索引库操作
目录
对索引库的操作:创建、删除、查看
文档操作
总结:
利用RestClient对索引库进行创建、删除...
利用RestClient实现文档的CRUD
批量导入功能
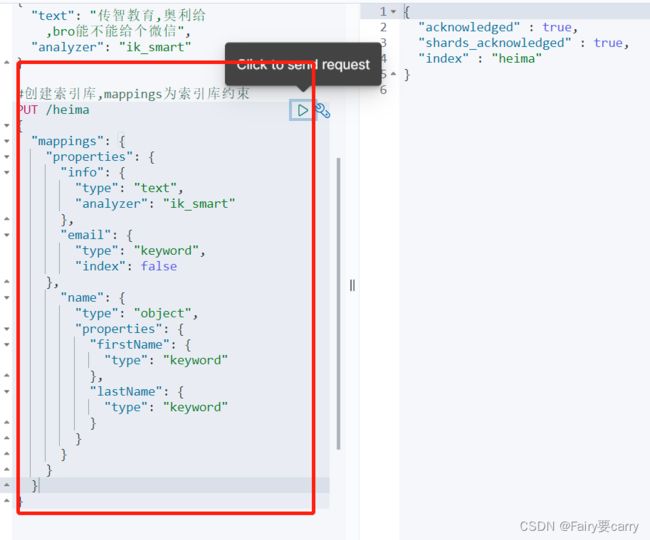
有了索引库相当于数据库database,而接下来,就是需要索引库中的类型了,也就是数据库中的表;创建表——>需要设置字段的约束;索引库也一样——>在创建索引库类型的时候,需要知道这个类型下有哪些字段(每个字段对应一些约束信息)——>这些字段以及对应的约束信息就叫:字段映射

下图右侧为json文档,左侧为约束:

mapping常见属性:
type:数据类型->记住,es中是没有数组的,但是数组中的属性是有类型的
keyword——>不分词
text——>代表要分词

index:是否索引(是否参与搜索)
true:表示字段会被索引(可以用来搜索),false:不能用来搜索;
analyzer:对text可分词文本的一个分词器
Properties:字段的子字段
(14条消息) Elasticsearch索引库、类型与文档_KeepMoving++的博客-CSDN博客_es索引类型文档
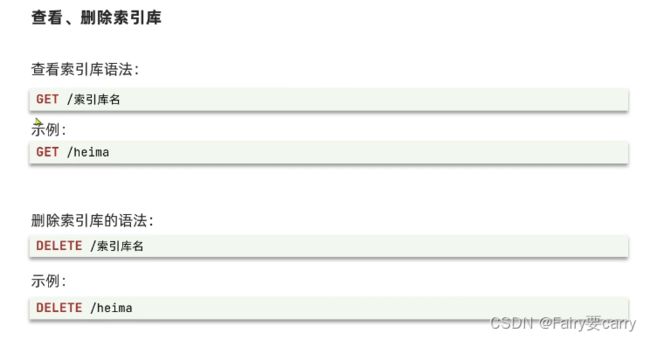
对索引库的操作:创建、删除、查看
符合RestFul风格:
不能修改索引库:
索引库和mapping映射(约束)一旦创建就无法修改,但是可以加入新的字段(新的字段名)

文档操作
根据前面对索引库的操作:对里面的类型(相当于数据库中的表)中的字段映射——>进行赋值,就是文档操作
doc:相当于数据库中的表,也就是这里的类型(type)(里面包含一条条数据)
mappings:字段的数据类型、属性、是否索引、是否存储等特性
doc后面的1:就是一条数据
每次进行写操作(插入),version版本+1

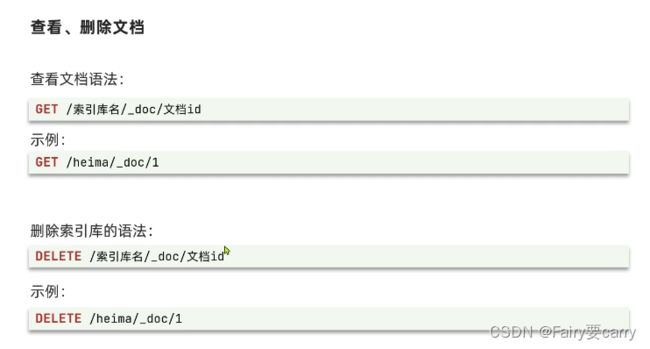
修改文档
全量修改:PUT /索引库名 /_doc /文档id {json文档}——>先删除,在修改
增量修改:(局部修改字段)POST /索引库名 /_update /文档id {“doc”:{字段}}



RestClient操作索引库
类似于RestTemplate,利用Java代码完成es操作

案例


问:如何实现一个字段里搜索到多个字段的内容?

