SpringCloud之组件Hystrix简介
服务雪崩介绍
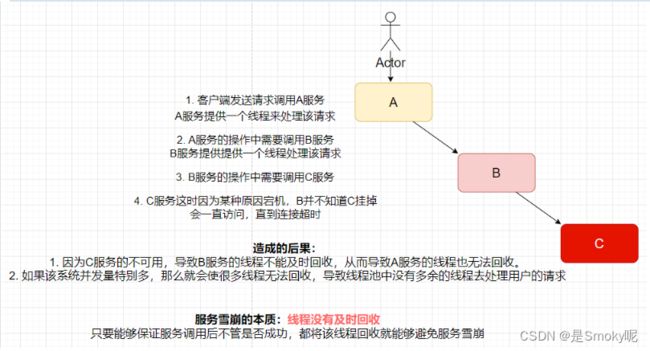
服务提供者不可用导致服务调用者也跟着不可用,以此类推引起整个链路中的所有微服务都不可用,
服务提供者A因为某种原因出现故障,那么服务调用者服务B依赖于服务A的请求便无法成功调用其提供的接口,假以时日依赖于服务A的请求越来越多导致服务B的Tomcat资源耗尽,造成服务B线程阻塞,导致服务B也出现故障。那么假如服务C依赖于服务B由于服务B也出现了故障导致服务C出现故障。以此类推引起整个链路中的所有微服务都不可用。
① 理解:
② 解决
将超时时间缩短(不可取)
优点:
简单
缺点:
有的服务超时时间都是提前预定好的
在一些服务中可以会大量的代码或者连接DB等,这时连接时间如果如果不够代码的执行时间,那么一个正常的业务也无法执行完
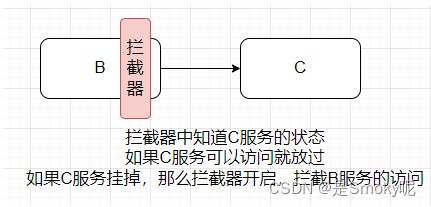
设置拦截器
概述
在微服务中可以解决
服务雪崩,称为熔断器或者断路器。能够防止分布式项目中出现联动故障(一个服务宕机,其他服务也无法正常运行)。Hystrix中设置了类似
拦截器的方案,如果需要调用的服务发生了宕机,那么就不调用这台机器,直接使用备选方案。
使用
① rent-car-service
配置文件
server: port: 8080 spring: application: name: rent-car-service eureka: client: service-url: defaultZone: http://localhost:8761/eureka instance: hostname: localhost instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} lease-renewal-interval-in-seconds: 5API:
@RestController public class CarController { @GetMapping("rent") public String rent(){ return "租车成功"; } }② conusmer-service
hystrix依赖
org.springframework.cloud spring-cloud-starter-netflix-hystrix 配置文件
server: port: 8081 spring: application: name: consumer-service eureka: client: service-url: defaultZone: http://localhost:8761/eureka instance: hostname: localhost instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} lease-renewal-interval-in-seconds: 5OpenFeign接口
@FeignClient(value = "rent-car-service",fallback = ConsumerRentCarFeignHystrix.class) // 指定发生服务雪崩时执行哪个类 public interface ConsumerRentCarFeign { @GetMapping("rent") String rent(); }Hystrix实现类
@Component // 添加到IOC容器中 public class ConsumerRentCarFeignHystrix implements ConsumerRentCarFeign { /** * 备用方案 * 当调用的服务挂掉后执行本方法 * @return */ @Override public String rent() { return "网络异常 稍后重试"; } }API
@RestController public class ConsumerController { @Autowired private ConsumerRentCarFeign consumerRentCarFeign; @GetMapping("consumerToRent") public String consumerToRent(){ System.out.println("有人来租车"); return consumerRentCarFeign.rent(); } }开启Hystrix
feign: hystrix: enabled: true
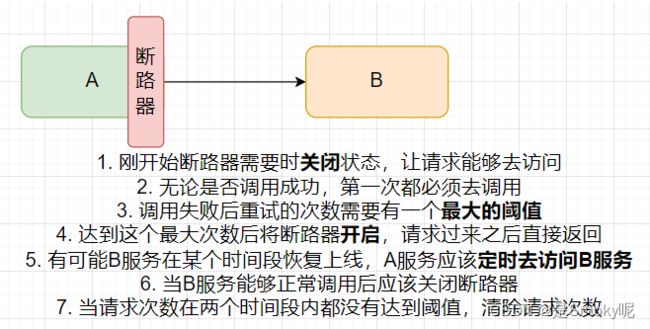
断路器思想
常用配置
hystrix: #hystrix 的全局控制
command:
default: #default 是全局控制,也可以换成单个方法控制,把 default 换成方法名即可
fallback:
isolation:
semaphore:
maxConcurrentRequests: 1000 #信号量隔离级别最大并发数
circuitBreaker:
enabled: true #开启断路器
requestVolumeThreshold: 3 #失败次数(阀值)
sleepWindowInMilliseconds: 20000 #窗口时间
errorThresholdPercentage: 60 #失败率
execution:
isolation:
Strategy: thread #隔离方式 thread 线程隔离集合和 SEMAPHORE 信号量隔离
thread:
timeoutInMilliseconds: 3000 #调用超时时长相关面试题
什么是 Hystrix?
