C语言的数组
目录
一维数组的创建和初始化
- 数组的创建
- 数组的初始化
- 一维数组的输入输出
- 计算数组的元素个数与长度
一维数组在内存中的存储
二维数组的创建和初始化
- 二维数组的创建
- 二维数组的初始化
- 二维数组的输入输出
二维数组在内存中的存储
一个扩展问题:数组越界
数组名是什么
数组是一组相同类型元素的集合
一维数组的创建和初始化
数组的创建
数组的创建方式:
type_t arr_name [const_n];
char arrc [10]//char类型的数组,长度为10
int arri [16]//int类型的数组,长度为16
type_t 是指数组的元素类型
const_n 是一个常量表达式,用来指定数组的大小C99标准前,数组大小必须是常量表达式指定
C99标准中,引入变长数组的概念,变长数组中允许数组的大小由变量来指定
(变长数组不能初始化)( Visual Studio 不支持, gcc 支持)
数组的初始化
数组的初始化是指:在创建数组的同时给数组的内容一些合理初始值(初始化)
代码举例
int arr1[10] = {1,2,3};//完全初始化
int arr2[10] = {1,2,3,4};//不完全初始化,剩下的空位默认初始化为0
char ch1[5] = {'a','b',99};//不完全初始化,剩下的空位默认初始化为0(对于字符类型而言也就是\0)
//此处会将99变为c(99为c的ascll码值)
char ch2[10] = "abcdef";//不完全初始化,f后面的空间初始化为0(也就是\0)
注意:如果数组初始化了,可以不指定数组的大小,数组大小会根据初始化的内容来确定
如下代码
char ch3[] = "abc";//不完全初始化,存放了a,b,c,'\0'四个字符
ch3[4]
char ch4[] = {'a','b','c'};//不完全初始化,只存放了a,b,c三个字符
ch4[3]ps: 字符串末尾隐藏了一个\0,作为字符串的结束标志,如上ch3
但如果通过ch4的方式初始化数组,则末尾不存在\0
所以当我们打印ch4时,会发现c后面出现了随机值(原因是没有\0,没有结束标志)
一维数组的输入输出
由于数组是一种多个同类型元素的集合,所以我们无法通过正常的方式进行输入输出操作
在进行输入输出时,我们需要通过下标索引来访问数组的每一个元素
这时候就会需要遍历数组
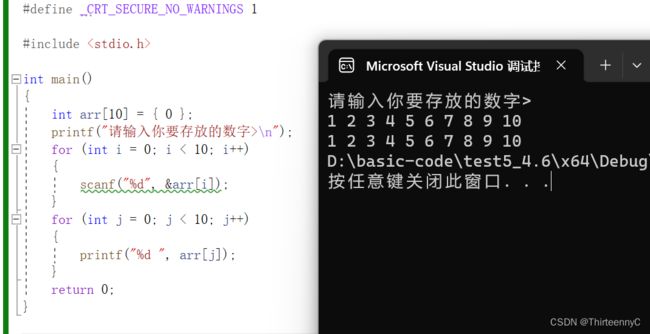
下标索引从0开始,我们可以通过arr[ ]在括号内指定一个值来访问相应下标索引的元素
计算数组的元素个数与长度
我们可以通过sizeof函数来计算数组的元素个数与长度
代码如下
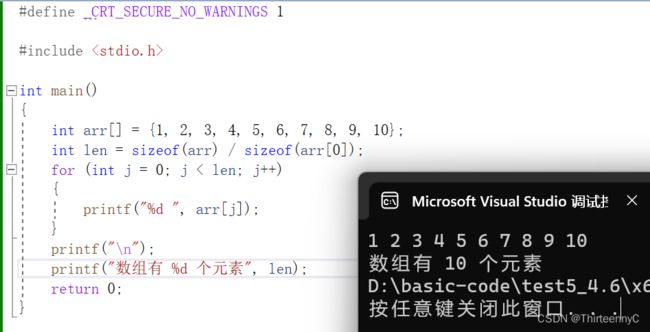
其中 sizeof(arr)计算的是数组的总大小
sizeof(arr[ 0 ])计算的是数组一个元素大小,这个数组存放的是int类型,也就是4个大小
所以,通过 数组总大小 / 数组每个元素的大小 = 数组的元素个数
一维数组在内存中的存储
那么一维数组在内存中是如何存储的呢?
我们通过下面这段代码来研究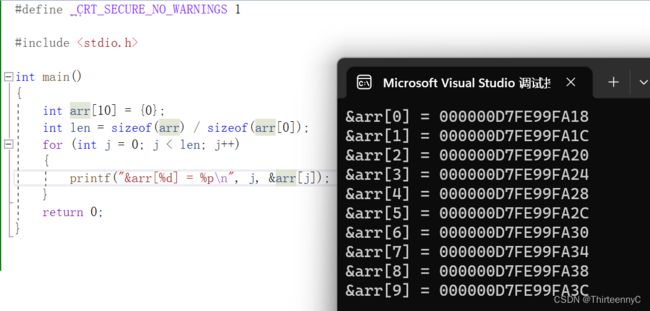
定义一个可以存放10个元素的整型数组arr,全部内容初始化为0
通过遍历将arr每个元素的地址打印出来可以看到
数组里的每个元素是连续存放的
随着下标的增长,地址是由低到高变化的
所以通过这个性质,我们可以通过一个元素的地址访问到其他元素(可以用于传参使用)

