python影视数据爬虫sqlite源码+论文(完整版和简洁版)
python影视数据爬虫sqlite源码+论文(完整版和简洁版)-99源码网,程序代做,代写程序代码,代写编程,代写Java编程,代写php编程,计算机专业代做,计算机毕业设计,网站建设,网站开发,程序
项目介绍:
python影视数据爬虫sqlite源码+论文(完整版和简洁版)
系统说明:
目 录
摘要............................................................................................................................................ 1
关键词........................................................................................................................................ 1
1 绪论........................................................................................................................................ 2
1.1 选题背景.......................................................................................................................... 2
1.1.1 课题的国内外的研究现状....................................................................................... 2
1.1.2 课题研究的必要性................................................................................................... 3
1.2 课题研究的内容.............................................................................................................. 4
2 开发软件平台介绍................................................................................................................ 4
2.1 软件平台.......................................................................................................................... 4
2.2 开发语言.......................................................................................................................... 4
3 网络爬虫总体方案................................................................................................................ 4
3.1 系统组成.......................................................................................................................... 4
3.2 工作原理.......................................................................................................................... 5
4 模块化设计............................................................................................................................ 6
4.1 Flask模块介绍................................................................................................................ 6
4.1.1 模块的略解............................................................................................................... 6
4.1.2 界面用户的交互....................................................................................................... 8
4.2 爬虫模块.......................................................................................................................... 9
4.2.1 BeautifulSoup4库的说明及使用................................................................................ 9
4.2.2 bs4库的说明及使用................................................................................................ 10
4.2.3 爬虫模块的流程解析............................................................................................. 10
4.3 反爬虫模块.................................................................................................................... 14
5 实验结论与发展前景.......................................................................................................... 14
5.1 网络爬虫主要实现代码................................................................................................ 14
5.2 xlsx文件........................................................................................................................ 21
6 总结...................................................................................................................................... 22
参考文献.................................................................................................................................. 24
致谢.......................................................................................................................................... 25
网络数据爬取及可视化分析--影视数据分析
计算机科学与技术专业学生 XXX
指导教师 XXX
摘要:无论时间和地点如何,信息都是至关重要的。随着万维网的迅速发展,信息已急剧增加。当传统的信息处理扩展到Internet领域时,通常需要将分布在各种网站上的信息下载到本地站点以进行进一步处理。但是,当收集大量数据时,传统方法显然不适用。传统的在Internet上查询信息的方法不可避免的问题之一是,令人印象深刻的信息使其难以区分和拒绝,以便更有效,更准确地获取所需的信息。当信息很多时,Web爬网程序可能是一个很好的方法。使用自定义规则,您可以从特定网站提取相关信息,并在过滤后获得更准确的信息。。
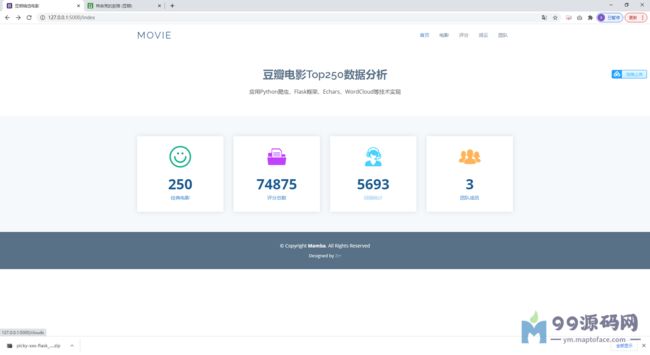
本文的网络爬虫程序主要采用Python脚本语言。使用Flask库构造图形界面便于操作,即通过点击对应按钮触发相应功能。数据存储并没有使用mysql和NoSQL,网络爬虫爬取的结果直接以sqlite文件保存,以便于数据的读取并将数据可视化。数据分析采用BeautifulSoup库,以bootstrap和echarts渲染界面,读取获得的数据生成散点图或柱状图以便于观察。
关键词:网络爬虫 Python 数据爬取 数据分析
Network data crawling and visualization analysis - film and television data analysis
Computer science and technology XXX
Tutor XXX
Abstract:Information is vital whenever and wherever. With the rapid development of the world wide web, information presents exponential explosive growth. When the traditional information processing is extended to the Internet field, it is often necessary to download the information distributed in various websites to the local for further processing. However, in a large number of data collection, it is obvious that the traditional method is not applicable. A problem that traditional methods can not avoid when querying information on the network is that the dazzling information makes it difficult to distinguish and give up. In order to obtain the desired large amount of information more efficiently and accurately, web crawler is an excellent means. Through the self-defined rules, we can mine the relevant information from the designated website, and get more accurate information after filtering.
This web crawler mainly uses Python script language. Using the flash library to construct a graphical interface is easy to operate, that is, by clicking the corresponding button to trigger the corresponding function. MySQL and NoSQL are not used in data storage. The results of web crawler crawling are directly saved in SQLite file to facilitate data reading and visualization. Data analysis uses the beatiful soup library, with bootstrap and ecarts rendering interface, reads the data to generate scatter or histogram for easy observation.
