NoneType class:
4 lineterminator=None kind:data type:NoneType class:
5 quotechar=None kind:data type:NoneType class:
6 quoting=None kind:data type:NoneType class:
7 skipinitialspace=None kind:data type:NoneType class:
11 csv.excel
excel, csv.excel, module=csv, line:0 at
描述excel生成CSV文件的常用属性。
data
1 delimiter=, kind:data type:str class:
2 doublequote=True kind:data type:bool class:
3 lineterminator=
kind:data type:str class:
4 quotechar=" kind:data type:str class:
5 quoting=0 kind:data type:int class:
6 skipinitialspace=False kind:data type:bool class:
12 csv.excel_tab
excel_tab, csv.excel_tab, module=csv, line:0 at
描述excel生成的以tab分隔的文件的常见属性。
data
1 delimiter= kind:data type:str class:
13 csv.unix_dialect
unix_dialect, csv.unix_dialect, module=csv, line:0 at
描述unix生成的CSV文件的通常属性。
data
1 delimiter=, kind:data type:str class:
2 doublequote=True kind:data type:bool class:
3 lineterminator=
kind:data type:str class:
4 quotechar=" kind:data type:str class:
5 quoting=1 kind:data type:int class:
6 skipinitialspace=False kind:data type:bool class:
14 csv.DictReader
DictReader, csv.DictReader, module=csv, line:0 at
property
1 fieldnames=
kind:property type:property class:
15 csv.DictWriter
DictWriter, csv.DictWriter, module=csv, line:0 at
method
1 writeheader(self)
kind=method class=DictWriter objtype=function line:142 at …\csv.py
2 writerow(self, rowdict)
kind=method class=DictWriter objtype=function line:154 at …\csv.py
3 writerows(self, rowdicts)
kind=method class=DictWriter objtype=function line:157 at …\csv.py
16 csv.Sniffer
Sniffer, csv.Sniffer, module=csv, line:0 at
“嗅探”CSV文件的格式(即delimiter, quotechar)返回一个Dialect对象。
method
1 has_header(self, sample)
kind=method class=Sniffer objtype=function line:384 at …\csv.py
2 sniff(self, sample, delimiters=None)
kind=method class=Sniffer objtype=function line:176 at …\csv.py
返回与示例对应的方言(或None)
内嵌函数或方法
17 writer
18 reader
19 register_dialect
20 unregister_dialect
21 get_dialect
22 list_dialects
23 field_size_limit
私有或局部
24 _Dialect
【re】
re, fullname=re, file=re.py