(c语言)万字详解字符函数,字符串函数,内存函数--内含所有模拟实现方法
目录
前言
1. 字符串操作函数
1.1 strlen
1.1.1 字符串以 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包含 '\0' )
1.1.2 参数指向的字符串必须要以 '\0' 结束。
1.1.3注意函数的返回值为size_t,是无符号的( 易错 )
1.1.4 strlen函数的三种模拟实现方法
1.2 strcpy
1.2.1 源字符串必须以 '\0' 结束,会将源字符串中的 '\0' 拷贝到目标空间,目标空间必须足够大,以确保能存放源字符串。
1.2.2 目标空间必须可变。
1.2.3 模拟实现方法
1.3 strcat
1.3.1 目标空间必须有足够的大,能容纳下源字符串的内容 目标空间必须可修改。
1.3.2 模拟实现方法
1.3.3 提示
1.4 strcmp
1.4.1 模拟实现方法
1.5 strncpy
1.5.1 模拟实现
1.6 strncat
1.6.1 模拟实现
1.7 strncmp
1.7.1 模拟实现
1.8 strstr
1.8.1 模拟实现
1.9 strtok
1.10 strerror
2. 字符操作函数
2.1 字符分类函数
2.2 字符转换函数
3.内存操作函数
3.1 memcpy
3.1.1 模拟实现
3.2 memmove
3.2.1 模拟实现
3.3 memcmp
3.4 memset
前言
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的变量,字符串通常放在常量字符串或者字符数组中。而字符串常量则适用于那些对它不做修改的字符串函数。
1. 字符串操作函数
1.1 strlen
![]()
1.1.1 字符串以 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包含 '\0' )
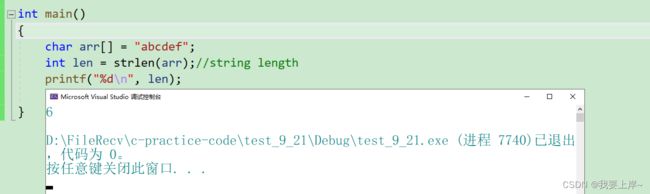
1.1.2 参数指向的字符串必须要以 '\0' 结束。

这是因为arr数组中没有 '\0',所以strlen函数会在数组后面的空间中找 '\0' 直到找到为止。
1.1.3注意函数的返回值为size_t,是无符号的( 易错 )
int main()
{
int len = 0;
if (strlen("abc") - strlen("qwerty") > 0)
{
printf(">\n");
}
else
{
printf("<=\n");
}
}你会猜答案是什么?一般人会认为是 <= 但是strlen函数的返回值是无符号整数,所以strlen("abc") - strlen("qwerty") 这个表达式的值是-3,但是strlen函数会认为 -3 是一个非常大的无符号整数,所以会打印出 > 。

1.1.4 strlen函数的三种模拟实现方法
方法一 计数器方法
str 指向的是arr数组,*str就拿到了str所指向地址的内容,当str所指向的空间的内容不为'\0'时,计数器++,当str指向的空间的内容为'\0'时,循环不会进入,计数器就不会++。所以count的值就是字符串的长度。
#include
#include
#include
size_t my_strlen(const char* str)
{
int count = 0;
assert(str != NULL);
while (*str)
{
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
printf("%d\n", my_strlen(arr));
return 0;
} 方法二 递归的方法
我们要想知道"abcdef"的长度,首先可以想到先知晓‘a’的长度再加上“bcedf”的长度,也就是1+strlen(bcdef),依此类推!1+1+strlen(cdef)........ 1+1+1+1+1+strlen(f),1+1+1+1+1+1+strlen('\0')
size_t my_strlen(const char* str)
{
assert(str != NULL);
if (*str != '\0')
return 1 + strlen(str + 1);
else
return 0;
}
int main()
{
char arr[] = "abcdef";
printf("%d\n", my_strlen(arr));
return 0;
}方法三 指针减指针
找到字符串最后一个元素的位置,与首元素位置相减即可。
size_t my_strlen(const char* str)
{
assert(str != NULL);
const char* p = str;
while (*str)
{
str++;
}
return str - p;
}
int main()
{
char arr[] = "abcdef";
printf("%d\n", my_strlen(arr));
return 0;
}1.2 strcpy
char* strcpy(char * destination, const char * source );
Copies the C string pointed by source into the array pointed by destination, including the terminating null character (and stopping at that point).
意思就是将源字符串指复制到目标字符串中去
1.2.1 源字符串必须以 '\0' 结束,会将源字符串中的 '\0' 拷贝到目标空间,目标空间必须足够大,以确保能存放源字符串。

