部分面试题记录
Spring相关:
1. spring框架中的单例bean是线程安全的嘛?
1.1 bean单例多例配置:
bean可以手动设置单例或者多例:
@Service
@Scope("singleton")
public class UserServicelmpl implements UserService {
}
- singleton:bean在每个Spring lOC容器中只有一个实例。
- prototype:一个bean的定义可以有多个实例。
1.2 分析:

其中UserService是没有可变的状态(即是不能被修改的),所以是线程安全的;
但是对于自定义的成员变量,就会有线程安全问题出现。
1.3 问题回答:

标准回答:

2. 什么是AOP,你们项目中有没有使用过AOP?
2.1 AOP概念解析:
AOP称为面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面” (Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。
常见的AOP使用场景
- 记录操作日志
- 缓存处理
- Spring中内置的事务处理
- 接口入参校验
2.2 记录操作日志举例分析

- 例如,如下请求,我们可以记录日志:
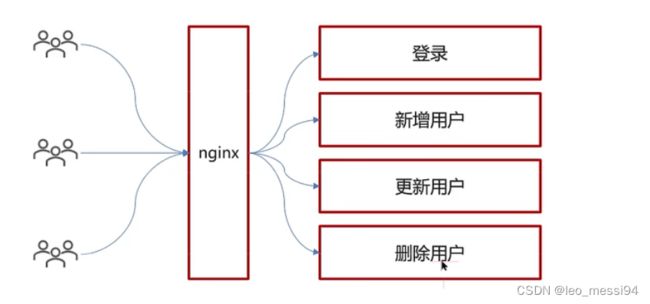
- 其中对于新增用户,我们可以添加环绕通知,来记录一些日志:

- 可以通过自定义注解,在新增用户的方法上加上我们的注解,来给此方法添加环绕通知。
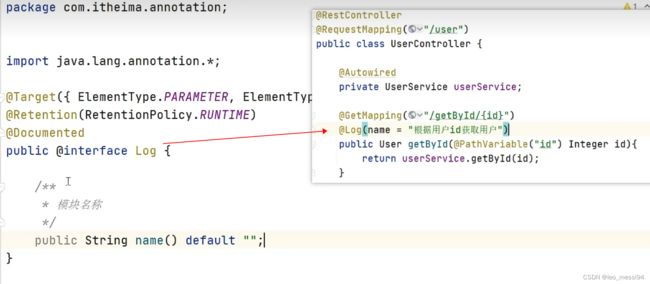
- 接着通过pointcut注解,关联到我们添加了注解的类,调用环绕通知,执行环绕通知中的内容,来完成参数等信息的获取及日志的收集

2.2 spring中的事务是如何实现的?
Spring支持编程式事务管理和声明式事务管理两种方式:
- 编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用
- 声明式事务管理:声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。

2.3 问题解答:

3. 事务失效的场景:
- 异常捕获处理
- 抛出检查异常
- 非public方法
3.1 异常捕获处理

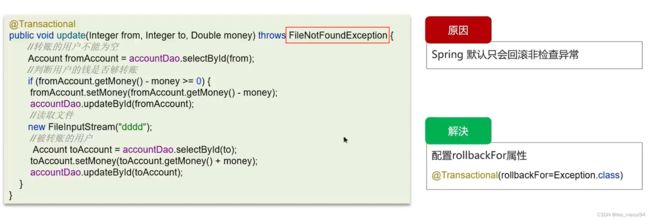
3.2 抛出检查异常
其中非检查异常即RuntimeException
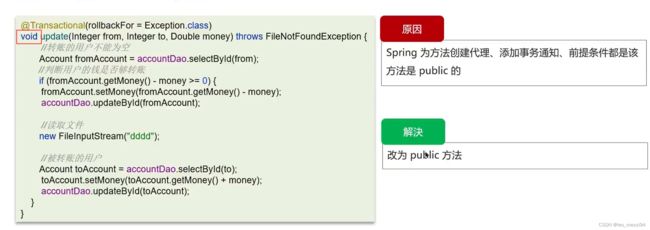
3.3 非public方法:
3.4 问题回答
- 异常捕获处理,自己处理了异常,没有抛出,解决:手动抛出
- 抛出检查异常,配置rollbackFor属性为Exception
- 非public方法导致的事务失效,改为public
4. Spring的bean生命周期?Spring容器是如何管理和创建bean实例的?
4.1 BeanDefinition:创建Bean对象的基础对象
4.2 对象的创建过程:
- 构造函数:调用bean的构造函数实例化bean对象(创建对象,但是并没有初始化)
- 依赖注入:注入@value或者@Autowired的属性
- Aware接口:如果bean实现了此结构,就需要重写这些方法
- Bean后置处理器BeanPostProcessor:初始化方法之前的后置处理器,用于增强bean的功能
- 调用初始化方法:
- 后置处理器BeanPostProcessor:在初始化之后的后置处理器,也是用于增强bean的功能,比如如果这个bean用到了AOP,那就是用后置处理器来实现AOP的

