Java中的Set
| Set接口中的方法基本上与Collection的API一致 |
|---|
Set系列集合
- 无序:存取顺序不一致
- 不重复:可以去除重复
- 无索引:没有带索引的方法,所以不能使用普通的for循环遍历,也不能通过索引来获取元素
遍历方法:
-------------迭代器
-------------增强for
-------------Lambda表达式
代码实现(同时展现了Set的三个特性):
package com.zzu.mySet;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class A01_SetDemo1 {
public static void main(String[] args) {
/*
利用Set系列的集合 添加字符串 并使用多种方式遍历
迭代器
增强for
Lambda表达式
*/
//1.创建一个Set集合的对象
Set<String> s = new HashSet<>();
//2.添加元素
//Set不重复
//如果元素是第一次添加 添加成功 返回true
//如果元素是第二次添加 添加失败 返回false
boolean r1 = s.add("jh");
boolean r2 = s.add("jh");
s.add("yy");
s.add("jj");
System.out.println(r1);//true
System.out.println(r2);//false
//3.打印集合
//Set无序
System.out.println(s);//[yy, jj, jh]
//Set无索引
//迭代器遍历
Iterator<String> it = s.iterator();
while(it.hasNext()){
String str = it.next();
System.out.print(str+" ");
}//yy jj jh
//增强for
for (String str : s) {
System.out.print(str+" ");
}//yy jj jh
//Lambda表达式
s.forEach(str-> System.out.print(str+" "));//yy jj jh
}
}
Set集合的实现类
HashSet:无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet:可排序、不重复、无索引
1. HashSet
HashSet 底层原理
- HashSet集合底层采取哈希表存储数据
- 哈希表是一种对于增删改查数据性能都较好的结构
哈希表组成
- JDK8之前:数组+链表
- JDK8开始:数组+链表+红黑树
哈希值
- 根据hashCode方法算出来的int类型的整数
- 该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用其内部的属性值计算哈希值
对象的哈希值特点
- 如果没有重写hashCode方法,不同的对象计算出哈希值是不同的
- 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
对于自定义类需要重写hashCode和equlas方法,对于String和Integer,java在底层已经写过了(上面对三种遍历方式讲解的同时已经演示了基本对象String、Integer的添加入Set的不重复性)。
这里代码演示自定义类:
package com.zzu.mySet;
import java.util.Objects;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
package com.zzu.mySet;
public class A02_HashSetDemo1 {
public static void main(String[] args) {
/*
哈希值:
对象的整数表现形式
1.如果没有重写hashCode方法,不同的对象计算出哈希值是不同的
2.如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
3.在小部分情况下,不同属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
*/
//1.创建对象
Student s1 = new Student("jh",19);
Student s2 = new Student("jh",19);
//2.如果没有重写hashCode方法,不同的对象计算出哈希值是不同的
// 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
// 这里已经重写
System.out.println(s1.hashCode());//106070
System.out.println(s2.hashCode());//106070
//在小部分情况下,不同属性值或者不同的地址值计算出来的哈希值也有可能一样
//哈希碰撞 这里碰巧有两个例子
System.out.println("abc".hashCode());//96354
System.out.println("acD".hashCode());//96354
}
}
HashSet底层
(1).原理分析


(2).上述底层原理可引出三个问题答案,这里简单说明,读者通过底层原理理解参悟
1.HashSet为什么存和取的顺序不一样
数据可能以链表方式存储,但是每个链表之间没有联系,并且可能含有红黑树,各个结构之间没有联系,下面LinkedHashSet区别就是数据是否有联系。
2.HashSet为什么没有索引
两种数据结构的存在,索引已经没有太大意义。
3.HashSet是利用什么机制保证数据去重的
重写hashCode和equals方法
(3).小练习
import java.util.Objects;
/*
类Student 重写其equals(),toString()方法 满足:
(1).比学号、姓名、性别
(2).System.out.println(new Student())输出信息:"学号:,姓名:(性别)"
