Java后端面试题 重难点和被问到没答上来的点(包括java基础、关系型数据库、Redis、计算机网络、Spring、Java多线程、vue等)
以下是我记录的一些重点问题和面试中被问到没答上来的问题,包括java基础、关系型数据库、Redis、计算机网络、Spring、Java多线程、vue
问题目录
- 1.fail-safe和fail-fast
- 2.四引用
- 3.explain字段重要内容
- 4.maven三大生命周期
- 5.MYSQL 创建修改表
- 6.数据库三范式
- 7.String、StringBuffer、StringBuilder区别
- 8.常见的异常类
- 9.IO流
- 10.Redis应用场景(高频,问各种数据类型的应用场景)
- 11.查询优化
- 12.类初始化顺序
- 13.HTTPS解决了HTTP什么问题?
- 14.Queue中poll()和remove()区别
- 15.怎么确保一个集合不能被修改?
- 16.final用于函数参数
- 17.SQL执行顺序(高频)
- 18.CAS如何解决ABA问题
- 19.JVM调优(不要觉得JVM调优不会问,真的会问,还不止一次。可以提前准备一个调优的例子,面试时讲)
- 20.JVM有哪些核心指标?合理范围是多少?
- 21.JVM优化步骤?
- 22.HashMap为什么线程不安全?
- 23.AOF和RDB相比优缺点(AOF和RDB是Redis里面试官经常喜欢问的)
- 24.MYSQL的where里的执行顺序
- 25.MyBatis缓存
- 26.Spring拦截器和过滤器区别
- 27.Vue生命周期(见vue官网)
- 28.Controller如何接受数组参数
- 29.Spring常用注解
- 30.为什么要少用局部变量? 局部变量缺点
- 31.String创建对象系列
- 32. socket怎么建立连接的?
- 33. vue2和vue3区别?
1.fail-safe和fail-fast
fail-safe: 安全失败,concurrent包下的容器都是该机制,可以在多线程下并发修改
fail-fast:快速失败,如果Java集合在使用迭代器遍历的过程中进行了增删操作则会抛出异常即使没有并发也会抛出
2.四引用
强引用: A a=new A(); GC永远不会回收这种对象
软引用: 有用但是非必须对象 在发送OOM时会把这些对象进行二次回收
弱引用: 非必须对象 被弱引用关联的对象只能生存到下次GC前
虚引用: 最弱的一种引用关系 存在的目的就是能在这个对象被GC时收到一个系统通知
3.explain字段重要内容
id:标识符
type:表的连接类型
4.maven三大生命周期
1.clean:清理项目
pre-clean(执清理前需要完成的工作)–> clean(清除上次构建过程中生成的文件,比如编译后的class文件)—>post-clean:(执行清理后需要完成的工作)
2.default:构建项目
Default生命周期是Maven生命周期中最重要的一个,绝大部分工作都发生在这个生命周期中。
其中比较重要和常用的阶段:
validate:检测项目结构是否正常,必要的配置文件是否存在
initialize:做构建前的初始化操作,比如初始化参数,创建必要目录
generate-sources:产生在编译过程中需要的源代码
process-sources:处理源代码,比如过滤值
compile:编译项目源代码
process-classes:产生编译过程中生成的文件
generate-test-sources:产生编译过程中测试相关的代码
process-test-sources:处理测试代码
generate-test-resources:产生测试中资源在classpath中的包
process-test-resources:复制并处理资源文件,至目标测试目录
test-compile 编译测试源代码。
process-test-classes 产生编译测试代码过程的文件test 使用合适的单元测试框架运行测试。这些测试代码不会被打包或部署。
prepare-package 处理打包前需要初始化的准备工作
package 接受编译好的代码,打包成可发布的格式,如 JAR 。
pre-integration-test 做好集成测试前的准备工作,比如集成环境的参数设置
integration-test 集成测试
post-integration-test 完成集成测试前的准备工作,比如集成环境的参数设置
verify 检测测试后的包是否完好
install 将包安装至本地仓库,以让其它项目依赖。
deploy 将最终的包复制到远程的仓库,以让其它开发人员与项目共享。
运行任何一个阶段的时候,它前面的所有阶段都会被运行,这也就是为什么我们运行mvn install 的时候,代码会被编译,测试,打包。此外,Maven的插件机制是完全依赖Maven的生命周期的,因此理解生命周期至关重要。
3.site:生项目站点
pre-site:执行一些需要在生成站点文档之前的操作
site:生成项目的站点文档
post-site:执行一些需要在生成站点文档之后完成的工作,并为部署做准备
site-destory:将生成的站点文档部署到特定服务器上
这里经常用到的是site阶段和site-deploy阶段,用以生成和发布Maven站点,这可是Maven相当强大的功能,Manager比较喜欢,文档及统计数据自动生成,很好看。
5.MYSQL 创建修改表
如何创建表在mysql中?
