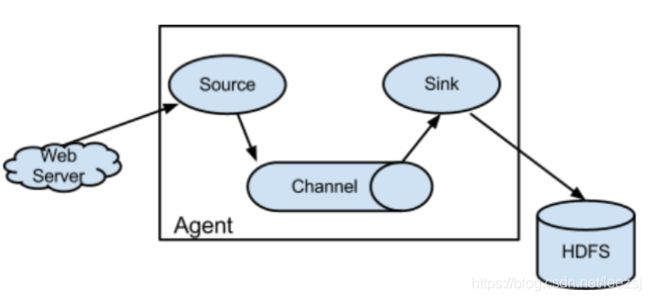
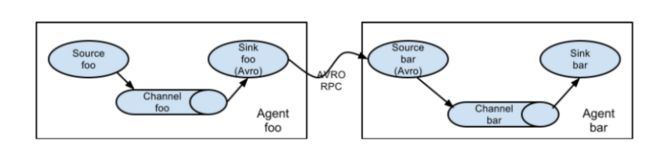
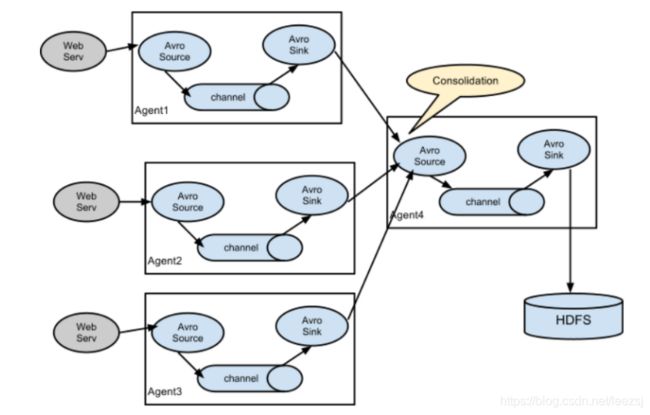
# list the sources, sinks and channels for the agent
.sources = .sinks = .channels =
# set channel for source
.sources..channels = ...
# set channel for sink
.sinks..channel =
# list the sources, sinks and channels for the agent
agent_foo.sources = avro-appserver-src-1
agent_foo.sinks = hdfs-sink-1
agent_foo.channels = mem-channel-1
# set channel for source
agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1
# set channel for sink
agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
配置组件属性
# properties for sources
.sources.. =
# properties for channels
.channel.. =
# properties for sinks
.sources.. =
以教员和课程为例介绍一对多关联关系,在这里认为一个教员可以叫多门课程,而一门课程只有1个教员教,这种关系在实际中不太常见,通过教员和课程是多对多的关系。
示例数据:
地址表:
CREATE TABLE ADDRESSES
(
ADDR_ID INT(11) NOT NULL AUTO_INCREMENT,
STREET VAR
In this lesson we used the key "UITextAttributeTextColor" to change the color of the UINavigationBar appearance to white. This prompts a warning "first deprecated in iOS 7.0."
Ins
质数也叫素数,是只能被1和它本身整除的正整数,最小的质数是2,目前发现的最大的质数是p=2^57885161-1【注1】。
判断一个数是质数的最简单的方法如下:
def isPrime1(n):
for i in range(2, n):
if n % i == 0:
return False
return True
但是在上面的方法中有一些冗余的计算,所以
hbase(hadoop)是用java编写的,有些语言(例如python)能够对它提供良好的支持,但也有很多语言使用起来并不是那么方便,比如c#只能通过thrift访问。Rest就能很好的解决这个问题。Hbase的org.apache.hadoop.hbase.rest包提供了rest接口,它内嵌了jetty作为servlet容器。
启动命令:./bin/hbase rest s
下面这段sql本来目的是想更新条件下的数据,可是这段sql却更新了整个表的数据。sql如下:
UPDATE tops_visa.visa_order
SET op_audit_abort_pass_date = now()
FROM
tops_visa.visa_order as t1
INNER JOIN tops_visa.visa_visitor as t2
ON t1.