4.3 代码演示:
@Component
public class User implements BeanNameAware, BeanFactoryAware, ApplicationontextAware, InitializingBean {
// 第一步:构造函数
public User(){ System.out.println("User的构造方法执行了.........");}
private String name ;
// 第二步:依赖注入
@Value("张三")
public void setName(String name) {
System.out.println("setName方法执行了.........");
}
// 第三步:aware接口
@Override
public void setBeanName(String name) {
System.out.println("setBeanName方法执行了.........");
}
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
System.out.println("setBeanFactory方法执行了.........");
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
System.out.println("setApplicationContext方法执行了........");
}
// 第五步:初始化方法
@PostConstruct
public void init() {System.out.println("init方法执行了............")}
@Override
public void afterPropertiesSetO throws Exception {
System.out.println("afterPropertiesSet方法执行了........");
}
// 容器销毁,bean被回收
@PreDestroy
public void destory(){ System.out.println("destory方法执行了。。。")}
}
4.3.1 前置后置示例:
(正常的代理就是在后置的后置处理器中完成的)。
bean对象处理配置类实现BeanPostProcessor接口,并重写其中的方法,完成后置处理器处理:

查看对User增强及增强的效果:目的是生成User的代理对象:
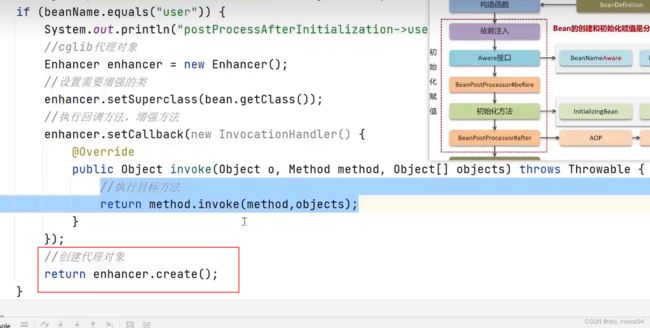
结果可以看到是个代理对象:
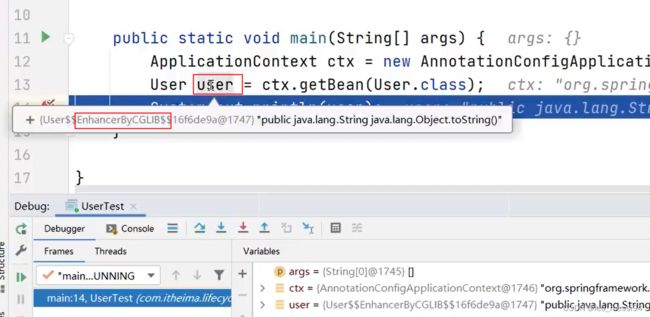
4.4 答案回答:

5. Spring的Bean的循环依赖问题:
5.1 问题示例:

5.2 死循环的产生:
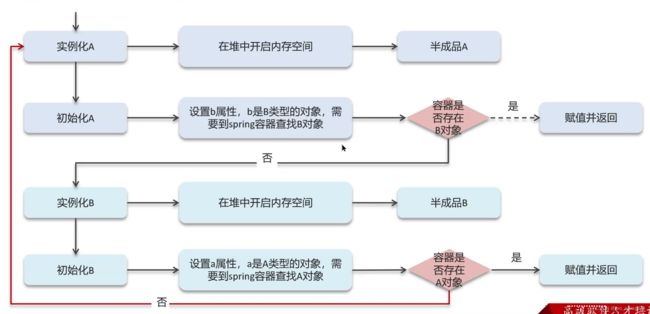
5.3 三级缓存解决循环依赖问题:
其中二级缓存存放的是半成品对象即只是创建了对象并没有初始化的对象。
5.3.1 三级缓存示例:
5.3.2 一级缓存无法解决循环依赖问题:
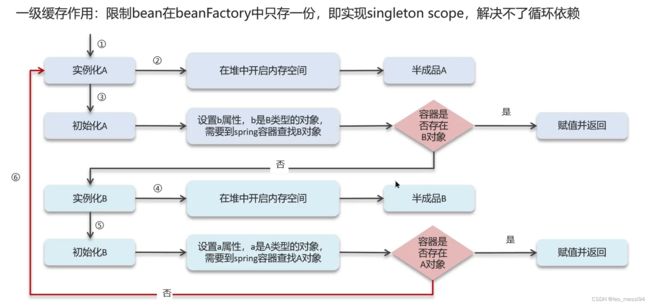
5.3.3 一级和二级缓存解决循环依赖问题:
- 到了创建B需要注入A的步骤,此时二级缓存中有对象A和对象B