这样你根据一个字段进行搜索,可以搜索出 多个字段的内容,而且你看不到其他字段名称;
#酒店mappings
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "{all}"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "{all}"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "{all}"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
总结:
在我们定义mapping映射时->主要考虑字段名字,类型,以及是否分词(所用分词器),是否支持搜索;
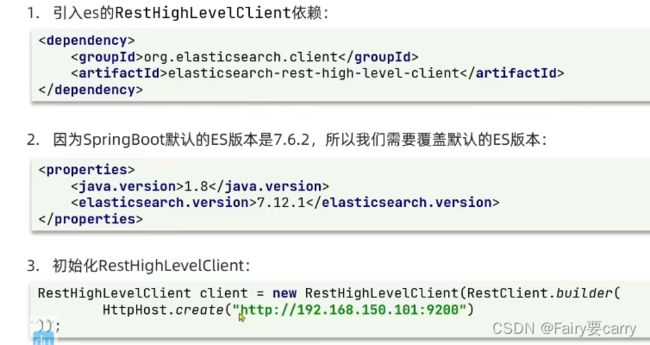
三个步骤,1、引入es客户端依赖;2、修改boot默认es依赖;3、初始化es客户端:RestHighLevelClient
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.12.1
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
/**
* @author diao 2022/5/20
*/
@SpringBootTest
public class HotelIndexTest {
private RestHighLevelClient client;
@Test
void test(){
System.out.println(client);
}
//初始化RestClient客户端
@BeforeEach
void setUp() {
this.client=new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.184.129:9200")
));
}
//关闭RestHighLevelClient
@AfterEach
void afterAll() throws IOException {
this.client.close();
}
}
![]()
利用RestClient对索引库进行创建、删除...
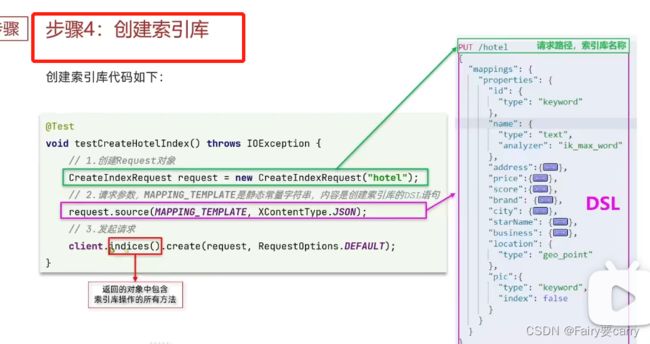
1.首先先初始化RestHighLevelClient:相当于es的客户端,可以利用它完成es的操作
2.创建索引库的请求:xxxIndexRequest,CREATE就是创建锁库,DELETE就是删除....
3.准备mappings,进行约束
4.发送请求,利用RestHighLevelClient.indices()得到索引库信息,里面封装了对于索引库的操作
/**
* @author diao 2022/5/20
*/
@SpringBootTest
public class HotelIndexTest {
private RestHighLevelClient client;
@Test
void test(){
System.out.println(client);
}
@Test
void createHotelIndex() throws IOException {
//1.创建请求对象,获取索引库
CreateIndexRequest request = new CreateIndexRequest("hotel");
//2.准备请求的参数,也就是实体中参数的约束mappings(转为json数据)
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3.发送请求,indices:得到索引库对象里面包括对索引库的操作:创建、删除...
client.indices().create(request, RequestOptions.DEFAULT);
}
@Test
void DeleteHotelIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request,RequestOptions.DEFAULT);
}
@Test
void JudgeExistsHotelIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists?"索引库已经存在!":"索引库不存在!");
}
//初始化RestClient客户端
@BeforeEach
void setUp() {
this.client=new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.184.129:9200")
));
}
//关闭RestHighLevelClient
@AfterEach
void afterAll() throws IOException {
this.client.close();
}
}

