【读书笔记】【程序员的自我修养 -- 链接、装载与库(一)】线程模型(多对多);目标文件格式;静态链接;
文章目录
- 前言
-
- 基础回顾
-
- 计算机总线
- 操作系统
-
- 虚拟地址空间的引入 —— 内存不够?
- 线程的引入 —— 众人拾柴火焰高
-
- 线程安全
- 线程模型
- 编译与链接
-
- 编译器
- 链接器
- 静态链接
- 目标文件
-
-
- 目标文件结构
- ELF 文件结构描述
- 链接接口 - 符号
-
- 符号、符号表和特殊符号
- 符号修饰与函数签名
- extern"c"
- 弱符号与强符号
-
- 静态链接
-
-
- 空间与地址分配
- 符号解析与重定位
- COMMON块
- C++相关问题
- 静态库链接
- Windows PE/COFF
-
- 总结
- 参考
前言
这本书适合通读吗? // 适合
- 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决;(Any problem in computer science can be solved by another layer of indirection)
下接:【读书笔记】【链接、装载与库 part II 】程序员的自我修养 – 链接、装载与库;进程虚拟地址空间、装载与动态链接、GOT、全局符号表、DLL、C++与动态链接
-
重定向与重定位
- 标准输入输出重定向到哪里去
- 目标地址不确定,修正的过程是重定位
-
integer
-
PE :portable executable
-
ELF :executable linkable format
-
COFF :common file format
基础回顾
计算机总线
从前包含南北桥。
- 南桥芯片接低速设备的ISA总线。
- 北桥芯片接高速设备的PCI(E)总线+南桥芯片。
CPU 的多核
- 随着摩尔定律的消逝,CPU频率很难提升,遂多CPU 和多核出现。多核处理器是SMP(symmetrical Multi-Processing)的简化版。
操作系统
- 操作系统上面有运行时库,下面有硬件。各层次之间都有一个中间层作为接口。从上至下依次是 应用程序编程接口、系统调用、硬件标准。

虚拟地址空间的引入 —— 内存不够?
-
why ?虚拟地址空间 - 虚拟地址作为增加的中间层,以间接访问地址。
- 隔离地址空间 : 防止不同进程的影响。
- 提高内存使用效率 : 让每个进程拥有完整的地址空间,屏蔽底层置换逻辑。
- 固定程序运行的地址 : 使得每个程序有自己固定的程序运行地址。重定位
-
物理地址空间 : 大小 由 CPU地址线位宽决定。如32位CPU能寻址4GB空间。(实际物理内存大小,只决定了哪些地址有效与否)(实际上,还有一些IO设备映射到物理地址空间)
-
虚拟地址空间 : 每个进程都有自己独立的虚拟空间,每个进程只能访问自己的虚拟地址空间。(虚拟地址空间是人们做出来的)
-
程序对内存的使用存在 局部性原理,使用小粒度的内存分割和映射,可提高内存使用率。(即分页,而非分段)
-
内存分页:
- 将地址空间等分为固定大小的页,同时将虚拟空间与物理空间进行分页。
- 可以按照页将常用页放入内存,不常用页写回磁盘。(程序的数据和代码都存在局部性原理)(C++程序申请的内存,只有在首次使用时才会真正申请内存,否则被当作未使用的内存,只占据虚拟空间)
- 程序运行过程中存在:虚拟页、物理页、磁盘页。
- 同样有些物理页可被不同的虚拟空间映射,实现不同进程的共享内存。(IPC的一种)
-
页错误:
- 进程所需的页不在内存中,触发页错误(page fault),然后OS接管该进程,负责读硬盘装入内存,并建立映射关系。
-
MMU(memory management unit)
- 虚拟存储的实现依靠集成于CPU内部的 硬件MMU。
- CPU将虚拟地址交给MMU转换为物理地址。
线程的引入 —— 众人拾柴火焰高
- 线程
- 由线程ID、PC指针、寄存器集合、堆栈组成。 各线程共享进程内存空间。(代码段、数据段、堆和进程级资源如文件、信号等)
- 多线程较多进程,在数据共享方面效率更高。

- 线程调度的优先级可以由用户指定、根据进入等待状态的频率提升或降低、长时间得不到执行被提升。
- linux 中新的进程用fork 、exec;用clone 产生类似线程。
线程安全
线程安全指:多线程并发时,数据的一致性,
- 单指令操作为原子的;windows 有提供一些原子操作的API,但是为了保证复杂数据结构的原子性,需要用锁。
- 同步:线程访问数据时,其他线程不能访问该数据,即数据访问的原子性。
- 二元信号量为一种简单的锁。信号量为允许多个线程并发访问的多元信号量。
- 互斥量 与二元信号量相似,二元信号量可以由其他线程释放,而互斥量要求同个线程获取与释放。// really?