- 将二级缓存中的半成品A对象注入到B中就能创建B对象了,有了B对象,A对象也创建成功,此时单例池中就有A对象和B对象了。

- 还存在的问题:
如果A是个代理对象,存入代理池的就会是代理对象,所以一二级缓存只能解决一般的循环依赖:
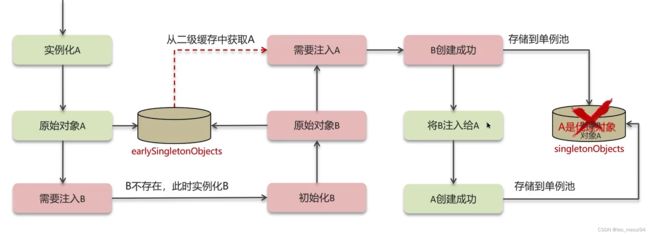
5.3.4 三级缓存解决循环依赖过程演示:
- 到了创建B对象需要A对象,此时通过三级缓存存储了原始对象A和原始对象B生成的工厂对象,对象工厂是专门用来创建对象的:

- 注入A需要从三级缓存中拿到A的工厂对象,生成一个A对象或者A的代理对象放到二级缓存中(还是一个半成品),接着从二级缓存中拿到这个半成品对象就可以把A的半成品注入B,B就可以创建成功
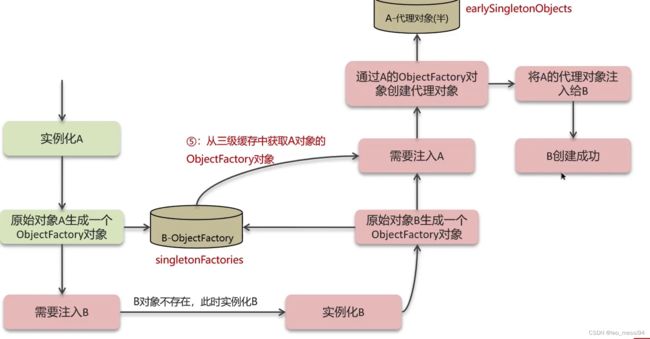
- B创建了放到单例池,A也被创建了:

5.3.5 有了三级缓存为什么还需要二级缓存:
因为我们的对象时单例的,对象工厂创建的对象都是单例的,在B中注入A的时候,我们生成了一个A的半成品对象放到了二级缓存中;创建完B对象,我们在生成A对象的时候,再次从二级缓存中获取到A的半成品对象,基于此半成品对象来生成A。
如果没有二级缓存,在注入B的时候,我们生了一个半成品A对象,到了创建A的时候,我们又会生成一个半成品A对象,出现了多例,此时就会有问题。
5.4 构造方法注入产生了循环依赖如何解决:
因为上面的三级缓存是处理初始化过程中的循环依赖问题,如果是构造函数(构造函数被调用在初始化之前)中的循环依赖如何解决?
5.4.1 问题出现:

5.4.2 解决:@lazy延迟加载
什么时候需要,什么时候再加载

5.5 问题回答:
5.5.1 spring中循环依赖:
- 循环依赖:循环依赖其实就是循环用,也就是两个或两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于A
- 循环依赖在spring中是允许存在,spring框架依据三级缓存已经解决了大部分的循环依赖
- 一级缓存:单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象
- 二级缓存:缓存早期的bean对象(生命周期还没走完)
- 三级缓存:缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的
5.5.2 构造方法中的循环依赖:
A依赖于B,B依赖于A,注入的方式是构造函数
- 原因:由于bean的生命周期中构造函数是第一个执行的,spring框架并不能解决构造函数的的依赖注入
- 解决方案:使用@Lazy进行懒加载,什么时候需要对象再进行bean对象的创建
6. springMVC执行流程:
- 前端控制器:调度中心
- 处理器映射器:找到具体的处理器
- 处理器适配器:调用具体的方法
- 处理器handler:controller中的具体方法
6.1 视图阶段:

6.2 前后端分离:
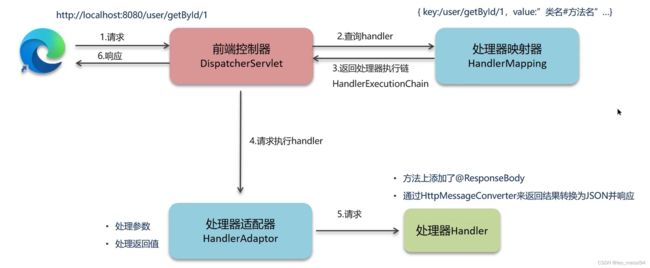
6.3 问题回答:
6.3.1 jsp版本:
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping (处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet
- DispatcherServlet调用HandlerAdapter (处理器适配器)
- HandlerAdapter经过适配调用具体的处理器 (Handler/Controller)
- Controller执行完成返回ModelAndView对象
- HandlerAdapter将Controller执行结果ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView传给ViewReslover (视图解析器)
- ViewReslover解析后返回具体View (视图)
- DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet响应用户
6.3.2 前后端分离版本:
- 用户发送出请求到前端控制器DispatcherServlet
- DispatcherServlet收到请求调用HandlerMapping (处理器映射器)
- HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet
- DispatcherServlet调用HandlerAdapter (处理器适配器)
- HandlerAdapter经过适配调用具体的处理器 (Handler/Controller)
- 方法上添加了@ResponseBody
- 通过HttpMessageConverter来返回结果转换为JSON并响应
7. springboot的自动配置原理:
7.1 springboot启动类注解解释:

7.2 EnableAutoConfiguration注解:
通过此注解,springboot已经为我们引入了100多个配置类:
这里面并不是所有的配置都会加载,只有引入了的才会加载,例如redis的配置类,直接帮我们配置了RedisTemplate:
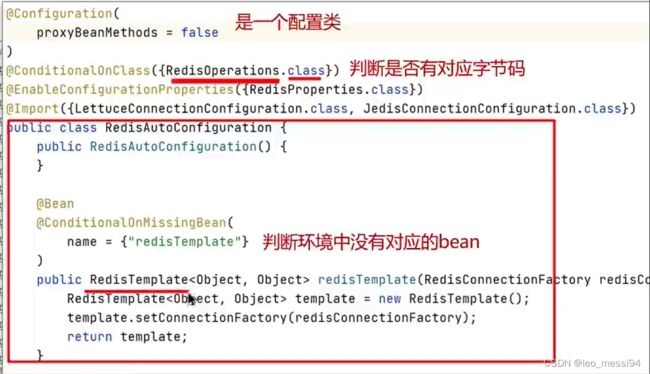
7.3 问题回答:
- 在Spring Boot项目中的引导类上有一个注解@SpringBootApplication,这个注解是对三个注解进行了封装,分别是:
- SpringBootConfiguration
- EnableAutoConfiguration
- ComponentScan
- 其中@EnableAutoConfiguration是实现自动化配置的核心注解。该注解通过@lmport注解导入对应的配置选择器内部就是读取了该项目和该项目引用的Jar包的的casspath路径下
META-INF/spring.factories文件中的所配置的类的全类名。在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中 - 条件判断会有像@Conditional0nClass这样的注解,判断是否有对应的lass文件,如果有则加载该类,把这个配置类的所有的Bean放入spring容器中使用。
8. spring、springmvc和springboot常用注解有哪些?
8.1 spring常用注解:
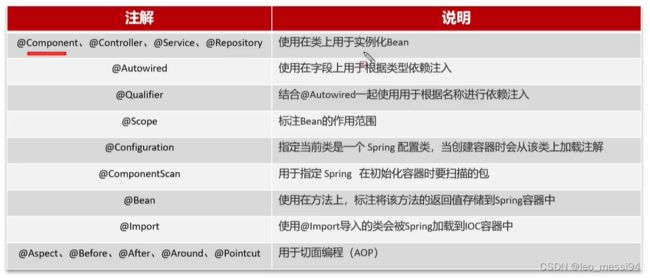
8.2 springmvc相关注解:

8.3 springboot相关注解:

9. Mybatis执行流程
9.1 问题目标:
- 理解各个组建的关系
- Sql的执行过程(参数映射、sql解析、执行和结果处理)
9.2 流程解析:
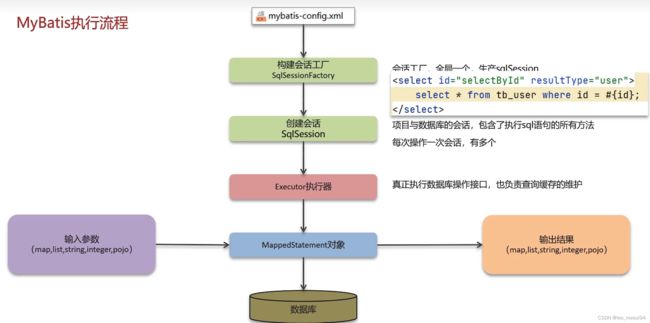
9.2.1 mybatis-config.xml示例

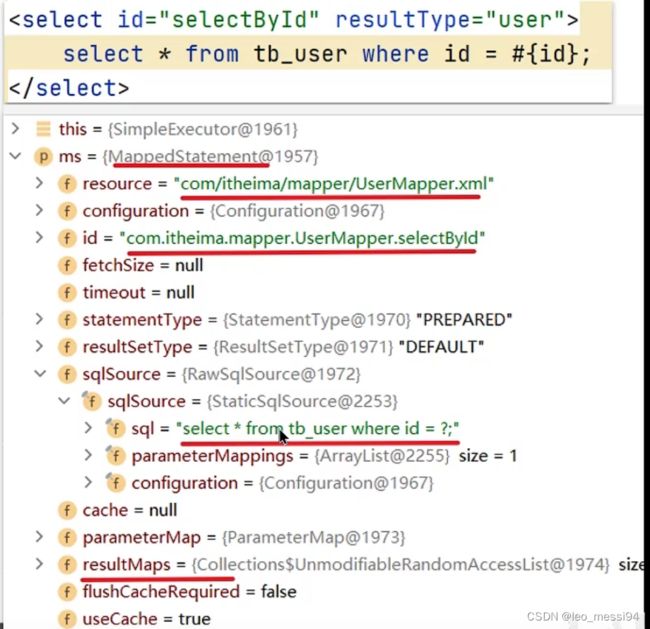
9.2.2 mappedStatement内容 解析
mappedStatement主要是将java入参转换成sql能够识别的类型,同时将sql的结果转成java能够识别的类型
9.3 问题回答:
- 读取MyBatis配置文件:mybatis-config.xml加载运行环境和映射文件
- 构造会话工厂SqlSessionFactory
- 会话工厂创建SqlSession对象 (包含了执行SQL语句的所有方法)
- 操作数据库的接口,Executor执行器,同时负责查询缓存的维护
- Executor接口的执行方法中有一个MappedStatement类型的参数,封装了映射信息
- 输入参数映射(将java类型转为sql类型)
- 输出结果映射(将sql类型转为java类型)
10. mybatis是否支持延迟加载:
10.1 什么是延迟加载:

10.2 测试示例:
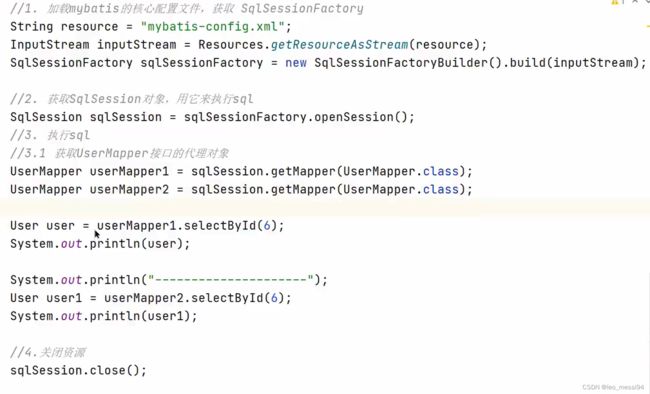
代码:(其中也包括了mybatis执行流程)
public void testSelectById() throws IOException {
//1。加载mybatis的核心配置文件,获取 SqLSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder(),build(inputStream);
//2。获取SqLSession对象,用它来执行sgl
SqlSession sqlSession = sqlSessionFactory.openSession();
//3。执行sgl
//3.1 获取UserMapper接口的代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.selectById(6);
System.out.printin(user.getUsername());
System.out.println("----------------");
List<Order> orderList = user.getOrderListO:System.out.printin(orderList);
//4.关闭资源
sqlSession.close();
}
sql:

结果:可以看到直接查出了order信息

10.2.1 实现懒加载(延迟加载)
修改mapper文件:

结果:可以看到只有当我们需要获取订单信息的时候,才会去执行订单的查询
10.3 开启全局懒加载:
在mybatis-config.xml中配置:

10.4 延迟加载的原理:
通过代理对象实时去查询数据。

10.5 问题回答:

11. mybatis的一级、二级缓存用过吗?
11.1 概念介绍:
其中一二级缓存都是基于本地缓存的。

11.2 一级缓存:
基于PerpetualCache的HashMap本地缓存,其存储作用域为Session,当Session进行flush或close之后,该Session中所有Cache就将清空,默认开启一级缓存。
11.2.1 测试:
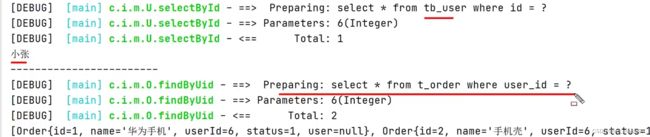
查询两次id=6的数据:
结果:可以看到在一个sqlsession中,查询只执行了一次
11.3 二级缓存:
二级缓存是基于namespace和mapper的作用域起作用的,不是依赖于sqlsession,默认也是采用PerpetualCache,hashmap存储
11.3.1 一级缓存作用域仅一个sqlsession示例:
创建2个sqlsession:

结果:可以看到执行了2次sql:
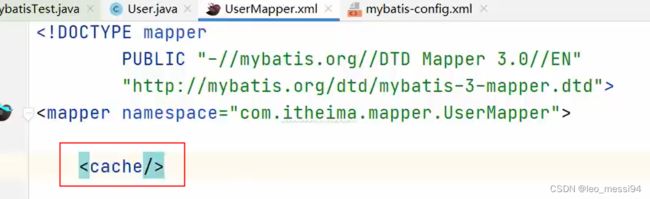
11.3.2 开启二级缓存:
- 第一步:开启

- 第二步:配置标签:
11.3.3 结果测试:
再次执上述代码,可以看到只执行了一次sql

11.3.4 二级缓存注意事项:
- 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namepaces)的进行了新增、修改、删除操作后,默认该作用域下所有select中的缓存将被clear
- 二级缓存需要缓存的数据实现Serializable接口
- 只有会话提交或者关闭以后,一级缓存中的数据才会转移到二级缓存中
11.4 问题回答:

12. 服务注册和发现是什么意思?Spring cloud如何实现服务注册和发现?
服务注册组件有eureka、nacos、zookeeper。
我们想项目中使用的为nacos。
12.1 eureka(nacos)的作用:
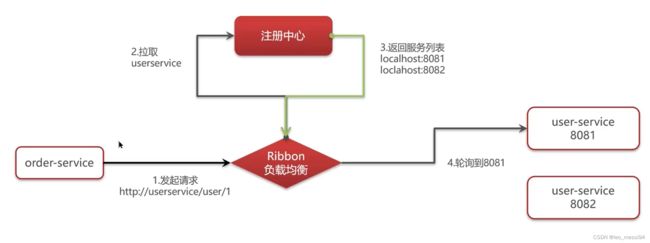
- 两个服务order和user。
- 在启动的时候,order和user都会把自己注册到注册中心中
- order想远程访问user的数据,那就需要拿到user的ip和端口。
- order拉取user的注册信息
- 通过负载均衡后,拿到了8081这个端口的服务,就访问这个服务的数据
- 如果user中的某个服务宕机了,euraka心跳机制30秒没有收到心跳返回,就将其中服务列表中删除

12.2 问题回答:

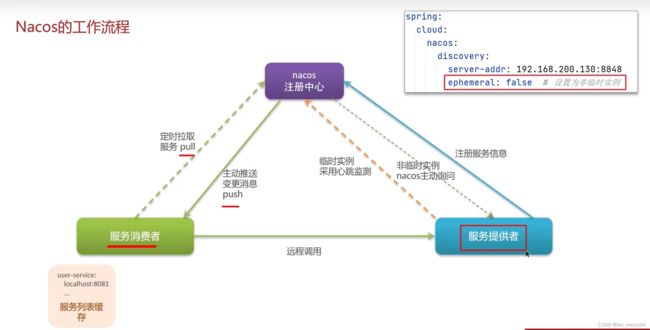
12.3 nacos的工作流程:
主要是临时实例和非临时实例的区别:
- 临时实例(默认都是临时):采用心跳机制,每过多少秒高速注册中心我还活着
- 非临时实例:nacos主动询问是否活着,如果挂了,就给消费者主动推送
12.4 nacos和euraka的区别:

13. 你们项目负载均衡是如何实现的?

13.1 ribbon负载均衡流程:
13.2 ribbon负载均衡策略:
主要有:轮询、权重、随机

13.3 负载均衡策略的实现:

13.4 问题回答:

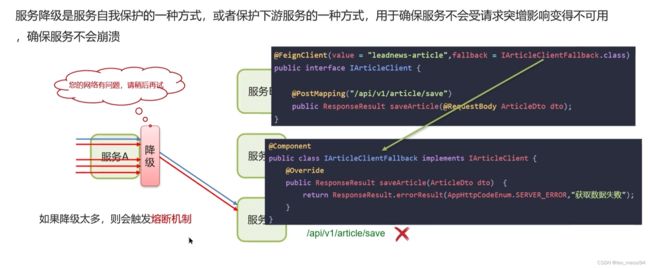
14. 服务雪崩:

14.1 服务降级
即如果一个服务的接口出现问题了,返回一个友好的提示。
通常通过feign进行配置:
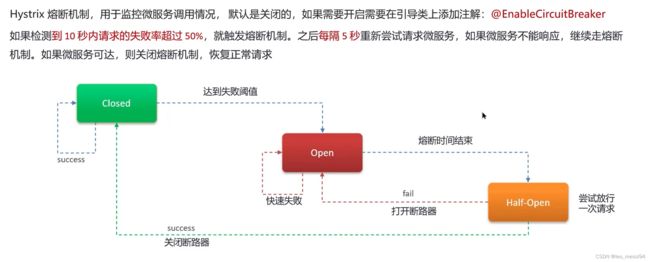
14.2 服务熔断:
14.3 问题回答:

15. 微服务的监控:
我们项目中用的springboot-admin。
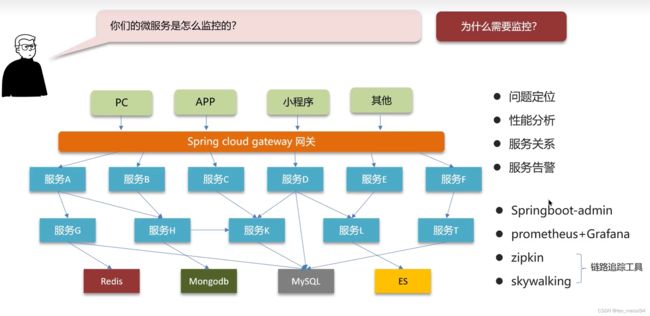
15.1 skywalking:
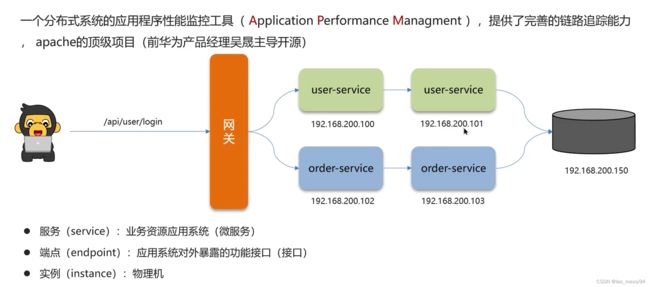