利用RestClient实现文档的CRUD
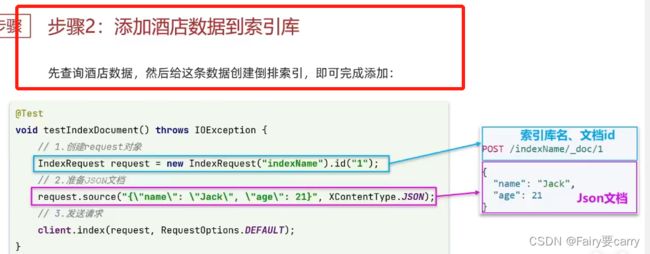
步骤:
1.先查询得到酒店数据
2.因为es中的字段与数据库中酒店字段不一致,所以我们需要一个中间类去规范
3.得到request对象——>new IndexRequest("hotel").id(数据库中酒店id)
4.得到JSON文档——>request.source();
5.最后利用RestClient发出请求即可
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import static cn.itcast.hotel.constants.HotelConstants.MAPPING_TEMPLATE;
/**
* @author diao 2022/5/20
*/
@SpringBootTest
public class HotelDocumentTest {
@Autowired
private IHotelService hotelService;
private RestHighLevelClient client;
@Test
void testAddDocument() throws IOException {
//根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
//我们将Hotel类型转为文档类型以此满足经纬度变成一个字段
HotelDoc hotelDoc = new HotelDoc(hotel);
//1.(根据索引库名称->进而得到文档request对象)
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
//2.准备json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
@BeforeEach
void beforeAll() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.184.129:9200")
));
}
//关闭RestHighLevelClient
@AfterEach
void afterAll() throws IOException {
this.client.close();
}
}
然后我们在Kibana中请求获取文档数据


对文档进行CRUD的代码
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("hotel", "61083");
client.delete(request,RequestOptions.DEFAULT);
}
@Test
void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("hotel", "61083");
request.doc(
"price","999",
"startName","西站"
);
client.update(request,RequestOptions.DEFAULT);
}
@Test
void testGetDocumentById() throws IOException {
//1.准备Request对象
GetRequest request = new GetRequest("hotel", "61083");
//2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3.解析响应结果
String json = response.getSourceAsString();
//再转为HotelDoc类型
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
@Test
void testAddDocument() throws IOException {
//根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
//我们将Hotel类型转为文档类型以此满足经纬度变成一个字段
HotelDoc hotelDoc = new HotelDoc(hotel);
//1.(根据索引库名称->进而得到文档request对象)
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
//2.准备json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//3.发送请求
client.index(request, RequestOptions.DEFAULT);
}和对索引库进行CRUD的区别主要在于:索引库是XXXIndexRequest获取请求对象,而文档的话就不需要Index,直接XXXRequest即可
只有在更新文档以及创建文档时才需要调用参数,前者:doc方法 ;后者:source方法

批量导入功能

其实就是将request请求的数据全都放在了Bulk中
@Test
void testBulkRequest() throws IOException {
//批量查询酒店数据
List hotels = hotelService.list();
//1.创建Request对象
BulkRequest request = new BulkRequest();
//2.给request对象增加参数,指定索引库的文档(也就是表)
for (Hotel hotel : hotels) {
HotelDoc hotelDoc = new HotelDoc(hotel);
//创建文档的request对象,并且source增加文档
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
//3.发送请求
client.bulk(request,RequestOptions.DEFAULT);
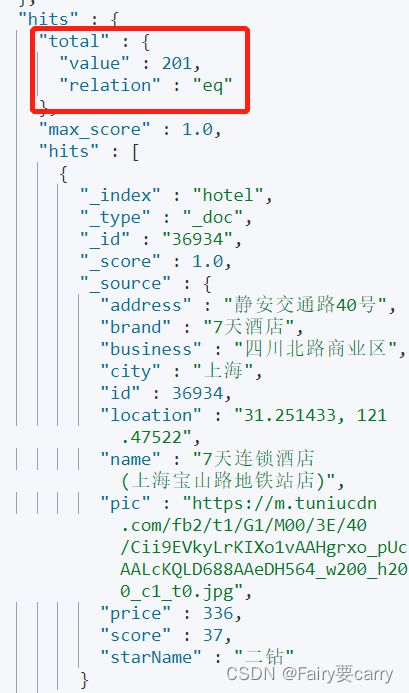
} 总共查询到了201条数据:_search批量查询
GET /hotel/_search