其他常用算法与数据结构总结(板子)
文章目录
- 一、数据结构
-
- 1. 并查集
- 2. 差分数组
- 2. 树状数组
- 4. 线段树
- 5. 字典树
- 二、图论
-
- 1. 内向基环树
- 三、数学
-
- 1. 最大公因数GCD和最小公倍数LCM
- 2. 求质数(埃氏筛)
- 3. 蓄水池采样(Reservoir Sampling)
一、数据结构
1. 并查集
简单来说,并查集是一种以树形结构来表示不同种类数据的集合。一般当我们需要用到数据的连通性时会用到它。
并查集维护一个数组parent,parent数组中维护的不是元素本身,而是元素的下标索引,当然,这个下标索引是指向该元素的父元素的。
并查集的应用场景:
并查集的主要作用不是“存储数据”,而是“快速查询数据的状态或者关系”。
具体来讲,并查集的作用是,快速响应对元素所处的集合进行合并操作,以及快速查询两个元素是否属于同一个集合。(如判断节点联通性问题)
并查集模板:
①parent数组版本
路径压缩:主要针对find函数,当在寻找一个节点A的根节点root时,直接将节点A的父节点B、祖父节点C…等节点全部指向根节点root。
优点:这样在下次寻找A的根节点、B的根节点、C的根节点时可以节省很长一段搜索路径。
private class UnionFind {
//par数组用来存储根节点,par[x]=y表示x的根节点为y
private int[] parent;
public UnionFind(int n) {
parent = new int[n];
//初始化, 每个节点都是一个联通分量
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
//查找x所在集合的根(带路径压缩)
private int find(int x) {
if (x != parent[x]) {
//递归返回的同时压缩路径
parent[x] = find(parent[x]);
}
return parent[x];
}
//合并x与y所在集合
public void union(int x, int y) {
int xRoot = find(x);
int yRoot = find(y);
if (xRoot != yRoot) { //不是同一个根,即不在同一个集合,就合并
parent[xRoot] = yRoot;
}
}
}
②HashMap版本
https://blog.csdn.net/weixin_45545090/article/details/124343565
“并”表示合并,“查”表示查找,“集”表示集合。其基本思想是用 father[i] 表示元素 i 的父节点。例如 father[1] = 2 表示元素 1 的父节点是 2。如果 father[i] = i,那么说明 i 是根节点,根节点作为一个集合的标识。当然,如果不使用数组来记录,而使用 map 来记录,那么可以使用 father.get(i) = null 来表示根节点。
class UnionFind {
// 用 Map 在存储并查集,表达的含义是 key 的父节点是 value
private Map<Integer,Integer> father;
// 0.构造函数初始化,初始时各自为一个集合,用null来表示
public UnionFind(int n) {
father = new HashMap<Integer,Integer>();
for (int i = 0; i < n; i++) {
father.put(i, null);//或者father.put(i,i);
}
}
// 1.添加:初始加入时,每个元素都是一个独立的集合,因此
public void add(int x) { // 根节点的父节点为null
if (!father.containsKey(x)) {
father.put(x, null);//或者father.put(x,x); 根节点的父节点为自己
}
}
// 2.查找:反复查找父亲节点。
public int find(int x) {
int root = x; // 寻找x祖先节点保存到root中
while(father.get(root) != null){//或者father.get(root) != root
root = father.get(root);
}
while(x != root){ // 路径压缩,把x到root上所有节点都挂到root下面
int original_father = father.get(x); // 保存原来的父节点
father.put(x,root); // 当前节点挂到根节点下面
x = original_father; // x赋值为原来的父节点继续执行刚刚的操作
