哈夫曼编码/译码器
哈夫曼编码/译码器
题目
哈夫曼编码/译码器。利用哈夫曼编码进行信息通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。试为这样的信息收发站写一个哈夫曼编/译码系统。
需求
(1)初始化(Initialization)。从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件hfmTree中。
(2)编码(Encoding)。利用已建好的哈夫曼树,对文件ToBeTran中的正文进行编码,然后将结果存入文件CodeFile中。
(3)译码(Decoding)。利用已建好的哈夫曼树将文件CodeFile中的代码进行译码,结果存入文件TextFile中。
(4)打印代码文件(Print)。将文件CodeFile以紧凑格式显示在终端上,每行50个代码。同时将此字符形式的编码写入文件CodePrint中。
(5)打印哈夫曼树(Tree Printing)。将已在内存中的哈夫曼树以直观的方式(树或凹入表形式)显示在终端上,同时将此字符形式的哈夫曼树写入文件TreePrint中。
测试数据
(1)已知某系统在通信联络中只可能出现8种字符,其概率分别为0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,以此设计哈夫曼编码。利用此数据对程序进行调试。
(2)用下表给出的字符集和频度的实际统计数据建立哈夫曼树,并实现以下报文的编码和译码:“THIS PROGRAM IS MY FAVORITE”。

程序设计流程图
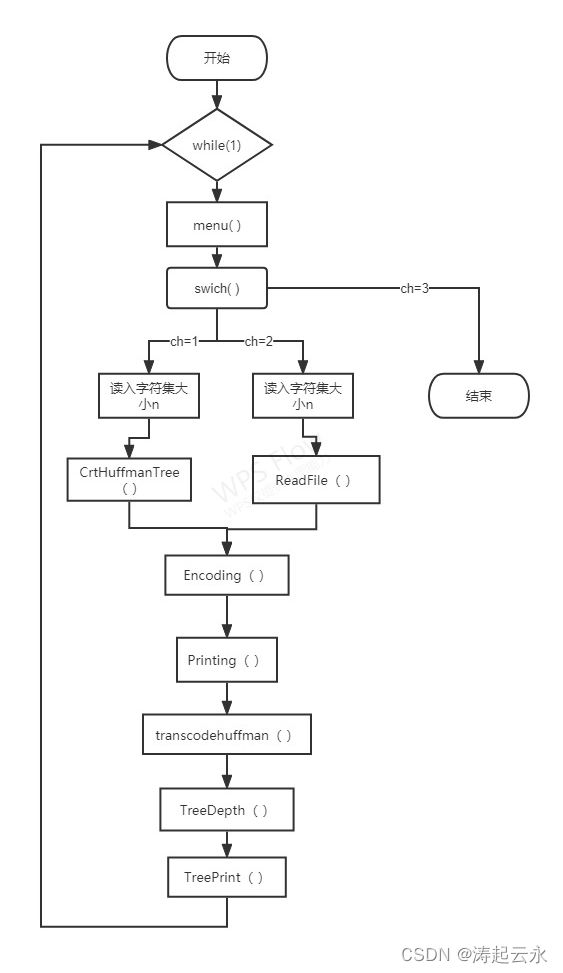
程序源代码
#pragma warning(disable:4996)
#include调试分析
a.问题分析与解决
(1)在调试时由于多次调用同一个文件并没有将指针复位,导致出现乱码。利用rewind( )函数可以将文件指针复位到文件开头,可以解决这个问题。
(2)当遇到需要读入字符且换行多次读取字符时,scanf( )函数会将换行符也读入,导致出现乱码。调用 库中的cin函数不仅可以自动吞掉换行符,而且可以不限输入格式。也可以在scanf( )函数后调用getchar( )函数来消除回车换行符。
(3)在使用fopen()函数时,一定要在写清文件的后缀,否则可能无法找到文件。
(4)在读取文件时,不可轻易使用rewind( )函数,否则读取文件数据时会把换行符也读入,导致读入错误而产生乱码。
b.算法的时空分析与改进设想
(1)在求解二叉树的深度时,我采用了后序遍历递归算法,在树的深度很大时其时空性能不高。可以通过建立一个显式栈来提高性能。
(2)本次采用的是静态链表构造的哈夫曼树,开辟的空间较大。个人认为利用动态链表构造哈夫曼树更能节省空间。