团体程序设计天梯赛 -- 练习集 (L2合集)
文章目录
-
- L2-001 紧急救援 (25 分)
- L2-002 链表去重 (25 分)
- L2-003 月饼 (25 分)
- L2-004 这是二叉搜索树吗? (25 分)
- L2-005 集合相似度 (25 分)
- L2-006 树的遍历 (25 分)
- L2-007 家庭房产 (25 分)
- L2-008 最长对称子串 (25 分)
- L2-009 抢红包 (25 分)
- L2-010 排座位 (25 分)
- L2-011 玩转二叉树 (25 分)
- L2-012 关于堆的判断 (25 分)
- L2-013 红色警报 (25 分)
- L2-014 列车调度 (25 分)
- L2-015 互评成绩 (25 分)
- L2-016 愿天下有情人都是失散多年的兄妹 (25 分)
- L2-017 人以群分 (25 分)
- L2-018 多项式A除以B (25 分)
- L2-019 悄悄关注 (25 分)
- L2-020 功夫传人 (25 分)
- L2-021 点赞狂魔 (25 分)
- L2-022 重排链表 (25 分)
- L2-024 部落 (25 分)
- L2-025 分而治之 (25 分)
- L2-026 小字辈 (25 分)
- L2-027 名人堂与代金券 (25 分)
- L2-028 秀恩爱分得快 (25 分)
- L2-029 特立独行的幸福 (25 分)
- L2-030 冰岛人 (25 分)
- L2-031 深入虎穴 (25 分)
- L2-032 彩虹瓶 (25 分)
- L2-033 简单计算器 (25 分)
- L2-034 口罩发放 (25 分)
- L2-035 完全二叉树的层序遍历 (25 分)
- L2-036 网红点打卡攻略 (25 分)
- L2-037 包装机 (25 分)
- L2-038 病毒溯源 (25 分)
- L2-039 清点代码库 (25 分)
- L2-040 哲哲打游戏 (25 分)
L2-001 紧急救援 (25 分)
作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图。在地图上显示有多个分散的城市和一些连接城市的快速道路。每个城市的救援队数量和每一条连接两个城市的快速道路长度都标在地图上。当其他城市有紧急求助电话给你的时候,你的任务是带领你的救援队尽快赶往事发地,同时,一路上召集尽可能多的救援队。
输入格式:
输入第一行给出4个正整数N、M、S、D,其中N(2≤N≤500)是城市的个数,顺便假设城市的编号为0 ~ (N−1);M是快速道路的条数;S是出发地的城市编号;D是目的地的城市编号。
第二行给出N个正整数,其中第i个数是第i个城市的救援队的数目,数字间以空格分隔。随后的M行中,每行给出一条快速道路的信息,分别是:城市1、城市2、快速道路的长度,中间用空格分开,数字均为整数且不超过500。输入保证救援可行且最优解唯一。
输出格式:
第一行输出最短路径的条数和能够召集的最多的救援队数量。第二行输出从S到D的路径中经过的城市编号。数字间以空格分隔,输出结尾不能有多余空格。
输入样例:
4 5 0 3
20 30 40 10
0 1 1
1 3 2
0 3 3
0 2 2
2 3 2
输出样例:
2 60
0 1 3
思路 :
拥有第二标尺的最短路径问题
第二标尺:有多条路径相同时
在有两条路径相同时,需要再增加一条判断准则(第一准则是距离)
1.给每一条边加一个边权(花费),要求在最短路径有多条时要求路径上花费最小或最大
2.给没个点加一个点权,和边权一样问法
3.直接问有多少条最短路径
解题方法:
是增加一个数组存放新的边权或点权或做短路径条数,然后在算法中修改优化d[v]步骤
1.cost[u][v]表示u->v的花费,并增加一个数组c[],令从起点s到达顶点u的最少花费为c[u],初始时只有c[s]=0,其余都为INF
for (int v = 0; v < n;v++){//以u为中介开始优化到s的距离
if(vis[v]==false&&G[u][v]!=INF){
if(d[u]+G[u][v]2.weight[u]表示城市u的点权(题目输入),并增加一个数组w[],s到u的最大物资为w[u],初始化时只有w[s]为weight[s],其余w[u]均为0
for (int v = 0; v < n;v++){//以u为中介开始优化到s的距离
if(vis[v]==false&&G[u][v]!=INF){
if(d[u]+G[u][v]w[v]){
w[v]=w[u]+weight[v];
}
}
}
3.增加数组num[],s到u的最短路径条数为num[u],num[s]=1,其余num[u]=0;
for (int v = 0; v < n;v++){//以u为中介开始优化到s的距离
if(vis[v]==false&&G[u][v]!=INF){
if(d[u]+G[u][v]AC代码 :
#include
#include
#include
#include
using namespace std;
const int N = 520;
const int INF = 0x7fffffff;
int G[N][N]; //存图
int dis[N]; //源点到各个点的距离 (第一标尺)
int cnt[N]; //每个城市救援队数量
int cntsum[N]; //源点到每个点的最多队伍数量 (第二标尺)
int road[N]; //最短路径条数
bool vis[N];
int pre[N]; //存路径
int n, m, s, d;
void printPath(int v){
if(v == s){
cout << v;
return;
}
printPath(pre[v]);
cout << " " << v;
}
int main(){
scanf("%d%d%d%d",&n,&m,&s,&d);
fill(G[0],G[0] + N * N,INF);
fill(dis, dis + N, INF);
for (int i = 0; i < n;i ++) cin >> cnt[i];
int a, b, c;
for(int i = 0;i < m;i ++){
scanf("%d%d%d", &a, &b, &c);
G[a][b] = c;
G[b][a] = c;
}
dis[s] = 0;
road[s] = 1;
cntsum[s] = cnt[s];
for (int i = 0; i < n;i ++){
int u = -1, min = INF;
for (int j = 0; j < n;j ++){
if (vis[j] == false && dis[j] < min){
min = dis[j];
u = j;
}
}
if(u == -1) break;
vis[u] = true;
for (int v = 0; v < n;v ++){
if (G[u][v] != INF && vis[v] == false){
if(dis[u] + G[u][v] < dis[v]){
dis[v] = dis[u] + G[u][v];
cntsum[v] = cntsum[u] + cnt[v];
road[v] = road[u];
pre[v] = u;
}else if(dis[u] + G[u][v] == dis[v]){
road[v] += road[u];
if(cntsum[v] < cntsum[u] + cnt[v]){
cntsum[v] = cntsum[u] + cnt[v];
pre[v] = u;
}
}
}
}
}
cout << road[d] << " " << cntsum[d] << endl;
printPath(d);
return 0;
}
L2-002 链表去重 (25 分)
给定一个带整数键值的链表 L,你需要把其中绝对值重复的键值结点删掉。即对每个键值 K,只有第一个绝对值等于 K 的结点被保留。同时,所有被删除的结点须被保存在另一个链表上。例如给定 L 为 21→-15→-15→-7→15,你需要输出去重后的链表 21→-15→-7,还有被删除的链表 -15→15。
输入格式:
输入在第一行给出 L 的第一个结点的地址和一个正整数 N(≤1e 5 ,为结点总数)。一个结点的地址是非负的 5 位整数,空地址 NULL 用 −1 来表示。
随后 N 行,每行按以下格式描述一个结点:
地址 键值 下一个结点
其中地址是该结点的地址,键值是绝对值不超过10
4
的整数,下一个结点是下个结点的地址。
输出格式:
首先输出去重后的链表,然后输出被删除的链表。每个结点占一行,按输入的格式输出。
输入样例:
00100 5
99999 -7 87654
23854 -15 00000
87654 15 -1
00000 -15 99999
00100 21 23854
输出样例:
00100 21 23854
23854 -15 99999
99999 -7 -1
00000 -15 87654
87654 15 -1
思路 :
开一个结构体存储信息,然后从头结点开始遍历一遍链表,重复的和没有重复的分开储存,下面代码开两倍空间进行存储;
不要被链表吓到
int h[N],e[N],ne[N],idx;
void add(int a,int b){
e[idx] = b;ne[idx] = h[a];h[a] = idx ++ ;
}
for(int i = h[a];i != -1;i = ne[i]){
int j = e[i];
}
AC代码 :
#include
#include
#include
using namespace std;
const int maxn = 1e5;
struct Node{
int address;
int key;
int next;
int num; //记录数组下标位置
}node[maxn];
bool vis[maxn];
bool cmp(Node a,Node b){
return a.num L2-003 月饼 (25 分)
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入格式:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
输出格式:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
输入样例:
3 20
18 15 10
75 72 45
输出样例:
94.50
思路 :
贪心模拟
AC代码 :
#include
using namespace std;
struct node{
double w,v,x;
};
bool cmp(node a,node b){
return a.x>b.x;
}
int main(){
int n,i;
double d,sum=0;
struct node a[1010];
scanf("%d %lf",&n,&d);
for(i=1;i<=n;i++){
scanf("%lf",&a[i].w);
}
for(i=1;i<=n;i++){
scanf("%lf",&a[i].v);
}
for(i=1;i<=n;i++){
a[i].x=(1.0*a[i].v)/a[i].w;
}
sort(a+1,a+n+1,cmp);
for(i=1;i<=n;i++){
if(d>=a[i].w){
sum+=a[i].v;