- 临界区 与互斥量相似,互斥量可以由其他进程获取,临界区仅作用于本进程。
- 读写锁 致力于较特殊的多读少写场合的同步,可实现读/写优先的读写锁。【C++】linux 下 pthread 线程同步例子;实现互斥锁、自旋锁、读写锁、条件变量;
- 条件变量 支持多个线程等待一个条件变量,当条件变量唤醒后,可以恢复多个线程。
- 可重入 是并发安全的强力保障,可重入函数可以在多线程环境下放心使用。
- 仅加锁也不一定能保证线程安全。
- 编译器将变量放入寄存器内计算、编译器优化了指令顺序。可以加 volatile 关键字,防止过度优化。
- volatile 可以防止变量缓存后不写回、防止编译器优化指令顺序。
- volatile能阻止编译器调整顺序,不能阻止CPU动态调度换序。(即调度引起的不同线程的顺序)
- 通常使用 barrier 指令,阻止换序穿透 barrier 指令。
线程模型
-
OS内核实现的内核线程由处理器或OS调度实现并发,用户实际使用的线程为用户态的用户线程。
- 由API或系统调用创建的线程为 一对一的线程。(linux 的clone、windows 的CreateThread)
-
一对一模型:
- 用户线程唯一对应一个内核使用的线程,但内核线程不一定在用户态由对应的线程。(实现真正的并发)
- 但是 :
- 多数OS限制了内核线程数量,即一对一线程会使用户线程受到限制。
- OS调度线程,上下文切换开销较大,导致用户线程执行效率下降。(当然还是比跨进程线程切换更快,只是相对于多对一的模型来说更慢)
-
多对一模型:
- 多个用户线程映射到一个内核线程上。
- 用户线程的切换由用户态代码进行,没有陷入内核态,更高效的上下文切换、几乎无限制的线程数。
- 但是:
- 一个用户线程的阻塞将使得对应内核线程也阻塞,造成其他用户线程也阻塞了。// 用户线程切换不行吗?,还是说阻塞是阻塞,切换时时间片到了用户线程的切换。
-
多对多模型:
- 将多个用户线程映射到一部分的内核线程上。(相当于又加了一个间接的中间层)
- 一个用户线程阻塞,不会造成其他所有用户线程的阻塞,因为还有别的内核线程被调度执行。
- 对用户线程数量也没什么限制,虽然在多处理器下比一对一模型提升高。
编译与链接
-
通常IDE的构建(build) 包括了:编译、链接;
-
GCC 编译时,有四步:预处理、编译、汇编、链接。gcc命令只是一些后台程序的包装,根据不同参数,调用对应的编译器程序cc1、汇编器as、连接器ld等;

-
预处理:
hello.i- 将 .h + .c 预编译成 .i 文件;相当于
gcc -E hello.c -o hello.i; - 主要负责:将
#开始的预编译指令替换与展开。
- 将 .h + .c 预编译成 .i 文件;相当于
-
编译:
hello.s- 编译成 .s 汇编代码文件;相当于
gcc -S hello.i -o hello.s; - 负责将预处理后的文件进行:词法分析、语法分析、语义分析、优化;
- 编译成 .s 汇编代码文件;相当于
-
汇编:
hello.o- 汇编成 .o 目标文件;相当于
gcc -c hello.s -o hello.o、as hello.s -o hello.o、或者直接gcc -c hello.c -o hello.o; - 每个汇编语句几乎都对应一条机器指令,只需要一一汇编为机器指令即可。
- 汇编成 .o 目标文件;相当于
-
链接:
a.out
编译器
* 编译器只是将高级语言翻译为机器语言的一个工具 * 主要包括了:扫描、词法分析、语法分析、语义分析、源代码优化、代码生成、目标代码优化; 
词法分析 - lex
- 将源代输入扫描器(scanner),利用有限状态机(finite state machine):将源代码字符序列分割成一系列记号(Token)。