防雪崩利器,具备服务降级,服务熔断, 依赖隔离, 监控(Hstrix Dashboard)等功能
什么是服务熔断?熔断器的作用是什么?
首先我们说一下什么是扇出与雪崩效应:多个微服务之间调用的时候,假设微服
务 A 调用了微服务 B 和微服务 C,微服务 B 和微服务 C 又调用了其他的服务,这
就是所谓的扇出,如果扇出的链路上某个微服务的调用响应时间过长,或者是不
可用,那么该微服务调用者就会阻塞线程,占用越来越多的系统资源,进而崩溃。
同理,影响调用者的调用者,进而一步步崩溃,这也就是所谓的雪崩效应。
那么服务熔断机制就是应对雪崩效应的一种微服务链路保护机制,扇出链路
的某个微服务不可用,或者是响应时间过长,会进行服务的降级,进而会熔断该
节点微服务的调用,快速返回错误的响应信息,当检测到该节点微服务调用响应
正常的时候,恢复链路。在 SpringCloud 框架里熔断机制是通过 Hystrix 实现的。
Hystrix 会搞很多个小的线程池比如订单服务请求库存服务是一个线程池,
请求仓储服务是一个线程池,请求积分服务是一个线程池。每个线程池里的线程
仅仅用于请求那个服务,当某个线程池达到阈值时,就会启动服务熔断,服务降
级。如果其他请求继续访问,就直接返回 fallback 的默认值。
什么是服务降级?
服务熔断的时候,在返回的之前做一个熔断处理,比如将请求信息存储到数
据库以便后期数据恢复,我认为这种熔断后的处理指的就是服务降级。优先核心
服务,非核心服务不可用或弱可用。
服务降级案例:双十一:《哎哟喂,被挤爆了.…》或 app 秒杀:《网络开小差
了,请稍后再试…》
在 fallbackMethod (回退函数)中具体实现降级逻辑。
熔断和降级:调用服务失败后快速失败
熔断:是为了防止异常不扩散,保证系统的稳定性
降级:编写好调用失败的补救逻辑,然后对服务直接停止运行,这样这些接口就无法正常调用,但又不至于直接报错,只是服务水平下降
通过HystrixCommand 或者 HystrixObservableCommand 将所有的外部系统(或者称为依赖)包装起来,整个包装对象是单独运行在一个线程之中(这是典型的命令模式)。
超时请求应该超过你定义的阈值
为每个依赖关系维护一个小的线程池(或信号量);如果它变满了,那么依赖关系的请求将立即被拒绝,而不是排队等待
统计成功,失败(由客户端抛出的异常),超时和线程拒绝
打开断路器可以在一段时间内停止对特性服务的所有请求,如果服务的错误百分比通过阈值,手动或自动的关闭断路器。
当请求被拒绝、连接超时或者断路器打开,直接执行 fallback 逻辑。
近乎实时监控指标和配置变化。
Hystrix如何避免雪崩效应的?
首先要避免雪崩效应的形成 需要一个强大的容错机制,Hystrix 就是实现了超时机制和断路器模式的工具类库
Hystrix主要通过以下几点实现延迟和容错:
包裹请求: 使用HystrixCOmmand 包裹对依赖的调用逻辑,每个命令在独立线程中执行.使用了设计模式种的"命令模式"
跳闸机制: 当服务的错误率超过了一定的阈值时,Hystrix 可以自动或者手动跳闸,停止请求服务一段时间
资源隔离: Hystrix 为每个依赖维护一个小型的线程池或者是信号量,如果该线程吃已满,发送到该依赖的请求立即被拒绝,而不是排队等候,从而加速失败判定.
监控: Hystrix可以近乎实时的监控运行指标和配置的变化,列如 成功,失败,超时和被拒绝的请求等.
回退机制: 当请求失败,超时,被拒绝,或者当断路器打开的时候,执行回退逻辑.回退逻辑由自行提供,列入返回一个缺省值
自我修复: 断路器打开一段时间后 ,会自动进入"半开状态",尝试请求服务,请求通过恢复请求,请求失败则继续断路器开启