}
return root;
}
// 3.合并:把两个集合合并为一个,只需要把其中一个集合的根节点挂到另一个集合的根节点下方
//也可以记录两个集合的大小,根据大小将小集合父节点挂载到大集合父节点上
public void union(int x, int y) { // x的集合和y的集合合并
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY){ // 节点联通只需要一个共同祖先,无所谓谁是根节点
father.put(rootX,rootY);
}
}
// 4.判断:判断两个元素是否同属一个集合
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
}
2. 差分数组
前缀和主要适用的场景是原始数组不会被修改的情况下,频繁查询某个区间的累加和
差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减
差分数组使用场景:对于一个数组
nums[]要求一:对
num[2...4]全部+ 1要求二:对
num[1...3]全部- 3要求三:对
num[0...4]全部+ 9
差分算法是前缀和算法的逆运算,可以快速的对数组的某一区间进行计算操作。
例如,有一数列 a[1],a[2],.…a[n],且令 b[i] = a[i]-a[i-1],b[1]=a[1],
那么就有a[i] = b[1]+b[2]+.…+b[i] = a[1]+a[2]-a[1]+a[3]-a[2]+.…+a[i]-a[i-1],
此时b数组称作a数组的差分数组,换句话来说a数组就是b数组的前缀和数组
例:
原始数组a:9 3 6 2 6 8
差分数组b:9 -6 3 -4 4 2可以看到a数组是b数组的前缀和数组。
那么现在有一个任务:对数组a区间[left,right]每个元素加一个常数c。这时可以利用原数组就是差分数组的前缀和这个特性,来解决这个问题。对于b数组,只需要执行b[left] += c, b[right+1] −= c
如何得到更新后的数组元素值? 只需要累加即可:第i位值sum :sum += b[i]
2. 树状数组
引用:IndexTree及AC自动机:https://blog.csdn.net/qq_56999918/article/details/122729412
IndexTree适用范围:
求区间和或区间极值(最大最小值);
解决LIS问题。
涉及到动态排序时,可能适用;(也可以考虑使用PQ)
涉及到双指针(区间问题)时,可能适用;
涉及到散列化时,可能适用;
涉及到需要捆绑下标排序的相关问题时,可能适用。
BIT可以解决的问题,Index Tree都可以解决;Index Tree可以解决的问题,线段树都可以解决。

IndexTree所能解决的典型问题就是存在一个长度为n的数组**【如何高效的某一个范围内的前缀和】,智能的解决单点更新完怎么维护一个结构快速查询的一个累加和快的问题,其基本操作主要有:**
- int query(int index):求1到index位置的累加和
- void add(int index, int d): 将index位置的数加一个d
- int RangeSum(int index1, int index2): 求index1到index2上面的累加和
问题1:如何获取一个二进制序列中最右侧的1?
公式:n&(~n+1) == n&(-n)
在IndexTree中一般有一个helper数组对应i为位置管理了一段区间的累加和:举个例子
那么,假设有序列A = {1, 2, 3, 4, 5, 6, 7, 8},注意在help数组中0位置不用,从1位置开始。1位置管理1位置的元素,2位置往前一看1位置有一个和我长度一模一样的累加和于是2位置就管理
1~2位置的累加和。3位置一看前面只有没有和他一样长度的累加和,所以3就只能管理3位置的数字了,4位置一看前面有一个3是和我长度一样的,于是他们两就结成伴了长度就变成2了往前一看还有一个长度为1~2的,于是他们两就结合在一起了,所以4位置管理的是1~8位置的累加和,同理5 6 7 8 位置也可以按照相同的方法求出,这样我们就得到了help数组对应树形结构:
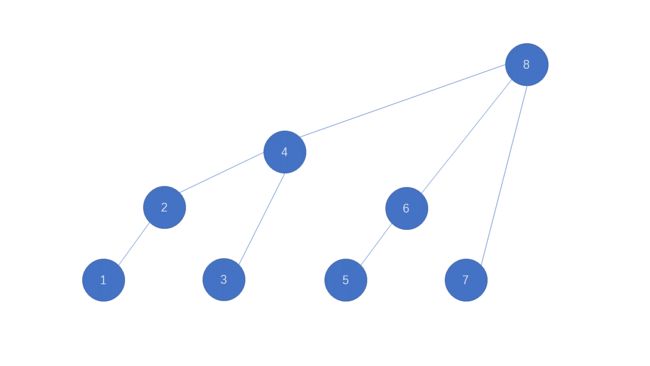
query(int index):假设我们想知道help数组中8位置对应位置管理的是哪个范围的累加和:首先我们只需要将8的二进制序列写出来 1000,我们将它最右边的1消掉在将这个数加1:也就是0000+1=0001他管理的范围就是消去最右边1的数+1到他本身也就是1~8.不信我们在尝试一个6:它对应的二进制序列为110,将其最右侧的1消去在加1得到101也就是5到6.
