如何合理选择ClickHouse表主键
ClickHouse提供索引和数据存储的复杂机制,能够实现在高负载下仍有优异的读写性能。当创建MergeTree表时需要选择主键,主键影响大多数查询性能。本文介绍主键的工作原理,让我们知道如何选择合适的主键。
设置主键
MergeTree表可以设置主键,必须在创建表时指定,示例如下:
CREATE TABLE test
(
`dt` DateTime,
`event` String,
`user_id` UInt64,
`context` String
)
ENGINE = MergeTree
PRIMARY KEY (event, user_id, dt)
ORDER BY (event, user_id, dt)
上面在三个列上按一定顺序创建了主键:event, user_id, dt。注意,主键应该与排序键相同,或作为排序键的前缀。
排序键定义在磁盘上的排列顺序,主键定义查询使用的数据结构。通常主键与顺序键相同,如何相同可以忽略主键的定义,ClickHouse会自动采用排序键的字段。
数据存储粒度
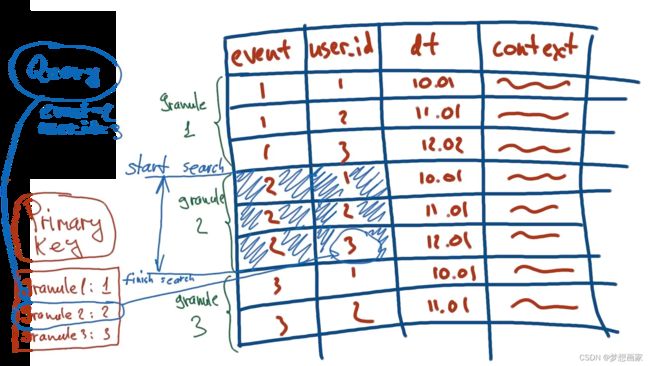
ClickHouse把表记录划分为多个组,组称为粒度:
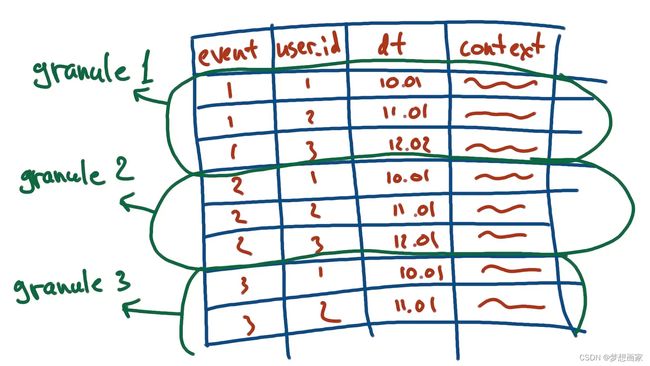
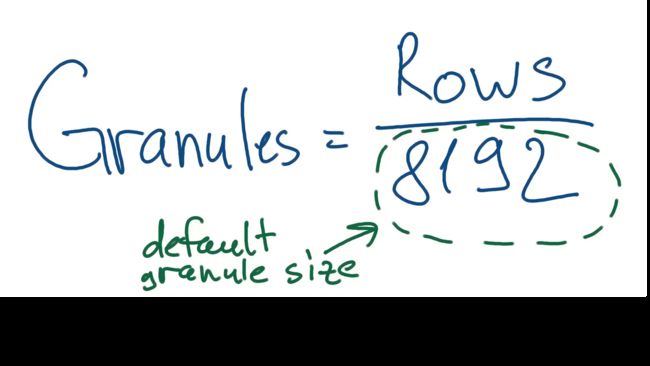
粒度大小基于表的设置(创建表时设置),缺省为8192,粒度数量可以通过下面公式进行计算:
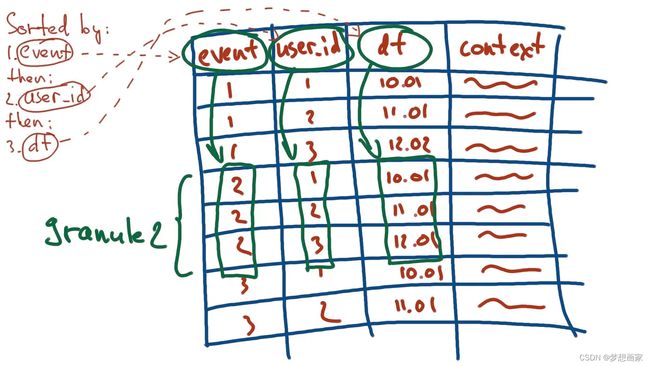
单个粒度可以理解为虚拟小表(包括较少记录的子集,缺省为8192)。每个粒度按顺序存储行(order by 指定的键顺序):
主键标记和索引存储
主键仅存储每个粒度第一行,而不是每一行:
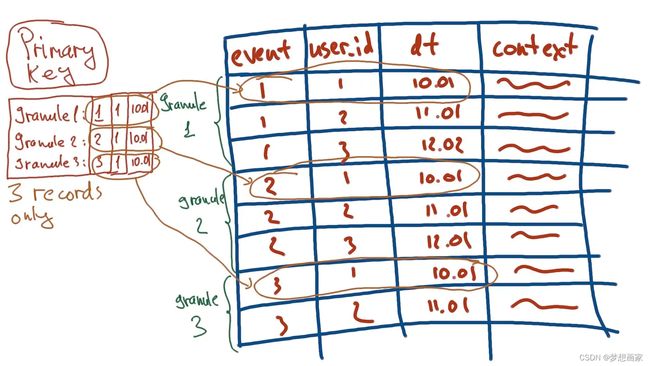
这就是ClickHouse查询快的原因。不保存所有值,技能保存部分使得主键特别小。Clickhouse不是查找单个行,而是先找到某个粒度,然后只对找到的粒度执行完整扫描(这是非常高效的,因为每个颗粒的尺寸都很小):
查询性能
这里填充5千万测试记录验证查询性能:
insert into test
select * FROM generateRandom(
'dt datetime, event Text, user_id UInt64, context Text',1, 20
) LIMIT 50000;
前节表定义了主键包括三个字段:

如果ClickHouse查询条件使用主键则能够利用主键提升性能:
SELECT *
FROM test
WHERE event = 'YJ9'
返回结果:
Query id: d237e4d9-5b6e-453f-befb-57e5ae84fd28
┌──────────────────dt─┬─event─┬──────────────user_id─┬─context─┐
│ 2079-09-01 19:10:41 │ YJ9 │ 16936621875208636777 │ │
└─────────────────────┴───────┴──────────────────────┴─────────┘
1 rows in set. Elapsed: 0.002 sec. Processed 8.19 thousand rows, 414.23 KB (3.78 million rows/s., 190.99 MB/s.)