每个元素的地址相差4的原因是存放的是整型元素,每个整型需要占据4个字节的空间
二维数组的创建和初始化
相比于一维数组,二位数组不过是以多行多列的方式创建的
可以这样理解,二维数组就是一个矩阵
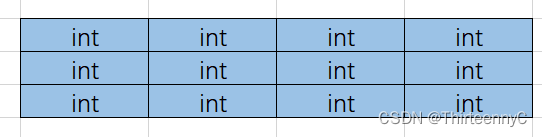
而放入代码来看的话可以这样理解 int arr[ 行 ][ 列 ]
二维数组的创建
int arr[3][4];
char arr[3][5];
double arr[2][4];
二维数组的初始化
int arr[3][4] = {1,2,3,4};//只初始化了一行的4个元素,其他位置为0
int arr[3][4] = {{1,2},{4,5}};//只初始化了1,2行的1,2列元素,其他位置为0
int arr[][4] = {{2,3},{4,5}};//同上只初始化了1,2行的1,2列元素,其他位置为0强调:二维数组的初始化,行可以省略(可以通过初始化的行数来确定),但是列不可以省略
二维数组的输入输出
与一维数组同样,我们无法通过普通的printf和scanf函数来输入输出二维数组
也是需要通过二维数组的下标索引来访问每一个元素
需要用遍历来执行
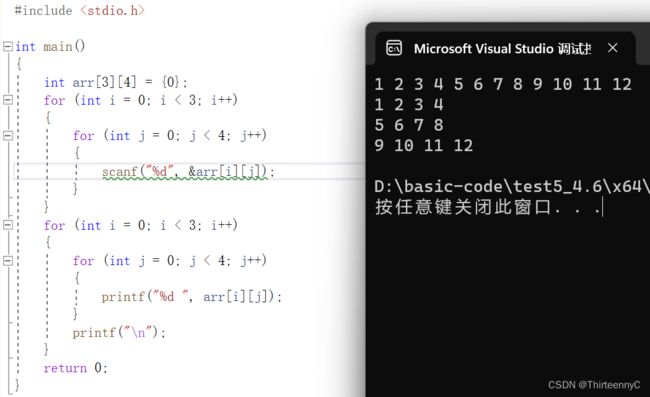
对于二维数组而言,由于存在行与列,我们需要嵌套遍历二维数组,从而来访问二维数组的每一个元素,如上所示:
第一层for循环负责遍历每一行的元素
第二层for循环负责遍历每一列的元素
二维数组在内存中的存储
像一维数组一样,这里我们尝试打印二维数组的每个元素
代码如下
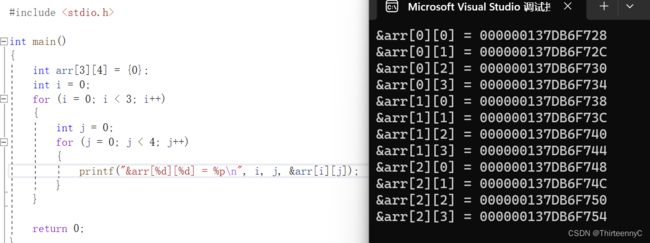
我们可以发现,即使是多行多列的二维数组,他的存储方式居然也是
连续存放

所以对于二维数组来说,我们可以理解为 一个一维数组里,放了若干个一维数组
而对于二维数组来说,他的里面的每个一维数组首元素的地址也就是这个一维数组的地址
一个扩展问题:数组越界
数组的下标是有范围限制的
数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就 是正确的
所以程序员写代码时,最好自己做越界的检查
如下错误代码
#include
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i=0; i<=10; i++)
{
printf("%d\n", arr[i]);//当i等于10的时候,越界访问了
}
return 0;
} 二维数组的行和列也可能存在越界
数组名是什么
这里加一个知识点:冒泡排序法
一串代码来探究一下

可以看到,数组的地址和数组首元素的地址一摸一样,从这里可以得知
数组名就是数组首元素的地址
但是!有两个例外
1.当我们使用sizeof(arr)去求的时候,如果数组首元素的地址,得到的应该是4/8(指针的大小)
实践出真理
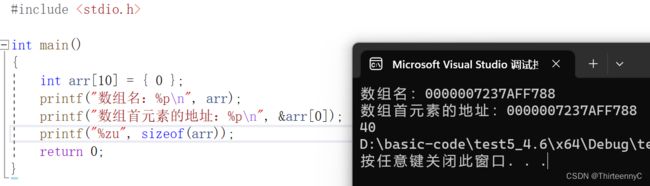
通过这里我们可以发现,打印的40是数组的大小,并非首地址的大小
所以当数组名放在sizeof中时,此时的数组名代表的是整个数组
2.&数组名时,得到的时整个数组的地址
实践出真理
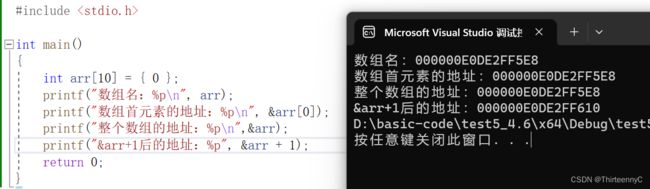
通过这里我们可以看到,虽然&arr找出整个数组的地址与数组首元素地址一致,但是当我们&arr+1之后,得到的是与&arr地址相差40空间的值
由此可以得出
&arr得到的整个数组的地址虽然和数组首元素的地址一致,但当&arr+1时跳过的是整个数组的空间