1.2.2 目标空间必须可变。
#include
#include
int main()
{
//char arr1[20] = "xxx\0xxxxxxxxx";
char* arr = "xxx\0xxxxxxxxx";
//arr指向的字符串是常量字符串 不可被修改1
char arr2[] = "abcdef";
strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
} 1.2.3 模拟实现方法
依次地将源字符串中的每个字符放到目标字符串即可,记住'\0'也要放过去。
char* my_strcpy(char* dest,const char* src)
{
assert(dest && src);
char* ret = dest;
while(*dest++ = *src++)
{
;
}
return ret;
}
//strcpy函数返回的是目标空间的起始地址
//strcpy函数的返回类型的设置是为了实现链式访问
int main()
{
char arr1[20] = "xxxxxxxxxxxx";
char arr2[] = "abcdef";
printf("%s\n", my_strcpy(arr1, arr2));
return 0;
}1.3 strcat
char * strcat ( char * destination, const char * source );
Appends (追加) a copy of the source string to the destination string. The terminating null characterin destination is overwritten by the first character of source, and a null-character is included at the end of the new string formed by the concatenation of both in destination.
意思就是在目标字符串之后追加源字符串,追加的位置是目标字符串的'\0'处,等到源字符串中第一次出现'\0'时停止,并且也会将'\0'给追加过去。
int main()
{
char arr1[20] = "xxx";
char arr2[] = "yyy";
strcat(arr1, arr2);
printf("%s\n", arr1);
return 0;
}
1.3.1 目标空间必须有足够的大,能容纳下源字符串的内容 目标空间必须可修改。
但是字符串自己给自己追加,会怎么样呢?