add(int index, int d)**:如果某一位置的值加上了某个数,必然会引起其他位置的值发生变化那么那些位置的值会发生变化呢?首先自己这个位置肯定会发生变化,其他位置通过计算得到,同样的先把其二进制序列写出来,将最右侧的1去出来和原来的数相加得到数就是会发生变化的位置,再重复上面这个过程,直到它大于n就结束。**将对应位置的值加上这个数即可这样我们就更新完成。
代码实现:
class BinaryIndexedTree{
private int n;
private int[] tree;
public BinaryIndexedTree(int n){
this.n = n;
tree = new int[n + 1];
}
// 将index位置加上val值
public void add(int index, int val){
while(index <= n){
tree[index] += val;
index += index & -index;
}
}
// 查询[0, index]的前缀和
public int query(int index) {
int s = 0;
while (index > 0) {
s += tree[index];
index -= index & -index;
}
return s;
}
// 返回[left, right]之间的区间和
public int RangeSum(int left, int right){
return query(right+1) - query(left);
}
}
带更新的树状数组:
307. 区域和检索 - 数组可修改
难度中等590
给你一个数组 nums ,请你完成两类查询。
- 其中一类查询要求 更新 数组
nums下标对应的值 - 另一类查询要求返回数组
nums中索引left和索引right之间( 包含 )的nums元素的 和 ,其中left <= right
实现 NumArray 类:
NumArray(int[] nums)用整数数组nums初始化对象void update(int index, int val)将nums[index]的值 更新 为valint sumRange(int left, int right)返回数组nums中索引left和索引right之间( 包含 )的nums元素的 和 (即,nums[left] + nums[left + 1], ..., nums[right])
class NumArray {
// 上来先把三个方法写出来(query()和add()是核心方法)
int[] tree;
int lowbit(int x){
return x & -x;
}
// 查询前缀和的方法
int query(int x){
int ans = 0;
for(int i = x; i > 0; i -= lowbit(i)) ans += tree[i];
return ans;
}
// 在树状数组 x 位置中增加值 u
void add(int x, int u){
for(int i = x; i <= n; i += lowbit(i)) tree[i] += u;
}
/
int[] nums;
int n;
// 初始化「树状数组」,要默认数组是从 1 开始
public NumArray(int[] nums) {
this.nums = nums;
n = nums.length;
tree = new int[n+1];
for(int i = 0; i < n; i++) add(i+1, nums[i]);
}
// 使用「树状数组」:
public void update(int index, int val) {
// 原有的值是 nums[i],要使得修改为 val,需要增加 val - nums[i]
add(index+1, val - nums[index]);
nums[index] = val;
}
public int sumRange(int left, int right) {
return query(right+1) - query(left);
}
}
练习题:1626. 无矛盾的最佳球队
4. 线段树
线段树详解:https://leetcode.cn/problems/range-module/solution/by-lfool-eo50/
什么样的问题可以用线段树解决?
区间范围上,统一增加,或者统一更新一个值。大范围信息可以只由左、右两侧信息加工出,而不必遍历左右两个子范围的具体状况。
线段树(segment tree),顾名思义, 是用来存放给定区间(segment, or interval)内对应信息的一种数据结构。与树状数组(binary indexed tree)相似,线段树也用来处理数组相应的区间查询(range query)和元素更新(update)操作。
与树状数组不同的是,线段树不止可以适用于区间求和的查询,也可以进行区间最大值,区间最小值(Range Minimum/Maximum Query problem)或者区间异或值的查询。
根据题目问题,改变表示的含义!!,如:
- 数字之和「总数字之和 = 左区间数字之和 + 右区间数字之和」
- 最大公因数 (GCD)「总 GCD = gcd(左区间 GCD, 右区间 GCD)」
- 最大值「总最大值 = max(左区间最大值,右区间最大值)」
不符合区间加法的例子:
众数「只知道左右区间的众数,没法求总区间的众数」
01 序列的最长连续零「只知道左右区间的最长连续零,没法知道总的最长连续零」
对于一个线段树来说**,其应该支持的两种操作为:**
