Android面试指南—Kotlin Flow篇
什么是 Kotlin Flow流?
在Kotlin官网中定义中是这么说的:
在协程中,与仅返回单个值的挂起函数相反,Flow可按顺序发出多个值, 它以协程为基础构建,可提供多个值,从概念上来讲,Flow是可通过异步方式进行计算处理的一组数据序列,所发出值的类型必须相同。
总结一下,我们可以将Flow定义为具有多个异步计算值的协程。它是可以异步计算的数据流,用于按顺序发送多个值。 发出的数据必须是同一类型,并且也是按顺序发出的,Flow使用挂起的函数以异步方式消费和生产。
为什么需要Kotlin Flow?
为了使应用程序响应并提高其性能,异步编程起着非常重要的作用,日常开发中,在协程没有出现的岁月里,可以使用RxJava响应式编程框架,它是ReactiveX基于Java的扩展,直到Kotlin的出现和发展。
在Kotlin中,相同的功能以Kotlin Flow API的形式提供。它不仅具备所需的所有运算符和功能,而且还支持挂起函数,这有助于以顺序方式执行异步任务,也让代码变得更加简洁和高效。
如果我们有 RxJava/其他响应式实现,为什么要创建 Flow?
在Flow中,如果我们想转换数据,用一个map操作符即可,这与RxJava有些不同,RxJava具有同步的map和异步的latMapSingle。流程图运算符有一个lambda,它是一个暂停,因此它适用于同步和异步。过滤数据也是如此,Flow只有一个Filter运算符适用于两者。
所以Flow能有效减少了在其它响应式实现中引入的操作符,更加方便简洁,这也是为什么要使用Flow的重要原因。
Kotlin Flow 是如何工作的?
平常我们开发都会使用到网络请求吧,当从服务器请求数据并使用异步编程来处理该数据时,Flow会在后台线程中异步管理该数据,因为某些进程可能会运行更长时间来获取数据。一旦收集器接收并收集了数据,就会使用回收器视图显示数据。
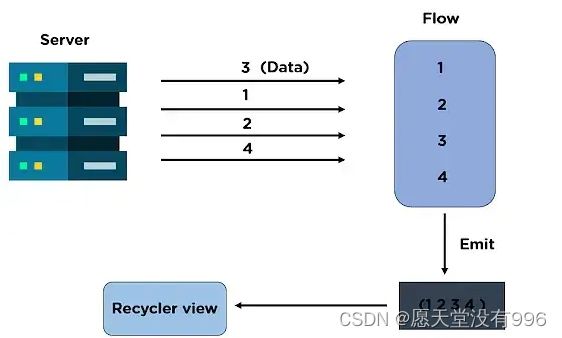
我们已经知道,Flow是一系列值,它使用挂起函数异步生成和使用值。
Flow流由三个实体组成:
- 生产者: 用于发出添加到流中的数据。
- 中介:它可以修改发送到流中的值
- 消费者 : 从流中接收值
Flow builders 的几种类型?
我们平时创建一个Flow流一般提供了4种方式
-
flowOf:它用于一组数据的创建Flow流
flowOf(4, 2, 3, 45, 5) .collect { print(it) } -
asFlow:这是一个扩展函数,有助于将当前类型转换为Flow流
(1..5).asFlow() .collect { print(it) } -
flow:这就是官方示例程序标准的创建Flow流的方式
flow { (0..10).forEach { emit(it) } }.collect { print(it) } -
channelFlow:此构建器使用构建器本身提供的发送元素来创建Flow流。
@OptIn(ExperimentalCoroutinesApi::class) channelFlow { (0..10).forEach { send(it) } }.collect { print(it) }需要注意的是channelFlow这个Api还是实验性的,所以正式项目环境中很少用到
Kotlin Flow如何实现并发?