- 记号一般分为:关键字、标识符、字面量(数字、字符串、etc)、特殊符号(+、=)。
语法分析 - yacc
- 语法分析器(grammar parser)将 Token 进行语法分析,产生语法树(syntax tree);采用了 上下文无关语法(context - free grammar)作为分析手段。
- 语法树是以表达式(Expression)为节点的树,一个语句可以是多个表达式的组合。
- 符号和数字是最小的表达式,所以作为语法树的叶子节点。
- 语法分析时,会确定运算符号的优先级及其含义。(
*作为乘法或者解引用符号) - 如果表达式不合法,编译器会报告语法分析阶段的错误。

语义分析
- 语义分析器(semantic analyzer)负责 静态语义 的分析,标识语法树上表达式的类型。
- 当需要类型隐式转换时,会在语法树中插入相应的转换节点。
- 静态语义 :包括声明和类型的匹配,类型的转换。当类型不匹配时,编译器会报错。(如将浮点数给指针)
- 动态语义 :在运行阶段出现的语义相关的问题。(如 0 作为被除数)

中间语言的生成
- 源码级优化器 (source code optimizer)负责源代码级别优化,往往将整个语法树转换为中间代码后优化。(直接在语法树上优化较为困难)
- 中间代码和目标机器、运行环境无关,所以不含数据的尺寸、变量地址、寄存器的名称等。
- 常见的中间代码有: 三地址码(three - adress code:
x = y op z) 、p-diamagnetic; - 中间代码的基础上优化,会将常数运算提前计算。
- 中间代码使得编译器可以分为前端+后端。前端负责生成为中间代码、后端负责中间代码转换为目标机器码,这样可以在跨平台阶段,使用同一个前端和多个平台的后端。
目标代码的生成和优化
-
从中间代码产生以后都作为了编译器后端,编译器后端主要包括:代码生成器(code generator)和目标代码优化器(target code optimizer)。
-
代码生成器 : 将中间代码转换成目标机器代码。(不同机器有不同的字长、寄存器、整数与浮点数的数据类型等)
-
目标代码优化器:对上述汇编代码进行优化,如许纳泽合适的寻址方式、使用位移代替乘法运算、删除多余指令等。
-
问题:
- 目标代码中有变量定义在其他模块,这些要在链接时才能确定。
链接器
- 重定位:代码修改后,重新计算各个目标地址的过程
- 模块化代码:使得代码更容易阅读、理解、重用,使得各个模块可以单独开发、编译、测试,改变部分代码不需要编译整个程序。
- 模块间如何组合,或者如何通信是重点。
- 常见的静态语言的C/C++模块间通信有:模块间函数调用、模块间的变量访问;
- 因为都是通过目标地址来实现,可以抽象为模块间符号的引用。
- 模块的拼接,就是链接过程。(linking)
静态链接
-
链接过程主要包括:地址和空间分配、符号决议、重定位。
-
静态链接 :将每个模块生成的目标文件(.o),加库文件一起链接成为最终的可执行文件。
-
库只是一些常用代码编译成目标文件后打包存放。最常见的库是运行时库(runtime lirary),是支持程序运行的基本函数的集合。
- 运行时库: 程序运行的时候所依赖的库文件,提供了静态、动态,以及debug、release 版本。
- C/C++运行时库提供了一些常用的功能支持(如malloc,free, printf等等)
- 运行时库: 程序运行的时候所依赖的库文件,提供了静态、动态,以及debug、release 版本。
-
在模块中调用其他模块的函数时,可以在
.h中找到对应函数,但是又没有链接,所以会将调用指令目标地址搁置,等到链接时再去修正。修正的过程就叫重定向,要修正的地方就是重定位入口。 -
重定位就是给这种绝对地址引用的位置“打补丁”,使其指向正确地址。
