阿里妈妈智能诊断工程能力建设
丨本文作者:茂道、羲洋、君之、天柏
1. 业务背景
算法同学在日常工作中经常要面临一些耗时较多的临时工单,这类工单的问题类型五花八门,背后对应的原因也各不相同,例如广告主操作类问题、大盘流量波动问题、海选问题、粗排问题等。这类Case每次都需要耗费较长时间单独解决,没有办法沉淀相应的工具和知识体系,随之带来的是算法团队开发诊断代码工作量大、开发周期长、不宜维护等问题。
为了有效地持续提升工单处理效率,算法同学希望可以通过简易服务化方式,通过数据 + 指标 + 规则 + 服务化模式快速配置SOP诊断链路,提升自动化诊断能力,最大化提升排查效率,并沉淀业务知识库,加快后续相似问题的诊断和响应速度。未来更期望将自动化诊断能力进行服务环节前置,如xspace、袋小蜜,直接赋能广告主,并基于诊断和建设能力,升级营销诊断和袋小蜜等。因此,商家端智能诊断系统应运而生。
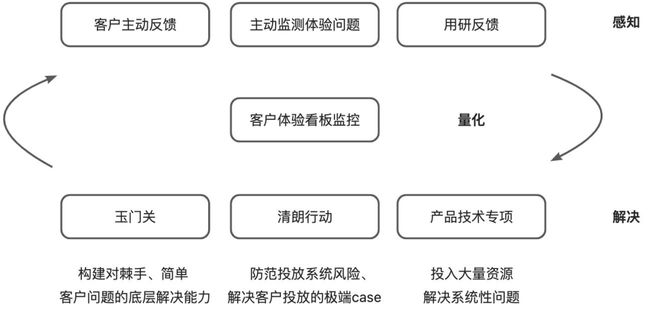 客服体验问题的解决思路
客服体验问题的解决思路
2. 建设目标
1)框架建设:希望通过SQL或者规则引擎+低代码方式提升业务侧迭代效率,提升算法同学的开发效率,迭代平台侧的的能力,沉淀组件和相关工程能力,整体工程资源和数据资源可控。
2)数据建设:目前replay数据、操作日志、效果数据均由算法维护或者算法可灵活获取,从算法角度可以建立完善的广告诊断数据中心,标准化数据存储方式和数据获取方式。
3)诊断规则知识库建设:通过建设示范性SOP,可以沉淀出大量可用的基础广告诊断规则(例如广告主余额不足、计划是否下线等)。同一数据诊断规则可以复用在多个SOP流程当中,用户可以基于诊断规则知识库搭建出复杂的广告诊断链路。
3. 技术方案
基于商家端引擎,我们开发了一套基于商家端框架的自动化SOP框架,将用户策略收口到商家端框架,可针对数据存储&管理、sop微服务开发&测试&监控制定标准,提升开发和迭代效率;建立数据、指标、规则、服务的统一开发标准,依托Dolphin数据湖的能力进行数据存储和查询,规则引擎支持规则输入和SOP诊断链路编排,支持用户自助迭代。利用工程团队的技术优势,提升开发和迭代效率。
标准化:数据存取标准化;服务接口标准化;核心算子SQL化、函数化;
可扩展:数据的扩展性;规则的扩展性;
少代码:数据读取高度抽象(SQL化)、流程模块化/函数化、SOP链路可视化配置;
可跟踪:日志、监控;
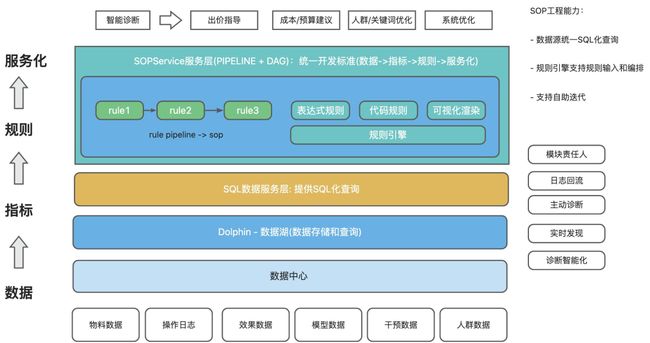 商家端诊断引擎框架图
商家端诊断引擎框架图
3. 规则引擎
标准化客诉流程:通过规则引擎促使各个业务线的SOP流程统一为标准流程,遵循统一的guideline。将SOP流程抽象为依赖什么数据,进行怎样的规则判断,得出怎样的结论,无法排查时应根据什么条件转交给不同的团队继续进行跟进。