d-=a[i].w;
}
else{
sum+=1.0*d*a[i].x;
break;
}
}
printf("%.2f\n",sum);
return 0;
}
L2-004 这是二叉搜索树吗? (25 分)
一棵二叉搜索树可被递归地定义为具有下列性质的二叉树:对于任一结点,
其左子树中所有结点的键值小于该结点的键值;
其右子树中所有结点的键值大于等于该结点的键值;
其左右子树都是二叉搜索树。
所谓二叉搜索树的“镜像”,即将所有结点的左右子树对换位置后所得到的树。
给定一个整数键值序列,现请你编写程序,判断这是否是对一棵二叉搜索树或其镜像进行前序遍历的结果。
输入格式:
输入的第一行给出正整数 N(≤1000)。随后一行给出 N 个整数键值,其间以空格分隔。
输出格式:
如果输入序列是对一棵二叉搜索树或其镜像进行前序遍历的结果,则首先在一行中输出 YES ,然后在下一行输出该树后序遍历的结果。数字间有 1 个空格,一行的首尾不得有多余空格。若答案是否,则输出 NO。
输入样例 1:
7
8 6 5 7 10 8 11
输出样例 1:
YES
5 7 6 8 11 10 8
输入样例 2:
7
8 10 11 8 6 7 5
输出样例 2:
YES
11 8 10 7 5 6 8
输入样例 3:
7
8 6 8 5 10 9 11
输出样例 3:
NO
思路 :
AC代码 :
#include
#define INF 0x3f3f3f3f
typedef long long ll;
using namespace std;
const int maxn = 1e3 + 10;
int n,a[maxn];
vector now;
void f(int l,int r,int x)
{
if(l > r) return;
int tl = r;
int tr = l + 1;
if(!x)
{
while(tl > l && a[tl] >= a[l]) tl--;
while(tr <= r && a[tr] < a[l]) tr++;
}
else
{
while(tl > l && a[tl] < a[l]) tl--;
while(tr <= r && a[tr] >= a[l]) tr++;
}
if(tr - tl != 1) return;
f(l+1,tl,x);
f(tr,r,x);
now.push_back(a[l]);
}
int main()
{
scanf("%d",&n);
for(int i = 0;i < n;i++) scanf("%d",&a[i]);
f(0,n - 1,0);
if(now.size() != n)
{
now.clear();
f(0,n - 1,1);
}
if(now.size() != n) printf("NO");
else
{
printf("YES\n%d",now[0]);
for(int i = 1;i < n;i++) printf(" %d",now[i]);
}
return 0;
}
L2-005 集合相似度 (25 分)
给定两个整数集合,它们的相似度定义为:N c /N t ×100%。其中N c 是两个集合都有的不相等整数的个数,N t 是两个集合一共有的不相等整数的个数。你的任务就是计算任意一对给定集合的相似度。
输入格式:
输入第一行给出一个正整数N(≤50),是集合的个数。随后N行,每行对应一个集合。每个集合首先给出一个正整数M(≤10 4 ),是集合中元素的个数;然后跟M个[0,10 9 ]区间内的整数。
之后一行给出一个正整数K(≤2000),随后K行,每行对应一对需要计算相似度的集合的编号(集合从1到N编号)。数字间以空格分隔。
输出格式:
对每一对需要计算的集合,在一行中输出它们的相似度,为保留小数点后2位的百分比数字。
输入样例:
3
3 99 87 101
4 87 101 5 87
7 99 101 18 5 135 18 99
2
1 2
1 3
输出样例:
50.00%
33.33%
AC代码
#include
#include
#include
#include
#include
#include
#include
using namespace std;
setq[55];
int main(){
int n;scanf("%d",&n);
for(int i = 1;i <= n;i ++){
int k;scanf("%d",&k);
for(int j = 1;j <= k;j ++){
int s;scanf("%d",&s);
q[i].insert(s);
}
}
int m;scanf("%d",&m);
while(m --){
int a,b;
scanf("%d%d",&a,&b);
float ans1 = 0,ans2 = 0;
for(auto it : q[a]){
if(q[b].find(it) != q[b].end())
ans1 ++;
}
ans2 = q[a].size() + q[b].size() - ans1;
printf("%.2lf%%\n",ans1 * 100 / ans2);
}
return 0;
}
L2-006 树的遍历 (25 分)
给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列。这里假设键值都是互不相等的正整数。
输入格式:
输入第一行给出一个正整数N(≤30),是二叉树中结点的个数。第二行给出其后序遍历序列。第三行给出其中序遍历序列。数字间以空格分隔。
输出格式:
在一行中输出该树的层序遍历的序列。数字间以1个空格分隔,行首尾不得有多余空格。
输入样例:
7
2 3 1 5 7 6 4
1 2 3 4 5 6 7
输出样例:
4 1 6 3 5 7 2
思路
https://blog.csdn.net/gpc_123/article/details/124161819?spm=1001.2014.3001.5501
先用两个数组pre和in数组将后续和中序存起来,然后再利用递归把大问题化成小问题,因为后序是LRD所以最后一个一定是根节点,在中序LDR里面找到这个根节点之后,左边的就是在根节点左子树上的结点,右边的就是在根节点右子树上的结点,再利用数组l,r把根节点的左右结点存起来
AC代码
#include
#include L2-007 家庭房产 (25 分)
给定每个人的家庭成员和其自己名下的房产,请你统计出每个家庭的人口数、人均房产面积及房产套数。
输入格式:
输入第一行给出一个正整数N(≤1000),随后N行,每行按下列格式给出一个人的房产:
编号 父 母 k 孩子1 … 孩子k 房产套数 总面积
其中编号是每个人独有的一个4位数的编号;父和母分别是该编号对应的这个人的父母的编号(如果已经过世,则显示-1);k(0≤k≤5)是该人的子女的个数;孩子i是其子女的编号。
输出格式:
首先在第一行输出家庭个数(所有有亲属关系的人都属于同一个家庭)。随后按下列格式输出每个家庭的信息:
家庭成员的最小编号 家庭人口数 人均房产套数 人均房产面积
其中人均值要求保留小数点后3位。家庭信息首先按人均面积降序输出,若有并列,则按成员编号的升序输出。
输入样例:
10
6666 5551 5552 1 7777 1 100
1234 5678 9012 1 0002 2 300
8888 -1 -1 0 1 1000
2468 0001 0004 1 2222 1 500
7777 6666 -1 0 2 300
3721 -1 -1 1 2333 2 150
9012 -1 -1 3 1236 1235 1234 1 100
1235 5678 9012 0 1 50
2222 1236 2468 2 6661 6662 1 300
2333 -1 3721 3 6661 6662 6663 1 100
输出样例:
3
8888 1 1.000 1000.000
0001 15 0.600 100.000
5551 4 0.750 100.000
思路
AC代码
#include
#define IOS std::ios::sync_with_stdio(false);std::cin.tie(0);
using namespace std;
const int N =1e4 + 5;
int cnt = 0, k;
struct data{
int id,fa,mom,num,area;
int child[10];
}a[N];
struct node{
int id,people;
double num,area;
bool flag = false;
}b[N];
bool vis[N];
int pre[N];
bool cmp(node a,node b){
if(a.area != b.area)
return a.area > b.area;
return a.id < b.id;
}
int find(int x){
if(x != pre[x]) pre[x] = find(pre[x]);
return pre[x];
}
void merge(int x,int y){
int fx = find(x);
int fy = find(y);
if(fx < fy) pre[fy] = fx;
else pre[fx] = fy;
}
int main(){
IOS;
int n;cin >> n;
for(int i = 0;i < N;i ++) pre[i] = i;
for(int i = 0;i < n;i ++){
cin >> a[i].id >> a[i].fa >> a[i].mom >> k;
vis[a[i].id] = 1;
if(a[i].fa != -1){
merge(a[i].id,a[i].fa);
vis[a[i].fa] = 1;
}
if(a[i].mom != -1){
merge(a[i].id,a[i].mom);
vis[a[i].mom] = 1;
}
for(int j = 0;j < k;j ++){
cin >> a[i].child[j];
vis[a[i].child[j]] = 1;
merge(a[i].child[j],a[i].id);
}
cin >> a[i].num >> a[i].area;
}
for(int i = 0;i < n;i ++){
int id = find(a[i].id);
b[id].id = id;
b[id].num += a[i].num;
b[id].area += a[i].area;
b[id].flag = true;
}
for(int i = 0;i < N;i ++){
if(vis[i]) b[find(i)].people ++;
if(b[i].flag) cnt++;
}
for(int i = 0;i < N;i ++){
if(b[i].flag){
b[i].num =1.0 * b[i].num / b[i].people ;
b[i].area = 1.0 * b[i].area / b[i].people;
}
}
sort(b,b+N,cmp);
cout << cnt << endl;
for(int i=0; i L2-008 最长对称子串 (25 分)
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。
输入格式:
输入在一行中给出长度不超过1000的非空字符串。
输出格式:
在一行中输出最长对称子串的长度。
输入样例:
Is PAT&TAP symmetric?