-
同样对于一些全局变量,在别的模块中访问时,也会暂时搁置,等待链接时“打补丁”。
目标文件
目标文件结构
- 目标文件 :源代码经过编译器编译但未进行链接的中间文件。从结构上讲,已经是编译后的可执行文件格式。
- 动态链接库(.dll、.so)和静态链接库(.lib、.a),都按照可执行文件格式存储。win下按照 PE-COFF 、linux下按照ELF 格式存储。
- 目标文件中包含了编译后的机器指令代码、数据,以及链接所需的符号表、调试信息、字符串等。
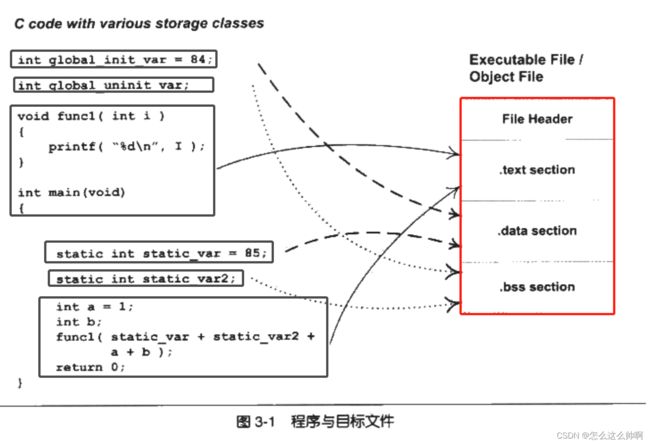
- 上图的目标文件格式为ELF。开头为一个文件头,描述了整个文件的文件属性。
- 文件头包含了:是否可执行、静态or动态链接、入口地址、目标硬件、目标OS等。还包括一个段表,描述各个段的偏移地址及属性。
- 属性包括了是否占据位置、可读可写?、是什么段、是否装载?
- bss段(block started by symbol)内的数据在运行时是要占内存空间的,但是会被初始化为0,所以没必要存储,只记录预留位置。所以bss段在目标文件中不占空间。(只在文件头中标识了预留位置)(通过size 手段查询.o文件,显示的bss段的大小是记录在文件头中的记录预留空间)
- 源代码编译后包括了程序指令和程序数据。代码段(.text)是程序指令,数据段(.data)和.bss段是程序数据。
- 指令和数据分离:
- 有利于程序装载后,映射到不同区域,使指令区域只读、数据区域读写。
- CPU指令缓存和数据缓存的分离,有利于提高缓存命中率。
- 有利于共享只读空间,节约空间。
- 文件头包含了:是否可执行、静态or动态链接、入口地址、目标硬件、目标OS等。还包括一个段表,描述各个段的偏移地址及属性。

-
- 不同编译器对于字符常量放入data还是rodata段是不同的。(gcc 将其放入rodata,msvc将其放入 data段)
- 同样存在编译器将初始化为0的静态变量同样放在bss 段这样的手段。
- 除了text、data、bss,ELF文件可能还存在很多段。
- gcc提供了
__attribute__((section("name")))将对应变量放或函数放入name 段中,为了满足有些硬件内存或IO的地址布局等。(跑arm经常能看到u32 arr[ ] __attribute__((at(0X68000000)));这样的绝对定位)- 如:
__attribute__((section("FOO"))) int global = 42;或__attribute__((section("BAR"))) void f00(){ }
- 如:
ELF 文件结构描述
ELF 文件主要结构:

- 可以使用
readelf -h hello.o命令详细查看ELF文件结构。其对应清单来自文件头结构体Elf32_Ehdr或Elf64_Ehdr
typedef struct
{
unsigned char e_ident [EI_NIDENT]
Elf32_Half e_type
Elf32_Half e_machine
Elf32_Word e_version
Elf32_Addr e_entry
Elf32_Off e_phoff
Elf32_Off e_shoff
Elf32_Word e_flags
Elf32_Half e_ehsize
Elf32_Half e_phentsize
Elf32_Half e_phnum
Elf32_Half e_shentsize
Elf32_Half e_shnum
Elf32_Half e_shstrndx
} Elf32_Ehdr;
- 段表(section header table) 是除了文件头外最重要的部分。偏移由头文件中的