为什么要引入规则引擎?将业务决策逻辑从系统逻辑中抽离出来,降低系统间的耦合,使两种逻辑可以独立于彼此而变化,降低维护两种逻辑的维护成本,不同sop链路可以复用规则。
不同用户的使用场景不同,代码能力不同。
3.1 引擎选型
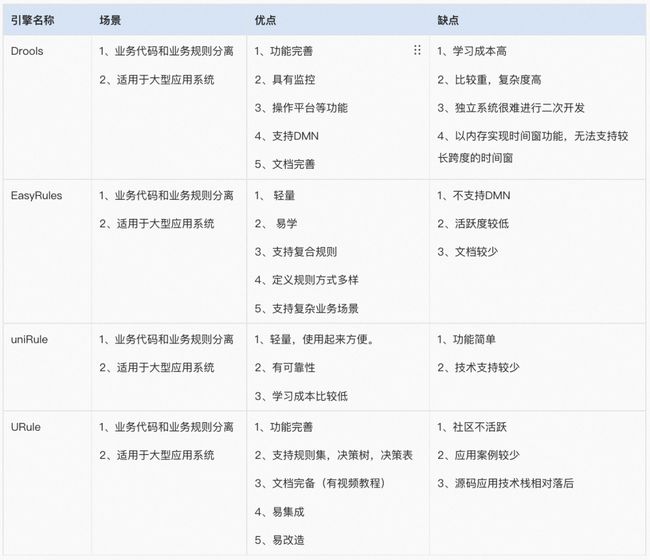
智能诊断场景需求:轻量开发、定义规则方式多种、支持代码模式和表达式规则,最终选择选择轻量、高效的表达式和代码结合的引擎easyRules。
3.2 规则
低代码平台针对不同的使用群体,划分为三种模式:
1)简单运算
通过四则运算和条件运算,产出规则,具体是metric 和 metirc之间的四则运算表达式 和 逻辑表达式,产出为 true或者false。
if(100.0 * (competition_times - adReplayInfo.getSn_real_competition_times())
/ competition_times�)>802)code模式
对于具有复杂数据结构的运算,需要使用code模式,编写代码片段,使用QLExpress语法格式。
for (i = 0;i < bidwordList.size();i++) {
bidword = bidwordList.get(i);
keywordCateInfoEntity = keywordCatInfo.get(bidword);
if (entity == null) {
subSopDiagnosis.appendDetails(String.format("投诉词【%s】与AD的类目不符.", bidword));
} else if (!entity.getCate_map().containsKey(cate_id)) {
subSopDiagnosis.appendDetails(String.format("投诉词【%s】与AD的类目不符,推荐类目为【%s】.", bidword, entity.getMain_cate_full_name()));
} else {
goodWords.add(bidword);
subSopDiagnosis.appendDetails(String.format("投诉词【%s】与AD的类目相符.", bidword));
}
}3)java代码
直接由用户编写rule class,运行时动态加载。
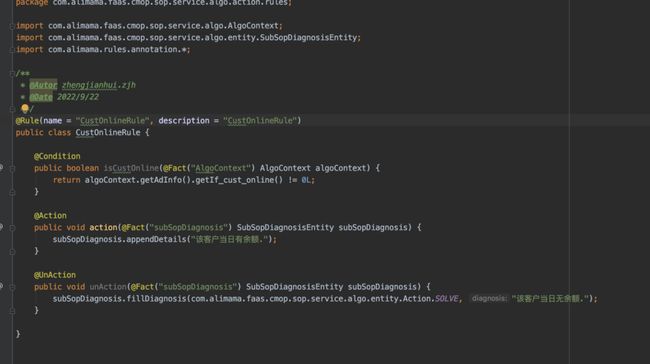 用户自定义规则编写示例
用户自定义规则编写示例
3.3 SOP链路
将SOP链路划分为参数检查、数据读取、规则组织、结果返回,在不同阶段绑定不同规则集,进行诊断链路串联。
参数检查:输入粒度规范、日期检查、输入关键词检查等;
数据读取:指标读取、衍生指标读取等;
规则组织:规则集绑定;
结果返回:诊断结果、诊断话术。