输出样例:
11
思路
暴力枚举
AC代码
#include
#include
#include
using namespace std;
int main() {
string s;
getline(cin,s);//这个是整行读入 cin是读入到第一个空格处
int x=1;
for(int i=0; i=i; j--) {
int left=i,right=j;
while(left<=right&&s[left++]==s[right--]) {
if(left>right)
x=max(x,j-i+1);
}
}
}
cout< L2-009 抢红包 (25 分)
没有人没抢过红包吧…… 这里给出N个人之间互相发红包、抢红包的记录,请你统计一下他们抢红包的收获。
输入格式:
输入第一行给出一个正整数N(≤10 4 ),即参与发红包和抢红包的总人数,则这些人从1到N编号。随后N行,第i行给出编号为i的人发红包的记录,格式如下:
KN 1 P 1 ⋯N K P K
其中K(0≤K≤20)是发出去的红包个数,N i 是抢到红包的人的编号,P i (>0)是其抢到的红包金额(以分为单位)。注意:对于同一个人发出的红包,每人最多只能抢1次,不能重复抢。
输出格式:
按照收入金额从高到低的递减顺序输出每个人的编号和收入金额(以元为单位,输出小数点后2位)。每个人的信息占一行,两数字间有1个空格。如果收入金额有并列,则按抢到红包的个数递减输出;如果还有并列,则按个人编号递增输出。
输入样例:
10
3 2 22 10 58 8 125
5 1 345 3 211 5 233 7 13 8 101
1 7 8800
2 1 1000 2 1000
2 4 250 10 320
6 5 11 9 22 8 33 7 44 10 55 4 2
1 3 8800
2 1 23 2 123
1 8 250
4 2 121 4 516 7 112 9 10
输出样例:
1 11.63
2 3.63
8 3.63
3 2.11
7 1.69
6 -1.67
9 -2.18
10 -3.26
5 -3.26
4 -12.32
思路 :
AC代码
#include
#include
#include
using namespace std;
struct X{
int id,sum,num;
};
bool cmp(X a,X b){
if(a.sum!=b.sum){
return a.sum>b.sum;
}else if(a.num!=b.num){
return a.num>b.num;
}else{
return a.id v(n+1);
for(int i=1;i<=n;i++){
v[i].id = i;
scanf("%d",&k);
for(int j=0;j L2-010 排座位 (25 分)
布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位。无论如何,总不能把两个死对头排到同一张宴会桌旁!这个艰巨任务现在就交给你,对任何一对客人,请编写程序告诉主人他们是否能被安排同席。
输入格式:
输入第一行给出3个正整数:N(≤100),即前来参宴的宾客总人数,则这些人从1到N编号;M为已知两两宾客之间的关系数;K为查询的条数。随后M行,每行给出一对宾客之间的关系,格式为:宾客1 宾客2 关系,其中关系为1表示是朋友,-1表示是死对头。注意两个人不可能既是朋友又是敌人。最后K行,每行给出一对需要查询的宾客编号。
这里假设朋友的朋友也是朋友。但敌人的敌人并不一定就是朋友,朋友的敌人也不一定是敌人。只有单纯直接的敌对关系才是绝对不能同席的。
输出格式:
对每个查询输出一行结果:如果两位宾客之间是朋友,且没有敌对关系,则输出No problem;如果他们之间并不是朋友,但也不敌对,则输出OK;如果他们之间有敌对,然而也有共同的朋友,则输出OK but…;如果他们之间只有敌对关系,则输出No way。
输入样例:
7 8 4
5 6 1
2 7 -1
1 3 1
3 4 1
6 7 -1
1 2 1
1 4 1
2 3 -1
3 4
5 7
2 3
7 2
输出样例:
No problem
OK
OK but…
No way
思路 :
朋友的朋友是朋友,敌人的敌人不是朋友,所以前者用并查集维护,后者用数组模拟关系即可
AC代码
#include
#include
#include
using namespace std;
int pre[110];
int enemy[110][110];
int find(int x){
if(x != pre[x])
return pre[x] = find(pre[x]);
return pre[x];
}
void merge(int a,int b){
int fx = find(a);
int fy = find(b);
if(fx != fy){
pre[fx] = fy;
}
}
int main(){
int n,m,k,a,b,c;
scanf("%d %d %d",&n,&m,&k);
for(int i=1;i<=n;i++) pre[i] = i;
for(int i=0;i L2-011 玩转二叉树 (25 分)
给定一棵二叉树的中序遍历和前序遍历,请你先将树做个镜面反转,再输出反转后的层序遍历的序列。所谓镜面反转,是指将所有非叶结点的左右孩子对换。这里假设键值都是互不相等的正整数。
输入格式:
输入第一行给出一个正整数N(≤30),是二叉树中结点的个数。第二行给出其中序遍历序列。第三行给出其前序遍历序列。数字间以空格分隔。
输出格式:
在一行中输出该树反转后的层序遍历的序列。数字间以1个空格分隔,行首尾不得有多余空格。
输入样例:
7
1 2 3 4 5 6 7
4 1 3 2 6 5 7
输出样例:
4 6 1 7 5 3 2
#include
using namespace std;
int mid[1000],in[1000],Left[1000],Right[1000];
int n;
int build(int L1,int R1,int L2,int R2)
{
if(L1>R1)return 0;
int root=in[L2];
int pos=L1;
while(mid[pos]!=root)pos++;
int cnt=pos-L1;
Left[root]=build(L1,pos-1,L2+1,L2+cnt);
Right[root]=build(pos+1,R1,L2+cnt+1,R2);
return root;
}
void level()
{
queueq;
q.push(in[1]);
int f=0;
while(!q.empty())
{
int u=q.front();q.pop();
if(!f)printf("%d",u),f=1;
else printf(" %d",u);
if(Right[u])q.push(Right[u]);
if(Left[u])q.push(Left[u]);
}
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++)cin>>mid[i];
for(int i=1;i<=n;i++)cin>>in[i];
int root=build(1,n,1,n);
level();
return 0;
}
L2-012 关于堆的判断 (25 分)
将一系列给定数字顺序插入一个初始为空的小顶堆H[]。随后判断一系列相关命题是否为真。命题分下列几种:
x is the root:x是根结点;
x and y are siblings:x和y是兄弟结点;
x is the parent of y:x是y的父结点;
x is a child of y:x是y的一个子结点。
输入格式:
每组测试第1行包含2个正整数N(≤ 1000)和M(≤ 20),分别是插入元素的个数、以及需要判断的命题数。下一行给出区间[−10000,10000]内的N个要被插入一个初始为空的小顶堆的整数。之后M行,每行给出一个命题。题目保证命题中的结点键值都是存在的。
输出格式:
对输入的每个命题,如果其为真,则在一行中输出T,否则输出F。
输入样例:
5 4
46 23 26 24 10
24 is the root
26 and 23 are siblings
46 is the parent of 23
23 is a child of 10
输出样例:
F
T
F
T
AC代码
#include
#define Inf 0x3f3f3f
const int N = 1005;
using namespace std;
int n, m, cnt, no;
int ans[N];
map p;
void create(int x){//堆的建立
ans[++cnt] = x;
int t = cnt;
while(t>1 && ans[t/2]>ans[t]){
swap(ans[t/2], ans[t]);
t/=2;
}
ans[t] = x;
}
int main(){
cin >> n >> m;
for(int i = 1; i<= n; i ++){
cin >> no;
create(no);
}
for(int i = 1; i <= n; i ++)//记录堆下标
p[ans[i]] = i;
while(m--){
string str;
int x, y;
cin >> x >> str;
if(str[0]=='a'){ //兄弟节点判断 x and y are siblings
cin >> y >> str >> str;
if(p[x]/2==p[y]/2)
cout << "T" << endl;
else
cout << "F" << endl;
}else{
cin >> str >> str;
if(str[0] == 'c'){ //子节点判断: x is a child of y
cin >> str >> y;
if(p[x]/2==p[y])
cout << "T" << endl;
else
cout << "F" << endl;
}else if(str[0]=='r'){//根节点判断: x is the root
if(p[x]==1)
cout << "T" << endl;
else
cout << "F" << endl;
}else if(str[0]=='p'){//父节点判断: x is the parent of y
cin >> str >> y;
if(p[x]==p[y]/2)
cout << "T" << endl;
else
cout << "F" << endl;
}
}
}
return 0;
}
L2-013 红色警报 (25 分)
战争中保持各个城市间的连通性非常重要。本题要求你编写一个报警程序,当失去一个城市导致国家被分裂为多个无法连通的区域时,就发出红色警报。注意:若该国本来就不完全连通,是分裂的k个区域,而失去一个城市并不改变其他城市之间的连通性,则不要发出警报。
输入格式:
输入在第一行给出两个整数N(0 < N ≤ 500)和M(≤ 5000),分别为城市个数(于是默认城市从0到N-1编号)和连接两城市的通路条数。随后M行,每行给出一条通路所连接的两个城市的编号,其间以1个空格分隔。在城市信息之后给出被攻占的信息,即一个正整数K和随后的K个被攻占的城市的编号。
注意:输入保证给出的被攻占的城市编号都是合法的且无重复,但并不保证给出的通路没有重复。
输出格式:
对每个被攻占的城市,如果它会改变整个国家的连通性,则输出Red Alert: City k is lost!,其中k是该城市的编号;否则只输出City k is lost.即可。如果该国失去了最后一个城市,则增加一行输出Game Over.。
输入样例:
5 4
0 1
1 3
3 0
0 4
5
1 2 0 4 3
输出样例:
City 1 is lost.
City 2 is lost.
Red Alert: City 0 is lost!
City 4 is lost.
City 3 is lost.
Game Over.
思路 ;
并查集思想
AC代码
#include
#include
#include
using namespace std;
const int N = 5200;
bool vis[N];
int pre[N];
struct node {
int x,y;
}q[N];
int find(int x){
if(pre[x] != x)
return pre[x] = find(pre[x]);
return pre[x];
}
void merge(int x,int y){
int fx = find(x);
int fy = find(y);
if(fx != fy)
pre[fx] = fy;
}
int n,m;
int main(){
scanf("%d%d", &n, &m);
for(int i = 0;i < n;i ++) pre[i] = i;
for(int i = 0;i < m;i ++){
cin >> q[i].x >> q[i].y;
merge(q[i].x,q[i].y);
}
for(int i=0;i L2-014 列车调度 (25 分)
火车站的列车调度铁轨的结构如下图所示。
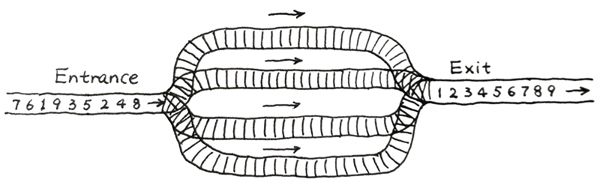
两端分别是一条入口(Entrance)轨道和一条出口(Exit)轨道,它们之间有N条平行的轨道。每趟列车从入口可以选择任意一条轨道进入,最后从出口离开。在图中有9趟列车,在入口处按照{8,4,2,5,3,9,1,6,7}的顺序排队等待进入。如果要求它们必须按序号递减的顺序从出口离开,则至少需要多少条平行铁轨用于调度?