方法:使用关键字create.
例子:create table demo.person {
age int ,
weight int,
hobby varchar
}
如何修改表结构?
场景1.修改字段
方法1:使用关键词alter 、change,可以改变表字段的名称和类型,但是转换的类型有限制,不能从数值类型转换为字符类型.
例子:alter table demo.person change age year int ;
方法2:使用关键词alter 、modify,可以改变类型,但是转换的类型有限制,不能从数值类型转换为字符类型.
例子:alter table demo.person modify age int ;
场景2.新增字段
方法1:使用关键词alter 、add,可以新增表字段;
例子:alter table demo.person add father varchar
6.数据库三范式
1NF:属性不可再分
2NF:满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键;完全依赖是针对于联合主键的情况,非主键列不能只依赖于主键的一部分)
3NF:满足第二范式;且不存在传递依赖,即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。
7.String、StringBuffer、StringBuilder区别
String值创建后不能修改,任何对String的修改都会引发新的String对的生成
StringBuffer:跟String类似,但是值可以修改,使用synchronized来保证线程安全
StringBuilder:StringBuffer的非线程安全版本
8.常见的异常类
NullPointerException:
NumberFormatException:字符转换异常
IOException:IO异常
FileNotFoundException:
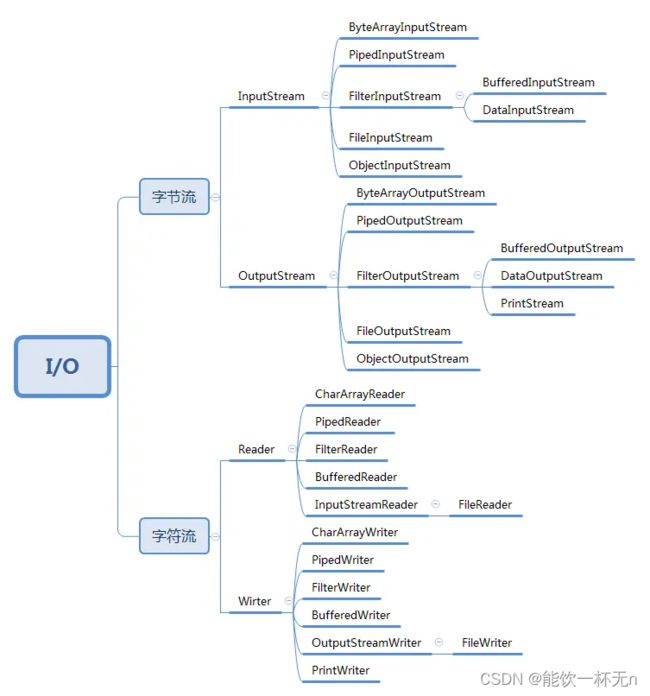
9.IO流
10.Redis应用场景(高频,问各种数据类型的应用场景)
缓存 点赞、排行榜、计数器等功能 共享session 分布式锁 消息中间件
11.查询优化
避免走全表,
1.在where order by的列上建立索引
2.避免null判断
3.少使用计算、函数、类型转换(字符串单引号)
4.少用!= <>
5.少用or
12.类初始化顺序
父类静态变量(静态代码块)-》子类静态变量-》父类非静态变量–》父类构造器–》子类非静态变量–》子类构造器
13.HTTPS解决了HTTP什么问题?
