【学习笔记】从MySQL快速入门 PostgreSQL
PGSQL
菜鸟教程/在线api文档
- 数据类型
- 语法
- DML
- 条件
- 高级
一、数据类型
数值类型:和mysql类似,叫法不同
- 特殊:serial 自增整数
| 名字 | 存储长度 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2 字节 | 小范围整数 | -32768 到 +32767 |
| integer | 4 字节 | 常用的整数 | -2147483648 到 +2147483647 |
| bigint | 8 字节 | 大范围整数 | -9223372036854775808 到 +9223372036854775807 |
| decimal | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| numeric | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位;小数点后 16383 位 |
| real | 4 字节 | 可变精度,不精确 | 6 位十进制数字精度 |
| double precision | 8 字节 | 可变精度,不精确 | 15 位十进制数字精度 |
| smallserial | 2 字节 | 自增的小范围整数 | 1 到 32767 |
| serial | 4 字节 | 自增整数 | 1 到 2147483647 |
| bigserial | 8 字节 | 自增的大范围整数 | 1 到 9223372036854775807 |
货币类型
money 类型存储带有固定小数精度的货币金额。
-
类似decimal
-
numeric、int 和 bigint 类型的值可以转换为 money
-
不建议使用浮点数来处理处理货币类型
字符类型
类似mysql,有区分定长和变长
| 序号 | 名字 & 描述 |
|---|---|
| 1 | **character varying(n), varchar(n)**变长,有长度限制 |
| 2 | **character(n), char(n)**f定长,不足补空白 |
| 3 | text变长,无长度限制 |
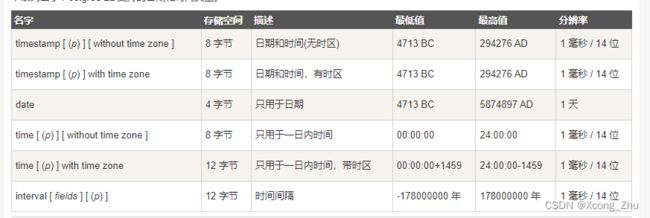
日期类型
布尔 / 枚举
支持
⭐️几何类型
pgsql相比于mysql的强大之处,适用于GIS开发
熟悉一下表现形式,后续可以设置对应的结构来存储地图信息
- 比如绘制图斑就可以用polygon
- 绘制边界则可以用path进行绘制
- 注意path有区分闭合和开放路线
| 名字 | 存储空间 | 说明 | 表现形式 |
|---|---|---|---|
| point | 16 字节 | 平面中的点 | (x,y) |
| line | 32 字节 | (无穷)直线(未完全实现) | ((x1,y1),(x2,y2)) |
| lseg | 32 字节 | (有限)线段 | ((x1,y1),(x2,y2)) |
| box | 32 字节 | 矩形 | ((x1,y1),(x2,y2)) |
| path | 16+16n 字节 | 闭合路径(与多边形类似) | ((x1,y1),…) |
| path | 16+16n 字节 | 开放路径 | [(x1,y1),…] |
| polygon | 40+16n 字节 | 多边形(与闭合路径相似) | ((x1,y1),…) |
| circle | 24 字节 | 圆 | <(x,y),r> (圆心和半径) |
JSON 类型
json 数据类型可以用来存储 JSON(JavaScript Object Notation)数据, 这样的数据也可以存储为 text,但是 json 数据类型更有利于检查每个存储的数值是可用的 JSON 值。
此外还有相关的函数来处理 json 数据:
| 实例 | 实例结果 |
|---|---|
| array_to_json(‘{{1,5},{99,100}}’::int[]) | [[1,5],[99,100]] |
| row_to_json(row(1,‘foo’)) | {“f1”:1,“f2”:“foo”} |
数组类型
PostgreSQL 允许将字段定义成变长的多维数组。
数组类型可以是任何基本类型或用户定义类型,枚举类型或复合类型。
声明语法如下:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
## 也可以用ARRAY关键字 用法如下
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer ARRAY[4],
schedule text[][]
);
插入值
用花括号包裹,再用逗号隔开
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
- 感觉可以理解为存入特殊的文本,pgsql内部将其解析为数组
查询值
-
用中括号加数字就可以访问对应的值
SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2]; ## 这个查询检索在第二季度薪水变化的雇员名 name ------- Carol (1 row) -
同时检索数组中的值,就必须检查每一个值。也可以用函数ALL表示
## 找出数组中所有元素值都等于 10000 的行 SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR pay_by_quarter[2] = 10000 OR pay_by_quarter[3] = 10000 OR pay_by_quarter[4] = 10000; SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
修改数组
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Carol';
## 或者使用 ARRAY 构造器语法:
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
二、基础语法
和mysql类似的SQL语法就不做赘述了,主要找一下特殊一些不同之处
1、数据库操作
-
创建数据库:基本类似,支持命令行创建
-
使用
\l用于查看已经存在的数据库: -
进入数据库,不一样 —— 为
\c + 数据库名