输入格式:
输入第一行给出一个整数N (2 ≤ N ≤10 5 ),下一行给出从1到N的整数序号的一个重排列。数字间以空格分隔。
输出格式:
在一行中输出可以将输入的列车按序号递减的顺序调离所需要的最少的铁轨条数。
输入样例:
9
8 4 2 5 3 9 1 6 7
输出样例:
4
思路 :
最长上升子序列
AC代码
#include
#include
#include
using namespace std;
const int N = 1e5 + 5;
int dp1[N],a[N];
int n;
int main(){
cin >> n;
for(int i = 1;i <= n;i ++) cin >> a[i];
int ans = 1;
dp1[ans] = a[1];
for(int i = 2;i <= n;i ++){
if(a[i] > dp1[ans])
dp1[++ans] = a[i];
else{
int temp = upper_bound(dp1 + 1,dp1 + ans + 1,a[i]) - dp1;
dp1[temp] = a[i];
}
}
cout << ans << endl;
return 0;
}
L2-015 互评成绩 (25 分)
学生互评作业的简单规则是这样定的:每个人的作业会被k个同学评审,得到k个成绩。系统需要去掉一个最高分和一个最低分,将剩下的分数取平均,就得到这个学生的最后成绩。本题就要求你编写这个互评系统的算分模块。
输入格式:
输入第一行给出3个正整数N(3 < N ≤10 4 ,学生总数)、k(3 ≤ k ≤ 10,每份作业的评审数)、M(≤ 20,需要输出的学生数)。随后N行,每行给出一份作业得到的k个评审成绩(在区间[0, 100]内),其间以空格分隔。
输出格式:
按非递减顺序输出最后得分最高的M个成绩,保留小数点后3位。分数间有1个空格,行首尾不得有多余空格。
输入样例:
6 5 3
88 90 85 99 60
67 60 80 76 70
90 93 96 99 99
78 65 77 70 72
88 88 88 88 88
55 55 55 55 55
输出样例:
87.667 88.000 96.000
思路 :
AC代码
#include
using namespace std;
int main()
{
int n,k,m;
double ch[10005][15];
double sum[10005]={0};
double ave[10005];
cin>>n>>k>>m;
for(int i=0;i>ch[i][j];
sum[i]+=ch[i][j];
}
sort(ch[i],ch[i]+k);
sum[i]=sum[i]-ch[i][0]-ch[i][k-1];
ave[i]=sum[i]/(double)(k-2);
}
sort(ave,ave+n);
for(int t=n-m;t L2-016 愿天下有情人都是失散多年的兄妹 (25 分)
呵呵。大家都知道五服以内不得通婚,即两个人最近的共同祖先如果在五代以内(即本人、父母、祖父母、曾祖父母、高祖父母)则不可通婚。本题就请你帮助一对有情人判断一下,他们究竟是否可以成婚?
输入格式:
输入第一行给出一个正整数N(2 ≤ N ≤10 4 ),随后N行,每行按以下格式给出一个人的信息:
本人ID 性别 父亲ID 母亲ID
其中ID是5位数字,每人不同;性别M代表男性、F代表女性。如果某人的父亲或母亲已经不可考,则相应的ID位置上标记为-1。
接下来给出一个正整数K,随后K行,每行给出一对有情人的ID,其间以空格分隔。
注意:题目保证两个人是同辈,每人只有一个性别,并且血缘关系网中没有乱伦或隔辈成婚的情况。
输出格式:
对每一对有情人,判断他们的关系是否可以通婚:如果两人是同性,输出Never Mind;如果是异性并且关系出了五服,输出Yes;如果异性关系未出五服,输出No。
输入样例:
24
00001 M 01111 -1
00002 F 02222 03333
00003 M 02222 03333
00004 F 04444 03333
00005 M 04444 05555
00006 F 04444 05555
00007 F 06666 07777
00008 M 06666 07777
00009 M 00001 00002
00010 M 00003 00006
00011 F 00005 00007
00012 F 00008 08888
00013 F 00009 00011
00014 M 00010 09999
00015 M 00010 09999
00016 M 10000 00012
00017 F -1 00012
00018 F 11000 00013
00019 F 11100 00018
00020 F 00015 11110
00021 M 11100 00020
00022 M 00016 -1
00023 M 10012 00017
00024 M 00022 10013
9
00021 00024
00019 00024
00011 00012
00022 00018
00001 00004
00013 00016
00017 00015
00019 00021
00010 00011
输出样例:
Never Mind
Yes
Never Mind
No
Yes
No
Yes
No
No
思路 :
深搜5代
AC代码 :
#include
#include
using namespace std;
const int maxn=100010;
bool flag=1;
int vis[maxn]={0};
struct node{
char gender;
int father,mother;
node(){
father=-1;
mother=-1;
}
}node[maxn];
void judge(int idx,int k){
if(idx==-1||k==6){
return ;
}
vis[idx]++;
if(vis[idx]==2)
flag=0;
judge(node[idx].father,k+1);
judge(node[idx].mother,k+1);
}
int main(){
int n,m;
cin>>n;
for(int i=0;i>id>>gender>>father>>mother;
node[id].gender=gender;
node[id].father=father;
node[id].mother=mother;
if(father!=-1)node[father].gender='M';
if(mother!=-1)node[mother].gender='F';
}
cin>>m;
for(int i=0;i>x>>y;
if(node[x].gender==node[y].gender)
cout<<"Never Mind"< L2-017 人以群分 (25 分)
社交网络中我们给每个人定义了一个“活跃度”,现希望根据这个指标把人群分为两大类,即外向型(outgoing,即活跃度高的)和内向型(introverted,即活跃度低的)。要求两类人群的规模尽可能接近,而他们的总活跃度差距尽可能拉开。
输入格式:
输入第一行给出一个正整数N(2≤N≤10 5 )。随后一行给出N个正整数,分别是每个人的活跃度,其间以空格分隔。题目保证这些数字以及它们的和都不会超过2 31 。
输出格式:
按下列格式输出:
Outgoing #: N1
Introverted #: N2
Diff = N3
其中N1是外向型人的个数;N2是内向型人的个数;N3是两群人总活跃度之差的绝对值。
输入样例1:
10
23 8 10 99 46 2333 46 1 666 555
输出样例1:
Outgoing #: 5
Introverted #: 5
Diff = 3611
输入样例2:
13
110 79 218 69 3721 100 29 135 2 6 13 5188 85
输出样例2:
Outgoing #: 7
Introverted #: 6
Diff = 9359
#include
using namespace std;
//#define int long long
#define fo(i,a,b) for(int i=a;i>N;
fo(i,0,N){
cin>>a[i];
}
sort(a,a+N);
int half=N/2;
int s1=0,s2=0;
fo(i,0,half) s1+=a[i];
fo(i,half,N) s2+=a[i];
printf("Outgoing #: %d\nIntroverted #: %d\nDiff = %d\n",N-half,half,s2-s1);
return 0;
}
L2-018 多项式A除以B (25 分)
这仍然是一道关于A/B的题,只不过A和B都换成了多项式。你需要计算两个多项式相除的商Q和余R,其中R的阶数必须小于B的阶数。
输入格式:
输入分两行,每行给出一个非零多项式,先给出A,再给出B。每行的格式如下:
N e[1] c[1] … e[N] c[N]
其中N是该多项式非零项的个数,e[i]是第i个非零项的指数,c[i]是第i个非零项的系数。各项按照指数递减的顺序给出,保证所有指数是各不相同的非负整数,所有系数是非零整数,所有整数在整型范围内。
输出格式:
分两行先后输出商和余,输出格式与输入格式相同,输出的系数保留小数点后1位。同行数字间以1个空格分隔,行首尾不得有多余空格。注意:零多项式是一个特殊多项式,对应输出为0 0 0.0。但非零多项式不能输出零系数(包括舍入后为0.0)的项。在样例中,余多项式其实有常数项-1/27,但因其舍入后为0.0,故不输出。
输入样例:
4 4 1 2 -3 1 -1 0 -1
3 2 3 1 -2 0 1
输出样例:
3 2 0.3 1 0.2 0 -1.0
1 1 -3.1
思路 :
多项式除法
https://blog.csdn.net/qq_37424623/article/details/121446565
AC代码
#include
using namespace std;
const int N=1e5+5;
int b[N];
double a[N],c[N],d[N];
int main()
{
int n,m,f1,n1=0,n2=0;
scanf("%d",&n);
for(int i=0,x; i=b[0]; i--)
{
t=i-b[0];
c[t]=a[i]/d[0];
for(int j=0; m>j; j++)a[t+b[j]]=a[t+b[j]]-c[t]*d[j];
}
for(int i=f1; i>=0; i--)
{
if(fabs(a[i])>=0.05)n2++;
if(fabs(c[i])>=0.05)n1++;
}
printf("%d",n1);
for(int i=f1; i>=0; i--)if(fabs(c[i])>=0.05)printf(" %d %.1f",i,c[i]);
if(n1==0)printf(" 0 0.0");
printf("\n");
printf("%d",n2);
for(int i=f1; i>=0; i--)if(fabs(a[i])>=0.05)printf(" %d %.1f",i,a[i]);