e_shoff决定。- 段表描述了各个段的信息,如段名、长度、偏移、读写权限和其他属性。
objudmp -h只是显示了关键段,还有些段如:符号表、字符串表、段名字符串表、重定位表等。用readelf -s hello.o查看真正段表结构。Elf32_Shdr结构体数组表示段,Elf32_Shdr称为段描述符(section descriptor)
typedef struct
{
Elf32_Word sh_name
Elf32_Word sh_type
Elf32_Word sh_flags
Elf32_Addr sh_addr
Elf32_Off sh_offset
Elf32_Word sh_size
Elf32_Word sh_link
Elf32_Word sh_info
Elf32_Word sh_addralign
Elf32_Word sh_entsize
} Elf32_Shdr;
- 其中
sh_type段类型、sh_flags段标志位(可写、进程空间中 分配空间/执行)主要决定段的属性。
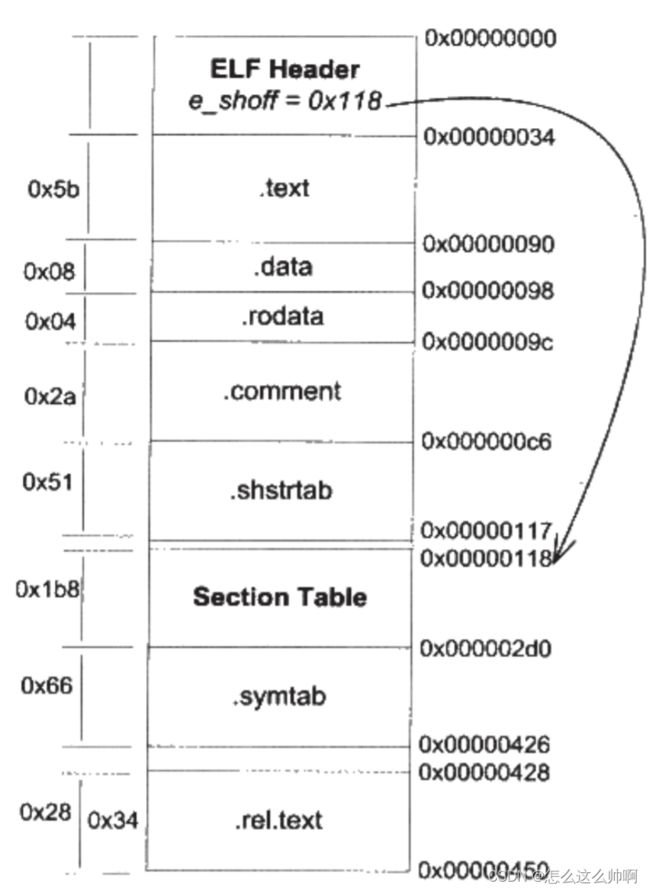
.rel.text段类型为SHT_REL,即是重定位表(relocation table)。用于在链接过程中,对代码段和数据段中绝对地址引用的位置的重定位。- 字符串表 : 用于存储ELF文件中的字符串,将字符串集中起来存储在一个表,用
\0分割字符串,用偏移地址引用字符串。一般包含字符串表(string table ,保存普通字符串,如符号名)和 段表字符串表(section header string table,保存段表中用到的字符串,如段名)- ELF头文件
Elf32_Ehdr结构体中e_shstrndx(section header string table index)表示的就是段表字符串表的索引,即分析ELF头文件,就可以的得到段表和段表字符串表的位置。
- ELF头文件
链接接口 - 符号
符号、符号表和特殊符号
- 符号:链接中,将函数和变量统称为符号(symbol),函数名和变量名就是符号名。
- 符号表中记录了目标文件中所用到的所有的符号,符号对应了一个符号值,就是对应变量或函数的地址。可以使用
nm hello.o或readelf -s hello.o查看符号表。- 符号表也是ELF文件中的一个段(
.symtab,是一个Elf32_Sym结构体数组)
- 符号表也是ELF文件中的一个段(
typedef struct
{
Elf32_Word st_name //符号名,作为该符号名在字符串表中的下标。
Elf32_Addr st_value
Elf32_Word st_size
unsigned char st_info // 标明符号类型(是什么类型对象,函数、数据、段、文件名?)和绑定信息(局部可见、全局可见、弱引用)
unsigned char st_other
Elf32_Section st_shndx
} Elf32_Sym;
-
其中value 对非COMMON属性的元素为其所在段的偏移,再根据段名,就可确定该元素在目标文件中的地址。

-
还有一些特殊符号可以直接在程序中声明和使用。这些符号是链接过程中链接器脚本定义的。所以程序中声明exten 后直接使用即可。
- 如:
__executable__start程序起始地址、__etext代码段结束地址、_edaa数据段结束地址、_end程序结束地址。 - 这些地址都是装载时的虚拟地址。
- 如:
符号修饰与函数签名
- 由于程序的庞大和库的引入,会产生很多重复的函数和变量名, 会使目标文件冲突。
- 为了防止符号名冲突,C语言源代码的全局变量和函数经过编译后,对应符号前会加上