postgres=# \c gis_db
您现在已经连接到数据库 "gis_db",用户 "postgres".
- 删除数据库类似
DROP DATABASE [ IF EXISTS ] name
2、SCHEMA 模式
PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
一个模式可以包含视图、索引、数据类型、函数和操作符等。
相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
使用模式的优势:
- 允许多个用户使用一个数据库并且不会互相干扰。
- 将数据库对象组织成逻辑组以便更容易管理。
- 第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
模式类似于操作系统层的目录,但是模式不能嵌套。

删除模式
删除一个为空的模式(其中的所有对象已经被删除):
DROP SCHEMA myschema;
删除一个模式以及其中包含的所有对象:
DROP SCHEMA myschema CASCADE;
3、DML (增删改)
- 新增语法 INSERT INTO
- 更新语法 UPDATE table SET colum1 = value1 WHERE condition
- 删除 DELETE FROM table_name WHRER condition
4、DQL
-
SELECT
-
支持数学表达式 avg/sum/count
-
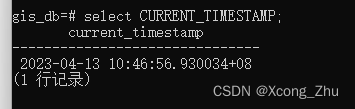
日期表达式 CURRENT_TIMESTAMP
-
查询条件支持
-
AND
-
OR
-
NOT NULL
-
LIKE
-
IN
-
NOT IN
-
BETWEEN
-
子查询

-
WITH
-
GROUB BY + HAVING
-
DISTINCT 获取唯一的数据
-
5、WITH子句
在 PostgreSQL 中,WITH 子句提供了一种编写辅助语句的方法,以便在更大的查询中使用。
-
WITH 子句有助于将复杂的大型查询分解为更简单的表单,便于阅读。这些语句通常称为通用表表达式(Common Table Express, CTE),也可以当做一个为查询而存在的临时表。
-
WITH 子句是在多次执行子查询时特别有用,允许我们在查询中通过它的名称(可能是多次)引用它。
-
WITH 子句在使用前必须先定义。
语法
WITH
表名A AS
(
子查询
)
SELECT *
FROM 表名A
- 当表名A和现有的表名相同时,具有更高的优先级。比如

结合递归RECURSIVE 使用 (没看懂
接下来让我们使用 RECURSIVE 关键字和 WITH 子句编写一个查询,查找 SALARY(工资) 字段小于 20000 的数据并计算它们的和:
WITH RECURSIVE t(n) AS (
VALUES (0)
UNION ALL
SELECT SALARY FROM COMPANY WHERE SALARY < 20000
)
SELECT sum(n) FROM t;
得到结果如下:
sum
-------
25000
(1 row)
6、DDL
创建:CREATE TABLE
在 PostgreSQL 中,ALTER TABLE 命令用于添加,修改,删除一张已经存在表的列。
-
另外你也可以用 ALTER TABLE 命令添加和删除约束。
-
用 ALTER TABLE 在一张已存在的表上添加列的语法如下:
ALTER TABLE + ADD
ALTER TABLE table_name ADD column_name datatype; -
在一张已存在的表上 DROP COLUMN(删除列),语法如下:
ALTER TABLE + DROP
ALTER TABLE table_name DROP COLUMN column_name; -
修改表中某列的 DATA TYPE(数据类型),语法如下:
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype; -
给表中某列添加 NOT NULL 约束,语法如下:
ALTER TABLE table_name ALTER column_name datatype NOT NULL;
清空表:TRUNCATE TABLE
三、运算符
算术运算符
假设变量 a 为 2,变量 b 为 3,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | a + b 结果为 5 |
| - | 减 | a - b 结果为 -1 |
| * | 乘 | a * b 结果为 6 |
| / | 除 | b / a 结果为 1 |
| % | 模(取余) | b % a 结果为 1 |
| ^ | 指数 | a ^ b 结果为 8 |
| |/ | 平方根 | |/ 25.0 结果为 5 |
| ||/ | 立方根 | ||/ 27.0 结果为 3 |
| ! | 阶乘 | 5 ! 结果为 120 |
| !! | 阶乘(前缀操作符) | !! 5 结果为 120 |