if(n2==0)printf(" 0 0.0");
return 0;
}
L2-019 悄悄关注 (25 分)
新浪微博上有个“悄悄关注”,一个用户悄悄关注的人,不出现在这个用户的关注列表上,但系统会推送其悄悄关注的人发表的微博给该用户。现在我们来做一回网络侦探,根据某人的关注列表和其对其他用户的点赞情况,扒出有可能被其悄悄关注的人。
输入格式:
输入首先在第一行给出某用户的关注列表,格式如下:
人数N 用户1 用户2 …… 用户N
其中N是不超过5000的正整数,每个用户i(i=1, …, N)是被其关注的用户的ID,是长度为4位的由数字和英文字母组成的字符串,各项间以空格分隔。
之后给出该用户点赞的信息:首先给出一个不超过10000的正整数M,随后M行,每行给出一个被其点赞的用户ID和对该用户的点赞次数(不超过1000),以空格分隔。注意:用户ID是一个用户的唯一身份标识。题目保证在关注列表中没有重复用户,在点赞信息中也没有重复用户。
输出格式:
我们认为被该用户点赞次数大于其点赞平均数、且不在其关注列表上的人,很可能是其悄悄关注的人。根据这个假设,请你按用户ID字母序的升序输出可能是其悄悄关注的人,每行1个ID。如果其实并没有这样的人,则输出“Bing Mei You”。
输入样例1:
10 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao
8
Magi 50
Pota 30
LLao 3
Ammy 48
Dave 15
GAO3 31
Zoro 1
Cath 60
输出样例1:
Ammy
Cath
Pota
输入样例2:
11 GAO3 Magi Zha1 Sen1 Quan FaMK LSum Eins FatM LLao Pota
7
Magi 50
Pota 30
LLao 48
Ammy 3
Dave 15
GAO3 31
Zoro 29
输出样例2:
Bing Mei You
#include
#include
#include L2-020 功夫传人 (25 分)
一门武功能否传承久远并被发扬光大,是要看缘分的。一般来说,师傅传授给徒弟的武功总要打个折扣,于是越往后传,弟子们的功夫就越弱…… 直到某一支的某一代突然出现一个天分特别高的弟子(或者是吃到了灵丹、挖到了特别的秘笈),会将功夫的威力一下子放大N倍 —— 我们称这种弟子为“得道者”。
这里我们来考察某一位祖师爷门下的徒子徒孙家谱:假设家谱中的每个人只有1位师傅(除了祖师爷没有师傅);每位师傅可以带很多徒弟;并且假设辈分严格有序,即祖师爷这门武功的每个第i代传人只能在第i-1代传人中拜1个师傅。我们假设已知祖师爷的功力值为Z,每向下传承一代,就会减弱r%,除非某一代弟子得道。现给出师门谱系关系,要求你算出所有得道者的功力总值。
输入格式:
输入在第一行给出3个正整数,分别是:N(≤10 5 )——整个师门的总人数(于是每个人从0到N−1编号,祖师爷的编号为0);Z——祖师爷的功力值(不一定是整数,但起码是正数);r ——每传一代功夫所打的折扣百分比值(不超过100的正数)。接下来有N行,第i行(i=0,⋯,N−1)描述编号为i的人所传的徒弟,格式为:
K i ID[1] ID[2] ⋯ ID[K i ]其中K i 是徒弟的个数,后面跟的是各位徒弟的编号,数字间以空格间隔。K i
为零表示这是一位得道者,这时后面跟的一个数字表示其武功被放大的倍数。
输出格式:
在一行中输出所有得道者的功力总值,只保留其整数部分。题目保证输入和正确的输出都不超过10 10。
输入样例:
10 18.0 1.00
3 2 3 5
1 9
1 4
1 7
0 7
2 6 1
1 8
0 9
0 4
0 3
输出样例:
404
AC代码
#include
#include
using namespace std;
int n;
double r,result = 0;
struct people {
int king = 1;
vector child;
}person[100000];
void search(int i, double k) {
if (person[i].king != 1)
result += k *= person[i].king;
for (auto& it : person[i].child)
search(it,k*(100 - r) / 100);
}
int main() {
int k, t;
double z;
scanf("%d%lf%lf", &n, &z, &r);
for (int i = 0; i < n; i++) {
scanf("%d", &k);
if (!k)
scanf("%d", &person[i].king);
for (int j = 0; j < k; j++) {
scanf("%d", &t);
person[i].child.push_back(t);
}
}
search(0, z);
printf("%d", (int)result);
return 0;
}
L2-021 点赞狂魔 (25 分)
微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持。每篇博文都有一些刻画其特性的标签,而你点赞的博文的类型,也间接刻画了你的特性。然而有这么一种人,他们会通过给自己看到的一切内容点赞来狂刷存在感,这种人就被称为“点赞狂魔”。他们点赞的标签非常分散,无法体现出明显的特性。本题就要求你写个程序,通过统计每个人点赞的不同标签的数量,找出前3名点赞狂魔。
输入格式:
输入在第一行给出一个正整数N(≤100),是待统计的用户数。随后N行,每行列出一位用户的点赞标签。格式为“Name K F 1 ⋯F K ”,其中Name是不超过8个英文小写字母的非空用户名,1≤K≤1000,F i
(i=1,⋯,K)是特性标签的编号,我们将所有特性标签从 1 到 10 7 编号。数字间以空格分隔。
输出格式:
统计每个人点赞的不同标签的数量,找出数量最大的前3名,在一行中顺序输出他们的用户名,其间以1个空格分隔,且行末不得有多余空格。如果有并列,则输出标签出现次数平均值最小的那个,题目保证这样的用户没有并列。若不足3人,则用-补齐缺失,例如mike jenny -就表示只有2人。
输入样例:
5
bob 11 101 102 103 104 105 106 107 108 108 107 107
peter 8 1 2 3 4 3 2 5 1
chris 12 1 2 3 4 5 6 7 8 9 1 2 3
john 10 8 7 6 5 4 3 2 1 7 5
jack 9 6 7 8 9 10 11 12 13 14
输出样例:
jack chris john
AC代码
#include
using namespace std;
struct node
{
char name[10];
int num;
set s;
}person[200];
bool cmp(struct node a,struct node b)
{
if(a.s.size()!=b.s.size())
return a.s.size()>b.s.size();
else
{
int c=a.s.size(),d=b.s.size();
return 1.0*c/a.num>1.0*d/b.num;
}
}
int main()
{
int i,j,n,m,k,t;
scanf("%d",&n);
for(i=0;i=n) printf(" -");
else
{
if(i==0) printf("%s",person[i].name);
else printf(" %s",person[i].name);
}
}
return 0;
}
L2-022 重排链表 (25 分)
给定一个单链表 L 1 →L 2 →⋯→L n−1 →L n ,请编写程序将链表重新排列为 L n →L 1 →L n−1 →L 2
→⋯。例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2→4→3。
输入格式:
每个输入包含1个测试用例。每个测试用例第1行给出第1个结点的地址和结点总个数,即正整数N (≤10 5
)。结点的地址是5位非负整数,NULL地址用−1表示。
接下来有N行,每行格式为:
Address Data Next
其中Address是结点地址;Data是该结点保存的数据,为不超过10
5
的正整数;Next是下一结点的地址。题目保证给出的链表上至少有两个结点。
输出格式:
对每个测试用例,顺序输出重排后的结果链表,其上每个结点占一行,格式与输入相同。
输入样例:
00100 6
00000 4 99999
00100 1 12309
68237 6 -1
33218 3 00000
99999 5 68237
12309 2 33218
输出样例:
68237 6 00100
00100 1 99999
99999 5 12309
12309 2 00000
00000 4 33218
33218 3 -1
AC代码
#include
#include
#define foreach(a,b,c) for((a)=(b); (a)<(c); (a)++)
using namespace std;
struct List{
int current;
int data;
int next;
};
List total[100001];
int main(){
int startAddress,N,i,address,data,next,index,length,pos;
scanf("%d %d",&startAddress, &N);
foreach(i,0,N){
scanf("%d %d %d",&address,&data,&next);
total[address].next = next;
total[address].data = data;
total[address].current = address;
}
vector totalArray;
do{
totalArray.push_back(total[startAddress]);
startAddress = total[startAddress].next;
}while(startAddress!=-1);
index = 0;
length = totalArray.size()-1;
printf("%05d %d ",totalArray[length].current,totalArray[length].data);
foreach(i,0,length){
if(i%2==0){
pos = index;
index ++;
}else{
pos = length-index;
}
printf("%05d\n",totalArray[pos].current);
printf("%05d %d ",totalArray[pos].current,totalArray[pos].data);
}
printf("-1\n");
return 0;
}
L2-023 图着色问题 (25 分)
图着色问题是一个著名的NP完全问题。给定无向图G=(V,E),问可否用K种颜色为V中的每一个顶点分配一种颜色,使得不会有两个相邻顶点具有同一种颜色?