我们都知道,Flow是异步的,但是收集器collect和发射器emit是按顺序的方式来工作,怎么说呢?就是当收集器开始收集数据,然后发射器发射出数据,直到没有发射器为止。经常有人说,它就是用同步的代码做异步的事情,这个总结挺到位的。当然,为了实现Flow并发,我们必须从使用单个协程转变为使用多个协程。
Flow对此提供了一些特殊的并发运算符,比如说buffer(),简单使用一个例子
fun main() = runBlocking {
val time = measureTimeMillis {
flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}
.buffer()
.collect { value ->
delay(300)
println(value)
}
}
println("Collected in $time ms")
}
在上述例子中,所有的 delay 所花费的时间是2000ms,当然这是在没有并发操作的情况下,然而通过buffer操作符并发地执行emit,再顺序地执行collect函数后,所花费的时间在1700ms左右,比预期的花费时间更高效。
那我们使用缓存区buffer的时候会发生什么呢?如下图所示
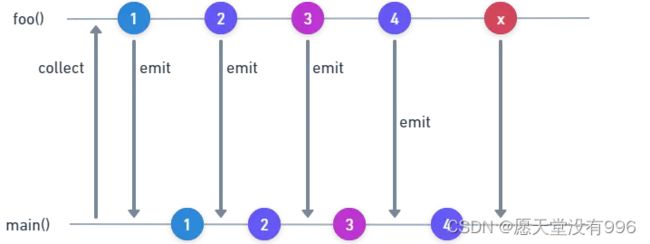
当收集器处理发出的数据时,下一个发射器开始其过程。它不会等待收集器完成它对先前发出的数据的处理并返回控制权。这是通过在单独的协程中运行收集器和发射器来实现的,这与在单个协程中运行的异步顺序方法不同。在内部它使用通道Channel将数据发送给接收者。
Kotlin Flow 如何进行并行调用?
那有小伙伴说了,如果我有很多个长任务想要同时执行呢,也就是并行,Flow能不能做到呢?答案肯定是YES的,为了并行运行长任务,我们需要使用Flow提供的组合操作符zip,它通过指定的函数将两个流集合的排放组合在一起,并根据此函数的结果为每个组合排放单个项目。
让我们通过示例代码来理解弹珠图:
val flowOne = flowOf(1, 2, 3)
val flowTwo = flowOf("A", "B", "C")
flowOne.zip(flowTwo) { intValue, stringValue ->
"$intValue$stringValue"
}.collect {
println(it)
}
输出结果如下:
1A
2B
3C
可以看到通过zip压缩将两个流执行完之后再一起输出结果,不够清晰?那我们再举一个Android中的真实用例:当我们想要并行运行两个网络请求任务并希望在两个任务完成时将两个任务的结果放在一个回调中。
假设我们有两个长时间允许的网络请求任务
-
长时间运行的任务请求一:
private fun doLongRunningTaskOne(): Flow<String> { return flow { //开始请求接口。。。。 delay(5000) emit("One") } } -
长时间运行的任务请求二:
private fun doLongRunningTaskTwo(): Flow<String> { return flow { //请求另一个接口。。。 delay(5000) emit("Two") } } -
现在,使用zip操作符处理
fun startLongRunningTask() { viewModelScope.launch { doLongRunningTaskOne() .zip(doLongRunningTaskTwo()) { resultOne, resultTwo -> return@zip resultOne + resultTwo } .flowOn(Dispatchers.Default) .catch { e -> //异常处理 } .collect { //获取结果 println(it) } } } -
结果输出如下:
OneTwo在这里,由于我们使用了zip运算符,它并行运行两个任务,并在两个任务完成时在一个回调中给出两个任务的结果。
通过使用zip运算符压缩两个流集合,两个任务并行运行。当两者都完成时,我们就会得到结果。这样我们就一次得到了两个流集合的结果。
Kotlin Flow的zip运算符的优点:
-
并行运行任务。
-
当所有任务完成时,在单个回调中返回任务结果。
这样我们就可以在 Kotlin 中使用Flow 的Zip操作符来并行运行任务。
Kotlin Flow中的异常处理?
我们都知道了Flow是在协程的基础进行构建的,它可以在有或没有异常的情况下完成,如果有异常的话它会直接完成Complete;在Flow中,我们一般都使用其提供的catch操作符来进行异常的处理。
还是以往的套路,先来举个例子,看下面的代码,告诉我,它会发生异常导致崩溃么? 答案是肯定的
(1..5).asFlow().map {
//当值为3得时候抛出异常
check(it != 3) {
"Value $it"
}
it * it
}.onCompletion {
Log.d(TAG, "onCompletion")
}.collect {
Log.d(TAG, "$it")
}
输出结果如下:
1
4
onCompletion
Exception in thread "main" java.lang.IllegalStateException: Value 3
是的,它崩溃了,中止了发射数据,Flow进入了onCompletion状态
此时我们再加上catch操作符,它将把异常的句柄信息交给我们,并不会发生崩溃
(1..5).asFlow().map {
check(it != 3) {
"Value $it"
}
it * it
}.onCompletion {
Log.d(TAG, "onCompletion")
}.catch { e ->
Log.e(TAG, "Caught is $e")
}.collect {
Log.d(TAG, "$it")
}
结果将是:
1
4
onCompletion
Caught java.lang.IllegalStateException: Value 3
它记录了异常信息,可以看到,无论加不加catch操作符,Flow发射数据都会中止,并且直接进入OnComplete状态,这和协程的异常处理基本是一致的,原来如此,差点忘了,Flow是以协程的基础构建,属于包含关系。
如此,我们知道了Flow是如何处理异常的,我们可以将catch应用于单个流并在出现任何错误时发出数据
如果我有一个长时间任务有异常的任务,Flow怎么进行重试?