_。这样还是不能解决同一种语言编写目标文件产生符号冲突,于是慢慢的linux下的gcc 已经不再使用这样的方式。但是windows下的GCC(mingw、cygwin)和visual C++还是默认加上的,并可根据命令定制。 - C++使用命名空间(namespace) 解决了多模块的符号冲突问题。
- 为了防止符号名冲突,C语言源代码的全局变量和函数经过编译后,对应符号前会加上
- C++ 的复杂特性(如重载等特性),使得C++符号管理更加复杂,于是引入了符号修饰(name decoration)和符号改编(name mangling) 机制。
- 对于函数重载和语言级别支持的命名空间,使得多个函数同名。
- 函数签名包括:函数名、参数类型、所在类及命名空间等。
- 编译器和链接器处理符号时,使用名称修饰 的方法,使得每个函数签名对应一个修饰后名称。目标文件中的符号名是对应函数和变量的修饰后名称。
- binutils 中提供了
c++filt工具以解析被修饰后的名称。如:c++filt _ZN1N1C4funcEi:解析为N::C::func(int) - 全局变量和静态变量也同样由这样的机制,如不同函数中有同名静态变量,对应的修饰后名字中有函数名的标记。
- 不同编译器采用不同的名字修饰方法,导师不同编译器产生的目标文件无法互相链接。
extern"c"
- c++为了与C兼容,符号管理上,C++使用
extern"c":来声明或定义一个C符号。- 因为Linux 下GCC 不会符号进行修饰了,而C++需要修饰,所以需要注明符号是c的,不要去修饰,否则链接时将会找不到对应符号。
- 例如
void *memset(void* ,int, size_t);是c语言在string.h中声明的函数,在c中使用时编译器对memset符号正确处理。但是在C++中使用时,编译器会以为这个是C++函数,将其修饰后,链接器将无法将其与C库中的对应符号进行链接。 - 所以需要在头文件声明时使用
extern"c"对其进行修饰(C、C++混合编程时,使用同一个头文件),但是C语言又不支持extern"c"语法,所以引入C++宏__cplusplus,C++编译器会在编译C++时默认定义这个宏。于是可以根据宏来判断当前编译器,以实现C、C++混合编程时只使用同一套头文件。
#ifdef __cplusplus
extern "c"{
#endif
void *memset(void* ,int, size_t);
#ifdef __cplusplus
}
#endif
上述代码的技巧在几乎所有的系统头文件中都有用到。
弱符号与强符号
- 编译器默认:函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。
- 可以使用GCC的
__attribute__((weak))来定义一个强符号为弱符号。 - 强弱符号时针对定义而言,不是使用
extern对符号的引用。
- 可以使用GCC的
- 连接器不允许强符号多次定义。
- 如果存在多个弱符号和一个强符号,将选择强符号。
- 多个弱符号则选择占空间最大的一个。(这样会引起歧义,出现难以发现的程序错误)
- 强引用:外部目标的符号引用在目标文件最终被链接为可执行文件时,如果没有找到该符号的定义,则会报顾好未定义错误,这种是强引用。
- 弱引用:处理弱引用时,有定义时,则链接器将该符号的引用决议。如果该符号未被定义,则链接器对该引用不报错。未被定义的弱引用一般默认为0或一个特殊值。
- 使用
__attribute__((weakref)) void foo();来对外部函数进行弱引用。 - 弱引用不存在定义时,链接时不会出错。但是在运行到使用这个函数时会发生运行错误,因为访问了非法地址。可以通过使用前加上
if(foo)来判断函数定义是否存在。
- 使用
- 弱符号和弱引用对于库来说十分有用 。
- 弱符号可以被强符号覆盖,使得程序可以使用自定义版本的库函数。