但本题并不是要你解决这个着色问题,而是对给定的一种颜色分配,请你判断这是否是图着色问题的一个解。
输入格式: 输出格式: 输入样例: 思路 : 在一个社区里,每个人都有自己的小圈子,还可能同时属于很多不同的朋友圈。我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。 输入格式: 其中K是小圈子里的人数,P[i](i=1,⋯,K)是小圈子里每个人的编号。这里所有人的编号从1开始连续编号,最大编号不会超过10 4 。之后一行给出一个非负整数Q(≤10 4 ),是查询次数。随后Q行,每行给出一对被查询的人的编号。 输出格式: 输入样例: 思路 : 分而治之,各个击破是兵家常用的策略之一。在战争中,我们希望首先攻下敌方的部分城市,使其剩余的城市变成孤立无援,然后再分头各个击破。为此参谋部提供了若干打击方案。本题就请你编写程序,判断每个方案的可行性。 输入格式: Np v[1] v[2] … v[Np] 输出格式: 输入样例: 思路 : 本题给定一个庞大家族的家谱,要请你给出最小一辈的名单。 输入格式: 输出格式: 输入样例: 对于在中国大学MOOC(http://www.icourse163.org/ )学习“数据结构”课程的学生,想要获得一张合格证书,总评成绩必须达到 60 分及以上,并且有另加福利:总评分在 [G, 100] 区间内者,可以得到 50 元 PAT 代金券;在 [60, G) 区间内者,可以得到 20 元PAT代金券。全国考点通用,一年有效。同时任课老师还会把总评成绩前 K 名的学生列入课程“名人堂”。本题就请你编写程序,帮助老师列出名人堂的学生,并统计一共发出了面值多少元的 PAT 代金券。 输入格式: 输出格式: 输入样例: AC代码 古人云:秀恩爱,分得快。 互联网上每天都有大量人发布大量照片,我们通过分析这些照片,可以分析人与人之间的亲密度。如果一张照片上出现了 K 个人,这些人两两间的亲密度就被定义为 1/K。任意两个人如果同时出现在若干张照片里,他们之间的亲密度就是所有这些同框照片对应的亲密度之和。下面给定一批照片,请你分析一对给定的情侣,看看他们分别有没有亲密度更高的异性朋友? 输入格式: K P[1] … P[K] 输出格式: 输入样例 1: 对一个十进制数的各位数字做一次平方和,称作一次迭代。如果一个十进制数能通过若干次迭代得到 1,就称该数为幸福数。1 是一个幸福数。此外,例如 19 经过 1 次迭代得到 82,2 次迭代后得到 68,3 次迭代后得到 100,最后得到 1。则 19 就是幸福数。显然,在一个幸福数迭代到 1 的过程中经过的数字都是幸福数,它们的幸福是依附于初始数字的。例如 82、68、100 的幸福是依附于 19 的。而一个特立独行的幸福数,是在一个有限的区间内不依附于任何其它数字的;其独立性就是依附于它的的幸福数的个数。如果这个数还是个素数,则其独立性加倍。例如 19 在区间[1, 100] 内就是一个特立独行的幸福数,其独立性为 2×4=8。 另一方面,如果一个大于1的数字经过数次迭代后进入了死循环,那这个数就不幸福。例如 29 迭代得到 85、89、145、42、20、4、16、37、58、89、…… 可见 89 到 58 形成了死循环,所以 29 就不幸福。 本题就要求你编写程序,列出给定区间内的所有特立独行的幸福数和它的独立性。 输入格式: 输出格式: 如果区间内没有幸福数,则在一行中输出 SAD。 输入样例 1: 输入样例 2: 思路 : AC代码 2018年世界杯,冰岛队因1:1平了强大的阿根廷队而一战成名。好事者发现冰岛人的名字后面似乎都有个“松”(son),于是有网友科普如下: 冰岛人沿用的是维京人古老的父系姓制,孩子的姓等于父亲的名加后缀,如果是儿子就加 sson,女儿则加 sdottir。因为冰岛人口较少,为避免近亲繁衍,本地人交往前先用个 App 查一下两人祖宗若干代有无联系。本题就请你实现这个 App 的功能。 输入格式: 随后一行给出正整数 M,为查询数量。随后 M 行,每行给出一对人名,格式为:名1 姓1 名2 姓2。注意:这里的姓是不带后缀的。四个字符串均由不超过 20 个小写的英文字母组成。 题目保证不存在两个人是同名的。 输出格式: 若两人为异性,且五代以内无公共祖先,则输出 Yes; 输入样例: 思路 : AC代码 著名的王牌间谍 007 需要执行一次任务,获取敌方的机密情报。已知情报藏在一个地下迷宫里,迷宫只有一个入口,里面有很多条通路,每条路通向一扇门。每一扇门背后或者是一个房间,或者又有很多条路,同样是每条路通向一扇门…… 他的手里有一张表格,是其他间谍帮他收集到的情报,他们记下了每扇门的编号,以及这扇门背后的每一条通路所到达的门的编号。007 发现不存在两条路通向同一扇门。 内线告诉他,情报就藏在迷宫的最深处。但是这个迷宫太大了,他需要你的帮助 —— 请编程帮他找出距离入口最远的那扇门。 输入格式: K D[1] D[2] … D[K] 输出格式: 输入样例: 彩虹瓶的制作过程(并不)是这样的:先把一大批空瓶铺放在装填场地上,然后按照一定的顺序将每种颜色的小球均匀撒到这批瓶子里。 假设彩虹瓶里要按顺序装 N 种颜色的小球(不妨将顺序就编号为 1 到 N)。现在工厂里有每种颜色的小球各一箱,工人需要一箱一箱地将小球从工厂里搬到装填场地。如果搬来的这箱小球正好是可以装填的颜色,就直接拆箱装填;如果不是,就把箱子先码放在一个临时货架上,码放的方法就是一箱一箱堆上去。当一种颜色装填完以后,先看看货架顶端的一箱是不是下一个要装填的颜色,如果是就取下来装填,否则去工厂里再搬一箱过来。 如果工厂里发货的顺序比较好,工人就可以顺利地完成装填。例如要按顺序装填 7 种颜色,工厂按照 7、6、1、3、2、5、4 这个顺序发货,则工人先拿到 7、6 两种不能装填的颜色,将其按照 7 在下、6 在上的顺序堆在货架上;拿到 1 时可以直接装填;拿到 3 时又得临时码放在 6 号颜色箱上;拿到 2 时可以直接装填;随后从货架顶取下 3 进行装填;然后拿到 5,临时码放到 6 上面;最后取了 4 号颜色直接装填;剩下的工作就是顺序从货架上取下 5、6、7 依次装填。 但如果工厂按照 3、1、5、4、2、6、7 这个顺序发货,工人就必须要愤怒地折腾货架了,因为装填完 2 号颜色以后,不把货架上的多个箱子搬下来就拿不到 3 号箱,就不可能顺利完成任务。 另外,货架的容量有限,如果要堆积的货物超过容量,工人也没办法顺利完成任务。例如工厂按照 7、6、5、4、3、2、1 这个顺序发货,如果货架够高,能码放 6 只箱子,那还是可以顺利完工的;但如果货架只能码放 5 只箱子,工人就又要愤怒了…… 本题就请你判断一下,工厂的发货顺序能否让工人顺利完成任务。 输入格式: 随后 K 行,每行给出 N 个数字,是 1 到N 的一个排列,对应工厂的发货顺序。 一行中的数字都以空格分隔。 输出格式: 输入样例: 思路 : stack AC代码 本题要求你为初学数据结构的小伙伴设计一款简单的利用堆栈执行的计算器。如上图所示,计算器由两个堆栈组成,一个堆栈 S 1 存放数字,另一个堆栈 S 2 存放运算符。计算器的最下方有一个等号键,每次按下这个键,计算器就执行以下操作: 输入格式: 第二行给出 N 个绝对值不超过 100 的整数;第三行给出 N−1 个运算符 —— 这里仅考虑 +、-、*、/ 这四种运算。一行中的数字和符号都以空格分隔。 输出格式: 如果执行除法时出现分母为零的非法操作,则在一行中输出:ERROR: X/0,其中 X 是当时的分子。然后结束程序。 输入样例 1: 输出样例 1: 输入样例 2: 输出样例 2: AC代码 为了抗击来势汹汹的 COVID19 新型冠状病毒,全国各地均启动了各项措施控制疫情发展,其中一个重要的环节是口罩的发放。 某市出于给市民发放口罩的需要,推出了一款小程序让市民填写信息,方便工作的开展。小程序收集了各种信息,包括市民的姓名、身份证、身体情况、提交时间等,但因为数据量太大,需要根据一定规则进行筛选和处理,请你编写程序,按照给定规则输出口罩的寄送名单。 输入格式: 接下来 D 块数据,每块给出一天的申请信息。第 i 块数据(i=1,⋯,D)的第一行是两个整数 T i 和 S i(1≤T i,S i ≤1000),表示在第 i 天有 T i 条申请,总共有 S i 个口罩发放名额。随后 T i 行,每行给出一条申请信息,格式如下: 姓名 身份证号 身体情况 提交时间 姓名 是一个长度不超过 10 的不包含空格的非空字符串; 身份证号 必须是 18 位的数字(可以包含前导0); 在输出完发放记录后,你还需要输出有合法记录的、身体状况为 1 的申请人的姓名及身份证号,用空格隔开。顺序按照申请记录中出现的顺序确定,同一个人只需要输出一次。 输入样例: AC代码 一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是完美二叉树。对于深度为 D 的,有 N 个结点的二叉树,若其结点对应于相同深度完美二叉树的层序遍历的前 N 个结点,这样的树就是完全二叉树。 给定一棵完全二叉树的后序遍历,请你给出这棵树的层序遍历结果。 输入格式: 输出格式: 输入样例: 一个旅游景点,如果被带火了的话,就被称为“网红点”。大家来网红点游玩,俗称“打卡”。在各个网红点打卡的快(省)乐(钱)方法称为“攻略”。你的任务就是从一大堆攻略中,找出那个能在每个网红点打卡仅一次、并且路上花费最少的攻略。 输入格式: 再下一行给出一个正整数 K,是待检验的攻略的数量。随后 K 行,每行给出一条待检攻略,格式为: 输出格式: 在第二行中,首先输出那个能在每个网红点打卡仅一次、并且路上花费最少的攻略的序号(从 1 开始),然后输出这个攻略的总路费,其间以一个空格分隔。如果这样的攻略不唯一,则输出序号最小的那个。 题目保证至少存在一个有效攻略,并且总路费不超过 10 9。 输入样例: 第 1 条攻略的总路费是:(0->5) 2 + (5->1) 2 + (1->4) 2 + (4->3) 2 + (3->6) 2 + (6->2) 2 + (2->0) 2 = 14; 第 5 条攻略的总路费同理可算得:1 + 1 + 1 + 2 + 3 + 1 + 2 = 11,是一条更省钱的攻略; 第 7 条攻略的总路费同理可算得:2 + 1 + 1 + 2 + 2 + 2 + 1 = 11,与第 5 条花费相同,但序号较大,所以不输出。 