比较运算符
sql的基础语法,没有特殊语法,略
逻辑运算符
sql的基础,参考菜鸟的注释,看起来用法和mysql一样
| 序号 | 运算符 & 描述 |
|---|---|
| 1 | AND逻辑与运算符。如果两个操作数都非零,则条件为真。PostgresSQL 中的 WHERE 语句可以用 AND 包含多个过滤条件。 |
| 2 | NOT逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。PostgresSQL 有 NOT EXISTS, NOT BETWEEN, NOT IN 等运算符。 |
| 3 | OR逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。PostgresSQL 中的 WHERE 语句可以用 OR 包含多个过滤条件。 |
位运算符 ,用的比较少 略
三、高级
1、约束:
以下是在 PostgreSQL 中常用的约束。
- NOT NULL:指示某列不能存储 NULL 值。
- UNIQUE:确保某列的值都是唯一的。
- PRIMARY Key:NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。。
- FOREIGN Key: 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK: 保证列中的值符合指定的条件。
- EXCLUSION :排他约束,保证如果将任何两行的指定列或表达式使用指定操作符进行比较,至少其中一个操作符比较将会返回 false 或空值。
2、连接
SQL 标准定义了三种类型的外部连接: LEFT、RIGHT 和 FULL, PostgreSQL 支持所有这些。
在 PostgreSQL 中,JOIN 有五种连接类型:
- CROSS JOIN :交叉连接
- 把第一个表的每一行与第二个表的每一行进行匹配。
- 如果两个输入表分别有 x 和 y 行,则结果表有 x*y 行
- INNER JOIN:内连接 :和mysql一样
- LEFT OUTER JOIN:左外连接:和mysql一样
- RIGHT OUTER JOIN:右外连接:和mysql一样
- FULL OUTER JOIN:全外连接:
3、UNION操作符
PostgreSQL UNION 操作符合并两个或多个 SELECT 语句的结果。
-
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
-
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
语法如下:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL 子句
允许存在重复!
- 默认地,UNION 操作符选取不同的值。
- 如果允许重复的值,请使用 UNION ALL
4、IS NULL 和 IS NOT NULL 操作符。
和mysql一样
- 查询为空或不为空的值时使用
5、别名
as关键字,和mysql一样可以省略
6、索引
和mysql类型, 语法如下:
CREATE INDEX index_name ON table_name;
## 删除
DROP INDEX index_name;
索引类型:
- 普通索引: CREATE INDEX
- 组合索引
- 唯一索引:UNIQUE INDEX
- 局部索引
CREATE INDEX index_name on table_name (conditional_expression); - 隐式索引:是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
查看索引:

7、视图
和mysql一样,语法:
CREATE VIEW 视图名 AS
SELECT 字段1,字段2...
FROM 表名
WHERE 条件;
## 删除
DROP VIEW 视图名;
8、事务
和mysql一样,语法:
BEGIN; ## 开启事务
## 。。。执行语句
COMMIT; ## 提交事务
ROLLBACK; ##回滚
9、自增长
不同于mysql,pgsql提供了对应的数据类型来表示自增id
SMALLSERIAL、SERIAL 和 BIGSERIAL 范围:
| 伪类型 | 存储大小 | 范围 |
|---|---|---|
SMALLSERIAL |
2字节 | 1 到 32,767 |
SERIAL |
4字节 | 1 到 2,147,483,647 |
BIGSERIAL |
8字节 | 1 到 922,337,2036,854,775,807 |
做个简单的总结
- PGSQL的大部分使用和MYSQL无异,以下特意提一下特殊之处
- PGSQL支持存储空间数据,如点、线、面,并提供强大的函数进行运算
- PGSQL支持存储数组和JSON,虽然本质上是TEXT,但是对内部的对象提供了检索的支持
- 数据库的结构也有点不同,PGSQL是 DATABASE > SCHEMA > TABLE的格式。其中SCHEMA是表的集合,而且一个表可以在不同的集合中出现。
- 自增长的数字采用特殊的数据类型 SMALLSERIAL / SERIAL / BIGSERIAL