- Update:更新输入数组中的某一个元素并对线段树做相应的改变。
- **Query:**用来查询某一区间对应的信息(如最大值,最小值,区间和等)。
所以线段树主要实现两个方法:「求区间和」&&「修改区间」,且时间复杂度均为 O(logn)。
始终记住一句话:线段树的每个节点代表一个区间
线段树完整模板
注意:下面模版基于求「区间和」以及对区间进行「加减」的更新操作,且为「动态开点」
public class SegmentTreeDynamic {
class Node {
Node left, right;
int val, add;
}
private int N = (int) 1e9;
private Node root = new Node();
//初始值start和end是固定的0-N,l和r是要更新的区间,更新值为val
public void update(Node node, int start, int end, int l, int r, int val) {
if (l <= start && end <= r) {
node.val += (end - start + 1) * val;
node.add += val;
return ;
}
int mid = (start + end) >> 1;
pushDown(node, mid - start + 1, end - mid);
if (l <= mid) update(node.left, start, mid, l, r, val);
if (r > mid) update(node.right, mid + 1, end, l, r, val);
pushUp(node);
}
public int query(Node node, int start, int end, int l, int r) {
if (l <= start && end <= r) return node.val;
int mid = (start + end) >> 1, ans = 0;
pushDown(node, mid - start + 1, end - mid);
if (l <= mid) ans += query(node.left, start, mid, l, r);
if (r > mid) ans += query(node.right, mid + 1, end, l, r);
return ans;
}
private void pushUp(Node node) {
node.val = node.left.val + node.right.val;
}
private void pushDown(Node node, int leftNum, int rightNum) {
if (node.left == null) node.left = new Node();
if (node.right == null) node.right = new Node();
if (node.add == 0) return ;
node.left.val += node.add * leftNum;
node.right.val += node.add * rightNum;
// 对区间进行「加减」的更新操作,下推懒惰标记时需要累加起来,不能直接覆盖
node.left.add += node.add;
node.right.add += node.add;
node.add = 0;
}
}
线段树的建立
public void buildTree(Node node, int start, int end) {
// 到达叶子节点
if (start == end) {
node.val = arr[start];
return ;
}
int mid = (start + end) >> 1;
node.left = new Node();node.right = new Node();
buildTree(node.left, start, mid);
buildTree(node.right, mid + 1, end);
// 向上更新
pushUp(node);
}
// 向上更新
private void pushUp(Node node) {
node.val = node.left.val + node.right.val;
}
带注释版:
注意:下面模版基于求「区间和」以及对区间进行「加减」的更新操作,且为「动态开点」
public class SegmentTreeDynamic {
class Node {
Node left, right; // 左右孩子节点
int val; // 当前节点值
int add; // 懒惰标记
}
private int N = (int) 1e9;
private Node root = new Node();
//初始值start和end是固定的0-N,l和r是要更新的区间,更新值为val
public void update(Node node, int start, int end, int l, int r, int val) {
// 找到满足要求的区间
if (l <= start && end <= r) {
// 区间节点加上更新值
// 注意:需要✖️该子树所有叶子节点
node.val += (end - start + 1) * val;
// 添加懒惰标记
// 对区间进行「加减」的更新操作,懒惰标记需要累加,不能直接覆盖
node.add += val;
return ;
}
int mid = (start + end) >> 1;
// 下推标记