HTTP明文传输,安全上有窃听、篡改、冒充风险
HTTPS通过混合加密来解决窃听 摘要算法来解决篡改 数字证书解决冒充
14.Queue中poll()和remove()区别
(1)offer()和add()区别:
增加新项时,如果队列满了,add会抛出异常,offer返回false。
(2)poll()和remove()区别:
poll()和remove()都是从队列中删除第一个元素,remove抛出异常,poll返回null。
(3)peek()和element()区别:
peek()和element()用于查询队列头部元素,为空时element抛出异常,peek返回null。
15.怎么确保一个集合不能被修改?
采用Collections包下的unmodifiableMap方法,通过这个方法返回的map,是不可以修改的。他会报 java.lang.UnsupportedOperationException错。
同理:Collections包也提供了对list和set集合的方法。
Collections.unmodifiableList(List)
Collections.unmodifiableSet(Set)
16.final用于函数参数
java中方法用final修饰参数的作用
在方法参数前面加final关键字就是为了防止数据在方法体重被修改。
主要分为两种情况:第一,用final修饰基本数据类型;第二,用final修饰引用数据类型。
第一种情况,修饰基本数据类型,这时参数的值在方法体内是不能被修改的,即不能被重新赋值。否则编译就不通过。
第二种情况,修饰引用类型。这时参数变量所引用的对象是不能被改变的。但是对于引用数据类型,如果修改其属性的话是完全可以的。
所以,final这个关键字,想用的话就用基本数据类型,还是很有作用的。
final变量:
对于基本类型使用final:它就是一个常量,数值恒定不变
对于对象引用使用final:使得引用恒定不变,一旦引用被初始化指向一个对象,就无法再把 它改为指向另一个对象。然而,对象自身却是可以被修改的,java并没有提供使任何对象恒定不变的途径。这一限制同样也使用数组,它也是对象。
17.SQL执行顺序(高频)
- from
- on
- join
- where
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum…
- having
- select
- distinct
- order by
- limit
18.CAS如何解决ABA问题
什么是CAS问题?
当执行campare and swap会出现失败的情况。例如,一个线程先读取共享内存数据值A,随后因某种原因,线程暂时挂起,同时另一个线程临时将共享内存数据值先改为B,随后又改回为A。随后挂起线程恢复,并通过CAS比较,最终比较结果将会无变化。这样会通过检查,这就是ABA问题。 在CAS比较前会读取原始数据,随后进行原子CAS操作。这个间隙之间由于并发操作,最终可能会带来问题。
如何解决?
设置版本号
19.JVM调优(不要觉得JVM调优不会问,真的会问,还不止一次。可以提前准备一个调优的例子,面试时讲)
通常来说,我们的 JVM 参数配置大多还是会遵循 JVM 官方的建议,例如:
- -XX:NewRatio=2,年轻代:老年代=1:2
- -XX:SurvivorRatio=8,eden:survivor=8:1
- 堆内存设置为物理内存的3/4左右
- 等等
20.JVM有哪些核心指标?合理范围是多少?
jvm.gc.time:每分钟的GC耗时在1s以内,500ms以内尤佳
jvm.gc.meantime:每次YGC耗时在100ms以内,50ms以内尤佳
jvm.fullgc.count:FGC最多几小时1次,1天不到1次尤佳
jvm.fullgc.time:每次FGC耗时在1s以内,500ms以内尤佳
21.JVM优化步骤?