和Rxjava一样,在进行任务重试的时候,Kotlin Flow提供了相应的操作符,它们分别是
- etrywhen
- retry
在大多数情况下,这两个操作符可以互换使用,它们本身并没有什么太大的区别,下面我们分别来看看吧
retrywhen
先用力的撇一眼Kotlin Flow源码中retryWhen的定义
fun <T> Flow<T>.retryWhen(predicate: suspend FlowCollector<T>.(cause: Throwable, attempt: Long) -> Boolean): Flow<T>
我们先开始使用这个操作符
.retryWhen { cause, attempt ->
}
可以看到它返回了两个参数,它们分别是
- cause:Throwable所有错误和异常的基类。
- attempt:attempt是代表当前尝试的次数,它从零开始。
这样以来,当我们在任务中出现了异常,我们将收到当前异常和尝试次数,这个时候就需要我们根据需求条件进行判断是否进行重试了,只有满足了一定的条件才可以重试,如此我们可以这么做
.retryWhen { cause, attempt ->
if (cause is IOException && attempt < 3) {
delay(2000)
return@retryWhen true
} else {
return@retryWhen false
}
}
retry
还是老规矩,我们再用力瞥一眼retry的源码定义
fun <T> Flow<T>.retry(
retries: Long = Long.MAX_VALUE,
predicate: suspend (cause: Throwable) -> Boolean = { true }
): Flow<T> {
require(retries > 0) { "Expected positive amount of retries, but had $retries" }
return retryWhen { cause, attempt -> attempt < retries && predicate(cause) }
}
只用关心一点,它实际上是在retryWhen的基础上调用,这也是为什么这两个操作符可以互相替换
retry函数是默认参数的,如果不设置次数,它将使用Long.MAX\VALUE,这样以来它将会不断重试,直到任务完成为止。所以我们可以这么写:
.retry(retries = 3) { cause ->
if (cause is IOException) {
delay(2000)
return@retry true
} else {
return@retry false
}
}
说说Cold Flow冷流 和Hot Flow热流?
说起Flow可以分为冷流和热流,结合官网和网络上的一些解释,其实分别可以概括成一句话
-
冷流就是不消费,不生产,多次消费,多次生产,一对一关系
-
热流就是只要创建,有无消费,都生产,一对多关系
你说什么,不是特别清晰,那笔者用一个表来展示冷流和热流的区别吧
| 冷流 | 热流 |
|---|---|
| 它仅在有收集器的时候才有数据 | 即使没有收集器,它也会发出数据 |
| 它不存储数据 | 它可以存储数据 |
| 它不能有多个收集器 | 它允许有多个收集器 |
在Cold Flow中,在多个收集器的情况下,完整的流程将从每个收集器的开始而开始,执行任务并将值发送到它们相应的收集器。这就像一对一的映射。1个收集器的1个生产流量。这意味着冷流不能有多个收集器,因为它将为每个收集器创建一个新流。
在Hot Flow中,在多个收集器的情况下,流将继续发出值,收集器从它们开始收集的地方获取值。这就像 1 对 N 映射,N 个收集器对应1个生产流量,这意味着一个热流可以有多个收集器。
如此我们写些伪代码来辅助说明下吧:
- 冷流示例
假设我们有一个Cold Flow,它以 1 秒的间隔发出 1 到 5
fun getNumbersColdFlow():ColdFlow<Int> {
return someColdFlow {
(1..5).forEach {
delay(1000)
emit(it)
}
}
}
我们创建两个收集器进行收集:
val numbersColdFlow = getNumbersColdFlow()
numbersColdFlow
.collect {
println("1st Collector: $it")
}
delay(2500)
numbersColdFlow
.collect {
println("2nd Collector: $it")
}
那么输出将是:
1st Collector: 1
1st Collector: 2
1st Collector: 3
1st Collector: 4
1st Collector: 5
2nd Collector: 1
2nd Collector: 2
2nd Collector: 3
2nd Collector: 4
2nd Collector: 5
我们这两个收集器从一开始就会得到所有的值,会从头到尾全部一点不落的拿到
- 热流示例
假设我们有一个Hot Flow,它同样以1秒的间隔发出1到5
fun getNumbersHotFlow(): HotFlow<Int> {
return someHotflow {
(1..5).forEach {
delay(1000)
emit(it)
}
}
}
现在我们继续创建两个收集器进行收集:
val numbersHotFlow = getNumbersHotFlow()
numbersHotFlow
.collect {
println("1st Collector: $it")
}
delay(2500)
numbersHotFlow
.collect {
println("2nd Collector: $it")
}
输出将是
1st Collector: 1
1st Collector: 2
1st Collector: 3
1st Collector: 4
1st Collector: 5
2nd Collector: 3
2nd Collector: 4
2nd Collector: 5
可以看到,第一个收集器将会接收到所有的值,由于第二个收集器将会2500毫秒之后开始收集,所以它只会收集那些2500毫秒之后的值。
StateFlow 和 SharedFlow 之间的区别?