// mid - start + 1:表示左孩子区间叶子节点数量
// end - mid:表示右孩子区间叶子节点数量
pushDown(node, mid - start + 1, end - mid);
// [start, mid] 和 [l, r] 可能有交集,遍历左孩子区间
if (l <= mid) update(node.left, start, mid, l, r, val);
// [mid + 1, end] 和 [l, r] 可能有交集,遍历右孩子区间
if (r > mid) update(node.right, mid + 1, end, l, r, val);
// 向上更新
pushUp(node);
}
// 在区间 [start, end] 中查询区间 [l, r] 的结果,即 [l ,r] 保持不变
// 对于上面的例子,应该这样调用该函数:query(root, 0, 4, 2, 4)
public int query(Node node, int start, int end, int l, int r) {
// 区间 [l ,r] 完全包含区间 [start, end]
// 例如:[2, 4] = [2, 2] + [3, 4],当 [start, end] = [2, 2] 或者 [start, end] = [3, 4],直接返回
if (l <= start && end <= r) return node.val;
// 把当前区间 [start, end] 均分得到左右孩子的区间范围
// node 左孩子区间 [start, mid]
// node 左孩子区间 [mid + 1, end]
int mid = (start + end) >> 1, ans = 0;
// 下推标记
pushDown(node, mid - start + 1, end - mid);
// [start, mid] 和 [l, r] 可能有交集,遍历左孩子区间
if (l <= mid) ans += query(node.left, start, mid, l, r);
// [mid + 1, end] 和 [l, r] 可能有交集,遍历右孩子区间
if (r > mid) ans += query(node.right, mid + 1, end, l, r);
// ans 把左右子树的结果都累加起来了,与树的后续遍历同理
return ans;
}
private void pushUp(Node node) {
node.val = node.left.val + node.right.val;
}
// leftNum 和 rightNum 表示左右孩子区间的叶子节点数量
// 因为如果是「加减」更新操作的话,需要用懒惰标记的值✖️叶子节点的数量
private void pushDown(Node node, int leftNum, int rightNum) {
// 动态开点
if (node.left == null) node.left = new Node();
if (node.right == null) node.right = new Node();
// 如果 add 为 0,表示没有标记
if (node.add == 0) return;
// 注意:当前节点加上标记值✖️该子树所有叶子节点的数量
node.left.val += node.add * leftNum;
node.right.val += node.add * rightNum;
// 把标记下推给孩子节点
// 对区间进行「加减」的更新操作,下推懒惰标记时需要累加起来,不能直接覆盖
node.left.add += node.add;
node.right.add += node.add;
// 取消当前节点标记
node.add = 0;
}
}
拓展:
- 对于表示为「区间和」且对区间进行「加减」的更新操作的情况,我们在更新节点值的时候『需要✖️左右孩子区间叶子节点的数量 (注意是叶子节点的数量)』;我们在下推懒惰标记的时候『需要累加』!!(这种情况和模版一致!!) 如题目 最近的请求次数
- 对于表示为「区间和」且对区间进行「覆盖」的更新操作的情况,我们在更新节点值的时候『需要✖️左右孩子区间叶子节点的数量 (注意是叶子节点的数量)』;我们在下推懒惰标记的时候『不需要累加』!!(因为是覆盖操作!!) 如题目 区域和检索 - 数组可修改
- 对于表示为「区间最值」且对区间进行「加减」的更新操作的情况,我们在更新节点值的时候『不需要✖️左右孩子区间叶子节点的数量 (注意是叶子节点的数量)』;我们在下推懒惰标记的时候『需要累加』!! 如题目 我的日程安排表 I、我的日程安排表 III
5. 字典树
208. 实现 Trie (前缀树)
Trie树(又叫「前缀树」或「字典树」)是一种用于快速查询「某个字符串/字符前缀」是否存在的数据结构。
其核心是使用「边」来代表有无字符,使用「点」来记录是否为「单词结尾」以及「其后续字符串的字符是什么」。
TrieNode实现:
class Trie {
class TrieNode{//字典树的结点数据结构
boolean end;//是否是单词末尾的标识
int pass; // 经过这个结点的次数(根据需要设置这个变量)
TrieNode[] child; //26个小写字母的拖尾
public TrieNode(){
end = false;
pass = 0;
child = new TrieNode[26];
}
}
TrieNode root;//字典树的根节点。
public Trie() {
root = new TrieNode();