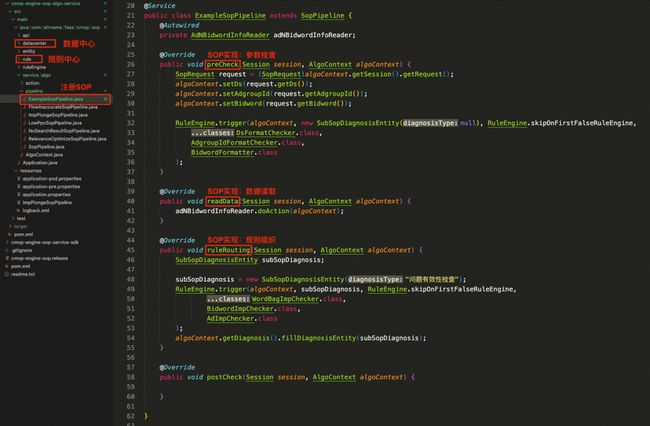 诊断链路编写示例
诊断链路编写示例
4. 数据中心
4.1 SQL统一查询
同步查询
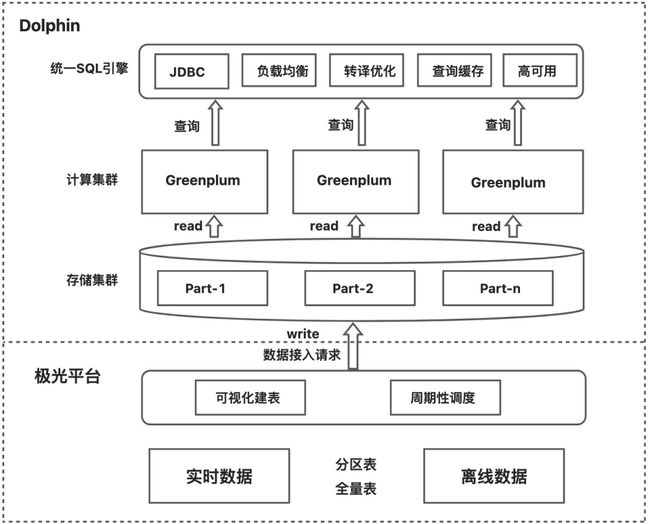
统一的SQL查询引擎对外提供统一的SQL语法(语法和PG语法保持一致),实现对Dolphin、IGraph、Hologres、Http、HSF等数据源的统一查询功能,同时也支持跨引擎查询功能,极大降低了用户的使用成本,使用存储在不同数据源的数据就像在ODPS上一样方便。
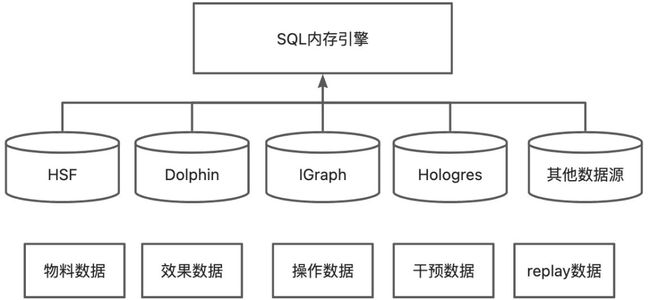 SQL统一查询引擎框架图
SQL统一查询引擎框架图
异步查询
对于数据量特别大、查询模式支持异步化查询;
4.2 数据建设
广告诊断系统数据可以划分为6大类:物料数据、效果数据、投放数据、干预数据、操作数据和人群数据。各类数据分别来自BP、SDS、投放引擎、算法维护、操作日志、达摩盘等,数据存在分散、存储引擎多种多样、数据格式不统一、维护团队较多、部分数据实效性较差等问题,整合和产出一份格式统一、数据完备的广告诊断数据仓库十分必要。对tickets工单系统中的客诉工单进行统计,诊断所需要的数据粒度也分为AD粒度、关键词粒度、人群粒度和QUERY粒度。
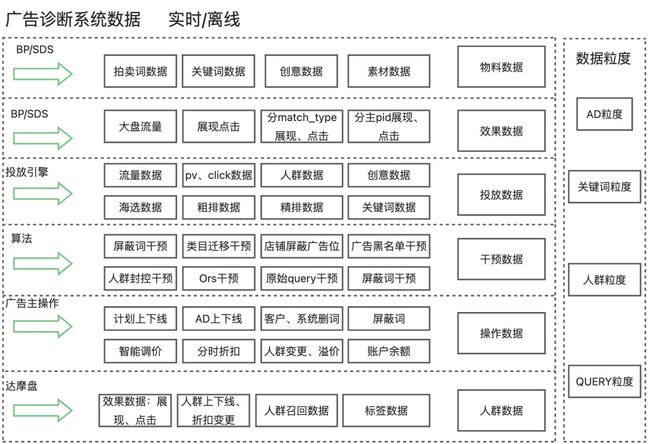 广告诊断数据大图
广告诊断数据大图
实时、离线数据建设
离线数据:数据ETL产出ODPS,通过极光平台[2]导入Dolphin。
实时数据产出:TT数据流回流ODPS,通过极光平台[2]导入Dolphin,产出小时级数据。
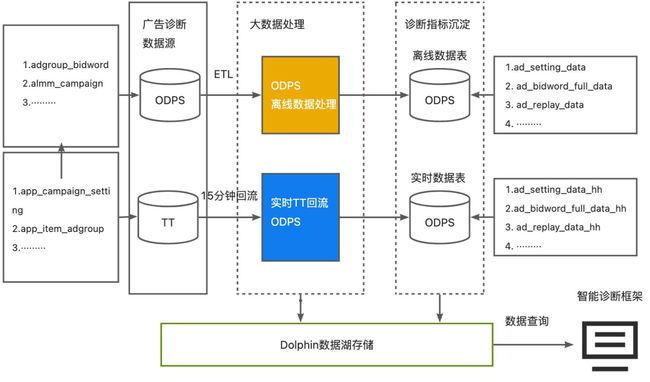 实时离线数据建设链路图
实时离线数据建设链路图
将存储在不同数据源的数据在平台进行注册,将诊断数据统一化为数据指标类型,用户可以在数据层定义衍生指标,支持四则运算以及复杂函数类型计算,沉淀出数据层的指标和衍生指标。
支持同一数据粒度下的多指标运算
生命周期管理
有效性巡检
指标数据探查
5. 加速引擎
广告诊断场景的查询具有查询QPS低、查询周期长、单值查询的特点,诊断场景对于查询延迟要求不高,实时数据与离线数据存储量较大,存储成本较高。针对这样的场景,我们通过数据库的外表技术,可以实现计算引加直接读取HDFS上的数据,多个计算集群,可以共享一份HDFS上的文件存储数据,实现数据的一写多读,HDFS底层使用HDD存储数据,实现数据成本的大幅度降低,数据统一存储。
为了支持外表数据,索引下推查询,我们对orc代码数据读取部分做了大量深入优化,包括排序列的智能选择,动态row group stripe size和索引和数据的本地cache。在直通车展现波动SOP场景中,90天长周期T级别数据量查询可以达到秒级延迟;在人群SOP场景中,Dolphin在标签圈人百亿ID的交并差领先的技术优势能够很好地体现出来。