(3).数组存放,实现头插、学号序输出、不重复的输入输出
*/
public class Student {
private String id;
private String name;
private String sex;
public Student() {
}
public Student(String id, String name, String sex) {
this.id = id;
this.name = name;
this.sex = sex;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
//重写之后的equals方法 比较的就是对象内部的属性值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(id, student.id) && Objects.equals(name, student.name) && Objects.equals(sex, student.sex);
}
//重写hashCode方法
@Override
public int hashCode() {
return Objects.hash(id, name, sex);
}
//重写之后的toString方法 打印的是属性值
@Override
public String toString() {
return "学号:" + id + ", 姓名:" + name + "("+sex+")";
}
}
import java.util.*;
public class Test {
public static void main(String[] args) {
//测试toString equals方法
Student s1 = new Student("202107","jh","m");
Student s2 = new Student("202107","yy","f");
//重写之后的toString() 打印的是内容
System.out.println("s1.toString():"+s1.toString());
System.out.println("s1.toString():"+s2.toString());
//重写之后的equals方法 比较的是内容
System.out.println("s1.equals(s2):"+s1.equals(s2));
//1.创建一个链式集合
LinkedList<Student> list = new LinkedList<>();
//2.数组生成7个学生信息
String[][] arrStu = {{"202101","张三","m"},{"202105","李四","m"},{"202101","张三","m"},
{"202101","张三","m"},{"202103","王小","f"},{"202102","王小","f"},{"202105","李四","m"}};
//3.生成学生对象 并且放入集合中
for (int i = 0; i < arrStu.length; i++) {
Student stu = new Student(arrStu[i][0],arrStu[i][1],arrStu[i][2]);
list.add(stu);
}
//4.头部插入对象 并输出list对象信息
Student s = new Student("202104","小七","f");
list.add(0,s);
list.forEach(str-> System.out.println(str));
//5.学号序输出list对象信息
list.sort((a,b)->a.getId().compareTo(b.getId()));
System.out.println("--------idSort--------");
list.forEach(str-> System.out.println(str));
//6.创建一个set集合 接收数据 重写hashCode方法保证键值唯一
Set<Student> set = new HashSet<>(list);
System.out.println("----------Set---------");
set.forEach(str-> System.out.println(str));
//添加数据 返回值看是否添加成功
Student stu = new Student("202101","张三","m");
boolean result = set.add(stu);
System.out.println("添加数据:"+result);
//打印最终结果
System.out.println("--------endSet--------");
set.forEach(str-> System.out.println(str));
}
}
s1.toString():学号:202107, 姓名:jh(m)
s1.toString():学号:202107, 姓名:yy(f)
s1.equals(s2):false
学号:202104, 姓名:小七(f)
学号:202101, 姓名:张三(m)
学号:202105, 姓名:李四(m)
学号:202101, 姓名:张三(m)
学号:202101, 姓名:张三(m)
学号:202103, 姓名:王小(f)
学号:202102, 姓名:王小(f)
学号:202105, 姓名:李四(m)
--------idSort--------
学号:202101, 姓名:张三(m)
学号:202101, 姓名:张三(m)
学号:202101, 姓名:张三(m)
学号:202102, 姓名:王小(f)
学号:202103, 姓名:王小(f)
学号:202104, 姓名:小七(f)
学号:202105, 姓名:李四(m)
学号:202105, 姓名:李四(m)
----------Set---------
学号:202101, 姓名:张三(m)
学号:202105, 姓名:李四(m)
学号:202104, 姓名:小七(f)
学号:202102, 姓名:王小(f)