我们已经知道什么是冷流和热流了,而StateFlow和SharedFlow都属于热流,下面笔者列出一张表来说明StateFlow 和SharedFlow之间的区别
| StateFlow | SharedFlow |
|---|---|
| 热流 | 热流 |
| 需要一个初始值并在收集器开始收集时立即发出它 | 不需要初始值,因此默认情况下不发出任何值 |
| 写法:val stateFlow = MutableStateFlow(0) | 写法:val sharedFlow = MutableSharedFlow() |
| 仅发出最后一个已知值 | 可以配置为使用重播运算符发出许多以前的值 |
| 它有value属性,可以查看当前值,保留了一个值的历史记录,我们可以直接获取而无需收集 | 它没有 value 属性 |
| 它不会发出连续的重复值。只有当它与前一项不同时,它才会发出值 | 它发出所有值并且不关心与前一项的区别,它还发出连续的重复值 |
| 类似于 LiveData,除了 Android 组件的生命周期感知。我们应该使用带有 StateFlow 的 repeatOnLifecycle 范围来为其添加生命周期感知,然后它就会变得与 LiveData 完全一样 | 和LiveData不同 |
我们分别举个相应的例子看看:
-
StateFlow示例
假设我们去记录小明的一次数学考试成绩, 一开始的成绩是个鸭蛋,代码如下:
val gradeStateFlow = MutableStateFlow(0)这个时候老师再去收集这个成绩
gradeStateFlow.collect { println(it) }一旦开始收集了,那么我们就会得到,原来小明考了个鸭蛋,回去应该得挨骂了
0这是因为小明的初始分数就是0,它会立即发出
后来老师发现原来自己算错分了,小明的分数原来是10分,所以就继续设置这个值,但又不小心输了两遍进去
gradeStateFlow.value = 10 gradeStateFlow.value = 10此时最后只会得到一个值,那就是10分,因为它不会发出连续的重复值
10小明回到家了,妈妈问他成绩怎么样,小明怕被打没有告诉她,所以妈妈就亲自打电话问了老师,这个时候,我们就创建了一个新的收集器,用来发送小明的最终成绩
gradeStateFlow.collect { println(it) }这个时候妈妈已经知道了小明最终只考了10分,免不了一顿责骂
10因为StateFlow存储最后一个值并在新的收集器中开始收集时会立即发出它
-
SharedFlow示例
第二天,小明的妈妈让小明去买些水果回来,于是乎,小明来到了楼下的水果店,开始选些水果并放入自己的购物篮中
val fruitSharedFlow = MutableSharedFlow<String>()
fruitSharedFlow.collect {
println(it)
}
这个时候是不会得到任何东西的,小明还没开始购买水果呢,这个时候他拿了1斤苹果,1斤香蕉和1斤葡萄,后面发现葡萄不够又拿了1斤
fruitSharedFlow.emit("1斤苹果")
fruitSharedFlow.emit("1斤香蕉")
fruitSharedFlow.emit("1斤葡萄")
fruitSharedFlow.emit("1斤葡萄")
最终得到的结果就是
1斤苹果
1斤香蕉
1斤葡萄
1斤葡萄
复制代码
可以看到我们可以得到连续的重复值,现在小明买完回到家,将购物篮的水果都交给了妈妈,这时候小明再看购物篮的时候,里面已经空空如也了,他不会得到任何结果,因为SharedFlow不存储最后一个值
fruitSharedFlow.collect {
println(it)
}
现在通过两个现实中的例子我们就可以理解下面几点
-
StateFlow是SharedFlow的一种,StateFlow是_SharedFlow_的特化
-
StateFlow 本质是一个具有固定 replay = 1 的SharedFlow,并增加了一些内容。这意味着新收集器在开始收集后将立即获得当前状态初始值。怎么说呢,我们还是用一段伪代码看看吧
StateFlow = SharedFlow .withInitialValue(initialValue) .replay(count=1) .distinctUntilChanged()实际开发中,我们是可以使用SharedFlow获取StateFlow行为
val sharedFlow = MutableSharedFlow( replay = 1, onBufferOverflow = BufferOverflow.DROP_OLDEST ) sharedFlow.emit(0) // initial value val stateFlow = sharedFlow.distinctUntilChanged() 事实上,这是让我们可以自定义属于我们的StateFlow,比如说需要存储最后的两个值,我们就可以根据我们的用例执行replay = 2
什么时候需要用StateFlow/SharedFlow?
使用StateFlow的情况
还是使用实际的例子来说明,我们有一个用例,就是通过网络从后台用户信息接口获取用户列表并将其显示再UI中
现在我们的ViewModel中有一个StateFlow
val usersStateFlow = MutableStateFlow<UiState<List<User>>>(UiState.Loading)
在Activity中创建收集器
usersStateFlow.collect {
}
现在,只要我们进入到Activity中,就会开始订阅收集,将收集以下内容:
usersStateFlow:作为StateFlow加载状态采用初始值并立即发出
当我们的viewModel从网络中获取数据时,它将数据设置到 usersStateFlow。
usersStateFlow.value = UiState.Success(usersFromNetwork)
我们的Activity中的收集器将获取用户的数据并将其显示在 UI 中
试想一下,如果方向改变了呢,ViewModel将被保留,但我们在 Activity 中的收集器将重新订阅收集,由于StateFlow保留最后一个值,我们可以直接获取之前从网络设置的用户列表,这个时候优势在于我不需要在重新请求网络接口了
这个时候,我们尝试使用SharedFlow代替StateFlow看看
val usersSharedFlow = MutableSharedFlow<UiState<List<User>>>()
usersSharedFlow.collect {
}
现在,只要我们打开Activity,Activity就会订阅收集。由于使用了SharedFlow,因此不会在此处收集任何内容。
当我们的ViewModel从网络中获取数据时。它将数据设置为usersSharedFlow。
usersSharedFlow.emit(UiState.Success(usersFromNetwork))
此时由于方向改变,ViewModel将被保留,我们在Activity中的收集器将重新订阅收集。由于使用不存储任何数据的SharedFlow,因此不会在此处收集任何内容。我们将不得不进行新的网络请求。
所以在这种情况下我们应该使用StateFlow而不是SharedFlow,为了避免不必要的频繁网络请求调用
使用SharedFlow的情况
假设我们现在执行一项任务,如果该任务失败就必须显示SnackBar提示
在我们的ViewModel中创建一个SharedFlow
val showSnackbarSharedFlow = MutableSharedFlow()
同样的,我们的Activity中有一个收集器
showSnackbarSharedFlow.collect {
}
现在,只要我们打开Activity,Activity就会订阅收集。由于使用了 SharedFlow,因此不会在此处收集任何内容
然后,当我们的viewModel启动任务并失败的时候,它会将showSnackbarSharedFlow设置为true,表示我们需要显示Snackbar
showSnackbarSharedFlow.emit(true)
如果方向改变,ViewModel将被保留,我们在 Activity 中的收集器将重新订阅收集。此处不会收集任何内容,因为SharedFlow不保留最后一个值。那很好。我们不应该在方向改变时再次显示Snackbar。
此时我们尝试使用StateFlow代替SharedFlow,但是如果方向改变了,ViewModel将被保留,我们在 Activity 中的收集器将重新订阅收集,因为StateFlow保留最后一个值。它将再次显示 Snackbar,那这样就不好,我们不应该在方向改变时再次显示Snackbar
所以,在这种情况下,我们应该使用SharedFlow而不是StateFlow。
具体什么时候使用StateFlow,什么时候ShardFlow,还请大家结合自身项目和需求的特点,选择合适的即可
更多Android面试题 请点击免费领取