ODPS表数据也可以直接通过极光平台[2]进行查询加速,极光平台[2]同时也支持原生SQL对各种数据源进行查询。
6. 总结与展望
当前在直通车业务场景下,商家端智能诊断系统可以支持展现波动、流量不精准以及搜索无展现、相关性优化SOP。展现波动/无展现SOP中49%给出诊断,流量不精准可100%给出建议,相关性优化可93%给出建议;覆盖直通车推广优化类工单65%,准确率>90%(推广优化类工单主要由技术同学负责解决,最复杂难解且数量多;覆盖率指能给出明确诊断或建议的比率),面向不同子问题的完结率和处理时长均有显著提升。
智能诊断系统由数据引擎团队与广告主赋能算法团队共建,希望可以通过低代码的智能系统更好地帮助算法侧沉淀营销知识库,真正从平台视角来帮助广告主解决营销投放中可能存在的问题,同时也可以更及时地排查系统中的潜在风险。后续我们希望通过业务场景拓展,推向更多的工单类型,同时将服务环节前置,从根源上释放算法同学的压力,同时更好地赋能广告主;并基于诊断和建议能力,升级营销诊断和袋小蜜等。未来可以基于多维时序数据进行归因分析辅助诊断,在广告主进行提出工单之前就将问题定位,提高平台的智能性。
7. 附录
[1] Dolphin:面向营销场景超融合智能引擎,Dolphin源自阿里妈妈数据营销平台达摩盘(DMP)场景,在通用OLAP MPP计算框架的基础上,针对营销场景的典型计算(标签圈人,洞察分析)等,进行了大量存储、索引和计算算子级别的性能优化,实现了在计算性能,存储成本,稳定性等各个方面的大幅度的提升。Dolphin引擎作为商家端服务的核心基建,可以横向覆盖交互式OLAP分析,AI算法计算,Streaming, Batch等多个计算场景。
[2] 极光平台:针对B端商家的统一服务框架和研发平台,主要有以下功能:1)统一服务框架:FAAS函数服务,算法同学开发业务核心代码,工程团队负责基础功能,实现服务的快速开发,迭代,发布上线及低成本运维;2)统一研发平台:支持商家端算法特征的开发,管理,沉淀。模型管理、发布上线;3)统一计算引擎:算法核心通用算子下沉Dolphin引擎,实现业务逻辑和底层计算解耦,算子复用。
END

阿里妈妈数据引擎团队-系列内容:
Dolphin:面向营销场景的超融合多模智能引擎
阿里妈妈Dolphin分布式向量召回技术详解
阿里妈妈Dolphin智能计算引擎基于Flink+Hologres实践
Dolphin Streaming实时计算,助力商家端算法第二增长曲线
面向数智营销的 AI FAAS 解决方案
FAE:阿里妈妈归因分析与用户增长分析引擎
开源greenplum向量计算库:https://github.com/AlibabaIncubator/gpdb-faiss-vector
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