我们看到搜索特定event值,仅扫描了单个粒度。这里YJ9只有一条,可以通过下面语句进行确认:
SELECT
event,
count(event != '') AS cnt
FROM test
GROUP BY event
HAVING cnt = 1
LIMIT 10
Query id: c5dc21e7-929a-4e0d-9ae9-0213caffee41
┌─event────┬─cnt─┐
│ Po$h\VLc │ 1 │
│ YJ9 │ 1 │
│ PS6>;.f │ 1 │
│ ov │ 1 │
│ |FYQ~ │ 1 │
│ yZ$~cP │ 1 │
│ kUAfps@ │ 1 │
│ kX{]/:g( │ 1 │
│ ]R,gw,vA │ 1 │
│ qu │ 1 │
└──────────┴─────┘
下面通过explain查看执行计划进行确认:
explain indexes = 1
SELECT *
FROM test
WHERE event = 'YJ9'
返回结果:
EXPLAIN json = 1, indexes = 1
SELECT *
FROM test
WHERE event = 'YJ9'
Query id: 6954664a-6e9c-4417-adba-d6f04270734b
┌─explain─────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Filter (WHERE) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ event │
│ Condition: (event in ['YJ9', 'YJ9']) │
│ Parts: 1/1 │
│ Granules: 1/6 │
└─────────────────────────────────────────────────────────────────────────────┘
可以看到仅使用了1/6,即扫描一个粒度。这说明不扫描全表,ClickHouse使用主键索引首先定义相应的粒度,然后在该粒度中扫描过滤,我们也可以在查询中使用多个主键列:
SELECT *
FROM test
WHERE event = 'YJ9' and user_id = '16936621875208636777'
返回结果:
SELECT *
FROM test
WHERE (event = 'YJ9') AND (user_id = '16936621875208636777')
Query id: 8deeb18f-8e85-4cb6-b8e4-fe6e11f2715c
┌──────────────────dt─┬─event─┬──────────────user_id─┬─context─┐
│ 2079-09-01 19:10:41 │ YJ9 │ 16936621875208636777 │ │
└─────────────────────┴───────┴──────────────────────┴─────────┘
1 rows in set. Elapsed: 0.003 sec. Processed 8.19 thousand rows, 414.23 KB (2.65 million rows/s., 133.93 MB/s.)
仍然仅扫描了单个粒度。相反如果使用条件列不在主键中,ClickHouse则需要全表扫描:
SELECT count(*)
FROM test where context = '{'
返回结果:
SELECT count(*)
FROM test
WHERE context = '{'
Query id: 0c6f01a1-7192-4d46-ad1b-89e465f051fd
┌─count()─┐
│ 24 │
└─────────┘
1 rows in set. Elapsed: 0.002 sec. Processed 50.00 thousand rows, 951.29 KB (21.15 million rows/s., 402.31 MB/s.)
可以看到ClickHouse执行了全表扫描。另外,如果使用条件列跳过主键的前缀,ClickHouse也不能完全利用主键索引:
SELECT *
FROM test
WHERE user_id = '16936621875208636777'
返回结果:
SELECT *
FROM test
WHERE user_id = '16936621875208636777'
Query id: d9d2675d-b231-4458-9bc1-6854cf4cf865
┌──────────────────dt─┬─event─┬──────────────user_id─┬─context─┐
│ 2079-09-01 19:10:41 │ YJ9 │ 16936621875208636777 │ │
└─────────────────────┴───────┴──────────────────────┴─────────┘
1 rows in set. Elapsed: 0.003 sec. Processed 50.00 thousand rows, 748.69 KB (17.25 million rows/s., 258.23 MB/s.)
主键索引利用
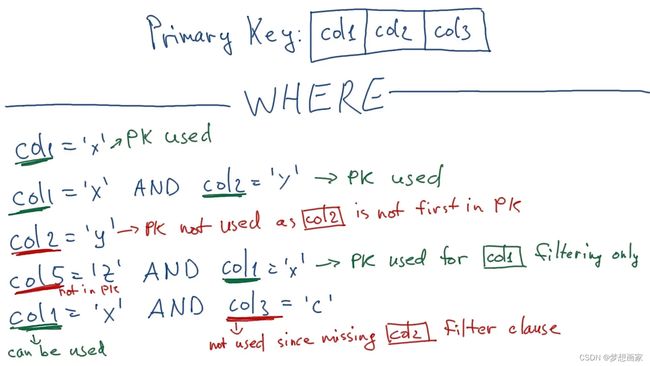
下面总结ClickHouse 利用主键索引的场景:
- 查询where或order子句包含主键的第一列
- 查询where包含主键的前x列,order子句包含主键的前x列
- 查询where包含主键的所有列
- 其他情况,ClickHouse需要扫描全表获取请求数据。
总结
基于ClickHouse优化结构和排序数据,正确利用主键索引能节约资源,极大提升查询性能。总之选择主键需遵循下面简单规则:
- 选择计划在大多数查询中使用的列
- 选择大部分查询需要的列,如主键包含3列,查询包括1列或2列
- 如果查询不确定,首先使用低基数列,然后再使用高基数列,从而获得更好的压缩和提高磁盘利用率
参考资料:https://medium.com/datadenys/how-clickhouse-primary-key-works-and-how-to-choose-it-4aaf3bf4a8b9