学号:202103, 姓名:王小(f)
添加数据:false
--------endSet--------
学号:202101, 姓名:张三(m)
学号:202105, 姓名:李四(m)
学号:202104, 姓名:小七(f)
学号:202102, 姓名:王小(f)
学号:202103, 姓名:王小(f)
2.LinkedHashSet(直接继承HashSet)
(1).LinkedHashSet集合的特点和原理
- 有序、不重复、无索引
- 底层基于哈希表,使用双链表记录添加顺序
在以后使用中,默认使用HashSet(效率高),如果要求去重且存取有序,才使用LinkedHashSet。
(2).LinkedHashSet底层原理
阿玮百万PPT:
这里双链表是上一次加入的元素与这一次加入的元素进行的链接,互相存储内存值。也正是这种链接使得LinkedHashSet有序。
package com.zzu.mySet;
import java.util.Objects;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
package com.zzu.mySet;
import java.util.LinkedHashSet;
public class A03_LinkedHashSetDemo {
public static void main(String[] args) {
//1.创建几个学生对象
Student s1 = new Student("jh",19);
Student s2 = new Student("yy",20);
Student s3 = new Student("jj",20);
Student s4 = new Student("jh",19);
//2.创建集合的对象
LinkedHashSet<Student> lhs = new LinkedHashSet<>();
//3.添加元素
System.out.println(lhs.add(s2));//true
System.out.println(lhs.add(s1));//true
System.out.println(lhs.add(s3));//true
System.out.println(lhs.add(s4));//false 已经重写hashCode equals 不重复
//4.打印集合(有序)
System.out.println(lhs);//[Student{name = yy, age = 20}, Student{name = jh, age = 19}, Student{name = jj, age = 20}]
}
}
3.TreeSet
(1).TreeSet的特点
- 不重复、无索引、可排序
- 可排序:按照元素的默认规则(从小到大)排序
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删查改性能都较好
(2).TreeSet集合默认的规则
- 对于数值类型:Integer,Double,默认按从小到大的顺序进行排序
- 对于字符、字符串类型:按照字符在ASCLL码表中的数字升序进行排序
(3).排序
<1>.默认规则排序
package com.zzu.mySet;
import java.util.Iterator;
import java.util.TreeSet;
import java.util.function.Consumer;
public class A04_TreeSetDemo1 {
public static void main(String[] args) {
/*
需求:利用TreeSet存储整数并排序(小数、字符、字符串道理一样)
*/
//1.创建对象
TreeSet<Integer> ts = new TreeSet<>();
//2.添加元素
ts.add(3);
ts.add(2);
ts.add(4);
ts.add(1);
ts.add(5);
//3.打印集合(有序)
System.out.println(ts);//[1, 2, 3, 4, 5]
//4.遍历集合(三种遍历)
//迭代器
Iterator<Integer> it = ts.iterator();
while(it.hasNext()){
int i = it.next();
System.out.print(i+" ");
}
System.out.println("\n-------------------");
//增强for
for(int i:ts){
System.out.print(i+" ");
}
System.out.println("\n-------------------");
//Lambda
ts.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer i) {
System.out.print(i+" ");
}
});
System.out.println();
//即
ts.forEach(i-> System.out.print(i+" "));
}
}
[1, 2, 3, 4, 5]
1 2 3 4 5
-------------------
1 2 3 4 5
-------------------
1 2 3 4 5
1 2 3 4 5
<2>.自定义对象排序
先了解一下红黑树的添加节点的基本规则,这里大家没基础应该先了解一下红黑树。

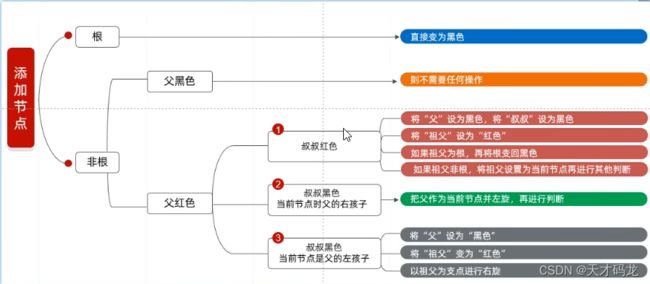
两种排序使用规则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种。
1.TreeSet的第一种排序
排序规则/自然排序:javabean类实现Comparable接口制定比较规则,这里通过自定义类中compareTo方法的重写,运用比较对红黑树存储数据进行更新。
public int compareTo(E e)
返回值:
- 负数:认为要添加的元素是小的,存左边
- 正数:认为要添加的元素是大的,存右边
- 0:认为要添加的元素已经存在,舍弃