Keywords: Web crawler; Python; data crawling; data analysis
1 绪论
1.1 选题背景
随着万维网的快速发展,因特网上的信息已经爆炸式增长。结果,人们在互联网上找到他们所需的信息变得越来越困难,这直接导致了搜索引擎的出现。搜索引擎在Internet上收集了数亿个页面,如何有效,准确地从这些页面获取信息成为一个问题,网络爬虫由此诞生。 Web爬网程序(在FOAF社区中也称为Web蜘蛛,Web机器人,通常是Web追踪器)是根据某些方法和规则自动在万维网上爬网信息的程序或脚本。其他不常见的名称包括蚂蚁,自动索引,模仿物或蠕虫[1]。
网络爬虫是一个程序或者脚本,人为的编写规则,网络爬虫程序根据规则对指定网址进行信息的获取。趋近完美的程序拥有高效、精准、及时的效果。网络爬虫并非一件容易的问题,想要实现一般需要面对两个大的问题:(一):爬虫本身程序的问题:高并发的实现,分布式的实现,数据的筛选及存储。(二):对应的拥有信息的网站为了减少信息被爬取的或者为了减轻服务器负载,各种反爬虫措施带来的问题使得信息不那么容易获取,或者获取的信息为加密信息,需要筛选或者进行反加密处理。
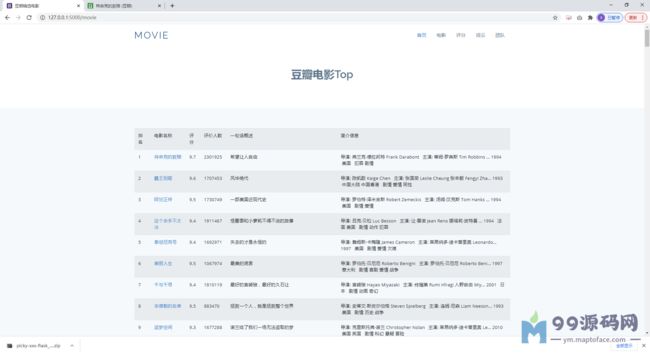
本文通过Python语言实现一个对Ajax异步加载的网站(豆瓣电影)的爬虫。通过爬虫程序实现对豆瓣电影Top榜的爬取,获取到排名、电影名称、评分、评价人数、概括、简介等数据,在进行数据分析。
1.1.1 课题的国内外的研究现状
Web搜寻器是在90年代类似Google的不同搜索引擎中创建的,用于捕获和搜寻各种基于Internet的网页,并在人们被各种搜索引擎处理后为他们提供检索服务。 Web爬网程序是不与其他用户直接通信的幕后技术,因此在2004年之前,它们的兴趣几乎为零,并且开发人员长期以来一直忽略它们。自2005年以来,人们对搜寻器技术越来越感兴趣,因此搜寻器对开发人员的兴趣也越来越大。相应的反爬行行为也出现了,难度逐渐增加。
正常情况下,任何支持网络通信的语言都可以写网络爬虫。但问题就在于,不同语言的不同特性,使得他们各有优缺。而对于网络爬虫这一特性的工作,Python脚本语言以其相对简单、开发度广的特性,力压群雄,并诞生了许多优秀的框架,如:scrapy、Crawley、pyspider。这里因为仅学习了scrapy框架,而scrapy框架更适用于大量数据的分布式爬虫,然而本文爬虫目标显然不需要爬取大量数据,故而选择使用BeautifulSoup模块代替原本笨重的自带爬虫模块。
在网络爬虫飞速发展的时代,各种网站、引擎、甚至app均成为网络爬虫的目标。各种网络爬虫手段和反网络爬虫手段层出不穷。一般主要网络爬虫手段有以下两种:
(一):伪造人为访问获取网络请求。
(二):使用selenium自动测试工具进行网站访问获取请求。
网络爬虫的反爬虫手段则主要有以下几种:
(一):浏览器识别,同一浏览器过于频繁的访问同一服务器会被服务器视为网络爬虫程序的访问,服务器会对该请求拉入黑名单禁止访问(一般禁止时间少则几十分钟,多则数小时乃至数日,甚至更久)。应对手段:在访问请求的函数中加入多个服务器的型号。在服务器型号过多时,一般用字典进行存储,用随机模块random,每进行一次网络请求,从字典中随机选取一个服务器型号以应对该类反爬虫。该类反网络爬虫亦为最常见的爬虫。
(二):IP识别,同一IP过于频繁访问同一服务器,服务器会对该IP进行封禁(封禁时间随不同公司而不同),一般使用代理池以应对这个问题。代理池的来源一般有两种:1.从网上收集免费的代理IP,对其进行测试,当前可用则存入代理池中。由于网络的公开性,免费代理存在极为不稳定的问题,在大规模使用时无法稳定使用。2.网站购买,从网站购买的代理IP稳定性有较好的保障,根据价格不同代理IP的性能也有差距,根据访问目标的网站性质,一般有HTTP和HTTPS两这级别使用的代理IP,HTTP的代理IP只能访问HTTP协议的网站,而HTTPS的代理IP对两种协议的网站均可访问。