如果自己给自己追加的话,以上面所画的图为例,原来'\0'的位置会被字符b覆盖,就会导致没有'\0',当src找到原来'\0'的位置时,找到的却是b,这样src和dest就会一直向后找,程序就会崩溃。所以用strcat函数来给自己追加字符串则不可行。
事实上,我们现在大多数编译器中,strcat这个函数都可以实现自己对自己的追加,这是因为现在的编译器都很高级,函数背后的源码实现,我们是看不见的,按逻辑上strcat是不可以自己对自己追加的,只是编译器为了更方便将它实现成我们想要的样子。
1.3.2 模拟实现方法
我们首先要找到目标字符串'\0'的位置,再将源字符串的内容从目标字符串'\0'的位置向后追加
char* my_strcat(char* dest, const char* src)
{
assert(dest && src);
char* ret = dest;
while (*dest)
{
dest++;
}
while (*dest++ = *src++)
{
;
}
return ret;
}
int main()
{
char arr1[20] = "xxx";
char arr2[] = "yyy";
printf("%s\n", my_strcat(arr1, arr2));
return 0;
}1.3.3 提示
很多人经常将两个字符串直接比较,认为这就是比较字符串的大小,但实际上这只是将两个字符串的首元素地址进行了比较。
1.4 strcmp
![]() This function starts comparing the first character of each string. If they are equal to each
This function starts comparing the first character of each string. If they are equal to each
other, it continues with the following pairs until the characters differ or until a terminating
null-character is reached.
意思就是 这个函数开始比较每个字符串的第一个字符。如果它们不相等,则得出结果。如果它们都相等,则继续往后比较,直到比较到字符不同或者碰到‘\0’字符时结束。
标准规定:
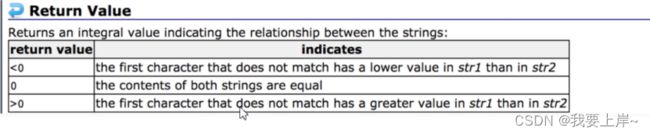
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字
注:在vs的编译器中分别用1 0 -1 来表示两个字符串的大小关系。
再次注意: strcmp函数比较的不是字符串的长度!!!
而是比较字符串中对应位置上的字符的大小!!!
int main()
{
char arr1[] = "abcd";
char arr2[] = "abdc";
int ret = strcmp(arr1, arr2);
if (ret > 0)
{
printf(">\n");
}
else if (ret == 0)
{
printf("=\n");
}
else
{
printf("<\n");
}
return 0;
}1.4.1 模拟实现方法
一.
int my_strcmp(const char* src1, const char* src2)
{
assert(src1 && src2);
while (*src1 == *src2)
{
if (*src1 == '\0')
return 0;
src1++;
src2++;
}
if (*src1 > *src2)
return 1;
else
return -1;
}
int main()
{
char arr1[] = "abcd";
char arr2[] = "abdc";
int ret = my_strcmp(arr1, arr2);
if (ret > 0)
printf(">\n");
else if (ret == 0)
printf("=\n");
else
printf("<\n");
return 0;
}二.
int my_strcmp(const char* src1, const char* src2)
{
assert(src1 && src2);
while (*src1 == *src2)
{
if (*src1 == '\0')
return 0;
src1++;
src2++;
}
return *src1 - *src2;
}
int main()
{
char arr1[] = "abcd";
char arr2[] = "abdc";
int ret = my_strcmp(arr1, arr2);
if (ret > 0)
printf(">\n");
else if (ret == 0)
printf("=\n");
else
printf("<\n");
return 0;
}1.5 strncpy
 Copies the first num characters of source to destination. If the end of the source C string
Copies the first num characters of source to destination. If the end of the source C string
(which is signaled by a null-character) is found before num characters have been copied,
destination is padded with zeros until a total of num characters have been written to it.
意思就是将源字符串的num个字符拷贝到目标空间。
如果源字符串的长度小于num,则将源字符串拷贝到目标字符串之后,在目标的后边追加'\0',直到整个拷贝的字符数达到num个。
int main()
{
char arr1[] = "abcdef";
char arr2[] = "qwe";
strncpy(arr1, arr2, 5);
printf("%s\n", arr1);
return 0;
}1.5.1 模拟实现
char* my_strncpy(char* dest, const char* src, int num)
{
assert(src && dest);
char* ret = dest;
int count = 0;
//拷贝
while (*dest++ = *src++)
{
count++;
if (count == num)
{
break;
}
}
count ++;
while (count
1.6 strncat
![]()
Appends the first num characters of source to destination, plus a terminating null-character.If the length of the C string in source is less than num, only the content up to the terminating null-character is copied.
(意思就是在将源字符串的num个字符(不包括'\0')追加到目标字符串之后,从'\0'处开始追加。如果源字符串中的字符数(不包括'\0') >= num个,则就规规矩矩地追加num(不包括'\0')个,还会在末尾追加一个'\0'。如果源字符串中的字符数(不包括'\0') < num个,则仅把有限的追加过去,也还是会在末尾追加一个'\0',单并不会添补'\0'的个数到num个了。)
int main()
{
char arr1[20] = "abcdef\0XXXXXXXX";
char arr2[] = "qwe";
strncat(arr1, arr2, 5);
printf("%s\n", arr1);
return 0;
}
1.6.1 模拟实现
char* my_strncat(char* dest, const char* src, int num)
{
assert(src && dest);
char* ret = dest;
int count = 0;
//找到'\0'的位置
while (*dest)
{
dest++;
}
//拷贝-- 这次是有数量限制的拷贝
while (*dest++ = *src++)
{
count++;
if (count == num)
{
//当count == num时,追加字符数已经达到,这时候dest已经向后走了一步
//之后给*dest附上'\0'即可。
*dest = '\0';
break;
}
}
return ret;
}
int main()
{
char arr1[20] = "xxxx\0xxxxxx";
char arr2[] = "yyyyy";
my_strncat(arr1, arr2, 5);
printf("%s\n", arr1);
return 0;
}
1.7 strncmp
![]()
Compares up to num characters of the C string str1 to those of the C string str2.
This function starts comparing the first character of each string. If they are equal to each other, it continues with the following pairs until the characters differ, until a terminating null-character is reached, or until num characters match in both strings, whichever happens first.
意思就是比较两个字符串,直到比较到出现某个字符不一样或者一个字符串结束或者num个字符全部比较完即可。
int main()
{
char arr1[] = "abcdef";
char arr2[] = "abcdq";
int ret = strncmp(arr1, arr2, 4);
printf("%d\n", ret);
return 0;
}1.7.1 模拟实现
int my_strncmp(const char* str1, const char* str2, int num)
{
assert(str1 && str2);
int count = 0;
while (*str1 == *str2)
{
count++;
//限制只比较num个
if (count == num || *str1 == '\0')
return 0;
str1++;
str2++;
}
return *str1 - *str2;
}
int main()
{
char arr1[20] = "abcdef";
char arr2[] = "abcfg";
int ret = my_strncmp(arr1, arr2, 4);
printf("%d\n", ret);
return 0;
}1.5 1.6 1.7介绍的都是长度受限的函数,都是指定处理几个字符的函数
1.8 strstr
char * strstr ( const char *str1, const char * str2);
Returns a pointer to the first occurrence of str2 in str1, or a null pointer if str2 is not part of str1.
(意思就是在str1指向的字符串中找str2指向的字符串,如果找到,则返回str2字符串第一次出现在str1中的地址,如果没有就返回空指针)
int main()
{
char arr1[] = "abbbcdef";
char arr2[] = "bbc";
char* ret = strstr(arr1, arr2);
if (NULL == ret)
{
printf("找不到子串\n");
}
else
{
printf("%s\n", ret);
}
return 0;
}
1.8.1 模拟实现