AC代码 一种自动包装机的结构如图 1 所示。首先机器中有 N 条轨道,放置了一些物品。轨道下面有一个筐。当某条轨道的按钮被按下时,活塞向左推动,将轨道尽头的一件物品推落筐中。当 0 号按钮被按下时,机械手将抓取筐顶部的一件物品,放到流水线上。图 2 显示了顺序按下按钮 3、2、3、0、1、2、0 后包装机的状态。 图 2 顺序按下按钮 3、2、3、0、1、2、0 后包装机的状态 一种特殊情况是,因为筐的容量是有限的,当筐已经满了,但仍然有某条轨道的按钮被按下时,系统应强制启动 0 号键,先从筐里抓出一件物品,再将对应轨道的物品推落。此外,如果轨道已经空了,再按对应的按钮不会发生任何事;同样的,如果筐是空的,按 0 号按钮也不会发生任何事。 现给定一系列按钮操作,请你依次列出流水线上的物品。 输入格式: 最后一行给出一系列数字,顺序对应被按下的按钮编号,直到 −1 标志输入结束,这个数字不要处理。数字间以空格分隔。题目保证至少会取出一件物品放在流水线上。 输出格式: 输入样例: AC代码 病毒容易发生变异。某种病毒可以通过突变产生若干变异的毒株,而这些变异的病毒又可能被诱发突变产生第二代变异,如此继续不断变化。 现给定一些病毒之间的变异关系,要求你找出其中最长的一条变异链。 在此假设给出的变异都是由突变引起的,不考虑复杂的基因重组变异问题 —— 即每一种病毒都是由唯一的一种病毒突变而来,并且不存在循环变异的情况。 输入格式: 随后 N 行,每行按以下格式描述一种病毒的变异情况: k 变异株1 …… 变异株k 输出格式: 在第二行中输出从源头开始最长的一条变异链,编号间以 1 个空格分隔,行首尾不得有多余空格。如果最长链不唯一,则输出最小序列。 注:我们称序列 { a 1 ,⋯,a n } 比序列 { b 1 ,⋯,b n } “小”,如果存在 1≤k≤n 满足 a i =b i 对所有 i 输入样例: 这里我们把问题简化一下:首先假设两个功能模块如果接受同样的输入,总是给出同样的输出,则它们就是功能重复的;其次我们把每个模块的输出都简化为一个整数(在 int 范围内)。于是我们可以设计一系列输入,检查所有功能模块的对应输出,从而查出功能重复的代码。你的任务就是设计并实现这个简化问题的解决方案。 输入格式: 随后 N 行,每行给出一个功能模块的 M 个对应输出,数字间以空格分隔。 输出格式: 注:所谓数列 { A 1 , …, A M } 比 { B 1 , …, B M } 大,是指存在 1≤i 输入样例: AC代码 哲哲是一位硬核游戏玩家。最近一款名叫《达诺达诺》的新游戏刚刚上市,哲哲自然要快速攻略游戏,守护硬核游戏玩家的一切! 为简化模型,我们不妨假设游戏有 N 个剧情点,通过游戏里不同的操作或选择可以从某个剧情点去往另外一个剧情点。此外,游戏还设置了一些存档,在某个剧情点可以将玩家的游戏进度保存在一个档位上,读取存档后可以回到剧情点,重新进行操作或者选择,到达不同的剧情点。 为了追踪硬核游戏玩家哲哲的攻略进度,你打算写一个程序来完成这个工作。假设你已经知道了游戏的全部剧情点和流程,以及哲哲的游戏操作,请你输出哲哲的游戏进度。 输入格式: 接下来的 N 行,每行对应一个剧情点的发展设定。第 i 行的第一个数字是 K i ,表示剧情点 i 通过一些操作或选择能去往下面 K i 个剧情点;接下来有 K i 个数字,第 k 个数字表示做第 k 个操作或选择可以去往的剧情点编号。 最后有 M 行,每行第一个数字是 0、1 或 2,分别表示: 0 表示哲哲做出了某个操作或选择,后面紧接着一个数字 j,表示哲哲在当前剧情点做出了第 j 个选择。我们保证哲哲的选择永远是合法的。 输出格式: 最后一行输出哲哲最后到达的剧情点编号。 输入样例: 1 -> 4 -> 3 -> 7 -> 8 -> 3 -> 5 -> 9 -> 10。 档位 1 开始存的是 1 号剧情点;档位 2 存的是 3 号剧情点;档位 1 后来又存了 9 号剧情点。 AC代码
输入在第一行给出3个整数V(0
对每种颜色分配方案,如果是图着色问题的一个解则输出Yes,否则输出No,每句占一行。
6 8 3
2 1
1 3
4 6
2 5
2 4
5 4
5 6
3 6
4
1 2 3 3 1 2
4 5 6 6 4 5
1 2 3 4 5 6
2 3 4 2 3 4
输出样例:
Yes
Yes
No
No
dfs搜索
AC代码 :#include L2-024 部落 (25 分)
输入在第一行给出一个正整数N(≤10 4 ),是已知小圈子的个数。随后N行,每行按下列格式给出一个小圈子里的人:
K P[1] P[2] ⋯ P[K]
首先在一行中输出这个社区的总人数、以及互不相交的部落的个数。随后对每一次查询,如果他们属于同一个部落,则在一行中输出Y,否则输出N。
4
3 10 1 2
2 3 4
4 1 5 7 8
3 9 6 4
2
10 5
3 7
输出样例:
10 2
Y
N
并查集
AC代码 :#includeL2-025 分而治之 (25 分)
输入在第一行给出两个正整数 N 和 M(均不超过10 000),分别为敌方城市个数(于是默认城市从 1 到 N 编号)和连接两城市的通路条数。随后 M 行,每行给出一条通路所连接的两个城市的编号,其间以一个空格分隔。在城市信息之后给出参谋部的系列方案,即一个正整数 K (≤ 100)和随后的 K 行方案,每行按以下格式给出:
其中 Np 是该方案中计划攻下的城市数量,后面的系列 v[i] 是计划攻下的城市编号。
对每一套方案,如果可行就输出YES,否则输出NO。
10 11
8 7
6 8
4 5
8 4
8 1
1 2
1 4
9 8
9 1
1 10
2 4
5
4 10 3 8 4
6 6 1 7 5 4 9
3 1 8 4
2 2 8
7 9 8 7 6 5 4 2
输出样例:
NO
YES
YES
NO
NO
模拟判断
AC代码 :#includeL2-026 小字辈 (25 分)
输入在第一行给出家族人口总数 N(不超过 100 000 的正整数) —— 简单起见,我们把家族成员从 1 到 N 编号。随后第二行给出 N 个编号,其中第 i 个编号对应第 i 位成员的父/母。家谱中辈分最高的老祖宗对应的父/母编号为 -1。一行中的数字间以空格分隔。
首先输出最小的辈分(老祖宗的辈分为 1,以下逐级递增)。然后在第二行按递增顺序输出辈分最小的成员的编号。编号间以一个空格分隔,行首尾不得有多余空格。
9
2 6 5 5 -1 5 6 4 7
输出样例:
4
1 9
思路 :
找到根节点后进行bfs进行广搜判断辈分
AC代码#includeL2-027 名人堂与代金券 (25 分)
输入在第一行给出 3 个整数,分别是 N(不超过 10 000 的正整数,为学生总数)、G(在 (60,100) 区间内的整数,为题面中描述的代金券等级分界线)、K(不超过 100 且不超过 N 的正整数,为进入名人堂的最低名次)。接下来 N 行,每行给出一位学生的账号(长度不超过15位、不带空格的字符串)和总评成绩(区间 [0, 100] 内的整数),其间以空格分隔。题目保证没有重复的账号。
首先在一行中输出发出的 PAT 代金券的总面值。然后按总评成绩非升序输出进入名人堂的学生的名次、账号和成绩,其间以 1 个空格分隔。需要注意的是:成绩相同的学生享有并列的排名,排名并列时,按账号的字母序升序输出。
10 80 5
[email protected] 78
[email protected] 87
[email protected] 65
[email protected] 96
[email protected] 39
[email protected] 87
[email protected] 80
[email protected] 88
[email protected] 80
[email protected] 70
输出样例:
360
1 [email protected] 96
2 [email protected] 88
3 [email protected] 87
3 [email protected] 87
5 [email protected] 80
5 [email protected] 80#includeL2-028 秀恩爱分得快 (25 分)
输入在第一行给出 2 个正整数:N(不超过1000,为总人数——简单起见,我们把所有人从 0 到 N-1 编号。为了区分性别,我们用编号前的负号表示女性)和 M(不超过1000,为照片总数)。随后 M 行,每行给出一张照片的信息,格式如下:
其中 K(≤ 500)是该照片中出现的人数,P[1] ~ P[K] 就是这些人的编号。最后一行给出一对异性情侣的编号 A 和 B。同行数字以空格分隔。题目保证每个人只有一个性别,并且不会在同一张照片里出现多次。
首先输出 A PA,其中 PA 是与 A 最亲密的异性。如果 PA 不唯一,则按他们编号的绝对值递增输出;然后类似地输出 B PB。但如果 A 和 B 正是彼此亲密度最高的一对,则只输出他们的编号,无论是否还有其他人并列。
10 4
4 -1 2 -3 4
4 2 -3 -5 -6
3 2 4 -5
3 -6 0 2
-3 2
输出样例 1:
-3 2
2 -5
2 -6
输入样例 2:
4 4
4 -1 2 -3 0
2 0 -3
2 2 -3
2 -1 2
-3 2
输出样例 2:
-3 2
思路 ;
大模拟
AC代码#includeL2-029 特立独行的幸福 (25 分)
输入在第一行给出闭区间的两个端点:1
按递增顺序列出给定闭区间 [A,B] 内的所有特立独行的幸福数和它的独立性。每对数字占一行,数字间以 1 个空格分隔。
10 40
输出样例 1:
19 8
23 6
28 3
31 4
32 3
注意:样例中,10、13 也都是幸福数,但它们分别依附于其他数字(如 23、31 等等),所以不输出。其它数字虽然其实也依附于其它幸福数,但因为那些数字不在给定区间 [10, 40] 内,所以它们在给定区间内是特立独行的幸福数。
110 120
输出样例 2:
SAD#includeL2-030 冰岛人 (25 分)

输入首先在第一行给出一个正整数 N(1
对每一个查询,根据结果在一行内显示以下信息:
若两人为异性,但五代以内(不包括第五代)有公共祖先,则输出 No;
若两人为同性,则输出 Whatever;
若有一人不在名单内,则输出 NA。
所谓“五代以内无公共祖先”是指两人的公共祖先(如果存在的话)必须比任何一方的曾祖父辈分高。
15
chris smithm
adam smithm
bob adamsson
jack chrissson
bill chrissson
mike jacksson
steve billsson
tim mikesson
april mikesdottir
eric stevesson
tracy timsdottir
james ericsson
patrick jacksson
robin patricksson
will robinsson
6
tracy tim james eric
will robin tracy tim
april mike steve bill
bob adam eric steve
tracy tim tracy tim
x man april mikes
输出样例:
Yes
No
No
Whatever
Whatever
NA#includeL2-031 深入虎穴 (25 分)
输入首先在一行中给出正整数 N(<10 5 ),是门的数量。最后 N 行,第 i 行(1≤i≤N)按以下格式描述编号为 i 的那扇门背后能通向的门:
其中 K 是通道的数量,其后是每扇门的编号。
在一行中输出距离入口最远的那扇门的编号。题目保证这样的结果是唯一的。
13
3 2 3 4
2 5 6
1 7
1 8
1 9
0
2 11 10
1 13
0
0
1 12
0
0
输出样例:
12
思路 :
找到根节点后直接bfs找到最后一个点即可
AC代码#include L2-032 彩虹瓶 (25 分)

输入首先在第一行给出 3 个正整数,分别是彩虹瓶的颜色数量 N(1
对每个发货顺序,如果工人可以愉快完工,就在一行中输出 YES;否则输出 NO。
7 5 3
7 6 1 3 2 5 4
3 1 5 4 2 6 7
7 6 5 4 3 2 1
输出样例:
YES
NO
NO#include L2-033 简单计算器 (25 分)

从 S 1 中弹出两个数字,顺序为 n 1 和 n 2 ;从 S 2 中弹出一个运算符 op;执行计算 n 2op n 1 ;
将得到的结果压回 S 1 。
直到两个堆栈都为空时,计算结束,最后的结果将显示在屏幕上。
输入首先在第一行给出正整数 N(1
将输入的数字和运算符按给定顺序分别压入堆栈 S 1 和 S 2 ,将执行计算的最后结果输出。注意所有的计算都只取结果的整数部分。题目保证计算的中间和最后结果的绝对值都不超过 10 9 。5
40 5 8 3 2
/ * - +
2
5
2 5 8 4 4
* / - +
ERROR: 5/0
#includeL2-034 口罩发放 (25 分)
输入第一行是两个正整数 D 和 P(1≤D,P≤30),表示有 D 天的数据,市民两次获得口罩的时间至少需要间隔 P 天。
给定数据约束如下:
身份证号 是一个长度不超过 20 的非空字符串;
身体情况 是 0 或者 1,0 表示自觉良好,1 表示有相关症状;
提交时间 是 hh:mm,为24小时时间(由 00:00 到 23:59。例如 09:08。)。注意,给定的记录的提交时间不一定有序;
身份证号 各不相同,同一个身份证号被认为是同一个人,数据保证同一个身份证号姓名是相同的。
能发放口罩的记录要求如下:
同一个身份证号若在第 i 天申请成功,则接下来的 P 天不能再次申请。也就是说,若第 i 天申请成功,则等到第 i+P+1 天才能再次申请;
在上面两条都符合的情况下,按照提交时间的先后顺序发放,直至全部记录处理完毕或 S
i
个名额用完。如果提交时间相同,则按照在列表中出现的先后顺序决定。
输出格式:
对于每一天的申请记录,每行输出一位得到口罩的人的姓名及身份证号,用一个空格隔开。顺序按照发放顺序确定。
4 2
5 3
A 123456789012345670 1 13:58
B 123456789012345671 0 13:58
C 12345678901234567 0 13:22
D 123456789012345672 0 03:24
C 123456789012345673 0 13:59
4 3
A 123456789012345670 1 13:58
E 123456789012345674 0 13:59
C 123456789012345673 0 13:59
F F 0 14:00
1 3
E 123456789012345674 1 13:58
1 1
A 123456789012345670 0 14:11
输出样例:
D 123456789012345672
A 123456789012345670
B 123456789012345671
E 123456789012345674
C 123456789012345673
A 123456789012345670
A 123456789012345670
E 123456789012345674
样例解释:
输出中,第一行到第三行是第一天的部分;第四、五行是第二天的部分;第三天没有符合要求的市民;第六行是第四天的部分。最后两行按照出现顺序输出了可能存在身体不适的人员。#includeL2-035 完全二叉树的层序遍历 (25 分)
输入在第一行中给出正整数 N(≤30),即树中结点个数。第二行给出后序遍历序列,为 N 个不超过 100 的正整数。同一行中所有数字都以空格分隔。
在一行中输出该树的层序遍历序列。所有数字都以 1 个空格分隔,行首尾不得有多余空格。
8
91 71 2 34 10 15 55 18
输出样例:
18 34 55 71 2 10 15 91
AC代码//完全二叉树采用顺序存储方式,如果有左孩子,则编号为2i,如果有右孩子,编号为2i+1,然后按照后序遍历的方式(左右根),进行输入,最后顺序输出即可。
#include L2-036 网红点打卡攻略 (25 分)
首先第一行给出两个正整数:网红点的个数 N(1
n V 1 V 2 ⋯ V n
其中 n(≤200) 是攻略中的网红点数,V i 是路径上的网红点编号。这里假设你从家里出发,从 V 1 开始打卡,最后从 V n 回家。
在第一行输出满足要求的攻略的个数。
6 13
0 5 2
6 2 2
6 0 1
3 4 2
1 5 2
2 5 1
3 1 1
4 1 2
1 6 1
6 3 2
1 2 1
4 5 3
2 0 2
7
6 5 1 4 3 6 2
6 5 2 1 6 3 4
8 6 2 1 6 3 4 5 2
3 2 1 5
6 6 1 3 4 5 2
7 6 2 1 3 4 5 2
6 5 2 1 4 3 6
输出样例:
3
5 11
样例说明:
第 2、3、4、6 条都不满足攻略的基本要求,即不能做到从家里出发,在每个网红点打卡仅一次,且能回到家里。所以满足条件的攻略有 3 条。#include L2-037 包装机 (25 分)
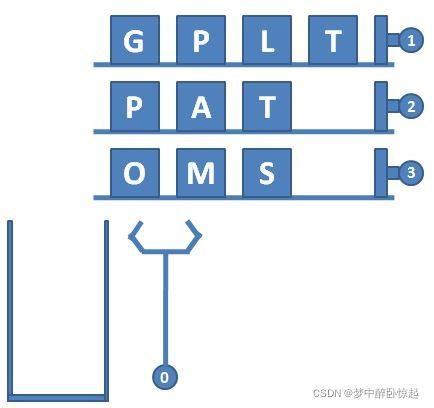
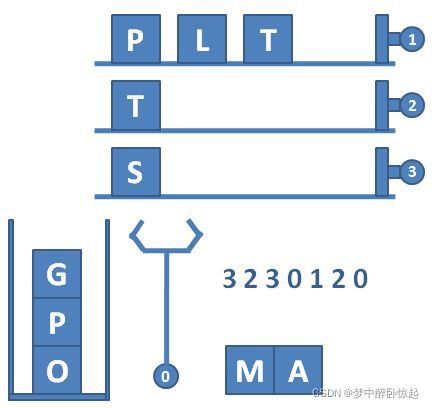
输入第一行给出 3 个正整数 N(≤100)、M(≤1000)和 S
max(≤100),分别为轨道的条数(于是轨道从 1 到 N 编号)、每条轨道初始放置的物品数量、以及筐的最大容量。随后 N 行,每行给出 M 个英文大写字母,表示每条轨道的初始物品摆放。
在一行中顺序输出流水线上的物品,不得有任何空格。
3 4 4
GPLT
PATA
OMSA
3 2 3 0 1 2 0 2 2 0 -1
输出样例:
MATA#includeL2-038 病毒溯源 (25 分)
输入在第一行中给出一个正整数 N(≤10 4 ),即病毒种类的总数。于是我们将所有病毒从 0 到 N−1 进行编号。
其中 k 是该病毒产生的变异毒株的种类数,后面跟着每种变异株的编号。第 i 行对应编号为 i 的病毒(0≤i
首先输出从源头开始最长变异链的长度。
10
3 6 4 8
0
0
0
2 5 9
0
1 7
1 2
0
2 3 1
输出样例:
4
0 4 9 1
思路 :
从根节点dfs
AC代码#includeL2-039 清点代码库 (25 分)

上图转自新浪微博:“阿里代码库有几亿行代码,但其中有很多功能重复的代码,比如单单快排就被重写了几百遍。请设计一个程序,能够将代码库中所有功能重复的代码找出。各位大佬有啥想法,我当时就懵了,然后就挂了。。。”
输入在第一行中给出 2 个正整数,依次为 N(≤10 4 )和 M(≤10 2 ),对应功能模块的个数和系列测试输入的个数。
首先在第一行输出不同功能的个数 K。随后 K 行,每行给出具有这个功能的模块的个数,以及这个功能的对应输出。数字间以 1 个空格分隔,行首尾不得有多余空格。输出首先按模块个数非递增顺序,如果有并列,则按输出序列的递增序给出。
7 3
35 28 74
-1 -1 22
28 74 35
-1 -1 22
11 66 0
35 28 74
35 28 74
输出样例:
4
3 35 28 74
2 -1 -1 22
1 11 66 0
1 28 74 35#include L2-040 哲哲打游戏 (25 分)
输入第一行是两个正整数 N 和 M (1≤N,M≤10 5 ),表示总共有 N 个剧情点,哲哲有 M 个游戏操作。
1 表示哲哲进行了一次存档,后面紧接着是一个数字 j,表示存档放在了第 j 个档位上。
2 表示哲哲进行了一次读取存档的操作,后面紧接着是一个数字 j,表示读取了放在第 j 个位置的存档。
约定:所有操作或选择以及剧情点编号都从 1 号开始。存档的档位不超过 100 个,编号也从 1 开始。游戏默认从 1 号剧情点开始。总的选项数(即 ∑K i )不超过 10 6 。
对于每个 1(即存档)操作,在一行中输出存档的剧情点编号。
10 11
3 2 3 4
1 6
3 4 7 5
1 3
1 9
2 3 5
3 1 8 5
1 9
2 8 10
0
1 1
0 3
0 1
1 2
0 2
0 2
2 2
0 3
0 1
1 1
0 2
输出样例:
1
3
9
10
样例解释:
简单给出样例中经过的剧情点顺序:#include