}
public void insert(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
//若当前结点下没有找到要的字母,则新开结点继续插入
if (p.child[u] == null) p.child[u] = new TrieNode();
p = p.child[u];
p.pass++;
}
p.end = true;
}
public boolean search(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
if (p.child[u] == null) return false;//变化点(根据题意)
p = p.child[u];
}
return p.end;
}
public boolean startsWith(String s) {
TrieNode p = root;
for(int i = 0; i < s.length(); i++) {
int u = s.charAt(i) - 'a';
if (p.child[u] == null) return false;
p = p.child[u];
}
return true;
}
}
二、图论
1. 内向基环树
https://leetcode.cn/problems/maximum-employees-to-be-invited-to-a-meeting/solution/nei-xiang-ji-huan-shu-tuo-bu-pai-xu-fen-c1i1b/
1、基环树定义
从 i i i 向 favorite [ i ] \textit{favorite}[i] favorite[i]连边,我们可以得到一张有向图。由于每个大小为 k k k 的连通块都有 k k k 个点和 k k k 条边,所以每个连通块必定有且仅有一个环,且由于每个点的出度均为1,这样的有向图又叫做内向基环树 (pseudotree),由基环树组成的森林叫基环树森林 (pseudoforest)。
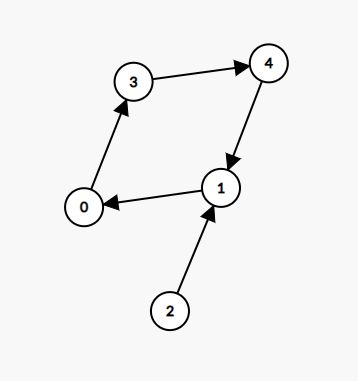
每一个内向基环树(连通块)都由一个基环和其余指向基环的树枝组成。例如示例 [ 3 , 0 , 1 , 4 , 1 ] [3,0,1,4,1] [3,0,1,4,1] 可以得到如下内向基环树,其基环由节点 0、1、3 和 4 组成,节点 2 为其树枝:
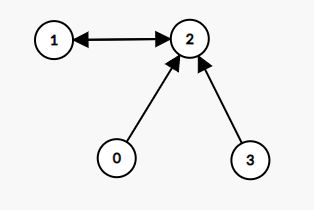
特别地,我们得到的基环可能只包含两个节点。例如示例 [ 2 , 2 , 1 , 2 ] [2,2,1,2] [2,2,1,2]可以得到如下内向基环树,其基环只包含节点 1 和 2,而节点 0 和 3 组成其树枝:
2、基环树问题的通用处理方法
下面介绍基环树问题的通用处理方法:
我们可以通过一次拓扑排序「剪掉」所有树枝,因为拓扑排序后,树枝节点的入度均为 0,基环节点的入度均为 1。这样就可以将基环和树枝分开,从而简化后续处理流程:
- 如果要遍历基环,可以从拓扑排序后入度为 1 的节点出发,在图上搜索;
- 如果要遍历树枝,可以以基环与树枝的连接处为起点,顺着反图来搜索树枝(搜索入度为 0 的节点),从而将问题转化成一个树形问题。
2127. 参加会议的最多员工数
难度困难75
一个公司准备组织一场会议,邀请名单上有 n 位员工。公司准备了一张 圆形 的桌子,可以坐下 任意数目 的员工。
员工编号为 0 到 n - 1 。每位员工都有一位 喜欢 的员工,每位员工 当且仅当 他被安排在喜欢员工的旁边,他才会参加会议。每位员工喜欢的员工 不会 是他自己。
给你一个下标从 0 开始的整数数组 favorite ,其中 favorite[i] 表示第 i 位员工喜欢的员工。请你返回参加会议的 最多员工数目 。
示例 1:

输入:favorite = [2,2,1,2]
输出:3
解释:
上图展示了公司邀请员工 0,1 和 2 参加会议以及他们在圆桌上的座位。
没办法邀请所有员工参与会议,因为员工 2 没办法同时坐在 0,1 和 3 员工的旁边。
注意,公司也可以邀请员工 1,2 和 3 参加会议。
所以最多参加会议的员工数目为 3 。
示例 2:
输入:favorite = [1,2,0]
输出:3
解释:
每个员工都至少是另一个员工喜欢的员工。所以公司邀请他们所有人参加会议的前提是所有人都参加了会议。
座位安排同图 1 所示:
- 员工 0 坐在员工 2 和 1 之间。
- 员工 1 坐在员工 0 和 2 之间。
- 员工 2 坐在员工 1 和 0 之间。
参与会议的最多员工数目为 3 。
示例 3:

输入:favorite = [3,0,1,4,1]
输出:4
解释:
上图展示了公司可以邀请员工 0,1,3 和 4 参加会议以及他们在圆桌上的座位。
员工 2 无法参加,因为他喜欢的员工 0 旁边的座位已经被占领了。
所以公司只能不邀请员工 2 。
参加会议的最多员工数目为 4 。
提示:
n == favorite.length2 <= n <= 1050 <= favorite[i] <= n - 1favorite[i] != i
对于本题来说,这两类基环树在组成圆桌时会有明显区别,下文会说明这一点。
先来看看基环大小大于 2 的情况:
- 显然基环上的节点组成了一个环,因而可以组成一个圆桌;而树枝上的点,若插入圆桌上 v → w v\rightarrow w v→w这两人中间,会导致节点 v 无法和其喜欢的员工坐在一起,因此树枝上的点是无法插入圆桌的;此外,树枝上的点也不能单独组成圆桌,因为这样会存在一个出度为 0 的节点,其无法和其喜欢的员工坐在一起。对于其余内向基环树(连通块)上的节点,和树枝同理,也无法插入该基环组成的圆桌。
