视频压缩H264编码原理介绍
一、视频压缩编码概念
编码这一概念在通信与信息处理领域中广泛使用,其基本原理是将信息按照一定规则使用某种形式的码流表示与传输。常用的需要编码的信息主要有:文字、语音、视频和控制信息等。
1. 为什么需要对视频编码?
对于视频数据而言,视频编码的最主要目的是数据压缩。这是因为动态图像的像素形式表示数据量极为巨大,存储空间和传输带宽完全无法满足保存和传输的需求。例如,图像的每个像素的三个颜色分量RGB各需要一个字节表示,那么每一个像素至少需要3字节,分辨率1280×720的图像的大小为2.76M字节。
如果对于同样分辨率的视频,如果帧率为25帧/秒,那么传输所需的码率将达到553Mb/s!如果对于更高清的视频,如1080P、4k、8k视频,其传输码率更是惊人。这样的数据量,无论是存储还是传输都无法承受。因此,对视频数据进行压缩称为了必然之选。
2. 视频信息为什么可以被压缩?
视频信息之所以存在大量可以被压缩的空间,是因为其中本身就存在大量的数据冗余。其主要类型有:
时间冗余:视频相邻的两帧之间内容相似,存在运动关系
空间冗余:视频的某一帧内部的相邻像素存在相似性
编码冗余:视频中不同数据出现的概率不同
视觉冗余:观众的视觉系统对视频中不同的部分敏感度不同
针对这些不同类型的冗余信息,在各种视频编码的标准算法中都有不同的技术专门应对,以通过不同的角度提高压缩的比率。
3. 视频编码标准化组织
从事视频编码算法的标准化组织主要有两个,ITU-T和ISO。
ITU-T,全称International Telecommunications Union - Telecommunication Standardization Sector,即国际电信联盟——电信标准分局。该组织下设的VECG(Video Coding Experts Group)主要负责面向实时通信领域的标准制定,主要制定了H.261/H263/H263+/H263++等标准。
ISO,全称International Standards Organization,即国际标准化组织。该组织下属的MPEG(Motion Picture Experts Group),即移动图像专家组主要负责面向视频存储、广播电视、网络传输的视频标准,主要制定了MPEG-1/MPEG-4等。
实际上,真正在业界产生较强影响力的标准均是由两个组织合作产生的。比如MPEG-2、H.264/AVC和H.265/HEVC等。
2003年3月,ITU-T和ISO/IEC 正式公布了H.264/MPEG-4 AVC视频压缩标准。H.264作为目前应用最为广泛的视频编码标准,在提高编码效率和灵活性方面取得了巨大成功,使得数字视频有效地应用在各种各样的网络类型和工程领域。为了在关键技术上不受国外牵制、节约专利费用支出,中国制定了AVS系列标准,可以提供与H.264/AVC相当的编码效率。
近年来随着用户要求的不断提升,高清(1920x1080)和超高清(3840x2160)视频的应用越来越广泛。相比于标清视频,高清视频分辨率更大更清晰,但是相应的数据量也随之增加。在存储空间和网络带宽有限的情况下,现有的视频压缩技术已经不能满足现实的应用需求。为了解决高清及超高清视频急剧增长的数据率给网络传输和数据存储带来的冲击,ITU-T和ISO/IEC联合制定了具有更高压缩效率的新一代视频压缩标准h265/HEVC(High Efficiency Video Coding)。
HEVC基于传统的混合视频编码框架,采用了更多的技术创新,包括灵活的块划分、更精细的帧内预测、新加入的Merge模式、Tile划分、自适应样点补偿等。灵活的块划分对编码性能提升最大,块划分包括编码单元(CU)、预测单元(PU)和变换单元(TU)。这些技术使得HEVC编码性能比H.264/AVC提高了一倍。但是,这些技术也使得HEVC编码器的复杂度大大增加,不利于HEVC编码器的实时应用和推广。
为了专门处理视频信息中的多种冗余,视频压缩编码采用了多种技术来提高视频的压缩比率。其中常见的有预测编码、变换编码和熵编码等。
至此,明白,H.264/H.265是一套视频压缩算法,是一套标准组织制定的视频压缩标准、规范。
视频质量
标清:480x800
普通高清:720x1280 720P
高清:1920x1080 1080P
2K:2048*1024
超高清 4K:3840x2160
1. 预测编码
预测编码可以用于处理视频中的时间和空间域的冗余。视频处理中的预测编码主要分为两大类:帧内预测和帧间预测。
帧内预测:预测值与实际值位于同一帧内,用于消除图像的空间冗余;帧内预测的特点是压缩率相对较低,然而可以独立解码,不依赖其他帧的数据;通常视频中的关键帧都采用帧内预测。
帧间预测:帧间预测的实际值位于当前帧,预测值位于参考帧,用于消除图像的时间冗余;帧间预测的压缩率高于帧内预测,然而不能独立解码,必须在获取参考帧数据之后才能重建当前帧。
通常在视频码流中,I帧全部使用帧内编码,P帧/B帧中的数据可能使用帧内或者帧间编码。
2. 变换编码
目前主流的视频编码算法均属于有损编码,通过对视频造成有限而可以容忍的损失,获取相对更高的编码效率。而造成信息损失的部分即在于变换量化这一部分。在进行量化之前,首先需要将图像信息从空间域通过变换编码变换至频域,并计算其变换系数供后续的编码。
在视频编码算法中通常使用正交变换进行变换编码,常用的正交变换方法有:离散余弦变换(DCT)、离散正弦变换(DST)、K-L变换等。
3. 熵编码
视频编码中的熵编码方法主要用于消除视频信息中的统计冗余。由于信源中每一个符号出现的概率并不一致,这就导致使用同样长度的码字表示所有的符号会造成浪费。通过熵编码,针对不同的语法元素分配不同长度的码元,可以有效消除视频信息中由于符号概率导致的冗余。
在视频编码算法中常用的熵编码方法有变长编码和算术编码等,具体来说主要有上下文自适应的变长编码(CAVLC)和上下文自适应的二进制算术编码(CABAC)。
【H.264/AVC视频编解码技术详解】三. H.264简介_Workshop of Wenjie.Yin-CSDN博客_h.264编解码
H.264和H.265对比
1、版本
H.265是新的编码协议,也即是H.264的升级版。H.265标准保留H.264原来的某些技术,同时对一些相关的技术加以改进。新技术使用先进的技术用以改善码流、编码质量、延时和算法复杂度之间的关系,达到最优化设置;
2、降码率
比起H.264/AVC,H.265/HEVC提供了更多不同的工具来降低码率,以编码单位来说,H.264中每个宏块(macroblock/MB)大小都是固定的16x16像素,而H.265的编码单位可以选择从最小的8x8到最大的64x64;
3、新技术使用先进的技术用以改善码流、编码质量、延时和算法复杂度之间的关系,达到最优化设置;
4、采用了块的四叉树划分结构
H.265相比H.264最主要的改变是采用了块的四叉树划分结构,采用了从64x64~8x8像素的自适应块划分,并基于这种块划分结构采用一系列自适应的预测和变换等编码技术;
5、算法优化
H264由于算法优化,可以低于1Mbps的速度实现标清数字图像传送;H265则可以实现利用1~2Mbps的传输速度传送720P(分辨率1280*720)普通高清音视频传送;
6、同样的画质和同样的码率,H.265比H2.64 占用的存储空间要少理论50%;
7、占用的存储空间缩小
比起H.264/AVC,H.265/HEVC提供了更多不同的工具来降低码率,以编码单位来说,H.264中每个宏块(macroblock/MB)大小都是固定的16x16像素,而H.265的编码单位可以选择从最小的8x8到最大的64x64。那么,在相同的图象质量下,相比于H.264,通过H.265编码的视频大小将减少大约39-44%;
总而言之,HEVC将传统基于块的视频编码模式推向更高的效率水平,总结一下就是:
-可变量的尺寸转换(从4×4 到32×32)
-四叉树结构的预测区域(从64×64到4×4)
-基于候选清单的运动向量预测。
-多种帧内预测模式。
-更精准的运动补偿滤波器。
-优化的去块、采样点自适应偏移滤波器等。
H264视频压缩算法现在无疑是所有视频压缩技术中使用最广泛,最流行的。随着 x264/openh264以及ffmpeg等开源库的推出,大多数使用者无需再对H264的细节做过多的研究,这大降低了人们使用H264的成本。
但为了用好H264,我们还是要对H264的基本原理弄清楚才行。今天我们就来看看H264的基本原理。
H264概述
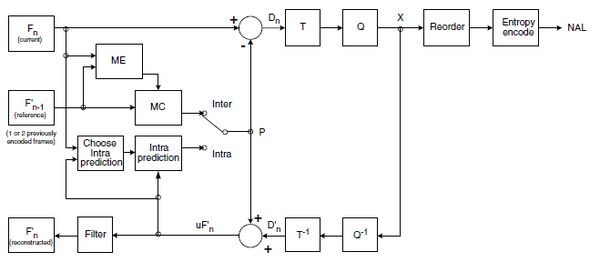
H264压缩技术主要采用了以下几种方法对视频数据进行压缩。包括:
- 帧内预测压缩,解决的是空域数据冗余问题。
- 帧间预测压缩(运动估计与补偿),解决的是时域数据冗徐问题。
- 整数离散余弦变换(DCT),将空间上的相关性变为频域上无关的数据然后进行量化。
- CABAC压缩。
经过压缩后的帧分为:I帧,P帧和B帧:
- I帧:关键帧,采用帧内压缩技术。
- P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧音压缩技术。
- B帧:双向参考帧,在压缩时,它即参考前而的帧,又参考它后面的帧。采用帧间压缩技术。
除了I/P/B帧外,还有图像序列GOP。
- GOP:两个I帧之间是一个图像序列,在一个图像序列中只有一个I帧。如下图所示:
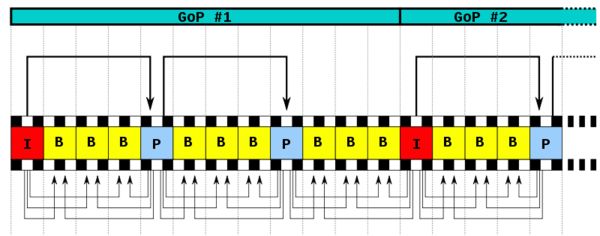
下面我们就来详细描述一下H264压缩技术。
H264压缩技术
H264的基本原理其实非常简单,下我们就简单的描述一下H264压缩数据的过程。通过摄像头采集到的视频帧(按每秒 30 帧算),被送到 H264 编码器的缓冲区中。编码器先要为每一幅图片划分宏块。
以下面这张图为例:

划分宏块
H264默认是使用 16X16 大小的区域作为一个宏块,也可以划分成 8X8 大小。

划分好宏块后,计算宏块的象素值。

以此类推,计算一幅图像中每个宏块的像素值,所有宏块都处理完后如下面的样子。

划分子块
H264对比较平坦的图像使用 16X16 大小的宏块。但为了更高的压缩率,还可以在 16X16 的宏块上更划分出更小的子块。子块的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4非常的灵活。

上幅图中,红框内的 16X16 宏块中大部分是蓝色背景,而三只鹰的部分图像被划在了该宏块内,为了更好的处理三只鹰的部分图像,H264就在 16X16 的宏块内又划分出了多个子块。
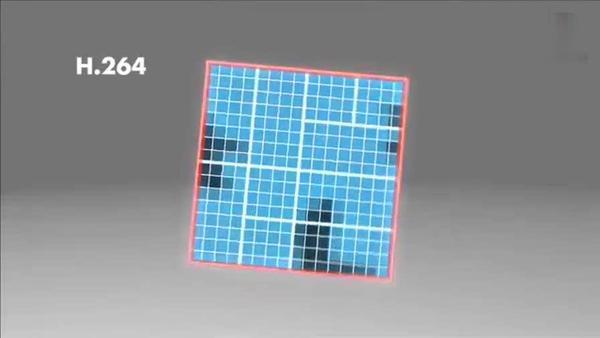
这样再经过帧内压缩,可以得到更高效的数据。下图是分别使用mpeg-2和H264对上面宏块进行压缩后的结果。其中左半部分为MPEG-2子块划分后压缩的结果,右半部分为H264的子块划压缩后的结果,可以看出H264的划分方法更具优势。

宏块划分好后,就可以对H264编码器缓存中的所有图片进行分组了。
帧分组
对于视频数据主要有两类数据冗余,一类是时间上的数据冗余,另一类是空间上的数据冗余。其中时间上的数据冗余是最大的。下面我们就先来说说视频数据时间上的冗余问题。
为什么说时间上的冗余是最大的呢?假设摄像头每秒抓取30帧,这30帧的数据大部分情况下都是相关联的。也有可能不止30帧的的数据,可能几十帧,上百帧的数据都是关联特别密切的。
对于这些关联特别密切的帧,其实我们只需要保存一帧的数据,其它帧都可以通过这一帧再按某种规则预测出来,所以说视频数据在时间上的冗余是最多的。
为了达到相关帧通过预测的方法来压缩数据,就需要将视频帧进行分组。那么如何判定某些帧关系密切,可以划为一组呢?我们来看一下例子,下面是捕获的一组运动的台球的视频帧,台球从右上角滚到了左下角。


H264编码器会按顺序,每次取出两幅相邻的帧进行宏块比较,计算两帧的相似度。如下图:

通过宏块扫描与宏块搜索可以发现这两个帧的关联度是非常高的。进而发现这一组帧的关联度都是非常高的。因此,上面这几帧就可以划分为一组。其算法是:在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内,我们认为这样的图可以分到一组。
在这样一组帧中,经过编码后,我们只保留第一帖的完整数据,其它帧都通过参考上一帧计算出来。我们称第一帧为IDR/I帧,其它帧我们称为P/B帧,这样编码后的数据帧组我们称为GOP。
运动估计与补偿
在H264编码器中将帧分组后,就要计算帧组内物体的运动矢量了。还以上面运动的台球视频帧为例,我们来看一下它是如何计算运动矢量的。
H264编码器首先按顺序从缓冲区头部取出两帧视频数据,然后进行宏块扫描。当发现其中一幅图片中有物体时,就在另一幅图的邻近位置(搜索窗口中)进行搜索。如果此时在另一幅图中找到该物体,那么就可以计算出物体的运动矢量了。下面这幅图就是搜索后的台球移动的位置。

通过上图中台球位置相差,就可以计算出台图运行的方向和距离。H264依次把每一帧中球移动的距离和方向都记录下来就成了下面的样子。

运动矢量计算出来后,将相同部分(也就是绿色部分)减去,就得到了补偿数据。我们最终只需要将补偿数据进行压缩保存,以后在解码时就可以恢复原图了。压缩补偿后的数据只需要记录很少的一点数据。如下所示:

我们把运动矢量与补偿称为帧间压缩技术,它解决的是视频帧在时间上的数据冗余。除了帧间压缩,帧内也要进行数据压缩,帧内数据压缩解决的是空间上的数据冗余。下面我们就来介绍一下帧内压缩技术。
帧内预测
人眼对图象都有一个识别度,对低频的亮度很敏感,对高频的亮度不太敏感。所以基于一些研究,可以将一幅图像中人眼不敏感的数据去除掉。这样就提出了帧内预测技术。
H264的帧内压缩与JPEG很相似。一幅图像被划分好宏块后,对每个宏块可以进行 9 种模式的预测。找出与原图最接近的一种预测模式。

下面这幅图是对整幅图中的每个宏块进行预测的过程。

帧内预测后的图像与原始图像的对比如下:

然后,将原始图像与帧内预测后的图像相减得残差值。

再将我们之前得到的预测模式信息一起保存起来,这样我们就可以在解码时恢复原图了。效果如下:

经过帧内与帧间的压缩后,虽然数据有大幅减少,但还有优化的空间。
对残差数据做DCT
可以将残差数据做整数离散余弦变换,去掉数据的相关性,进一步压缩数据。如下图所示,左侧为原数据的宏块,右侧为计算出的残差数据的宏块。
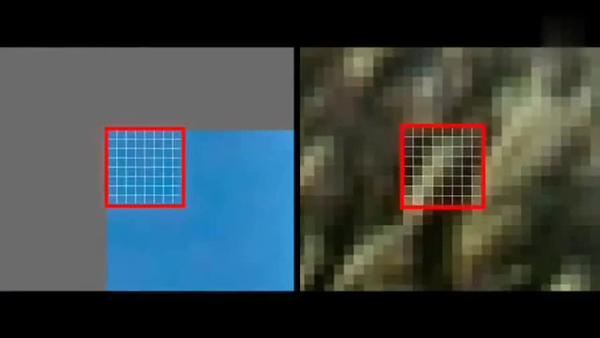
将残差数据宏块数字化后如下图所示:
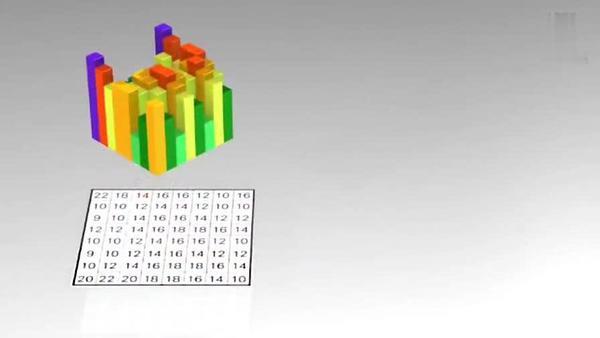
将残差数据宏块进行 DCT 转换。

去掉相关联的数据后,我们可以看出数据被进一步压缩了。

做完 DCT 后,还不够,还要进行 CABAC 进行无损压缩。
CABAC
上面的帧内压缩是属于有损压缩技术。也就是说图像被压缩后,无法完全复原。而CABAC属于无损压缩技术。
无损压缩技术大家最熟悉的可能就是哈夫曼编码了,给高频的词一个短码,给低频词一个长码从而达到数据压缩的目的。MPEG-2中使用的VLC就是这种算法,我们以 A-Z 作为例子,A属于高频数据,Z属于低频数据。看看它是如何做的。

CABAC也是给高频数据短码,给低频数据长码。同时还会根据上下文相关性进行压缩,这种方式又比VLC高效很多。其效果如下:

现在将 A-Z 换成视频帧,它就成了下面的样子。

从上面这张图中明显可以看出采用 CACBA 的无损压缩方案要比 VLC 高效的多。
小结
至此,我们就将H264的编码原理讲完了。本篇文章主要讲了以下以点内容:
1. 简音介绍了H264中的一些基本概念。如I/P/B帧, GOP。
2. 详细讲解了H264编码的基本原理,包括:
- 宏块的划分
- 图像分组
- 帧内压缩技术原理
- 帧间压缩技术原理。
- DCT
- CABAC压缩原理。
希望以上内容能对您有所帮助。谢谢!
H264基本原理 - 李超的文章 - 知乎 https://zhuanlan.zhihu.com/p/31056455
参考链接:https://blog.csdn.net/jakezhang1990/article/details/107817278