我们采用这种也个既包含简单又包含复杂情况的例子来讲解。 我们要明白我们的意图:在arr1中是否存在子串arr2。
首先,*sr1 ! = *str2,所以从字符a开始向后是找不到子串bbc的,所以str1++,向后看能否匹配成功。

从这种情况开始,str1和st2同时向后移动,但是移动两次后,b和c不相同。这表明,从第二个字符b开始,也是不能找到子串bbc的。

此时,就要回到第三个字符重新比较,而str2也要回到最开始的位置,以便进行下次比较。
 而这次,str1和str2向后走时,所指向的内容都相同。当*srt2 == '\0'时,则代表找到了子串bbc,此时返回第三个字符所在的即可。
而这次,str1和str2向后走时,所指向的内容都相同。当*srt2 == '\0'时,则代表找到了子串bbc,此时返回第三个字符所在的即可。
我们的逻辑梳理清楚了,但是要实现这并不方便,我们找到子串bbc后,str1已经不在原来第三个字符的位置了,并且之前每一次的匹配失败,str2都要回到起始位置。那么,我们就干脆不要动str1和str2,用另外两个指针s1,s2来代替它们移动。我们还要用一个指针cur来记录一下每次重新匹配的位置。

第一个字符肯定不成功,所以cur往后移动,s1要指向cur,因为第一个字符已经不会匹配成功了,所以要从下一个字符开始匹配。

这个时候又匹配失败了,所以cur继续向后移动。

每一次匹配s1都要指向cur,并且s2只要匹配失败了就要回到初始位置。
 此时,找到子串,这时返回cur指针即可。
此时,找到子串,这时返回cur指针即可。

char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
const char* s1 = str1;
const char* s2 = str2;
const char* cur = str1;
while (*cur)
{
s1 = cur;
s2 = str2;
//*s1和*s2不仅要相同,还要判断它们是否已经到达末尾
while ((*s1 == *s2) && *s1 && *s2)
{
s1++;
s2++;
}
//当s2指向'\0'就代表有这个子串
if (*s2 == '\0')
{
return (char*)cur;
}
cur++;
}
return NULL;
}
int main()
{
char arr1[] = "abbbcdef";
char arr2[] = "bbc";
char* ret = my_strstr(arr1, arr2);
if (NULL == ret)
{
printf("找不到子串\n");
}
else
{
printf("%s\n", ret);
}
return 0;
}查找子串还有一种更好的方法:kmp算法,我会在之后的博客中更新出来。
1.9 strtok
![]()
这个函数的作用就是将有分隔符的字段都分割出来
sep参数是个字符串,定义了用作分隔符的字符集合
第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的字符串
strtok函数会找到str中的一个分隔符,并将其用 \0 覆盖,并且返回指向这个以\0结尾的字符串的指针。例如:char* sep = "@! ";, char arr[ ]="abcd@retw!weru@" 如果首先将首元素地址传给strtok这个函数,那么它就会从首元素向后找,找到abcd后@所在的位置,并将其覆盖成\0,同时将字符a的地址作为返回值返回。
(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
如果 strtok 函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
如果 strtok 函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
如果字符串中不存在更多的标记,则返回 NULL 指针。
#include
#include
int main()
{
char arr[30] = "abcd@efg!hijk@haha";
char buf[30] = { 0 };
strcpy(buf, arr);
char* sep = "@!";
printf("%s\n",strtok(buf, sep)); //只找第一个标记
printf("%s\n", strtok(NULL, sep)); //是从保存的好的位置开始继续往后找
printf("%s\n", strtok(NULL, sep)); //是从保存的好的位置开始继续往后找
return 0;
} 
当然,这样写代码有点呆,我们可以有另外两种写法。
#include
#include
int main()
{
char arr[30] = "abcd@efg!hijk@haha";
char buf[30] = { 0 };
strcpy(buf, arr);
char* sep = "@!";
char* str = NULL;
for (str = strtok(buf, sep); str != NULL; str = strtok(NULL, sep))
{
printf("%s\n", str);
}
return 0;
}