package com.zzu.mySet;
import java.util.TreeSet;
public class A05_TreeSetDemo2 {
public static void main(String[] args) {
/*
需求:创建TreeSet集合,并添加3个学生对象
学生对象属性:
姓名、年龄
要求按照学生年龄排序
同年龄按照姓名字母排列(暂不考虑中文)
同姓名,同年龄认为是一个人
方式一:
默认的排序规则/自然排序
Student实现Comparable接口,重写里面的抽象方法,制定比较规则
*/
//1.创建三个学生对象
Student s1 = new Student("jh",19);
Student s2 = new Student("yy",20);
Student s3 = new Student("jj",19);
//2.创建集合对象
TreeSet<Student> ts = new TreeSet<>();
//3.添加元素
ts.add(s1);
ts.add(s2);
ts.add(s3);
//4.打印集合
System.out.println(ts);
}
}
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
@Override
//this:表示当前要添加的元素
//o:表示已经在红黑树存在的元素
//返回值:
//1. 负数:认为要添加的元素是小的,存左边
//2. 正数:认为要添加的元素是大的,存右边
//3. 0:认为要添加的元素已经存在,舍弃
public int compareTo(Student o) {
//这里打印this和o直观地看到排序的过程
System.out.println("-------------");
System.out.println("this:" + this);
System.out.println("o:" + o);
//指定排序的规则
//这里先看年龄再看姓名
//年龄相同则比较姓名
//都相同则舍弃
int age = this.age-o.age;
if(age!=0) return age;
else return this.name.compareTo(o.name);
}
}
-------------
this:Student{name = jh, age = 19}
o:Student{name = jh, age = 19}
-------------
this:Student{name = yy, age = 20}
o:Student{name = jh, age = 19}
-------------
this:Student{name = jj, age = 19}
o:Student{name = jh, age = 19}
-------------
this:Student{name = jj, age = 19}
o:Student{name = yy, age = 20}
[Student{name = jh, age = 19}, Student{name = jj, age = 19}, Student{name = yy, age = 20}]
2.TreeSet的第二种排序
比较器排序:创建TreeSet对象的时候,传递比较器Comparator制定规则
package com.zzu.mySet;
import java.util.Comparator;
import java.util.TreeSet;
public class A06_TreeSetDemo3 {
public static void main(String[] args) {
/*
需求:请自行选择比较器排序和自然排序两种方式
要求:存入无个字符串,"a","jh","yy","yjj","jzqh"
按照长度排序:如果一样长则按照首字母排序
这里String类中底层有写好的函数进行ASCLL码比较,很显然第一种方式无法实现要求
采取第二种排序方式:比较器排序
*/
//1.创建集合
//o1:表示当前要添加的元素
//o2:表示已经在红黑树存在的元素
//返回值规则跟第一种方式是一样的
/* TreeSet ts = new TreeSet<>(new Comparator() {
@Override
public int compare(String o1, String o2) {
//按照长度排序
int i = o1.length()-o2.length();
//如果一样长度则按照首字母排序
return i==0?o1.compareTo(o2):i;
}
});*/
TreeSet<String> ts = new TreeSet<>((o1, o2)-> {
//按照长度排序
int i = o1.length()-o2.length();
//如果一样长度则按照首字母排序
return i==0?o1.compareTo(o2):i;
});
//2.添加元素
ts.add("a");
ts.add("yy");
ts.add("jh");
ts.add("jzqh");
ts.add("yjj");
//3.打印集合
System.out.println(ts);//[a, jh, yy, yjj, jzqh]
}
}
<3>.小练习
package com.zzu.mySet;
import java.util.TreeSet;
public class A07_TreeSetDemo4 {
public static void main(String[] args) {
/*
需求:创建五个学生对象
属性:(姓名、年龄、语文成绩、数学成绩、英语成绩)
按照总分从高到低输出到控制台
如果总分一样 按照语文成绩排
如果语文成绩一样 按照数学成绩排
如果数学成绩一样 按照英语成绩排
如果英文成绩一样 按照年龄大小排
如果年龄一样 按照姓名的字母顺序排
如果都一样 认为是同一个学生 不存
第一种:默认排序/自然排序
第二种:比较器排序
默认情况下,用第一种排序方式,如果第一种不能满足当前的需求,采取第二种方式
*/
//1.创建学生对象