因此,**对于基环大小大于 2 的情况,圆桌的最大员工数目即为最大的基环大小,记作 ** maxRingSize \textit{maxRingSize} maxRingSize
下面来分析基环大小等于 2 的情况:
以如下基环树为例,0 和 1 组成基环,其余节点组成树枝:
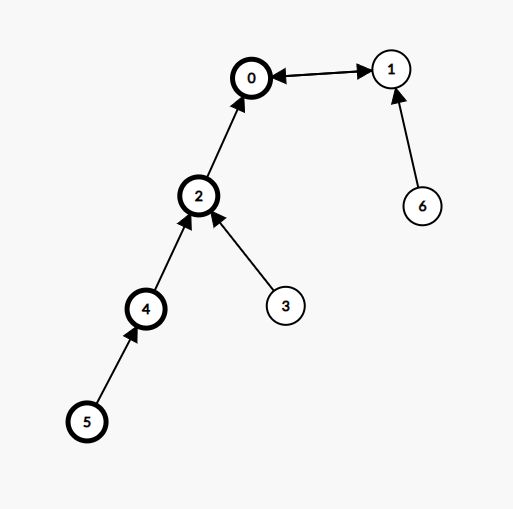
我们可以先让 0 和 1 坐在圆桌旁(假设 0 坐在 1 左侧),那么 0 这一侧的树枝只能坐在 0 的左侧,而 1 这一侧的树枝只能坐在 1 的右侧。
2 可以紧靠着坐在 0 的左侧,而 3 和 4 只能选一个坐在 2 的左侧(如果 4 紧靠着坐在 2 的左侧,那么 3 是无法紧靠着坐在 4 的左侧的,反之亦然)。
这意味着从 0 出发倒着找树枝上的点(即沿着反图上的边),每个点只能在其反图上选择其中一个子节点,因此 0 这一侧的节点必须组成一条链,那么我们可以找最长的那条链,即上图加粗的节点。
对于 1 这一侧也同理。将这两条最长链拼起来即为该基环树能组成的圆桌的最大员工数。
对于多个基环大小等于 2 的基环树,每个基环树所对应的链,都可以拼在其余链的末尾,因此我们可以将这些链全部拼成一个圆桌,其大小记作 sumChainSize \textit{sumChainSize} sumChainSize。
答案即为 max ( maxRingSize , sumChainSize ) \max(\textit{maxRingSize},\textit{sumChainSize}) max(maxRingSize,sumChainSize)
对于本题,我们可以遍历所有基环,并按基环大小分类计算:
对于大小大于 2 的基环,我们取基环大小的最大值;
对于大小等于 2 的基环,我们可以从基环上的点出发,在反图上找到最大的树枝节点深度。
class Solution {
List<Integer>[] rg; // g的反图
int[] degree; // g上每个节点的入度
public int maximumInvitations(int[] g) {
int n = g.length;
rg = new ArrayList[n];
Arrays.setAll(rg, e -> new ArrayList<>());
degree = new int[n];
for(int v = 0; v < n; v++){
int w = g[v]; // v->w
rg[w].add(v);
degree[w]++; //rg反图上记录下w->v,并且w入度+1
}
// 拓扑排序,剪掉g上的所有树枝(入度 =0 的节点)
Deque<Integer> dq = new ArrayDeque<>();
for(int i = 0; i < n; i++){
if(degree[i] == 0) dq.addLast(i);
}
while(!dq.isEmpty()){
int v = dq.pollFirst();
int w = g[v]; // v->w,v只有一条出边
if(--degree[w] == 0) dq.addLast(w);
}
// 大小>2的基环:基环大小的最大值maxRingSize
// 大小=2的基环,从基环上的点出发,反向找到树枝的最大深度sumChainSize
int maxRingSize = 0, sumChainSize = 0;
for(int i = 0; i < n; i++){
if(degree[i] <= 0) continue;
//遍历基环上的点(拓扑排序后入度>0的点)
degree[i] = -1;
int ringsize = 1; // tmp环的大小
for(int v = g[i]; v != i; v = g[v]){ //环循环终止条件v!= i,即转一圈
degree[v] = -1; //将基环上的点的入度标记为-1,避免重复访问
ringsize++;
}
//遍历树枝-----------------------------------------------------------------
if(ringsize == 2){ //基环大小为2,累加两条最长链的长度
sumChainSize += rdfs(i) + rdfs(g[i]); // i->g[i],g[i]->i,因此从两个点出发找最长链的长度
}else{// 基环大小 >2, 取所有基环的最大值
//取基环最大值-------------------------------------------------------------
maxRingSize = Math.max(maxRingSize, ringsize);
}
}
return Math.max(maxRingSize, sumChainSize);
}
// 类似树的直径问题,只不过不用求树的直径,而是求当前节点的最大直径(不需要更新全局变量直径长度)
public int rdfs(int v){
int maxdepth = 1;
for(int w : rg[v]){ //w->v,在反图中v包含了所有指向v的树枝,枚举找最大值
if(degree[w] == 0){ //树枝上的点在拓扑排序后,入度均为 0
maxdepth = Math.max(maxdepth, rdfs(w) + 1);
}
}
return maxdepth;
}
}
其他类似问题
- 2360. 图中的最长环
三、数学
1. 最大公因数GCD和最小公倍数LCM
