爬虫实战(1)————百度首页爬取
百度首页爬取
提供我的爬取页面的思路,不一定是正确的但是我都是按照这个思路走的
第一步(页面分析)
可以看到页面非常简单
那么我们的需求就是 首先 构造url 然后观察我们想要爬取的对象
我们的需求是:爬取 新闻 hao123 这些的 文字 以及点击以后要跳转的页面的url
首先构造百度的url
直接复制url
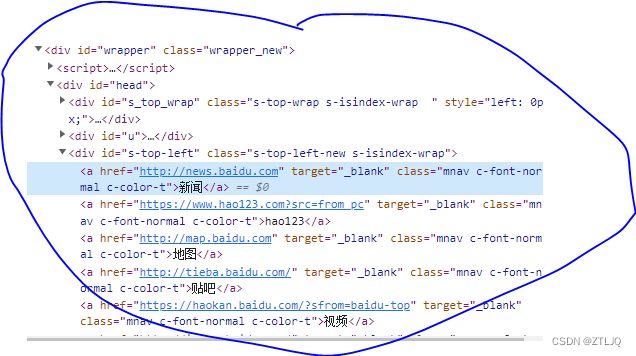
url = ('https://www.baidu.com/')然后使用F12开发工具 查看 新闻这些标题的 位置 以及会跳转的url的位置在什么地方
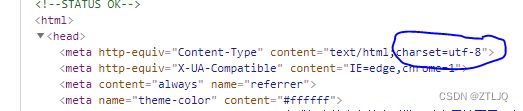
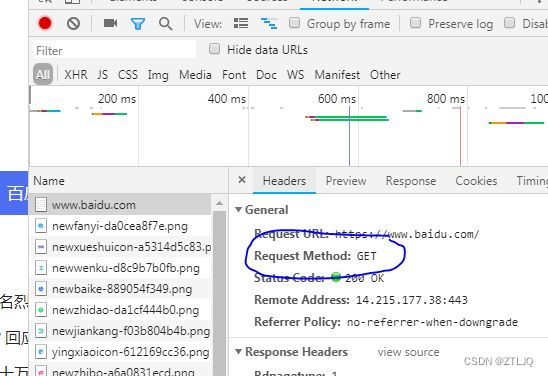
这里我们还需要查看 网页的编码方式和是POST方法还是GET方法
如图片所示 圈出的部分是新闻 的文本以及跳转的Url所在的位置 以及 使用的是什么编码方式和get方法
我们可以使用 xpath 正则表达式 以及BeautifiSoup 进行定位元素 然后 使用get方法获取元素
那么我们就可以开始写程序 已经分析完页面了
第二步(代码的编写)
在上面我们以及分析完页面以后 我选择使用xpath方法来定位元素 接下来导入库
import requests
from lxml import etree这里有一个问题会出现 就是 我们初学的时候 设置headers 就只设置一个User-Agent
但是我们在爬取一些网站的时候 他需要的头文件不只这些 网站会设置反爬 如果我们不伪装的像一点 就会被识别 爬虫就会失效
那么在我们爬取网站的时候 可以多使用一点头文件 如图
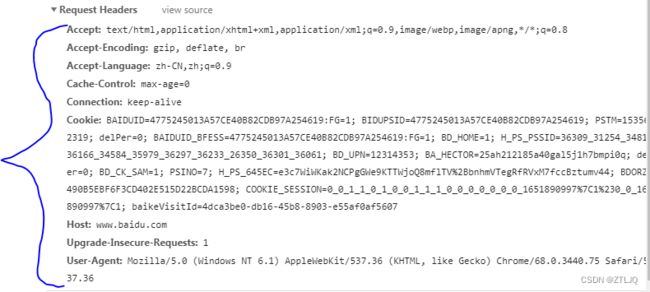
这些文件我们都可以使用 用来伪装我们的爬虫程序 代码如下
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9'
}接下来就是定义请求头 然后设置编码格式
req = requests.get(url=url,headers=headers)
content = req.content.decode('utf-8')接下来就是 使用xpath语法 去定位元素
在使用xpath语法的时候 我们需要在页面观察定位的元素在什么地方
首先找到 id唯一命名 然后 定位到以后 判断 一个是在href元素中 一个是a标签的文本当中
如下图以及代码

get = etree.HTML(content)
geturl = get.xpath('//div[@id="s-top-left"]/a/@href')
getname = get.xpath('//div[@id="s-top-left"]/a/text()')运行完以后 查看是否能成功爬出想要的东西 可以print 一下 geturl 和 getname 查看是否爬取成功
接下来就相当于一个总和的步骤 爬取完以后我们需要把爬取的数据放到一起
要用到 zip函数
zip函数 相当于 可以拼接数据 一个geturl对应一个getname 让我们更清楚的看出来 一个名字然后他跳转的Url是多少
这里需要用到字典 来存放数据 代码如下:
works=[]
for urls,names in zip(geturl,getname):
work={
"url":urls,
"name":names
}
works.append(work)
print(works)第三步(检查错误 优化代码)
在写这个代码的时候 我一开始用的不是zip 我直接写了一个for就写完了 这个zip方法是我后来改的
给大家多提供几种写法 源码如下 下面这个我是直接用for方法 与 xpath结合 如果刚刚入门xpath语法的小伙伴 可以看一看 使用zip的方法 下面的这个 是结合起来 可能稍微难一点
# get = etree.HTML(content)
# works=[]
# select = get.xpath('//div[@id="s-top-left"]/a')
# for selects in select:
# geturl=selects.xpath('./@href')
# urlname = selects.xpath('./text()')
# work={
# "url":geturl,
# "name":urlname
# }
# works.append(work)
# print(works)最后附上源码
import requests
from lxml import etree
url = ('https://www.baidu.com/')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9'
}
req = requests.get(url=url,headers=headers)
content = req.content.decode('utf-8')
get = etree.HTML(content)
geturl = get.xpath('//div[@id="s-top-left"]/a/@href')
getname = get.xpath('//div[@id="s-top-left"]/a/text()')
works=[]
for urls,names in zip(geturl,getname):
work={
"url":urls,
"name":names
}
works.append(work)
print(works)