Student2 s1 = new Student2("zhangsan",23,90,99,50);
Student2 s2 = new Student2("lisi",24,90,90,50);
Student2 s3 = new Student2("wangwu",25,80,99,50);
Student2 s4 = new Student2("zhaoliu",26,66,76,86);
Student2 s5 = new Student2("qianqi",27,77,78,87);
//2.创建集合
TreeSet<Student2> ts = new TreeSet<>();
//3.添加元素
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
//4.遍历集合
for (Student2 stu : ts) {
System.out.println(stu);
}
}
}
package com.zzu.mySet;
public class Student2 implements Comparable<Student2>{
//姓名
private String name;
//年龄
private int age;
//语文成绩
private int chinese;
//数学成绩
private int math;
//英语成绩
private int english;
public Student2() {
}
public Student2(String name, int age, int chinese, int math, int english) {
this.name = name;
this.age = age;
this.chinese = chinese;
this.math = math;
this.english = english;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
/**
* 获取
* @return chinese
*/
public int getChinese() {
return chinese;
}
/**
* 设置
* @param chinese
*/
public void setChinese(int chinese) {
this.chinese = chinese;
}
/**
* 获取
* @return math
*/
public int getMath() {
return math;
}
/**
* 设置
* @param math
*/
public void setMath(int math) {
this.math = math;
}
/**
* 获取
* @return english
*/
public int getEnglish() {
return english;
}
/**
* 设置
* @param english
*/
public void setEnglish(int english) {
this.english = english;
}
public String toString() {
return "Student2{name = " + name + ", age = " + age + ", chinese = " + chinese + ", math = " + math + ", english = " + english + "}";
}
/*
按照总分从高到低输出到控制台
如果总分一样 按照语文成绩排
如果语文成绩一样 按照数学成绩排
如果数学成绩一样 按照英语成绩排
如果英文成绩一样 按照年龄大小排
如果年龄一样 按照姓名的字母顺序排
如果都一样 认为是同一个学生 不存
*/
@Override
public int compareTo(Student2 o) {
int sum1 = this.getChinese()+this.getMath()+this.getEnglish();
int sum2 = o.getChinese()+o.getMath()+o.getEnglish();
//比较两者总分
int i = sum2 - sum1;
//如果总分一样 按照语文成绩排
i = i==0?o.getChinese()-this.getChinese():i;
//如果语文成绩一样 按照数学成绩排
i = i==0?o.getMath()-this.getMath():i;
//如果数学成绩一样 按照英语成绩排(不需要比较了)
//i = i==0?o.getEnglish()-this.getEnglish():i;
//如果英文成绩一样 按照年龄大小排
i = i==0?o.getAge()-this.getAge():i;
//如果年龄一样 按照姓名的字母顺序排
i = i==0?o.getName().compareTo(this.getName()):i;
return i;
}
}
Student2{name = qianqi, age = 27, chinese = 77, math = 78, english = 87}
Student2{name = zhangsan, age = 23, chinese = 90, math = 99, english = 50}
Student2{name = lisi, age = 24, chinese = 90, math = 90, english = 50}
Student2{name = wangwu, age = 25, chinese = 80, math = 99, english = 50}
Student2{name = zhaoliu, age = 26, chinese = 66, math = 76, english = 86}
4.使用场景
- 如果想对集合中的元素去重:用HashSet集合,基于哈希表的。(用的最多)
- 如果相应对集合中的元素去重,而且保证存取顺序:用LinkedHashSet集合,基于哈希表和双链表,效率低于HahSet。
- 如果想对集合中的元素进行排序:用TreeSet集合,基于红黑树。