(三)网站的Ajax的异步加载,ajax的异步加载使得网络爬虫无法直接从当前网页的源代码中获取需要的信息,需要打开浏览器的开发者模式对网站的请求信息进行分析进而筛选出需要的信息,这是个复杂的过程,本文的网络爬虫爬取目标即为该类型。
(四)网站的各种验证及账号登录,许多网站使用账号限制,无法登陆则无法进入下一级界面获取关键的信息,登陆可用代码直接模拟登陆,问题在于验证码的验证,一般需要网上的打码平台进行处理,该过程较为复杂不予详解。
1.1.2 课题研究的必要性
实践是最好的学习。在学习网络爬虫时,许多知识点的掌握并不牢靠,通过自己动手编程能够快速且扎实的提高自身的能力。本文中的网络爬虫程序不仅实现对象信息的定量抓取、信息筛选,获取的信息对应届毕业生亦不失为极其有用的信息。电影,在当今社会,作为人们在日常生活中不可缺少的一种娱乐方式,已经发展出百花争鸣的局面,让我们欣赏各种各样的影视剧。但是,人们在看完电影之后,往往会有一些发自内心的感触,或许是同情主人公的悲欢离合,或许是对于故事的情节触目惊心,或许是对电影特效的与众不同,总之,人们在看完一部电影后或多或少都会将自己内心的所思所想告诉他人,或者是想了解他人是否同自己一样感同身受,因此,为了让更多的人可以方便地通过互联网相互之间交流对于电影的看法或是发布一些影评,或者可以从他人的影评中了解这部电影是否值得去看,于是,创建一个对于影评的搜索系统就显得很有必要了。
1.2 课题研究的内容
本设计主要基于Pycharm的编程平台建设,整个系统由如下几个模块组成,具体如下:Flask图形界面模块,设置按钮,点击按钮触发对应功能;爬虫模块,编写爬虫文件,由bootstrap模块‘查询’按钮触发,对获取内容以sqlite保存;数据分析模块,读取对应的sqlite文件,让数据可视化,由bootstrap模块‘生成可视化图’按钮触发;本文爬取目标网站IP的封禁程度一般,因此本文暂未使用代理IP。
2 开发软件平台介绍
2.1 软件平台
该设计基于Pycharm软件平台。 PyCharm是由JetBrains创建的Python IDE,具有一系列工具,可帮助用户提高使用Python语言进行开发时的熟练度,例如调试,语法突出显示,项目管理,代码跳转,智能提示,自动完成和模块测试和版本控制。此外,IDE提供了一些高级功能来支持通用框架,例如Django,Scarpy和pyspider。同时,Google App Engine和PyCharm支持IronPython。这些功能,再加上高级代码分析软件的支持,使PyCharm成为了专业和初学者Python开发人员的强大工具[2]。
2.2 开发语言
本设计采用的Python语言是一种计算机程序设计语言,因常被用于脚本开发也常被称为脚本语言。由C语言为底层开发的,本身有许多库由C语言封装的,起初被用于数学家和科学家的数学计算,因其简洁、易学、扩展性强的特点,被广泛的使用在各个领域,比如软件开发、大数据、AI、网络编程等(本文的网络爬虫属于网络编程)。网络爬虫常用语言为Java和Python,两者均支持网络爬虫。对比之下,Python开发速度更快且支持分布式爬虫,Java对比Python运行速度较快的特点显得苍白,因此采用Python语言。
适用场景:
毕业论文、课程设计、公司项目参考
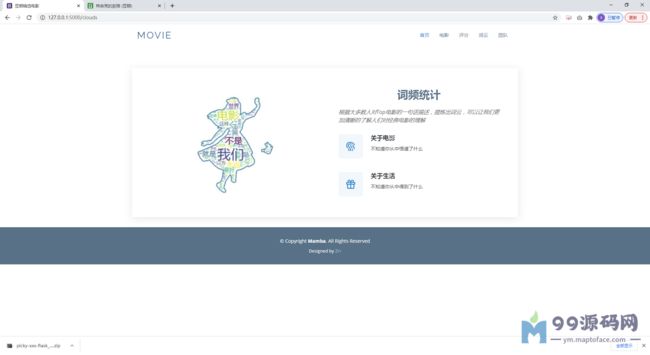
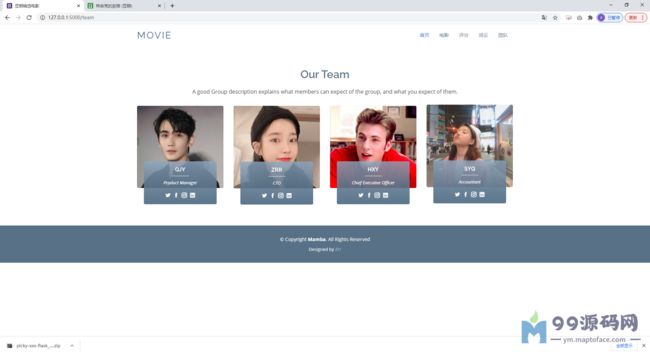
运行截图:

关注【程序代做 源码分享】公众号获取更多免费源码!!!