- 弱引用可以在扩展功能时,定义为弱引用,当和扩展模块一起链接时可以正常使用,当去掉扩展模块链接时,程序也能正常连接和运行,只是缺少对应功能,使得程序更容易裁剪和组合。

静态链接
空间与地址分配
- 可执行文件中的代码段与数据段都是由输入目标文件中合并而来的。
- 将所有的相同性质的段合并起来。对于
.bss段来说,只分配了虚拟地址空间,并没有在文件中的内容。虚拟地址空间用于在后续装载后分配的虚拟地址。
- 链接过程 (两步链接:空间与地址分配、符号解析与重定位)
- 空间与地址分配:扫描输入目标文件,获得段长度、属性和位置,将文件符号表中所有符号定义与符号引用收集,放入全局符号表。这步合并了各个段并建立了映射关系。
- 符号解析与重定位:读取输入文件的段数据、重定位信息,进行符号解析与重定位、调整代码中的地址等。是链接过程中的重点。
- 链接命令:
ld a.o b.o -e main -o ab- (
-e main表示将main 作为程序入口,ld链接器默认程序入口为_start)(-o ab表示链接输出文件名为ab,默认为ab.out) - 链接后,可执行文件的各个段都被分配到了相应的虚拟地址,这里的虚拟地址就是程序在进程中的虚拟地址。
- 所分配的起始地址,和OS的进程虚拟地址空间的分配规则有关。Linux下ELF可执行文件默认从地址
0x08048000开始分配。
- (

- 当各个段的虚拟地址确定了以后,链接器开始计算各个符号的虚拟地址。
- 因为符号对于段内的相对位置固定,所以函数与变量的地址其实已经确定了,只需要链接器给这些符号地址在段地址基础上加上段内偏移地址即可。
符号解析与重定位
- 在未链接的目标文件中,对应的外部符号都由0或特殊地址代替,将真正的地址计算工作交给了链接器。
- 当链接器完成地址和空间的分配之后,已经有了所有符号的虚拟地址了,遂根据符号地址对每个需要重定位的指令进行地址修正。
- 每个要被重定位的地方称为重定位入口(relocation entry),重定位入口的偏移表示该入口在要被重定位的段中的偏移位置,即对应指令的地址部分。
- 可以使用
objdump -r a.o查看对应的重定位表。重定位表使用一个Elf32_Rel结构体数组记录偏移(offset)和信息(info)
- 链接时“符号未定义”,就是缺少了某个库、或者输入目标文件路径不正确、或者符号的声明与定义不一致。
- 重定位的过程中也伴随这符号的解析过程。重定位过程中,每个重定位入口都是对一个外部符号的引用。
- 当需要对某个符号的引用进行重定位时,链接器会去查找由所有目标文件符号表组成的全局符号表,找到对应的符号进行重定位。
- 即根据重定位表知道哪些需要重定位,再根据之前空间地址分配时简历的全局符号表来重定位。(全局符号表中已经记录了各个符号的绝对虚拟地址)
- 如果重定位项符号没有在全局符号表中找到, 链接器就会报符号未定义错误。(
undefined reference to "***")
- 指令修正方式包括了绝对寻址修正(修正后是实际地址)和相对寻址修正(修正后是距离被修正位置的地址差)。
COMMON块
- COMMON块机制:现代链接机制处理弱符号,采用COMMON机制。弱符号所占空间大小按照最大的来算。
- 看似因为编译器和链接器允许不同类型的弱符号同时存在。
- 真正原因是链接器不支持符号类型,即链接器无法判断各个符号的类型是否一致。
- 这也是为什么弱符号元素空间在编译后是未知的,因为有可能别的模块的该符号所占空间更大。
- 只有链接过程能确定弱符号的大小,所以可以在最终输出文件的BSS段为其分配空间。
C++相关问题
- C++的语言特性,使得编译器和链接器共同支持才能完成工作。主要包括重复代码消除、全局构造与析构。
- 对于重复代码的消除。(模板造成的多个段中存在同一个模板实例)