int main()
{
char arr[30] = "abcd@efg!hijk@haha";
char buf[30] = { 0 };
strcpy(buf, arr);
char* sep = "@!";
char* str = strtok(buf, sep);
while (str != NULL)
{
printf("%s\n", str);
str = strtok(NULL, sep);
}
return 0;
}
这两种使用strtok函数的方法都可以。但是这个函数不需要模拟实现,了解怎么使用即可。
1.10 strerror
![]()
这个函数主要的用途主要是 返回错误码所对应的错误信息
errno(错误码)是一种全局变量
我们有时上网所见到的404就是一种常见的错误码。
#include
#include
#include
int main()
{
printf("%s\n", strerror(0));
printf("%s\n", strerror(1));
printf("%s\n", strerror(2));
printf("%s\n", strerror(3));
int* p = (int*)malloc(INT_MAX);//向堆区申请内存的 INT_MAX是整型的最大值
//使用INT_MAX时需要调用头文件limits.h
if (p == NULL)
{
printf("%s\n", strerror(errno));
//perror("Malloc");
return 1;
}
return 0;
} 
同样地,这个函数也没有模拟实现的必要。
此外,还有一个perror函数,它会为你打印你输入的字符并在后面加上一个空格和一个 : 号
int main()
{
int* p = (int*)malloc(INT_MAX);//向堆区申请内存的
if (p == NULL)
{
//printf("%s\n", strerror(errno));
perror("Malloc");
return 1;
}
//....
return 0;
} 
2. 字符操作函数
2.1 字符分类函数
| 函数 | 如果他的参数符合下列条件就返回真 |
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行'\n',回车‘\r’,制表符'\t'或者垂直制表符'\v' |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母a~f,大写字母A~F |
| islower | 小写字母a~z |
| isalpha | 字母a~z或A~Z |
| isalnum | 字母或者数字,a~z,A~Z,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括 |
2.2 字符转换函数
| int tolower ( int c ); | 将大写转换成小写 |
| int toupper ( int c ) | 将小写转换成大写 |
下面是使用的一些例子。
#include
int main()
{
//int ret = iscntrl(
//int ret = isdigit('5');
//char ch = 'a';
printf("%d\n", ret);
///*int ret = islower(ch);*/
//int ret = isalnum(ch);
//printf("%d\n", ret);
//int ret = ispunct('*');
//int ret = isgraph('A');
/*int ret = isprint(' ');
printf("%d\n", ret);*/
char ch = 'A';
putchar(tolower(ch));
putchar(toupper(ch));
} 3.内存操作函数
3.1 memcpy
![]()
我们知道strcpy只能拷贝字符串,但在我们的实际应用中还会有许多其它类型的数据,这个时候strcpy就不能够满足我们的需求了,所以memcpy就出现了。
memcpy函数是从 source 指向的位置开始向后复制 num 个字节的数据到 destination 指向的 内存位置。 这个函数在遇到 '\0' 的时候并不会停下来。
如果 source 和 destination 有重叠的情况,复制的结果则是会出现不确定的情况。
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[5] = { 0 };
memcpy(arr2, arr1, 20);
return 0;
}代码调试走起来,你会看到arr2中的元素变成了1,2,3,4,5。


3.1.1 模拟实现
设计memcpy函数的作者一开始是想不到它会用作什么类型的数据的
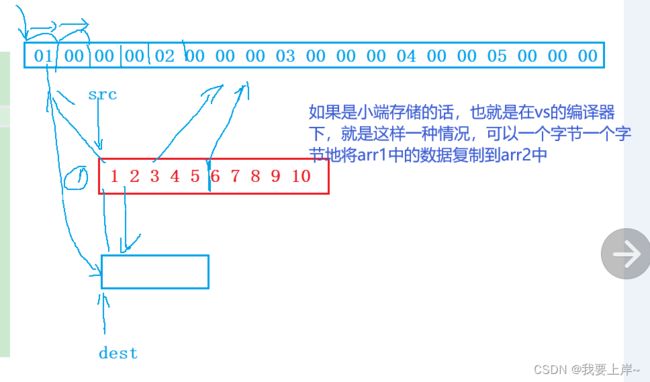
#include
#include
#include
void* my_memcpy(char* dest, char* src, size_t count)
{
assert(src && dest);
char* ret = dest;
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1; // 因为dest是void*类型的 要向后移动一个字节,就要先转化为char*类型
src = (char*)src + 1; //同理src也一样
}
return ret;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[5] = { 0 };
my_memcpy(arr2, arr1, 20);
return 0;
} 
但是当我们用自己模拟实现的mencpy函数在碰到重叠的内存块时,就会发生错误,产生和我们预期不一样的结果。
#include
void* my_memcpy(void* dest,const void* src, size_t count)
{
assert(dest && src);
void* ret = dest;
while (count--)
{
*(char*)dest= *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(arr1+2, arr1, 20);
return 0;
} 