// 最大公因数GCD:两个或多个整数共有约数中最大的一个
// 辗转相除法
public int gcd(int x, int y) {
return y == 0 ? x : gcd(y, x % y);
}
// 最小公倍数LCM:两个或多个整数公有的倍数叫做它们的公倍数,
// 其中除0以外最小的一个公倍数就叫做这几个整数的最小公倍数。
public int lcm(int x, int y) {
return (x * y) / gcd(x, y);
}
2. 求质数(埃氏筛)
质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
private static void euler() {
int n = (int)1e5;
//判断是否是质数,1-质数 0-合数
int[] isPrime = new int[n];
// 存放质数
int[] primes = new int[n];
int k = 0;//存放质数数组的索引下标
Arrays.fill(isPrime, 1);
isPrime[1] = 0; // 1不是质数
for(int i = 2; i < n; i++) {
if(isPrime[i] == 1){
primes[k++] = i;
}
// 枚举已经筛出来的素数prime[j](j=1~cnt)
for(int j = 0; primes[j] * i < n; j++){
//筛掉i的素数倍,即i的prime[j]倍
isPrime[primes[j] * i] = 0;//每个质数都和i相乘得到合数
//如果i整除prime[j],退出循环,保证线性时间复杂度
if (i % primes[j] == 0) //primes[j]是i的一个质因数
break;
}
}
}
3. 蓄水池采样(Reservoir Sampling)
1、问题描述分析:
采样问题经常会被遇到,比如:
- 从 100000 份调查报告中抽取 1000 份进行统计。
- 从一本很厚的电话簿中抽取 1000 人进行姓氏统计。
- 从 Google 搜索 “Ken Thompson”,从中抽取 100 个结果查看哪些是今年的。
这些都是很基本的采用问题。
既然说到采样问题,最重要的就是做到公平,也就是保证每个元素被采样到的概率是相同的。所以可以想到要想实现这样的算法,就需要掷骰子,也就是随机数算法。(这里就不具体讨论随机数算法了,假定我们有了一套很成熟的随机数算法了)
对于第一个问题,还是比较简单,通过算法生成 [0,100000−1) 间的随机数 1000 个,并且保证不重复即可。再取出对应的元素即可。
但是对于第二和第三个问题,就有些不同了,我们不知道数据的整体规模有多大。可能有人会想到,我可以先对数据进行一次遍历,计算出数据的数量 N,然后再按照上述的方法进行采样即可。这当然可以,但是并不好,毕竟这可能需要花上很多时间。也可以尝试估算数据的规模,但是这样得到的采样数据分布可能并不平均。
2、蓄水池采样算法(Reservoir Sampling)
算法的过程:
假设数据序列的规模为 n,需要采样的数量的为 k。
首先构建一个可容纳 k 个元素的数组,将序列的前 k 个元素放入数组中。
然后从第 k+1 个元素开始,以 k/n 的概率来决定该元素最后是否被留在数组中(每进来一个新的元素,数组
中的每个旧元素被替换的概率是相同的)。 当遍历完所有元素之后,数组中剩下的元素即为所需采取的样本。
- 不证明
398. 随机数索引
难度中等264
给你一个可能含有 重复元素 的整数数组 nums ,请你随机输出给定的目标数字 target 的索引。你可以假设给定的数字一定存在于数组中。
实现 Solution 类:
Solution(int[] nums)用数组nums初始化对象。int pick(int target)从nums中选出一个满足nums[i] == target的随机索引i。如果存在多个有效的索引,则每个索引的返回概率应当相等。
示例:
输入
["Solution", "pick", "pick", "pick"]
[[[1, 2, 3, 3, 3]], [3], [1], [3]]
输出
[null, 4, 0, 2]
解释
Solution solution = new Solution([1, 2, 3, 3, 3]);
solution.pick(3); // 随机返回索引 2, 3 或者 4 之一。每个索引的返回概率应该相等。
solution.pick(1); // 返回 0 。因为只有 nums[0] 等于 1 。
solution.pick(3); // 随机返回索引 2, 3 或者 4 之一。每个索引的返回概率应该相等。
提示:
1 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 1target是nums中的一个整数- 最多调用
pick函数104次
class Solution {
Random random = new Random();
private int[] nums;
public Solution(int[] nums) {
this.nums = nums;
}
public int pick(int target) {
int count = 0;
int ans = -1;
for(int i = 0; i < nums.length; i++){
if(nums[i] == target){
// 1 1/2 1/3 1/4 的概率替换
count++;
if(random.nextInt(count)==0) ans = i;
}
}
return ans;
}
}