- 通常使用每个模板实例对应一个段,在链接时区分相同的模板实例段,将其合并入最后的代码段。
- 同样虚函数表也会存在多个目标文件使用一个模板类,造成多份虚函数表。同样采用类似的方法实现代码消除。
- C++ 的全局构造与析构在另外两个 .init 、.fini段中,有系统库调用执行这两个部分(在main前和main后)
- ABI(Application Binary Interface,应用程序二进制接口)和诸多因素相关,如硬件平台、编程语言、编译器、链接器和OS之间。ABI兼容讲的是二进制兼容问题。
- 就语言层面,就有内置类型的大小和存放方式、组合类型的存储方式和内存分布函数调用方式等等兼容问题。
- ABI不兼容,很多只提供二进制的库,就有可能只有使用编译库的编译器来编译自己的程序才能用。
静态库链接
-
程序依靠OS提供的API进行输入输出以及交互,通常一种语言的开发环境所带的语言库,都对OS的API进行了包装,如printf,在windows下最终会调用
WriteConsole,linux 最终调用write。 -
静态库可以看作是一组目标文件得集合。
- 如将各种
.o文件使用 ar 压缩程序压缩并进行编号和索引,生成libc.a。 - 链接时,链接器自动寻找所需符号及其所在目标文件,将这些目标文件从
.a库中解压出来,并将其链接一起成为可执行文件。 - 静态运行库中一个目标文件只包含一个函数,因为链接静态库时以目标文件为单位,使用一个函数就只需要将这个目标文件链接进来。否则目标文件中很多函数,都链接进来就是浪费。
- 如将各种
-
默认使用链接器时,ld会使用默认链接脚本。
- 可以自己修改连接脚本,可以指定各个段的段虚拟地址、段名称、段存放顺序等。
Windows PE/COFF
- PE(protable executable,win32平台标准可执行文件格式)与ELF同源,由COFF(common object file format)格式发展而来。
- 32位PE格式和64位PE32+格式并没有结构变化,最大变化将32位字段改为64位。
- PE 是COFF的一种扩展,Windows平台目标文件默认COFF、可执行文件默认PE.
- windows 使用 Microsoft Visual C++环境,包括编译器 cl、链接器 link 、可执行文件查看器 dumpbin
- COFF文件结构
- 同ELF相似,包括映像头(描述文件总体结构和属性)、段表(描述文件中包含的段属性)、各个段、符号表等
- PE文件在装载时,直接被映射到今晨的虚拟空间中运行,它是进程虚拟空间的映像。 所以PE可执行文件很多时候叫做映像文件(image file)

.drectve段是directive的缩写,是编译器传递给链接器的指令,即编译器希望链接器怎样链接这个目标文件(object)。.deug开头的段都包含着调试信息。- COFF符号表是最后部分,主要是符号名、符号类型、所在位置。
- PE文件是基于COFF的扩展,比COFF多了几个结构
- 文件开始部分为DOS MZ可执行文件格式的文件头和sub (为了兼容DOS)
- COFF文件头扩展为了PE文件头结构
- 包括了之前的 Image Header 以及新增的PE扩展头部结构(PE optional Header)

- PE扩展头部结构(PE optional Header)
- PE数据目录:
DataDirectory成员变量,是一个IMAGE_DATA_DIRECTORY结构体数组,存放着导入表、导出表、资源、重定位表等,用于windows 装载PE可执行文件时的一些装载需要的数据结构。- 数组长度16,记录着前面所需的各种表的虚拟地址和长度。这些表多数和装载、DLL动态链接有关。
- PE数据目录:
总结
参考
- 程序员的自我修养 – 链接、装载与库;