1.分析和定位当前系统的瓶颈
(1)CPU
1)CPU指标
- 查看占用CPU最多的进程
- 查看占用CPU最多的线程
- 查看线程堆栈快照信息
- 分析代码执行热点
- 查看哪个代码占用CPU执行时间最长
- 查看每个方法占用CPU时间比例
2)JVM 内存指标
- 查看当前 JVM 堆内存参数配置是否合理
- 查看堆中对象的统计信息
- 查看堆存储快照,分析内存的占用情况
- 查看堆各区域的内存增长是否正常
- 查看是哪个区域导致的GC
- 查看GC后能否正常回收到内存
3)JVM GC指标 - 查看每分钟GC时间是否正常
- 查看每分钟YGC次数是否正常
- 查看FGC次数是否正常
- 查看单次FGC时间是否正常
- 查看单次GC各阶段详细耗时,找到耗时严重的阶段
- 查看对象的动态晋升年龄是否正常
2、确定优化目标
定位出系统瓶颈后,在优化前先制定好优化的目标是什么,例如: - 将FGC次数从每小时1次,降低到1天1次
- 将每分钟的GC耗时从3s降低到500ms
- 将每次FGC耗时从5s降低到1s以内
22.HashMap为什么线程不安全?
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
23.AOF和RDB相比优缺点(AOF和RDB是Redis里面试官经常喜欢问的)
AOF:
用 AOF 日志的方式来恢复数据其实是很慢的,因为 Redis 执行命令由单线程负责的,而 AOF 日志恢复数据的方式是顺序执行日志里的每一条命令,如果 AOF 日志很大,这个「重放」的过程就会很慢了。
RDB:
在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
24.MYSQL的where里的执行顺序
从左到右
25.MyBatis缓存
- 一级缓存的作用域是一个sqlsession内; 更新清除一级缓存时也会清除二级缓存 一级缓存默认开启
- 二级缓存作用域是针对mapper进行缓存; 二级缓存需要手动开启
26.Spring拦截器和过滤器区别
过滤器(Filter):用于属性甄别,对象收集(不可改变过滤对象的属性和行为)
拦截器(Interceptor):用于对象拦截,行为干预(可以改变拦截对象的属性和行为)
- 过滤器和拦截器触发时机不一样,过滤器是在请求进入容器后,但请求进入servlet之前进行预处理的。请求结束返回也是,是在servlet处理完后,返回给前端之前。
- 拦截器可以获取IOC容器中的各个bean,而过滤器就不行,因为拦截器是spring提供并管理的,spring的功能可以被拦截器使用,在拦截器里注入一个service,可以调用业务逻辑。而过滤器是JavaEE标准,只需依赖servlet
api ,不需要依赖spring。 - 过滤器的实现基于回调函数。而拦截器(代理模式)的实现基于反射
- Filter是依赖于Servlet容器,属于Servlet规范的一部分,而拦截器则是独立存在的,可以在任何情况下使用。
- Filter的执行由Servlet容器回调完成,而拦截器通常通过动态代理(反射)的方式来执行。
- Filter的生命周期由Servlet容器管理,而拦截器则可以通过IoC容器来管理,因此可以通过注入等方式来获取其他Bean的实例,因此使用会更方便。
拦截器本质上是面向切面编程(AOP),符合横切关注点的功能都可以放在拦截器中来实现,主要的应用场景包括:
- 登录验证,判断用户是否登录。
- 权限验证,判断用户是否有权限访问资源,如校验token
- 日志记录,记录请求操作日志(用户ip,访问时间等),以便统计请求访问量。
- 处理cookie、本地化、国际化、主题等。性能监控,监控请求处理时长等。
- 通用行为:读取cookie得到用户信息并将用户对象放入请求,从而方便后续流程使用,还有如提取
Locale、Theme信息等,只要是多个处理器都需要的即可使用拦截器实现)
过滤器应用场景:
- 过滤敏感词汇(防止sql注入)
- 设置字符编码
- URL级别的权限访问控制
- 压缩响应信息
27.Vue生命周期(见vue官网)
创建前、创建后、载入前、载入后、更新前、更新后、销毁前、销毁后。
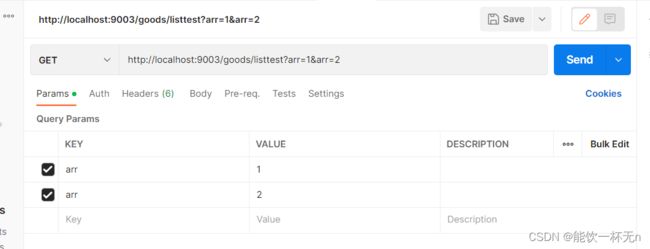
28.Controller如何接受数组参数
对于GET:
后端用@RequestParam
@GetMapping("/listtest")
public Integer test(@RequestParam List<Integer> arr){
for (Integer i : arr) {