15.1.1 慢接口追踪:
可以看到是哪里(在哪个服务中)很慢
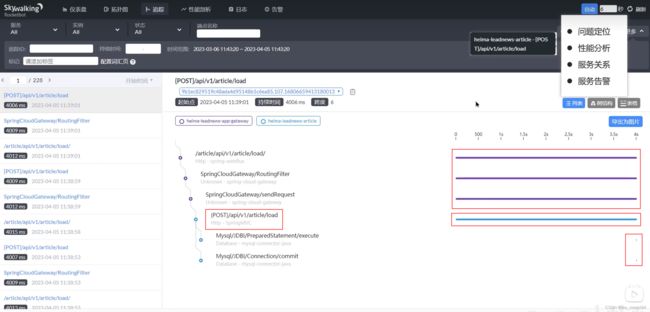
15.1.2 服务关系查看:
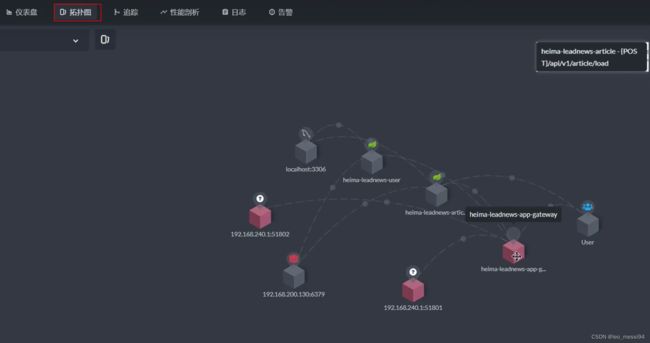
15.1.3 服务告警:
15.2 问题回答:

16. 限流:
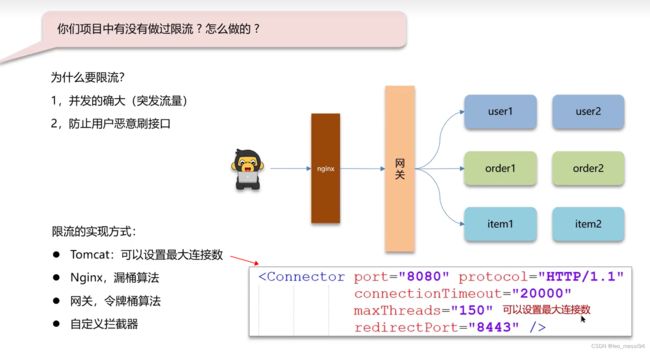
16.1 Nginx限流:
使用的是漏桶算法:
16.1.1 控制速率:

16.1.2 控制并发:

16.2 网关限流:

16.3 问题回答:

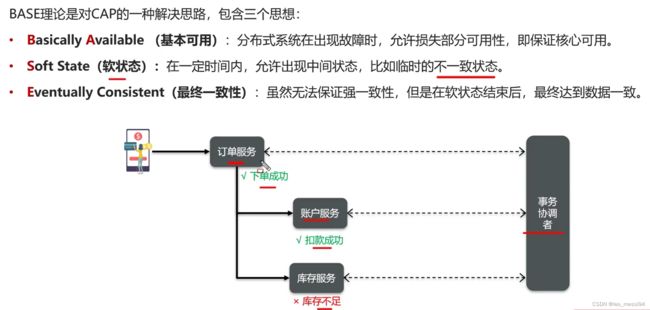
17. CAP和BASE

17.1 CAP:

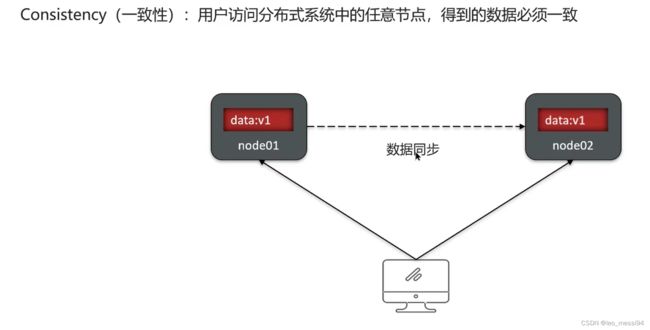
17.1.1 一致性:
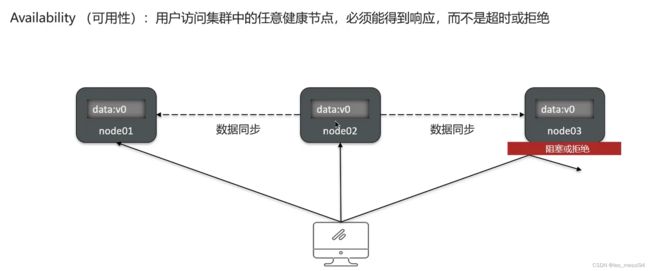
17.1.2 可用性:
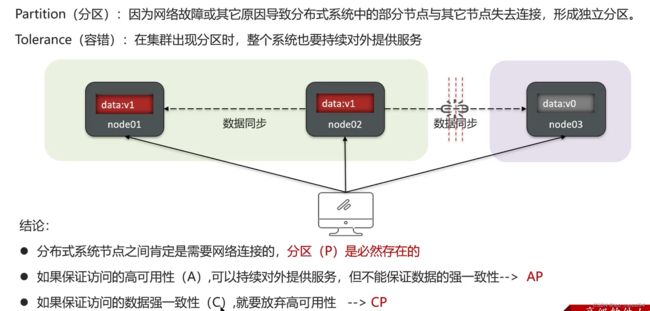
17.1.3 分区容错:
17.2 BASE:
17.3 问题回答:

18. 你们采用的哪种分布式事务框架?
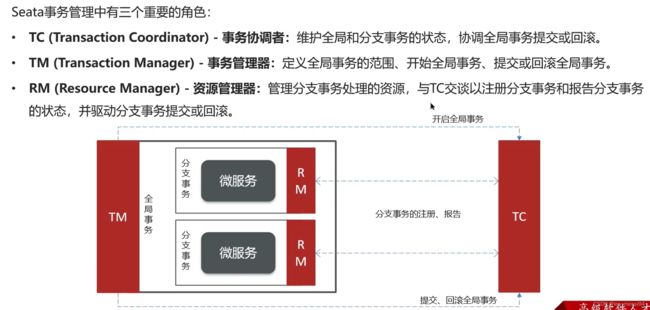
18.1 seata:
18.1.1 seata的三个角色:
seata支持三种工作模式:
18.1.2 seata的XA模式:

18.1.3 AT模式(推荐的):

18.1.4 TCC模式:

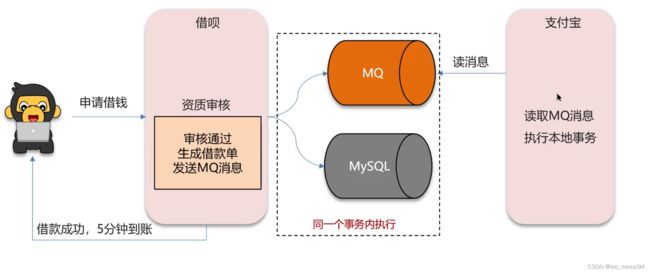
18.2 MQ分布式事务
如果强一致性不高,可以使用这种方式。
18.3 问题回答:

19. 分布式服务的接口欧幂等性如何设计?

19.1 接口幂等
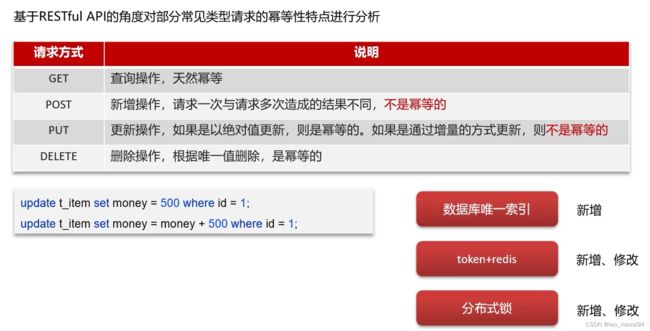
19.1.1 token+redis:
多次点击提交订单,此时因为第一次提交已经删除了token,所以后面的操作就获取不到这个token,就会直接返回。保证了只有一个请求执行:
19.1.2 分布式锁:
如果拿到锁,再执行,拿不到就等待(或者快速失败)。
这里可以控制锁的粒度。
19.2 问题回答:

20. 你们项目使用了什么分布式任务调度?

20.1 xxl-job的路由策略有哪些?
20.2 xxl-job任务失败怎么办?
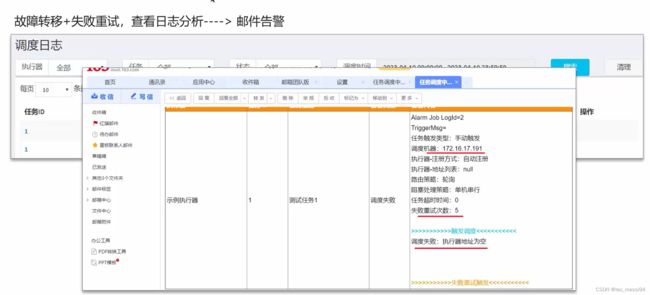
20.3 如果有大数据量的任务需要同时执行,怎么做?

20.4 问题回答:
