Python爬虫 批量采集京东商品数据,实时了解商品价格走势
文章目录
- 写在前面
- 准备工作
-
-
- 驱动安装
- 模块使用与介绍
-
- 流程解析
- 完整代码
- 效果展示
写在前面
这不快过年了,又是要买年货,又是要给女朋友买礼物的,分析一下价格,看看哪些是真的降价了~
准备工作
驱动安装
实现案例之前,我们要先安装一个谷歌驱动,因为我们是使用selenium 操控谷歌驱动,然后操控浏览器实现自动操作的,模拟人的行为去操作浏览器。
以谷歌浏览器为例,打开浏览器看下我们自己的版本,然后下载跟自己浏览器版本一样或者最相近的版本,下载后解压一下,把解压好的插件放到我们的python环境里面,或者和代码放到一起也可以。
模块使用与介绍
seleniumpip install selenium ,直接输入selenium的话是默认安装最新的,selenium后面加上版本号就是安装对应的的版本;csv内置模块,不需要安装,把数据保存到Excel表格用的;time内置模块,不需要安装,时间模块,主要用于延时等待;
流程解析
我们访问一个网站,要输入一个网址,所以代码也是这么写的。
首先导入模块
from selenium import webdriver
文件名或者包名不要命名为selenium,会导致无法导入。
webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器。
实例化浏览器对象 ,我这里用的是谷歌,建议大家用谷歌,方便一点。
driver = webdriver.Chrome()
我们用get访问一个网址,自动打开网址。
driver.get('https://www.jd.com/')
运行一下

打开网址后,以买口红为例。
我们首先要通过你想购买的商品关键字来搜索得到商品信息,用搜索结果去获取信息。
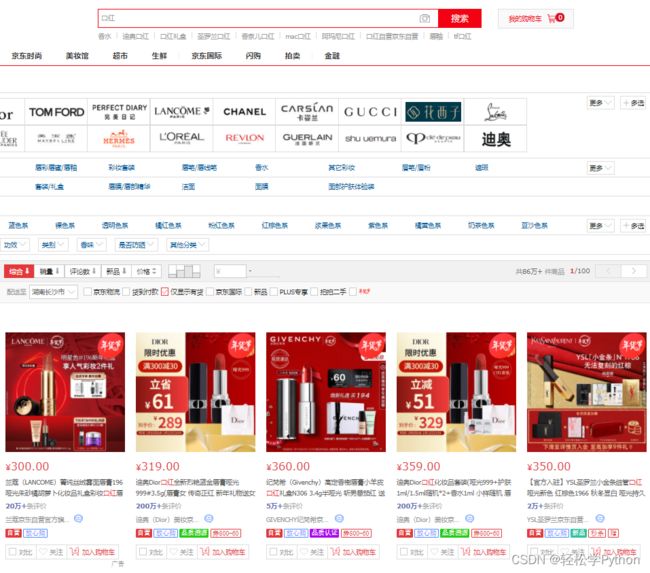
那我们也要写一个输入,空白处点击右键,选择检查。
选择element 元素面板

鼠标点击左边的箭头按钮,去点击搜索框,它就会直接定位到搜索标签。
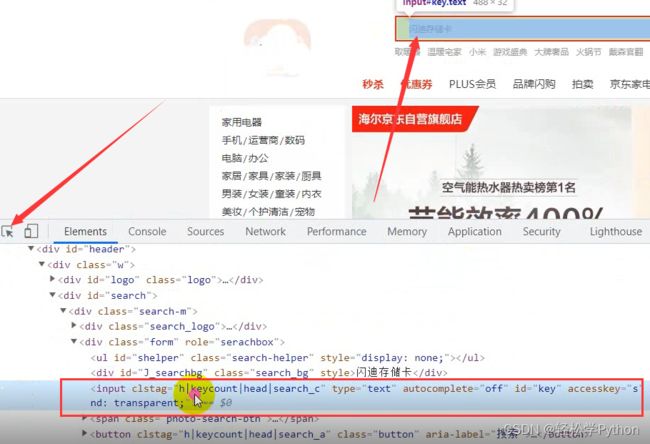
在标签上点击右键,选择copy,选择copy selector 。

如果你是xpath ,就copy它的xpath 。
然后把我们想要搜索的内容写出来
driver.find_element_by_css_selector('#key').send_keys('口红')
再运行的时候,它就会自动打开浏览器进入目标网址搜索口红。
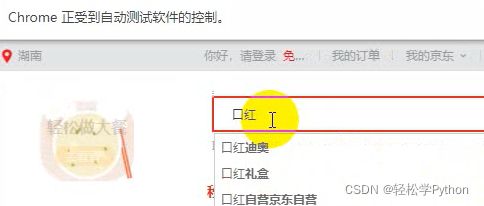
同样的方法,找到搜索按钮进行点击。
driver.find_element_by_css_selector('.button').click()
再运行就会自动点击搜索了
页面搜索出来了,那么咱们正常浏览网页是要下拉网页对吧,咱们让它自动下拉就好了。
先导入time模块
import time
执行页面滚动的操作
def drop_down():
"""执行页面滚动的操作""" # javascript
for x in range(1, 12, 2): # for循环下拉次数,取1 3 5 7 9 11, 在你不断的下拉过程中, 页面高度也会变的;
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 执行我们JS代码
循环写好了,然后调用一下。
drop_down()
我们再给它来个延时
driver.implicitly_wait(10)
这是一个隐式等待,等待网页延时,网不好的话加载很慢。
隐式等待不是必须等十秒,在十秒内你的网络加载好后,它随时会加载,十秒后没加载出来的话才会强行加载。
还有另外一种死等的,你写的几秒就等几秒,相对没有那么人性化。
time.sleep(10)
加载完数据后我们需要去找商品数据来源
价格/标题/评价/封面/店铺等等
还是鼠标右键点击检查,在element ,点击小箭头去点击你想查看的数据。
可以看到都在li标签里面

获取所有的 li 标签内容,还是一样的,直接copy 。

在左下角就有了
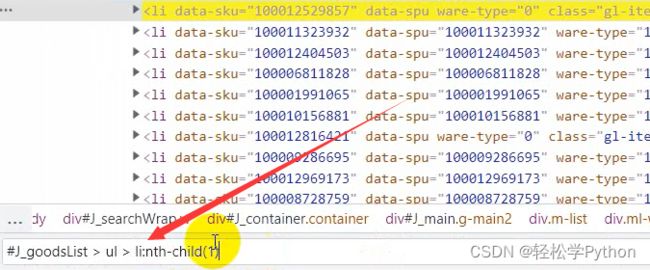
这里表示的是取的第一个,但是我们是要获取所有的标签,所以左边框框里 li 后面的可以删掉不要。
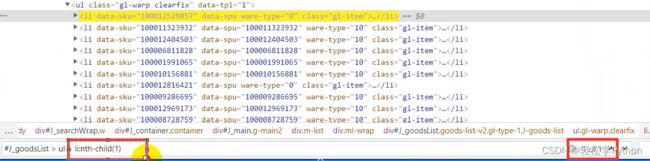
不要的话,可以看到这里是60个商品数据,一页是60个。
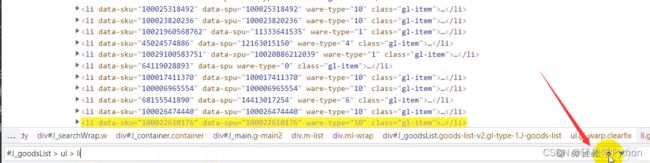
所以我们把剩下的复制过来, 用lis接收一下 。
lis = driver.find_elements_by_css_selector('#J_goodsList ul li')
因为我们是获取所有的标签数据,所以比之前多了一个s

打印一下
print(lis)
通过lis返回数据 列表 [] 列表里面的元素 <> 对象

遍历一下,把所有的元素拿出来。
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品标题 获取标签文本数据
price = li.find_element_by_css_selector('.p-price strong i').text # 价格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 评论量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店铺名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品详情页
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推导式 ','.join 以逗号把列表中的元素拼接成一个字符串数据
dit = {
'商品标题': title,
'商品价格': price,
'评论量': commit,
'店铺名字': shop_name,
'标签': icon,
'商品详情页': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
搜索功能
key_world = input('请输入你想要获取商品数据: ')
要获取的数据 ,获取到后保存CSV
f = open(f'京东{key_world}商品数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品标题',
'商品价格',
'评论量',
'店铺名字',
'标签',
'商品详情页',
])
csv_writer.writeheader()
然后再写一个自动翻页
for page in range(1, 11):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1)
drop_down()
get_shop_info() # 下载数据
driver.find_element_by_css_selector('.pn-next').click() # 点击下一页
完整代码
from selenium import webdriver
import time
import csv
def drop_down():
"""执行页面滚动的操作"""
for x in range(1, 12, 2):
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 执行JS代码
key_world = input('请输入你想要获取商品数据: ')
f = open(f'京东{key_world}商品数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品标题',
'商品价格',
'评论量',
'店铺名字',
'标签',
'商品详情页',
])
csv_writer.writeheader()
# 实例化一个浏览器对象
driver = webdriver.Chrome()
driver.get('https://www.jd.com/') # 访问一个网址 打开浏览器 打开网址
# 通过css语法在element(元素面板)里面查找 #key 某个标签数据 输入一个关键词 口红
driver.find_element_by_css_selector('#key').send_keys(key_world) # 找到输入框标签
driver.find_element_by_css_selector('.button').click() # 找到搜索按钮 进行点击
# time.sleep(10) # 等待
# driver.implicitly_wait(10) # 隐式等待
def get_shop_info():
# 第一步 获取所有的li标签内容
driver.implicitly_wait(10)
lis = driver.find_elements_by_css_selector('#J_goodsList ul li') # 获取多个标签
# 返回数据 列表 [] 列表里面的元素 <> 对象
# print(len(lis))
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品标题 获取标签文本数据
price = li.find_element_by_css_selector('.p-price strong i').text # 价格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 评论量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店铺名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品详情页
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推导式 ','.join 以逗号把列表中的元素拼接成一个字符串数据
dit = {
'商品标题': title,
'商品价格': price,
'评论量': commit,
'店铺名字': shop_name,
'标签': icon,
'商品详情页': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
# print(href)
for page in range(1, 11):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1)
drop_down()
get_shop_info() # 下载数据
driver.find_element_by_css_selector('.pn-next').click() # 点击下一页
driver.quit() # 关闭浏览器
效果展示


后面没写那么详细了,有点事情就直接发了,有视频的,可以找我看视频
代码是没得问题的,大家可以去试试,有什么问题欢迎在评论区交流~