System.out.println(i);
}
return 1;
}
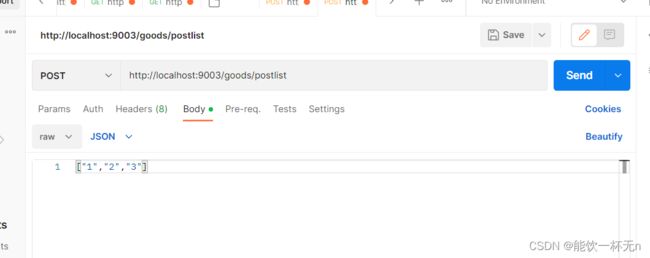
对于POST:
使用@RequestBody
@PostMapping("/postlist")
public String test2(@RequestBody List<Integer> arr){
for (Integer i : arr) {
System.out.println(i);
}
return "hello";
}
29.Spring常用注解
@Value
用于注入application.yml定义的属性
public class A{
@Value("${push.start:0}") 如果缺失,默认值为0
private Long id;
}
@RestController
组合@Controller 和@Response Body
@RequestParam
获取request请求的参数值
public List<CopperVO> getOpList(HttpServletRequest request,
@RequestParam(value = "pageIndex", required = false) Integer pageIndex,
@RequestParam(value = "pageSize", required = false) Integer pageSize) {
}
@ResponseBody
支持将返回值放在response体内,而不是返回一个页面。比如Ajax接口,可以用此注解返回数据而不是页面。此注解可以放置在返回值前或方法前
@PathVariable
用来获得请求url中的动态参数
@Import(Config1.class)
导入Config1配置类里实例化的bean
@Configuration
public class CDConfig {
@Bean // 将SgtPeppers注册为 SpringContext中的bean
public CompactDisc compactDisc() {
return new CompactDisc(); // CompactDisc类型的
}
}
@Configuration
@Import(CDConfig.class) //导入CDConfig的配置
public class CDPlayerConfig {
@Bean(name = "cDPlayer")
public CDPlayer cdPlayer(CompactDisc compactDisc) {
// 这里会注入CompactDisc类型的bean
// 这里注入的这个bean是CDConfig.class中的CompactDisc类型的那个bean
return new CDPlayer(compactDisc);
}
}
30.为什么要少用局部变量? 局部变量缺点
局部变量太多会导致GC多 因为局部变量会被频繁回收
根据迪米特法则,应减少陌生的类作为局部变量,会增加耦合
局部变量位于jvm栈,递归层数多时可能引起栈溢出
局部变量是线程私有(线程封闭的)
31.String创建对象系列
String str=“a”+"b"创建了几个对象?
一个 String常量的累加操作中,编译器会进行优化,如果是 String str = “a” + “b”,那相当于String str = “ab”; ,常量池中会创建一个ab的对象
String str = new String(“a”) + new String(“b”)几个?
在堆中创建了三个字符串对象(a字符串对象,b字符串对象,ab字符串对象),在堆中的常量池中创建了2个字符串对象(a字符串对象,b字符串对象),一共创建了5个字符串对象。
Sting s="a"和String s=new String(“a”)区别?
两个语句都会先去字符串常量池检查是否存在a 如果有则直接使用 如果没有则在常量池中创建 a 对象
另外String s =new String(“a”)还会在堆离创建一个 a 的对象实例
所以前者被后者包含
32. socket怎么建立连接的?
建立TCP连接过程
调用系统函数 socket (),创建并绑定一个 IP 地址和端口。
调用系统函数 listen (),进行地址监听。此时可以通过 netstate 命令查看对应端口是否被监听。
调用系统函数 accept (),从内核获取客户端的连接,如果没有客户端进行连接,则会阻塞等待。
最后调用完成需要close() 连接