看上述的代码,我们是要将从arr1开始向后的20个字节拷贝到从arr1+2开始的20个字节处,也就是将1 2 3 4 5拷贝到3 4 5 6 7的位置,我们想得到的结果应该是1 2 1 2 3 4 5 8 9 10,但是通过调试来看结果是1 2 1 2 1 2 1 8 9 10。为什么会是这样呢?

按照上面的模拟实现方法,我们将1拷贝到3的位置时,3就被覆盖了,等我们再到3的位置时,原来的3 就被改成了1,我们会将1拷贝到后面去,其他情况,以此类推下去。
而要实现重叠内存块的拷贝那就要用到 memmove 函数了。
3.2 memmove
![]()
这个函数和 memcpy 的差别就是 memmove 函数处理的源内存块和目标内存块是可以重叠的。
如果源空间和目标空间出现重叠,就得使用memmove函数处理。
int main()
{
/*int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[5] = { 0 };
my_memcpy(arr1+2, arr1, 20);*/
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr1+2, arr1, 20);
return 0;
}
3.2.1 模拟实现
比如,我要将3 4 5 6 7拷贝到 1 2 3 4 5的位置。


当 dest < src 时,我们要想做到不覆盖,就要从源数据段开始从前向后拷贝。

当dest > src && dest < (char*)src+count 时, 我们要想做到不覆盖,就要从源数据段开始从后向前拷贝。

当 dest > (char*)src+count 时,从前向后,从后向前拷贝都不影响了。

因此,我们就有两种方法。画绿圈的是一种,画红圈的是一种。
方法一,当 dest < src 时,就从源数据段开始从前向后拷贝,当dest > src 时,就从源数据段开始从后向前拷贝。

方法二 当dest > src && dest < (char*)src+count 时,就从源数据段开始从后向前拷贝,其他情况则从后向前拷贝

方法一代码
void* my_memmove(void* dest, void* src, size_t count)
{
assert(src && dest);
char* ret = dest;
if (dest < src)
{
//前->后
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
//后->前
else
{
while (count--)
{
*((char*)dest + count) = *((char*)src + count);
}
}
return ret;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr1+2, arr1, 20);
return 0;
}从后向前拷贝的代码解释

当count判断后,进入到循环内部,count就会--,我们要做的操作是从后向前拷贝,而此时count的值时19,对此时的地址解引用,就正好找到了源数据段的最后一个字节,将其拷贝到目标数据段的最后一个字节即可。
方法二代码
void* my_memmove(void* dest, void* src, size_t count)
{
assert(src && dest);
char* ret = dest;
//后->前
if (dest > src && dest < (char*)src+count)
{
while (count--)
{
*((char*)dest + count) = *((char*)src + count);
}
}
//前->后
else
{
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
return ret;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr1 + 2, arr1, 20);
return 0;
}但是,实际上在我们今天的编译器中,memmove和memcpy所实现的功能几乎都完全一样了,这并不代表我们的模拟就是错的,只是编译器的作者在逐渐方便我们的使用。
3.3 memcmp
| int memcmp ( const void * ptr1,const void * ptr2,size_t num ); |
这个函数用于 比较从ptr1和ptr2指针开始的num个字节
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 1,2,3,4,0x11223305 };
int ret = memcmp(arr1, arr2, 18);
printf("%d\n", ret);
return 0;
}
00小于33 ,所以打印出来的结果是-1

同样的,这个函数也没有模拟的必要。
3.4 memset
void * memset ( void * ptr, int value, size_t num );
这个函数用于更改内存中的数据,注意是以字节为单位更改的。
int main()
{
int arr[] = { 0x11111111,0x22222222,3,4,5 };
memset(arr, 6, 20);//memset是以字节为单位来初始化内存单元的
return 0;
}
这个,也就只需要知道怎么用即可。没必要模拟。